Sidste år postede jeg et tip kaldet Forbedre SQL Server Efficiency ved at skifte til I STEDET FOR Triggere.
Den store grund til, at jeg har en tendens til at foretrække en ISTEDEN FOR trigger, især i tilfælde, hvor jeg forventer en masse forretningslogikovertrædelser, er, at det virker intuitivt, at det ville være billigere at forhindre en handling helt, end at gå videre og udføre den (og log det!), kun for at bruge en AFTER-trigger til at slette de stødende rækker (eller rulle hele handlingen tilbage). Resultaterne vist i det tip viste, at dette faktisk var tilfældet – og jeg formoder, at de ville være endnu mere udtalte med flere ikke-klyngede indekser påvirket af operationen.
Det var dog på en langsom disk og på en tidlig CTP af SQL Server 2014. Da jeg forberedte et dias til en ny præsentation, jeg vil lave i år på triggere, fandt jeg ud af, at på en nyere version af SQL Server 2014 – kombineret med opdateret hardware – det var lidt sværere at demonstrere det samme delta i ydeevne mellem en EFTER og I STEDET FOR trigger. Så jeg satte mig for at finde ud af hvorfor, selvom jeg med det samme vidste, at dette ville blive mere arbejde, end jeg nogensinde har gjort for et enkelt dias.
En ting, jeg vil nævne, er, at triggere kan bruge tempdb på forskellige måder, og dette kan forklare nogle af disse forskelle. En AFTER-trigger bruger versionslagret til de indsatte og slettede pseudo-tabeller, mens en INSTEAD OF-trigger laver en kopi af disse data i en intern arbejdstabel. Forskellen er subtil, men værd at påpege.
Variablerne
Jeg vil teste forskellige scenarier, herunder:
- Tre forskellige udløsere:
- En AFTER-udløser, der sletter bestemte rækker, der fejler
- En AFTER-trigger, der ruller hele transaktionen tilbage, hvis en række mislykkes
- En I STEDET FOR trigger, der kun indsætter rækker, der passerer
- Forskellige gendannelsesmodeller og indstillinger for snapshot-isolering:
- FULD med SNAPSHOT aktiveret
- FULD med SNAPSHOT deaktiveret
- ENKELT med SNAPSHOT aktiveret
- SIMPEL med SNAPSHOT deaktiveret
- Forskellige disklayouts*:
- Data på SSD, log på 7200 RPM HDD
- Data på SSD, log på SSD
- Data på 7200 RPM HDD, log på SSD
- Data på 7200 RPM HDD, log på 7200 RPM HDD
- Forskellige fejlfrekvenser:
- 10 %, 25 % og 50 % fejlrate på tværs af:
- Enkelt batchindlæg på 20.000 rækker
- 10 batches af 2.000 rækker
- 100 batches af 200 rækker
- 1.000 batches af 20 rækker
- 20.000 singleton skær
*
tempdber en enkelt datafil på en langsom 7200 RPM disk. Dette er bevidst og beregnet til at forstærke eventuelle flaskehalse forårsaget af de forskellige anvendelser aftempdb. Jeg planlægger at gense denne test på et tidspunkt, nårtempdber på en hurtigere SSD. - 10 %, 25 % og 50 % fejlrate på tværs af:
Okay, TL;DR Allerede!
Hvis du bare vil vide resultaterne, så spring ned. Alt i midten er kun baggrund og en forklaring på, hvordan jeg satte op og kørte testene. Jeg er ikke knust over, at ikke alle vil være interesserede i alle detaljerne.
Scenariet
For dette særlige sæt af tests er det virkelige scenarie et, hvor en bruger vælger et skærmnavn, og triggeren er designet til at fange tilfælde, hvor det valgte navn overtræder nogle regler. Det kan for eksempel ikke være nogen variant af "ninny-muggins" (du kan bestemt bruge din fantasi her).
