Paginering er en almindelig anvendelse i klient- og webapplikationer overalt. Google viser dig 10 resultater ad gangen, din onlinebank viser muligvis 20 regninger pr. side, og fejlsporing og kildekontrolsoftware viser muligvis 50 elementer på skærmen.
Jeg ønskede at se på den almindelige pagineringstilgang på SQL Server 2012 – OFFSET / FETCH (en standard svarende til MySQL's prioprietære LIMIT-klausul) – og foreslå en variation, der vil føre til mere lineær sidesøgningsydelse på tværs af hele sættet, i stedet for kun at være optimal i begyndelsen. Hvilket desværre er alt, som mange butikker vil teste.
Hvad er paginering i SQL Server?
Baseret på indekseringen af tabellen, de nødvendige kolonner og den valgte sorteringsmetode kan paginering være relativt smertefri. Hvis du leder efter de "første" 20 kunder, og det klyngede indeks understøtter denne sortering (f.eks. et klynget indeks på en IDENTITY-kolonne eller DateCreated-kolonne), så vil forespørgslen være relativt effektiv. Hvis du har brug for at understøtte sortering, der kræver ikke-klyngede indekser, og især hvis du har kolonner, der er nødvendige for output, der ikke er dækket af indekset (ligegyldigt, hvis der ikke er noget understøttende indeks), kan forespørgslerne blive dyrere. Og selv den samme forespørgsel (med en anden @PageNumber-parameter) kan blive meget dyrere, efterhånden som @PageNumber bliver højere – da flere læsninger kan kræves for at komme til det "udsnit" af dataene.
Nogle vil sige, at fremskridt mod slutningen af sættet er noget, du kan løse ved at kaste mere hukommelse på problemet (så du fjerner enhver fysisk I/O) og/eller bruge caching på applikationsniveau (så du ikke kommer til at databasen overhovedet). Lad os antage i forbindelse med dette indlæg, at mere hukommelse ikke altid er mulig, da ikke alle kunder kan tilføje RAM til en server, der er ude af hukommelsespladser eller ikke er i deres kontrol, eller bare knipse med fingrene og have nyere, større servere klar at gå. Især da nogle kunder er på Standard Edition, så de er begrænset til 64 GB (SQL Server 2012) eller 128 GB (SQL Server 2014), eller bruger endnu mere begrænsede udgaver såsom Express (1 GB) eller et af mange cloud-tilbud.
Så jeg ville se på den almindelige personsøgningstilgang på SQL Server 2012 – OFFSET / FETCH – og foreslå en variation, der vil føre til mere lineær personsøgningsydelse på tværs af hele sættet, i stedet for kun at være optimal i begyndelsen. Hvilket desværre er alt, som mange butikker vil teste.
Opsætning af sidedata/eksempel
Jeg har tænkt mig at låne fra et andet indlæg, Dårlige vaner:Fokuserer kun på diskplads, når jeg vælger nøgler, hvor jeg udfyldte følgende tabel med 1.000.000 rækker af tilfældige (men ikke helt realistiske) kundedata:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Da jeg vidste, at jeg ville teste I/O her og ville teste fra både en varm og kold cache, gjorde jeg testen i det mindste en lille smule mere retfærdig ved at genopbygge alle indekserne for at minimere fragmentering (hvilket ville blive gjort mindre forstyrrende, men regelmæssigt, på de fleste travle systemer, der udfører enhver form for indeksvedligeholdelse):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Efter genopbygningen kommer fragmentering nu ind på 0,05 % – 0,17 % for alle indekser (indeksniveau =0), sider er fyldt over 99 %, og rækkeantallet/sideantallet for indeksene er som følger:
| Indeks | Sideantal | Rækketælling |
|---|---|---|
| C_PK_Customers_I (klynget indeks) | 19.210 | 1.000.000 |
| C_Email_Customers_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (filtreret indeks) | 13.648 | 815.235 |
| C_Name_Customers_I | 16.824 | 1.000.000 |
Indekser, sideantal, rækkeantal
Dette er åbenbart ikke et superbredt bord, og jeg har ladet komprimering være ude af billedet denne gang. Måske vil jeg udforske flere konfigurationer i en fremtidig test.
