I sidste måned postede jeg en udfordring om at skabe en effektiv nummerseriegenerator. Svarene var overvældende. Der var mange geniale ideer og forslag, med masser af applikationer langt ud over denne særlige udfordring. Det fik mig til at indse, hvor fantastisk det er at være en del af et fællesskab, og at fantastiske ting kan opnås, når en gruppe kloge mennesker slår sig sammen. Tak Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason og John Number2 for at dele dine ideer og kommentarer.
Til at begynde med tænkte jeg på kun at skrive én artikel for at opsummere de ideer, folk indsendte, men der var for mange. Så jeg deler dækningen op i flere artikler. Denne måned vil jeg primært fokusere på Charlies og Alan Bursteins foreslåede forbedringer af de to originale løsninger, som jeg postede sidste måned i form af de inline TVF'er kaldet dbo.GetNumsItzikBatch og dbo.GetNumsItzik. Jeg vil navngive de forbedrede versioner henholdsvis dbo.GetNumsAlanCharlieItzikBatch og dbo.GetNumsAlanCharlieItzik.
Det er så spændende!
Itziks originale løsninger
Som en hurtig påmindelse bruger de funktioner, jeg dækkede sidste måned, en basis-CTE, der definerer en tabelværdikonstruktør med 16 rækker. Funktionerne bruger en række kaskadende CTE'er, der hver anvender et produkt (krydssammenføjning) af to forekomster af dens foregående CTE. På denne måde kan du med fem CTE'er ud over basisen få et sæt på op til 4.294.967.296 rækker. En CTE kaldet Nums bruger funktionen ROW_NUMBER til at producere en række tal, der starter med 1. Til sidst beregner den ydre forespørgsel tallene i det anmodede interval mellem inputs @low og @high.
Funktionen dbo.GetNumsItzikBatch bruger en dummy join til en tabel med et kolonnelagerindeks for at få batchbehandling. Her er koden til at oprette dummy-tabellen:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Og her er koden, der definerer dbo.GetNumsItzikBatch-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Jeg brugte følgende kode til at teste funktionen med "Kassér resultater efter udførelse" aktiveret i SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Her er præstationsstatistikken, som jeg fik for denne udførelse:
CPU time = 16985 ms, elapsed time = 18348 ms.
Funktionen dbo.GetNumsItzik ligner, kun den har ikke en dummy join og får normalt rækketilstandsbehandling gennem hele planen. Her er funktionens definition:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Her er koden, jeg brugte til at teste funktionen:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Her er præstationsstatistikken, som jeg fik for denne udførelse:
CPU time = 19969 ms, elapsed time = 21229 ms.
Alan Bursteins og Charlies forbedringer
Alan og Charlie foreslog adskillige forbedringer af mine funktioner, nogle med moderate præstationsimplikationer og nogle med mere dramatiske. Jeg starter med Charlies resultater vedrørende kompilering overhead og konstant foldning. Jeg vil derefter dække Alans forslag, herunder 1-baserede versus @lav-baserede sekvenser (også delt af Charlie og Jeff Moden), undgå unødvendig sortering og beregne et talområde i modsat rækkefølge.
Resultater af kompileringstid
Som Charlie bemærkede, bruges en nummerseriegenerator ofte til at generere serier med meget små antal rækker. I disse tilfælde kan kompileringstiden for koden blive en væsentlig del af den samlede forespørgselsbehandlingstid. Det er især vigtigt, når du bruger iTVF'er, da det i modsætning til med lagrede procedurer ikke er den parameteriserede forespørgselskode, der bliver optimeret, snarere forespørgselskoden efter parameterindlejring finder sted. Med andre ord erstattes parametrene med inputværdierne før optimering, og koden med konstanterne bliver optimeret. Denne proces kan have både negative og positive konsekvenser. En af de negative implikationer er, at du får flere kompilationer, da funktionen kaldes med forskellige inputværdier. Af denne grund bør kompileringstider bestemt tages i betragtning - især når funktionen bruges meget hyppigt med små områder.