Jeg oprettede en tabel med 20.000 unikke brugernavne:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Så lavede jeg en tabel, der ville være kilden for mine "frække navne" at tjekke op imod. I dette tilfælde er det bare ninny-muggins-00001 gennem ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Jeg oprettede disse tabeller i model database, så hver gang jeg opretter en database, ville den eksistere lokalt, og jeg planlægger at oprette en masse databaser for at teste scenariematricen ovenfor (i stedet for blot at ændre databaseindstillinger, rydde loggen osv.). Bemærk venligst, at hvis du opretter objekter i modellen til testformål, skal du sørge for at slette disse objekter, når du er færdig.
Som en sidebemærkning vil jeg med vilje lade nøgleovertrædelser og anden fejlhåndtering ude af dette, hvilket gør den naive antagelse, at det valgte navn kontrolleres for unikhed længe før indsættelsen nogensinde forsøges, men inden for den samme transaktion (ligesom check mod den frække navnetabel kunne være lavet på forhånd).
For at understøtte dette oprettede jeg også følgende tre næsten identiske tabeller i model , til testisoleringsformål:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Og de følgende tre udløsere, en for hver tabel:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Du vil sandsynligvis overveje yderligere håndtering for at underrette brugeren om, at deres valg blev rullet tilbage eller ignoreret – men dette er også udeladt for nemheds skyld.
Testopsætningen
Jeg oprettede eksempeldata, der repræsenterede de tre fejlrater, jeg ville teste, ændrede 10 procent til 25 og derefter 50, og tilføjede også disse tabeller til model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Hver tabel har 20.000 rækker, med en forskellig blanding af navne, der vil bestå og fejle, og rækkenummerkolonnen gør det nemt at opdele dataene i forskellige batchstørrelser for forskellige tests, men med gentagelige fejlfrekvenser for alle testene.
Selvfølgelig har vi brug for et sted at fange resultaterne. Jeg valgte at bruge en separat database til dette, hvor jeg kørte hver test flere gange, blot registrerede varigheden.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Jeg udfyldte dbo.Tests tabel med følgende script, så jeg kunne udføre forskellige dele for at sætte de fire databaser op, så de matcher de aktuelle testparametre. Bemærk, at D:\ er en SSD, mens G:\ er en 7200 RPM disk:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Så var det nemt at køre alle testene flere gange:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
På mit system tog dette tæt på 6 timer, så vær forberedt på at lade dette køre uafbrudt. Sørg også for, at du ikke har nogen aktive forbindelser eller forespørgselsvinduer åbne mod model database, ellers kan du få denne fejl, når scriptet forsøger at oprette en database:
Kunne ikke opnå eksklusiv lås på database-'model'. Prøv handlingen igen senere.
Resultater
Der er mange datapunkter at se på (og alle forespørgsler, der bruges til at udlede dataene, henvises til i appendiks). Husk, at hver gennemsnitsvarighed, der er angivet her, er over 10 tests og indsætter i alt 100.000 rækker i destinationstabellen.
Graf 1 – Samlede aggregater
Den første graf viser overordnede aggregater (gennemsnitlig varighed) for de forskellige variable isoleret (så *alle* tests ved hjælp af en AFTER-trigger, der sletter, *alle* tests med en AFTER-trigger, der ruller tilbage osv.).