Sådan pagineres en SQL-forespørgsel effektivt
Konceptet paginering – der kun viser brugeren rækker ad gangen – er lettere at visualisere end at forklare. Tænk på indekset for en fysisk bog, som kan have flere sider med referencer til punkter i bogen, men organiseret alfabetisk. Lad os for nemheds skyld sige, at der passer ti elementer på hver side i indekset. Dette kan se sådan ud:
Nu, hvis jeg allerede har læst side 1 og 2 i indekset, ved jeg, at for at komme til side 3, skal jeg springe 2 sider over. Men da jeg ved, at der er 10 genstande på hver side, kan jeg også tænke på dette som at springe 2 x 10 genstande over, og starte på 21. emne. Eller, for at sige det på en anden måde, jeg skal springe de første (10*(3-1)) elementer over. For at gøre dette mere generisk kan jeg sige, at for at starte på side n skal jeg springe de første (10 * (n-1)) elementer over. For at komme til den første side springer jeg 10*(1-1) punkter over, for at slutte på punkt 1. For at komme til den anden side springer jeg 10*(2-1) punkter over for at slutte på punkt 11. Og så på.
Med disse oplysninger vil brugere formulere en sidesøgning som denne, givet at OFFSET/FETCH-sætningerne tilføjet i SQL Server 2012 var specifikt designet til at springe så mange rækker over:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Som jeg nævnte ovenfor, fungerer dette fint, hvis der er et indeks, der understøtter ORDER BY, og som dækker alle kolonnerne i SELECT-sætningen (og, for mere komplekse forespørgsler, WHERE- og JOIN-sætningerne). Sorteringsomkostningerne kan dog være overvældende uden noget understøttende indeks, og hvis outputkolonnerne ikke er dækket, vil du enten ende med en hel masse nøgleopslag, eller du kan endda få en tabelscanning i nogle scenarier.
Bedste praksis for sortering af SQL-paginering
I betragtning af tabellen og indekserne ovenfor, ønskede jeg at teste disse scenarier, hvor vi vil vise 100 rækker pr. side og udlæse alle kolonnerne i tabellen:
- Standard –
ORDER BY CustomerID(klynget indeks). Dette er den mest bekvemme bestilling for databasefolkene, da det ikke kræver yderligere sortering, og alle data fra denne tabel, der muligvis er nødvendige for visning, er inkluderet. På den anden side er dette muligvis ikke det mest effektive indeks at bruge, hvis du viser en delmængde af tabellen. Ordren giver måske heller ikke mening for slutbrugere, især hvis CustomerID er en surrogat-id uden ekstern betydning. - Telefonbog –
ORDER BY LastName, FirstName(understøttende ikke-klyngede indeks). Dette er den mest intuitive bestilling for brugere, men vil kræve et ikke-klynget indeks for at understøtte både sortering og dækning. Uden et understøttende indeks ville hele tabellen skulle scannes. - Brugerdefineret –
ORDER BY FirstName DESC, EMail(ingen understøttende indeks). Dette repræsenterer muligheden for brugeren til at vælge enhver sorteringsrækkefølge, de ønsker, et mønster Michael J. Swart advarer om i "UI Design Patterns That Don't Scale."
Jeg ønskede at teste disse metoder og sammenligne planer og målinger, når jeg - under både varm cache og kold cache scenarier - kiggede på side 1, side 500, side 5.000 og side 9.999. Jeg oprettede disse procedurer (der kun adskiller sig fra ORDER BY-klausulen):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail I virkeligheden vil du sandsynligvis kun have én procedure, der enten bruger dynamisk SQL (som i mit "køkkenvask" eksempel) eller et CASE-udtryk til at diktere rækkefølgen.