Her er de kompileringstider, Charlie fandt for de forskellige grundlæggende CTE-kardinaliteter:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Det er nysgerrigt at se, at blandt disse er 16 det optimale, og at der er et meget dramatisk spring, når du går op til næste niveau, som er 256. Husk at funktionerne dbo.GetNumsItzikBacth og dbo.GetNumsItzik bruger en base CTE-kardinalitet på 16 .
Konstant foldning
Konstant foldning er ofte en positiv implikation, som under de rigtige forhold kan aktiveres takket være parameterindlejringsprocessen, som en iTVF oplever. Antag for eksempel, at din funktion har et udtryk @x + 1, hvor @x er en inputparameter for funktionen. Du aktiverer funktionen med @x =5 som input. Det indlejrede udtryk bliver så 5 + 1, og hvis det er kvalificeret til konstant foldning (mere om dette snart), bliver det til 6. Hvis dette udtryk er en del af et mere udførligt udtryk, der involverer kolonner, og anvendes på mange millioner rækker, kan dette resultere i ikke-ubetydelige besparelser i CPU-cyklusser.
Den vanskelige del er, at SQL Server er meget kræsen med hensyn til, hvad der skal foldes konstant, og hvad der ikke skal foldes konstant. For eksempel vil SQL Server ikke konstant fold col1 + 5 + 1, og den vil heller ikke folde 5 + col1 + 1. Men den vil folde 5 + 1 + col1 til 6 + col1. Jeg ved. Så hvis din funktion for eksempel returnerede SELECT @x + col1 + 1 AS mycol1 FRA dbo.T1, kunne du aktivere konstant foldning med følgende lille ændring:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Tror du mig ikke? Undersøg planerne for de følgende tre forespørgsler i PerformanceV5-databasen (eller lignende forespørgsler med dine data) og se selv:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Jeg fik følgende tre udtryk i Compute Scalar-operatorerne for henholdsvis disse tre forespørgsler:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Kan du se, hvor jeg vil hen med dette? I mine funktioner brugte jeg følgende udtryk til at definere resultatkolonnen n:
@low + rownum - 1 AS n
Charlie indså, at med følgende lille ændring kan han aktivere konstant foldning:
@low - 1 + rownum AS n
For eksempel havde planen for den tidligere forespørgsel, som jeg leverede mod dbo.GetNumsItzik, med @low =1, oprindeligt følgende udtryk defineret af Compute Scalar-operatoren:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Efter anvendelse af ovenstående mindre ændring bliver udtrykket i planen:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Det er genialt!
Hvad angår præstationsimplikationerne, skal du huske, at de præstationsstatistikker, jeg fik for forespørgslen mod dbo.GetNumsItzikBatch før ændringen, var følgende:
CPU time = 16985 ms, elapsed time = 18348 ms.
Her er tallene, jeg fik efter ændringen:
CPU time = 16375 ms, elapsed time = 17932 ms.
Her er tallene, jeg fik for forespørgslen mod dbo.GetNumsItzik oprindeligt:
CPU time = 19969 ms, elapsed time = 21229 ms.
Og her er tallene efter ændringen:
CPU time = 19266 ms, elapsed time = 20588 ms.
Ydeevnen forbedredes kun en smule med et par procent. Men vent, der er mere! Hvis du har brug for at behandle de bestilte data, kan præstationskonsekvenserne være meget mere dramatiske, som jeg kommer til senere i afsnittet om bestilling.
1-baseret versus @lav-baseret sekvens og modsatte rækkenumre
Alan, Charlie og Jeff bemærkede, at i langt de fleste af de virkelige tilfælde, hvor du har brug for en række tal, har du brug for det til at starte med 1 eller nogle gange 0. Det er langt mindre almindeligt at have brug for et andet udgangspunkt. Så det kunne give mere mening at få funktionen til altid at returnere et interval, der starter med f.eks. 1, og når du har brug for et andet udgangspunkt, skal du anvende eventuelle beregninger eksternt i forespørgslen mod funktionen.