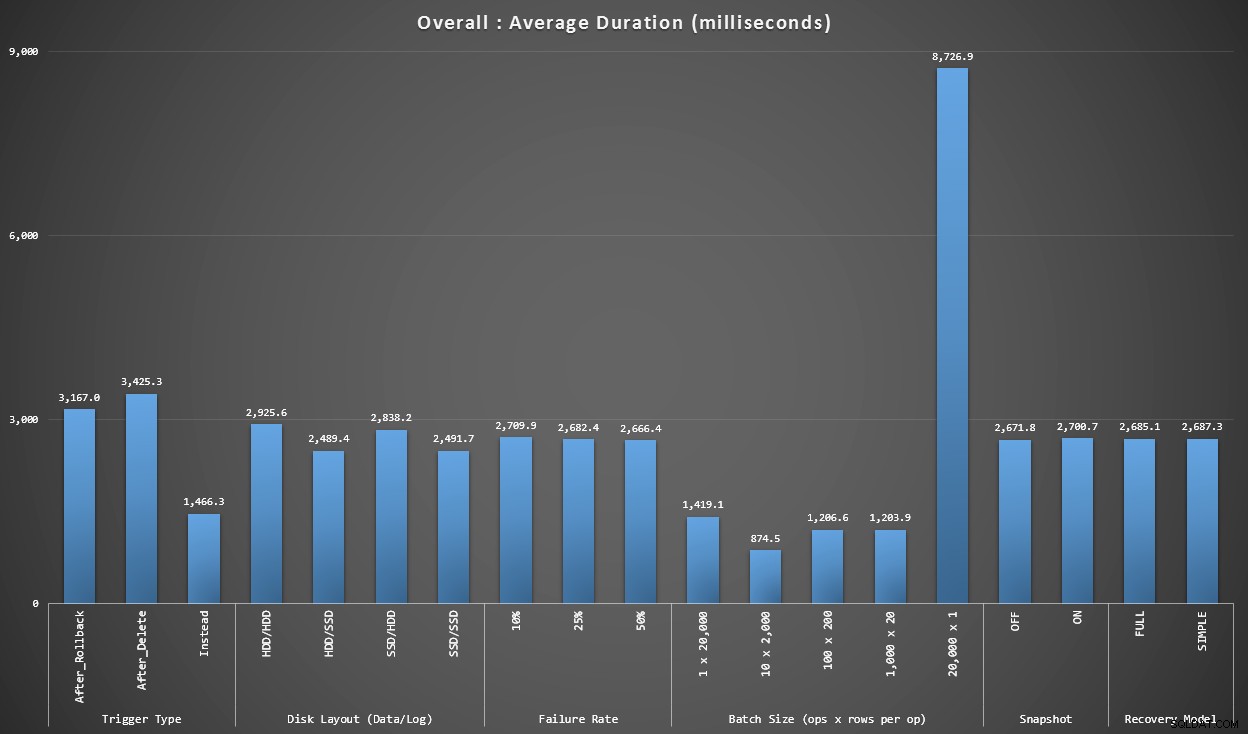
Gennemsnitlig varighed, i millisekunder, for hver variabel isoleret em>
Et par ting springer ud af os med det samme:
- INSTEAD OF-triggeren her er dobbelt så hurtig som begge AFTER-triggere.
- At have transaktionsloggen på SSD gjorde lidt af en forskel. Placeringen af datafilen meget mindre.
- Batchen på 20.000 singleton-skær var 7-8 gange langsommere end nogen anden batchdistribution.
- Den enkelte batch-indsats på 20.000 rækker var langsommere end nogen af de ikke-singleton-distributioner.
- Fejlfrekvens, snapshot-isolering og gendannelsesmodel havde ringe eller ingen indflydelse på ydeevnen.
Graf 2 – Bedste 10 samlet
Denne graf viser de hurtigste 10 resultater, når hver variabel tages i betragtning. Disse er alle I STEDET FOR triggere, hvor den største procentdel af rækker fejler (50%). Overraskende nok havde den hurtigste (dog ikke ret meget) både data og log på den samme HDD (ikke SSD). Der er en blanding af disklayouts og gendannelsesmodeller her, men alle 10 havde snapshot-isolering aktiveret, og de øverste 7 resultater involverede alle batchstørrelsen på 10 x 2.000 rækker.