I begge tilfælde kan du se de bedste resultater ved at bruge OPTION (GENKOMPILER) på forespørgslen for at undgå genbrug af planer, der er optimale for én sorteringsmulighed, men ikke alle. Jeg oprettede separate procedurer her for at fjerne disse variabler; Jeg tilføjede OPTION (RECOMPILE) for disse tests for at holde mig væk fra parametersniffing og andre optimeringsproblemer uden at skylle hele plancachen gentagne gange.
En alternativ tilgang til SQL Server-paginering for bedre ydeevne
En lidt anderledes tilgang, som jeg ikke ser implementeret særlig ofte, er at finde den "side", vi er på, kun ved at bruge klyngingsnøglen og derefter slutte sig til det:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Det er selvfølgelig mere udførlig kode, men forhåbentlig er det klart, hvad SQL Server kan tvinges til at gøre:at undgå en scanning eller i det mindste udskyde opslag, indtil et meget mindre resultatsæt er skåret ned. Paul White (@SQL_Kiwi) undersøgte en lignende tilgang tilbage i 2010, før OFFSET/FETCH blev introduceret i de tidlige SQL Server 2012-betaer (jeg bloggede først om det senere samme år).
I betragtning af ovenstående scenarier oprettede jeg yderligere tre procedurer, med den eneste forskel mellem kolonnen(erne) specificeret i ORDER BY-sætningerne (vi har nu brug for to, en til selve siden og en til at bestille resultatet):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Bemærk:Dette fungerer muligvis ikke så godt, hvis din primære nøgle ikke er klynget – en del af tricket, der gør dette til at fungere bedre, når et understøttende indeks kan bruges, er, at klyngingsnøglen allerede er i indekset, så en opslag undgås ofte.
Test sortering af klyngenøgle
Først testede jeg det tilfælde, hvor jeg ikke forventede stor variation mellem de to metoder – sortering efter klyngingsnøglen. Jeg kørte disse sætninger i en batch i SQL Sentry Plan Explorer og observerede varighed, læsninger og de grafiske planer, og sikrede mig, at hver forespørgsel startede fra en fuldstændig kold cache:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