Alan kom faktisk med en elegant idé om at få den indbyggede TVF til at returnere både en kolonne, der starter med 1 (simpelthen det direkte resultat af ROW_NUMBER-funktionen) kaldet rn, og en kolonne, der starter med @low kaldet n. Da funktionen bliver inlinet, når den ydre forespørgsel kun interagerer med kolonnen rn, bliver kolonnen n ikke engang evalueret, og du får ydeevnefordelen. Når du har brug for sekvensen til at starte med @low, interagerer du med kolonnen n og betaler de relevante ekstra omkostninger, så der er ingen grund til at tilføje nogen eksplicitte eksterne beregninger. Alan foreslog endda at tilføje en kolonne kaldet op, der beregner tallene i modsat rækkefølge, og kun interagere med den, når der er behov for en sådan sekvens. Kolonnen op er baseret på beregningen:@high + 1 – rownum. Denne kolonne har betydning, når du skal behandle rækkerne i faldende rækkefølge, som jeg demonstrerer senere i bestillingsafsnittet.
Så lad os anvende Charlies og Alans forbedringer på mine funktioner.
For batch-mode-versionen skal du sørge for at oprette dummy-tabellen med columnstore-indekset først, hvis den ikke allerede er til stede:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Brug derefter følgende definition for dbo.GetNumsAlanCharlieItzikBatch-funktionen:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Her er et eksempel på brug af funktionen:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Denne kode genererer følgende output:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Test derefter funktionens ydeevne med 100 mio. rækker, og returner først kolonnen n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Her er præstationsstatistikken, som jeg fik for denne udførelse:
CPU time = 16375 ms, elapsed time = 17932 ms.
Som du kan se, er der en lille forbedring sammenlignet med dbo.GetNumsItzikBatch i både CPU og forløbet tid takket være den konstante foldning, der fandt sted her.
Test funktionen, kun denne gang returnerer kolonnen rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Her er præstationsstatistikken, som jeg fik for denne udførelse:
CPU time = 15890 ms, elapsed time = 18561 ms.
CPU-tid yderligere reduceret, selvom den forløbne tid ser ud til at være steget en smule i denne udførelse sammenlignet med, når du forespørger kolonne n.
Figur 1 har planerne for begge forespørgsler.
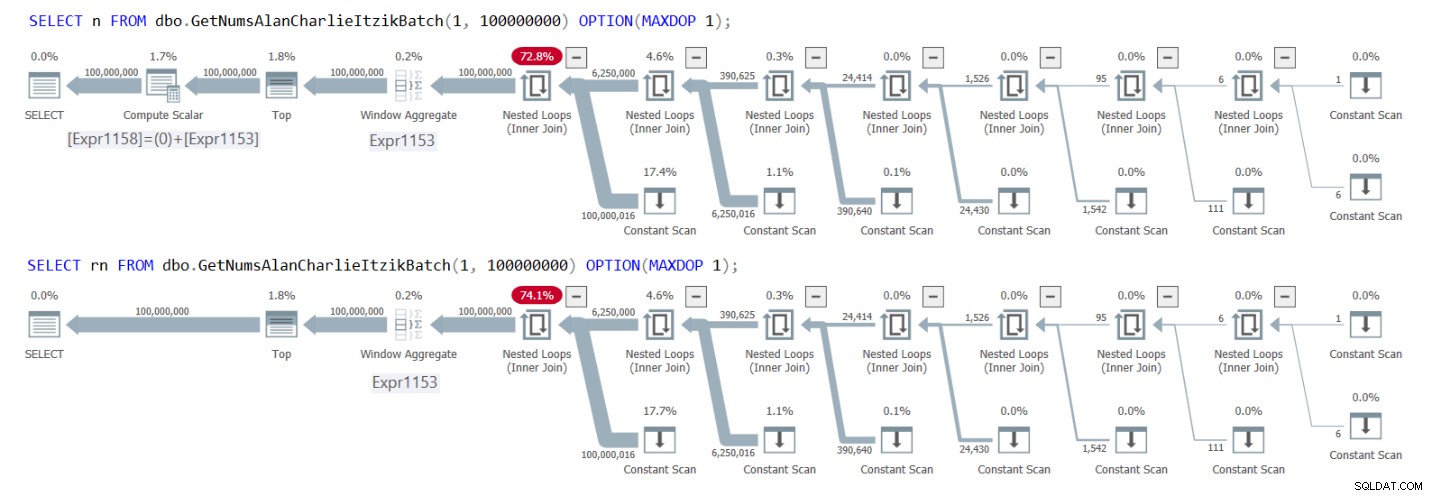 Figur 1:Planer for GetNumsAlanCharlieItzikBatch, der returnerer n versus rn
Figur 1:Planer for GetNumsAlanCharlieItzikBatch, der returnerer n versus rn
Du kan tydeligt se i planerne, at når du interagerer med kolonnen rn, er der ikke behov for den ekstra Compute Scalar-operator. Bemærk også i den første plan resultatet af den konstante foldningsaktivitet, som jeg beskrev tidligere, hvor @low – 1 + rownum blev indsat til 1 – 1 + rownum og derefter foldet til 0 + rownum.