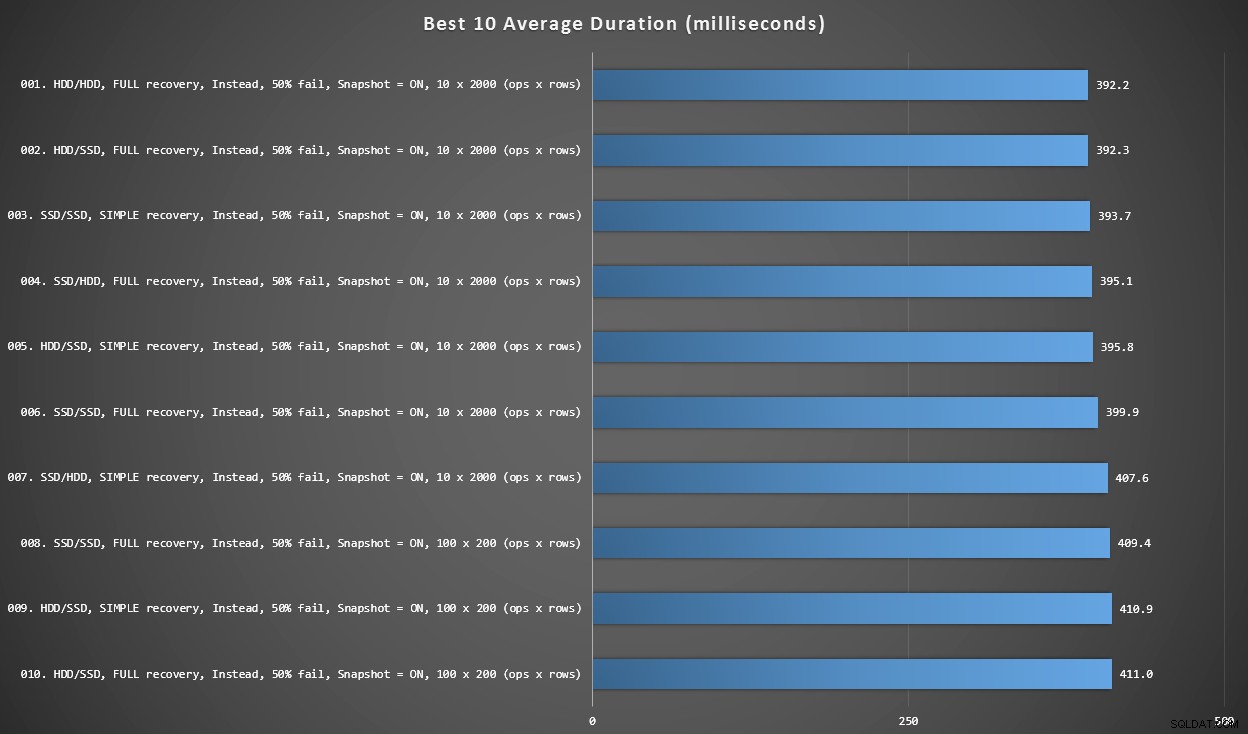
Bedste 10 varigheder i millisekunder, i betragtning af hver variabel
Den hurtigste AFTER-trigger – en ROLLBACK-variant med 10 % fejlrate i batchstørrelsen på 100 x 200 rækker – kom i position #144 (806 ms).
Graf 3 – Værste 10 samlet
Denne graf viser de langsomste 10 resultater, når hver variabel tages i betragtning; alle er AFTER-varianter, alle involverer de 20.000 singleton-indsatser, og alle har data og log på den samme langsomme HDD.