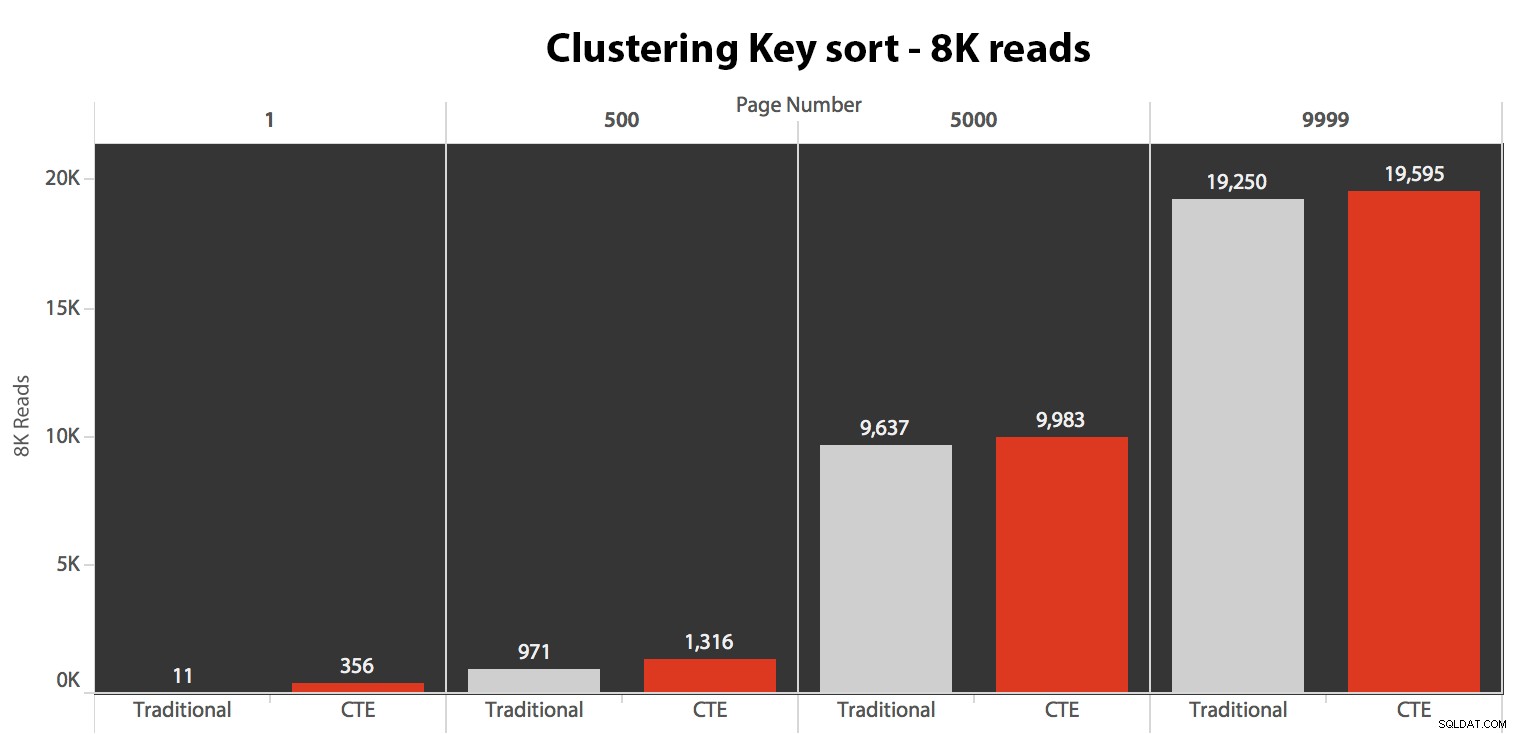
Resultaterne her var ikke forbløffende. Over 5 udførelser vises det gennemsnitlige antal læsninger her, der viser ubetydelige forskelle mellem de to forespørgsler på tværs af alle sidetal, når der sorteres efter klyngingsnøglen:
Planen for standardmetoden (som vist i Plan Explorer) var i alle tilfælde som følger:
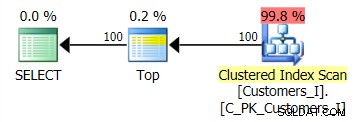
Mens planen for den CTE-baserede metode så sådan ud:
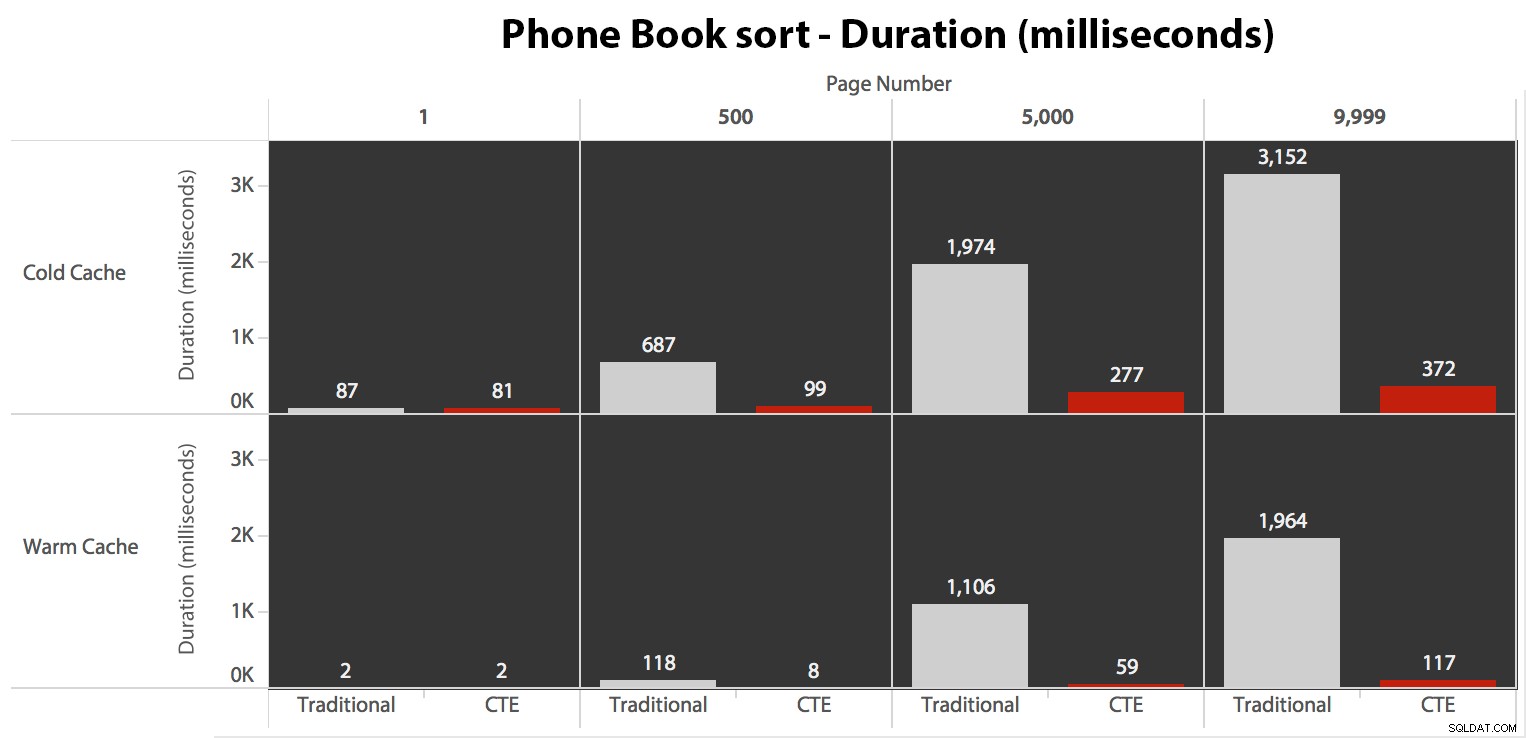
Nu, mens I/O var den samme uanset caching (bare meget flere read-ahead-læsninger i det kolde cache-scenarie), målte jeg varigheden med en kold cache og også med en varm cache (hvor jeg kommenterede DROPCLEANBUFFERS-kommandoerne og kørte forespørgslerne flere gange før måling). Disse varigheder så således ud:
Mens du kan se et mønster, der viser, at varigheden stiger i takt med, at sidetallet bliver højere, så husk skalaen:For at ramme rækkerne 999.801 -> 999.900, taler vi et halvt sekund i værste fald og 118 millisekunder i bedste fald. CTE-tilgangen vinder, men ikke ret meget.