Her er definitionen af rækketilstandsversionen af funktionen kaldet dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Brug følgende kode til at teste funktionen, og forespørg først kolonnen n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Her er de præstationsstatistikker, jeg fik:
CPU time = 19047 ms, elapsed time = 20121 ms.
Som du kan se, er det lidt hurtigere end dbo.GetNumsItzik.
Forespørg derefter kolonnen rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Ydeevnetallene forbedres yderligere på både CPU'en og den forløbne tidsfront:
CPU time = 17656 ms, elapsed time = 18990 ms.
Bestillingsovervejelser
De førnævnte forbedringer er bestemt interessante, og ydeevnepåvirkningen er ikke ubetydelig, men ikke særlig betydelig. En meget mere dramatisk og dybtgående præstationspåvirkning kan observeres, når du skal behandle dataene sorteret efter nummerkolonnen. Dette kunne være så simpelt som at skulle returnere de bestilte rækker, men det er lige så relevant for ethvert ordrebaseret behandlingsbehov, f.eks. en Stream Aggregate-operatør til gruppering og aggregering, en Merge Join-algoritme for joining og så videre.
Når du forespørger dbo.GetNumsItzikBatch eller dbo.GetNumsItzik og bestiller efter n, opdager optimeringsværktøjet ikke, at det underliggende bestillingsudtryk @low + rownum – 1 er ordrebevarende med hensyn til rownum. Implikationen minder lidt om et ikke-SARG-bart filtreringsudtryk, kun med et ordensudtryk resulterer dette i en eksplicit sorteringsoperator i planen. Den ekstra sortering påvirker responstiden. Det påvirker også skalering, som typisk bliver n log n i stedet for n.
For at demonstrere dette, forespørg dbo.GetNumsItzikBatch, og anmod om kolonnen n, sorteret efter n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Jeg fik følgende præstationsstatistik:
CPU time = 34125 ms, elapsed time = 39656 ms.
Kørselstiden mere end fordobles i forhold til testen uden ORDER BY-klausulen.
Test funktionen dbo.GetNumsItzik på en lignende måde:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Jeg fik følgende tal til denne test:
CPU time = 52391 ms, elapsed time = 55175 ms.
Også her er køretiden mere end fordoblet i forhold til testen uden ORDER BY-klausulen.
Figur 2 har planerne for begge forespørgsler.