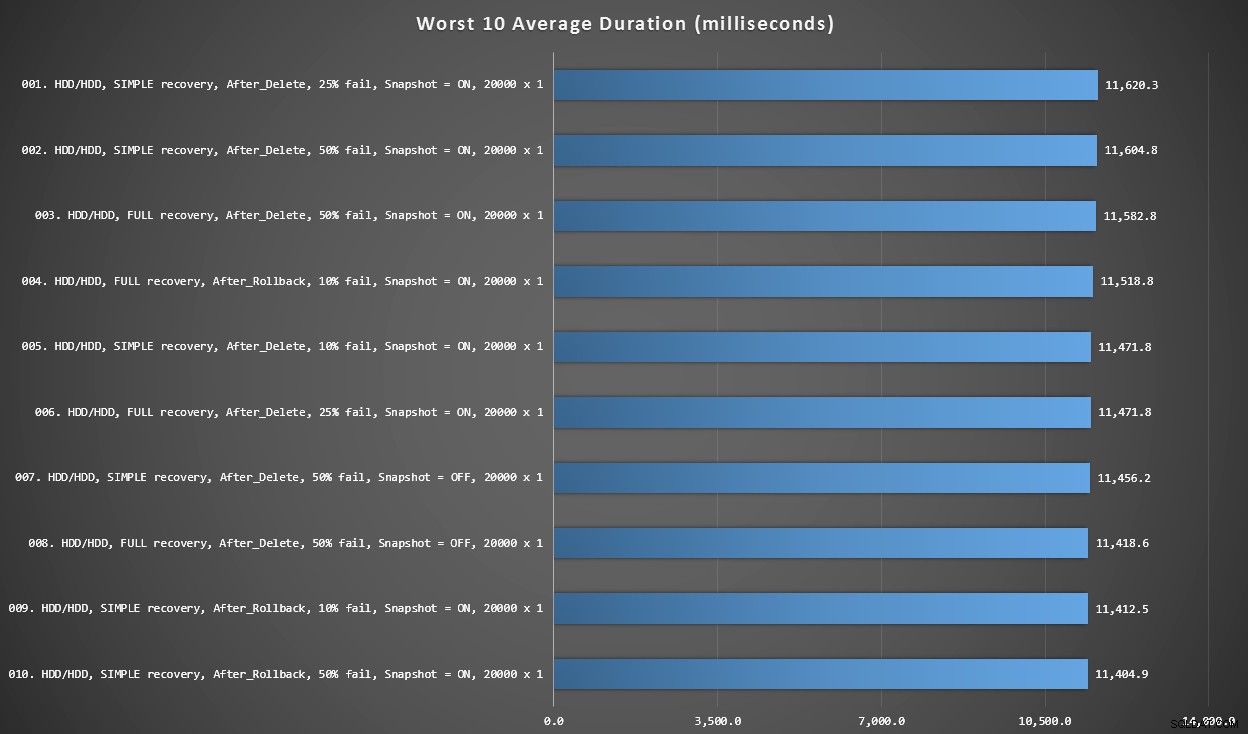
Værste 10 varigheder, i millisekunder, i betragtning af hver variabel
Den langsomste I STEDET FOR test var i position #97, ved 5.680 ms – en 20.000 singleton indstikstest, hvor 10 % mislykkedes. Det er også interessant at observere, at ikke en enkelt AFTER-trigger ved brug af 20.000 singleton-skærs batchstørrelse klarede sig bedre – faktisk var det 96. værste resultat en EFTER (slet) test, der kom ind på 10.219 ms – næsten det dobbelte af det næstlangsommeste resultat.
Graf 4 – Log Disk Type, Singleton Inserts
Graferne ovenfor giver os en nogenlunde idé om de største smertepunkter, men de er enten for zoomet ind eller ikke zoomet nok ind. Denne graf filtrerer ned til data baseret på virkeligheden:i de fleste tilfælde vil denne type operation være en enkelt indsættelse. Jeg tænkte, at jeg ville opdele det efter fejlfrekvens og typen af disk, loggen er på, men kun se på rækker, hvor batchen består af 20.000 individuelle indstik.
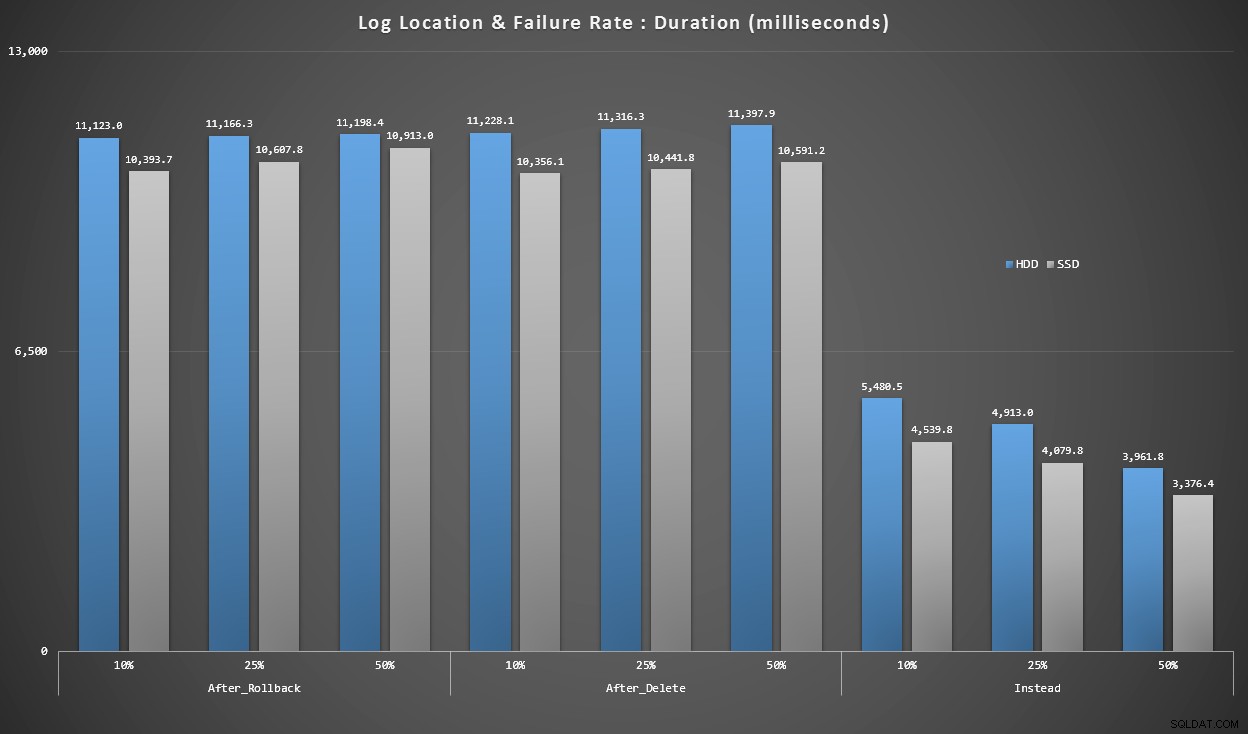
Varighed, i millisekunder, grupperet efter fejlrate og logplacering, for 20.000 individuelle skær
Her ser vi, at alle AFTER-triggere er i gennemsnit i intervallet 10-11 sekunder (afhængigt af logplacering), mens alle I STEDET FOR triggere er et godt stykke under 6-sekundersmærket.
Konklusion
Indtil videre forekommer det mig klart, at STEDET FOR-triggeren er en vinder i de fleste tilfælde – i nogle tilfælde mere end andre (f.eks. da fejlraten stiger). Andre faktorer, såsom genopretningsmodellen, ser ud til at have meget mindre indflydelse på den samlede ydeevne.
Hvis du har andre ideer til, hvordan du opdeler dataene, eller gerne vil have en kopi af dataene til at udføre din egen udskæring og opdeling, så lad mig det vide. Hvis du gerne vil have hjælp til at sætte dette miljø op, så du kan køre dine egne tests, kan jeg også hjælpe med det.
Selvom denne test viser, at I STEDET FOR triggere absolut er værd at overveje, er det ikke hele historien. Jeg slog bogstaveligt talt disse triggere sammen ved at bruge den logik, som jeg troede gav mest mening for hvert scenarie, men triggerkode - som enhver T-SQL-sætning - kan indstilles til optimale planer. I et opfølgende indlæg vil jeg tage et kig på en potentiel optimering, der kan gøre AFTER-triggeren mere konkurrencedygtig.
Bilag
Forespørgsler brugt til sektionen Resultater:
Graf 1 – Samlede aggregater
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Graf 2 og 3 – Bedste og værste 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Graf 4 – Log Disk Type, Singleton Inserts
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;