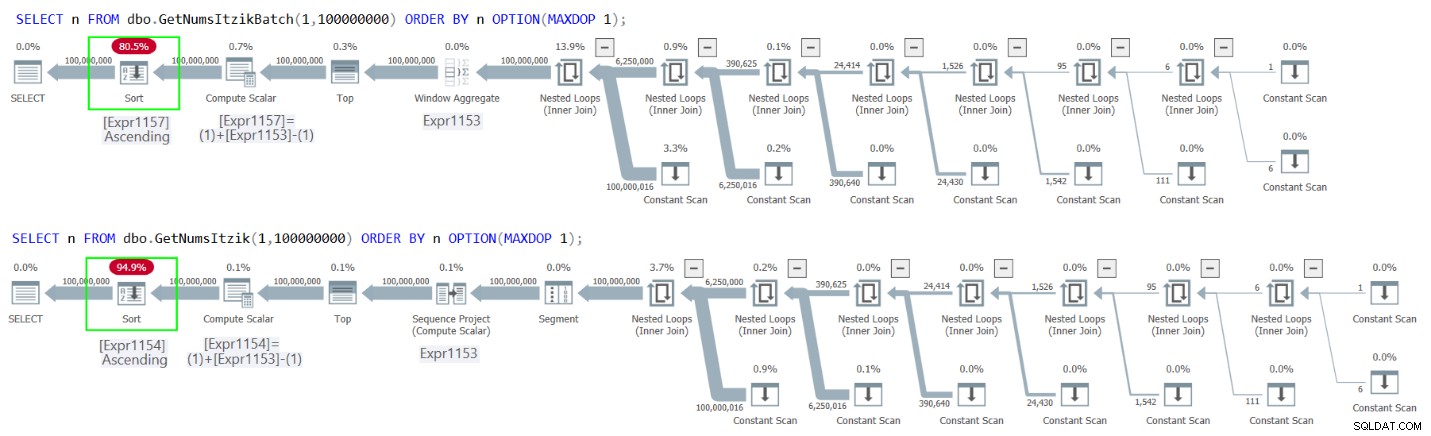 Figur 2:Planer for GetNumsItzikBatch og GetNumsItzik bestilling af n
Figur 2:Planer for GetNumsItzikBatch og GetNumsItzik bestilling af n
I begge tilfælde kan du se den eksplicitte sorteringsoperator i planerne.
Når du forespørger på dbo.GetNumsAlanCharlieItzikBatch eller dbo.GetNumsAlanCharlieItzik og bestiller efter rn, behøver optimizeren ikke at tilføje en Sorter-operator til planen. Så du kunne returnere n, men bestille efter rn, og på denne måde undgå en sortering. Hvad der dog er lidt chokerende – og jeg mener det på en god måde – er, at den reviderede version af n, som oplever konstant foldning, er ordensbevarende! Det er nemt for optimizeren at indse, at 0 + rownum er et ordensbevarende udtryk med hensyn til rownum og dermed undgå en sortering.
Prøv det. Forespørgsel dbo.GetNumsAlanCharlieItzikBatch, returnerer n og bestiller efter enten n eller rn, som sådan:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Jeg fik følgende præstationstal:
CPU time = 16500 ms, elapsed time = 17684 ms.
Det er naturligvis takket være, at der ikke var behov for en Sort-operatør i planen.
Kør en lignende test mod dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Jeg fik følgende tal:
CPU time = 19546 ms, elapsed time = 20803 ms.
Figur 3 har planerne for begge forespørgsler:
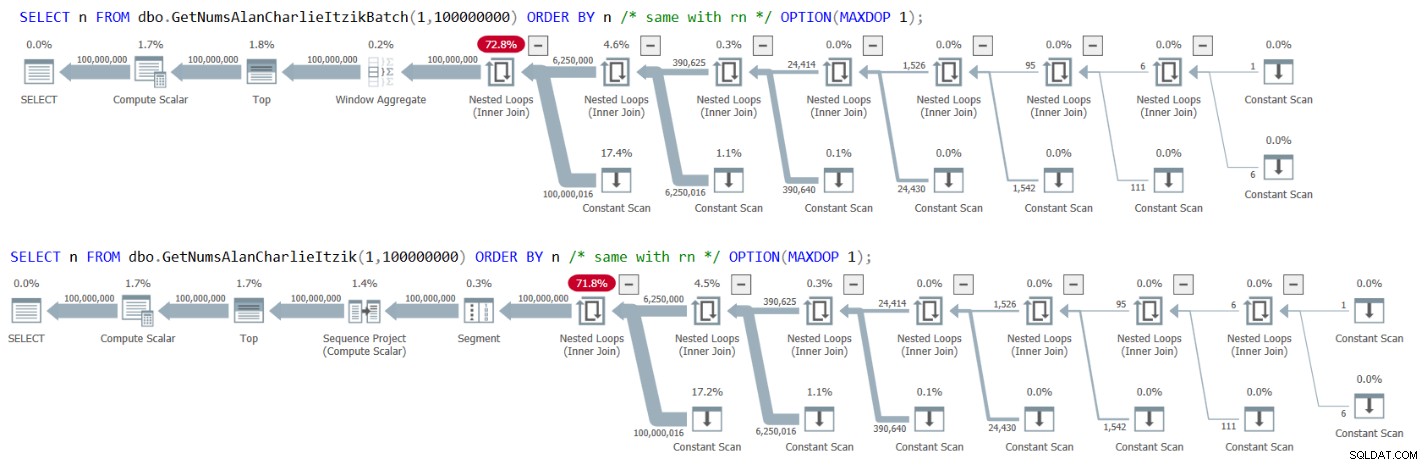
Figur 3:Planer for GetNumsAlanCharlieItzikBatch og Getarlietzik efter bestilling eller bestilling
Bemærk, at der ikke er nogen sorteringsoperatør i planerne.
Giver dig lyst til at synge...
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Tak Charlie!
Men hvad hvis du skal returnere eller behandle tallene i faldende rækkefølge? Det åbenlyse forsøg er at bruge ORDER BY n DESC, eller ORDER BY rn DESC, som sådan:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Desværre resulterer begge tilfælde dog i en eksplicit sortering i planerne, som vist i figur 4.
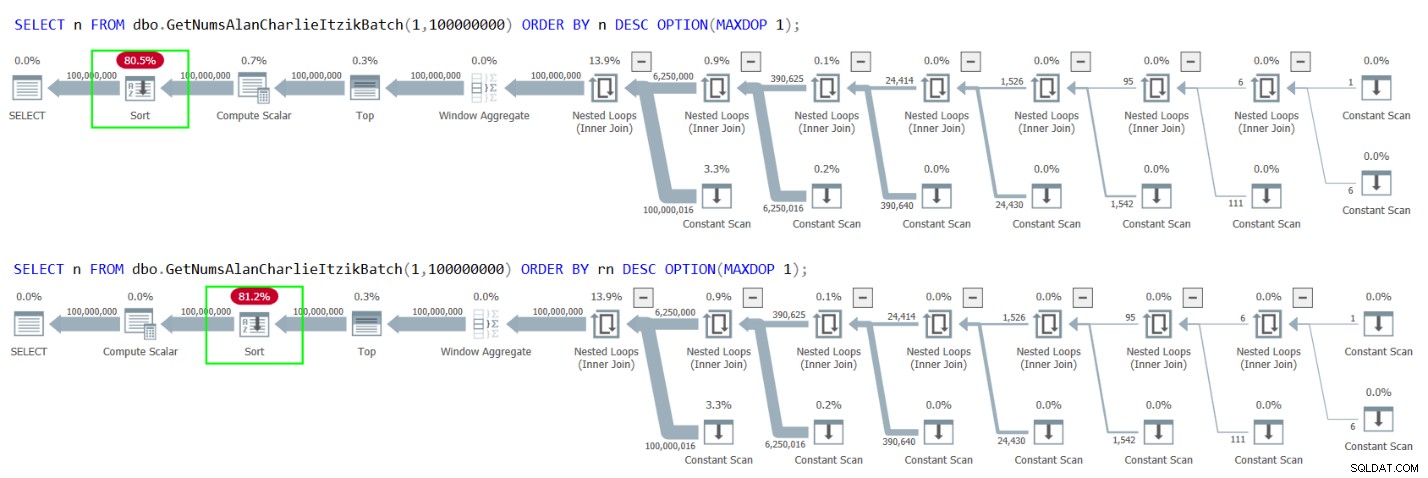 Figur 4:Planer for GetNumsAlanCharlieItzikBatch-bestilling efter n eller rn descen
Figur 4:Planer for GetNumsAlanCharlieItzikBatch-bestilling efter n eller rn descen
Det er her Alans smarte trick med spalteopgaven bliver en livredder. Returner kolonnen op, mens du bestiller efter enten n eller rn, sådan:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Planen for denne forespørgsel er vist i figur 5.
 Figur 5:Plan for GetNumsAlanCharlieItzikBatch, der returnerer op og bestiller som cnding eller em>
Figur 5:Plan for GetNumsAlanCharlieItzikBatch, der returnerer op og bestiller som cnding eller em>
Du får data tilbage sorteret efter n faldende, og der er ikke behov for en sortering i planen.
Tak Alan!
Ydeevneoversigt
Så hvad har vi lært af alt dette?
Kompileringstider kan være en faktor, især når du bruger funktionen ofte med små områder. På en logaritmisk skala med grundtallet 2 ser sød 16 ud til at være et dejligt magisk tal.
Forstå de særlige kendetegn ved konstant foldning og brug dem til din fordel. Når en iTVF har udtryk, der involverer parametre, konstanter og kolonner, skal du sætte parametrene og konstanterne i den forreste del af udtrykket. Dette vil øge sandsynligheden for foldning, reducere CPU-overhead og øge sandsynligheden for ordrebevarelse.
Det er ok at have flere kolonner, der bruges til forskellige formål i en iTVF, og forespørge på de relevante i hvert enkelt tilfælde uden at bekymre dig om at betale for dem, der ikke er refereret til.
Når du skal have talrækken returneret i modsat rækkefølge, skal du bruge den oprindelige n- eller rn-kolonne i ORDER BY-sætningen med stigende rækkefølge og returnere kolonnen op, som beregner tallene i omvendt rækkefølge.
Figur 6 opsummerer de præstationstal, som jeg fik i de forskellige tests.
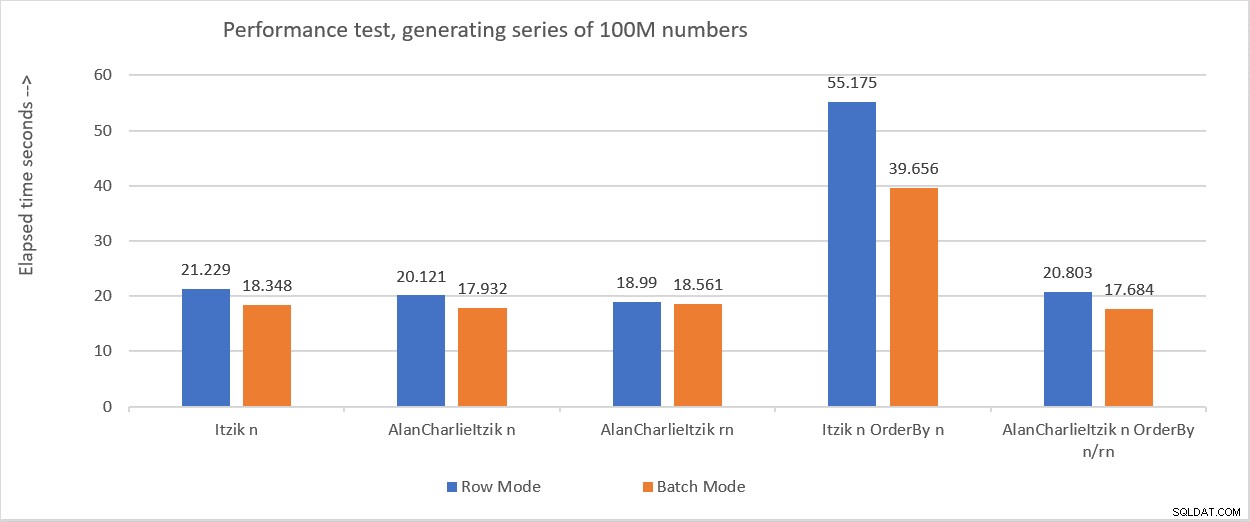 Figur 6:Præstationsoversigt
Figur 6:Præstationsoversigt
Næste måned fortsætter jeg med at udforske yderligere ideer, indsigt og løsninger til nummerseriegeneratorudfordringen.