Test af telefonbogssortering
Dernæst testede jeg det andet tilfælde, hvor sorteringen blev understøttet af et ikke-dækkende indeks på Efternavn, Fornavn. Forespørgslen ovenfor har lige ændret alle forekomster af Test_1 til Test_2 . Her var læsningerne ved hjælp af en kold cache:
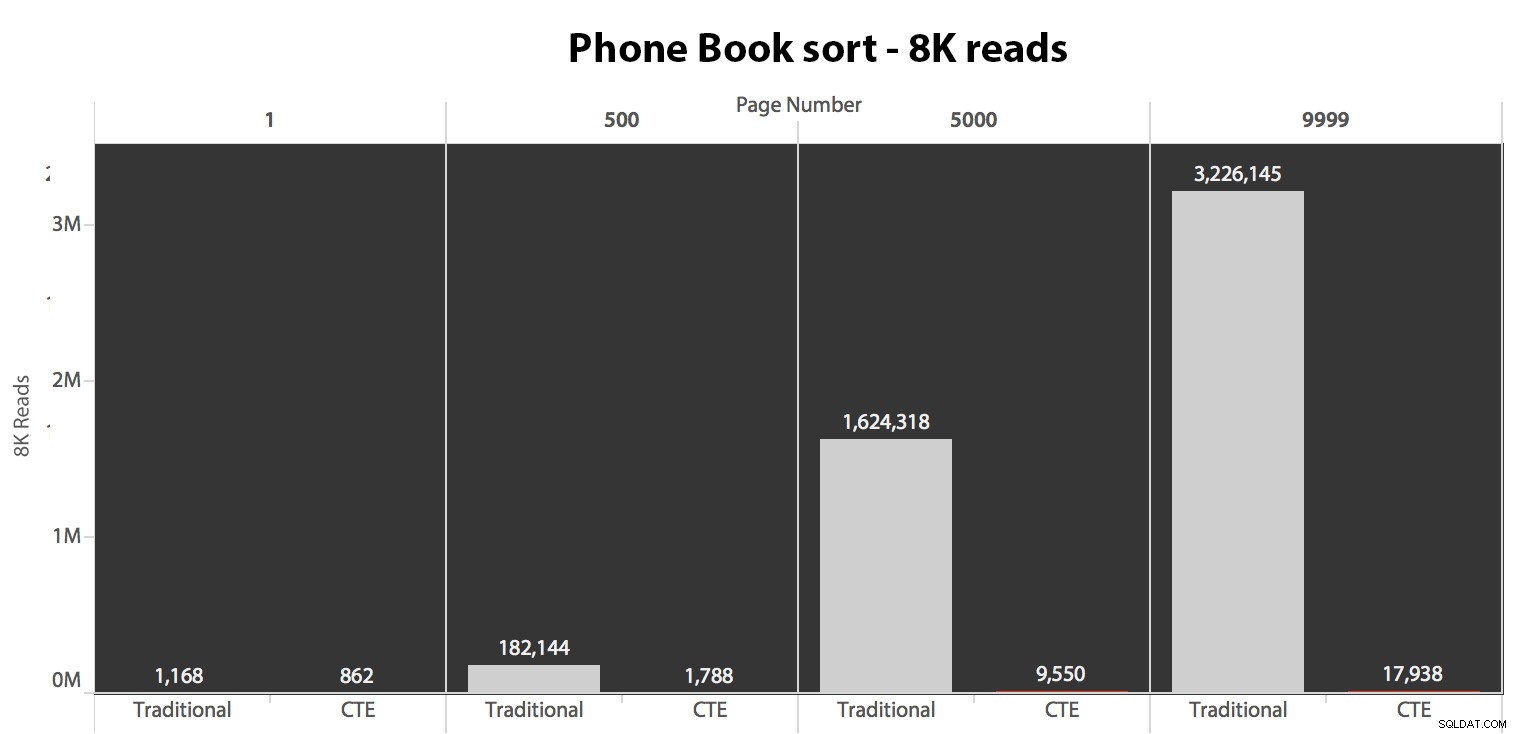
(Læsningerne under en varm cache fulgte det samme mønster - de faktiske tal afveg lidt, men ikke nok til at retfærdiggøre et separat diagram.)
Når vi ikke bruger det klyngede indeks til at sortere, er det klart, at I/O-omkostningerne forbundet med den traditionelle metode med OFFSET/FETCH er langt værre, end når man identificerer nøglerne først i en CTE og trækker resten af kolonnerne. kun for den delmængde.
Her er planen for den traditionelle forespørgselstilgang:
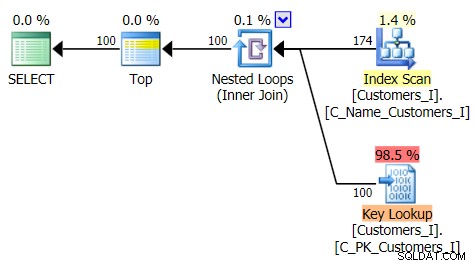
Og planen for min alternative CTE-tilgang:
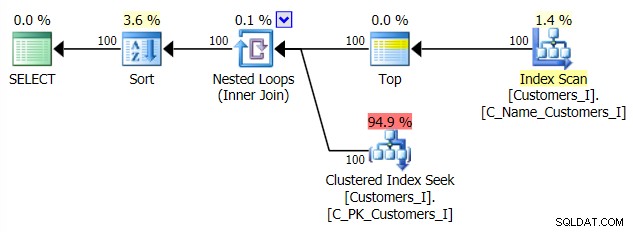
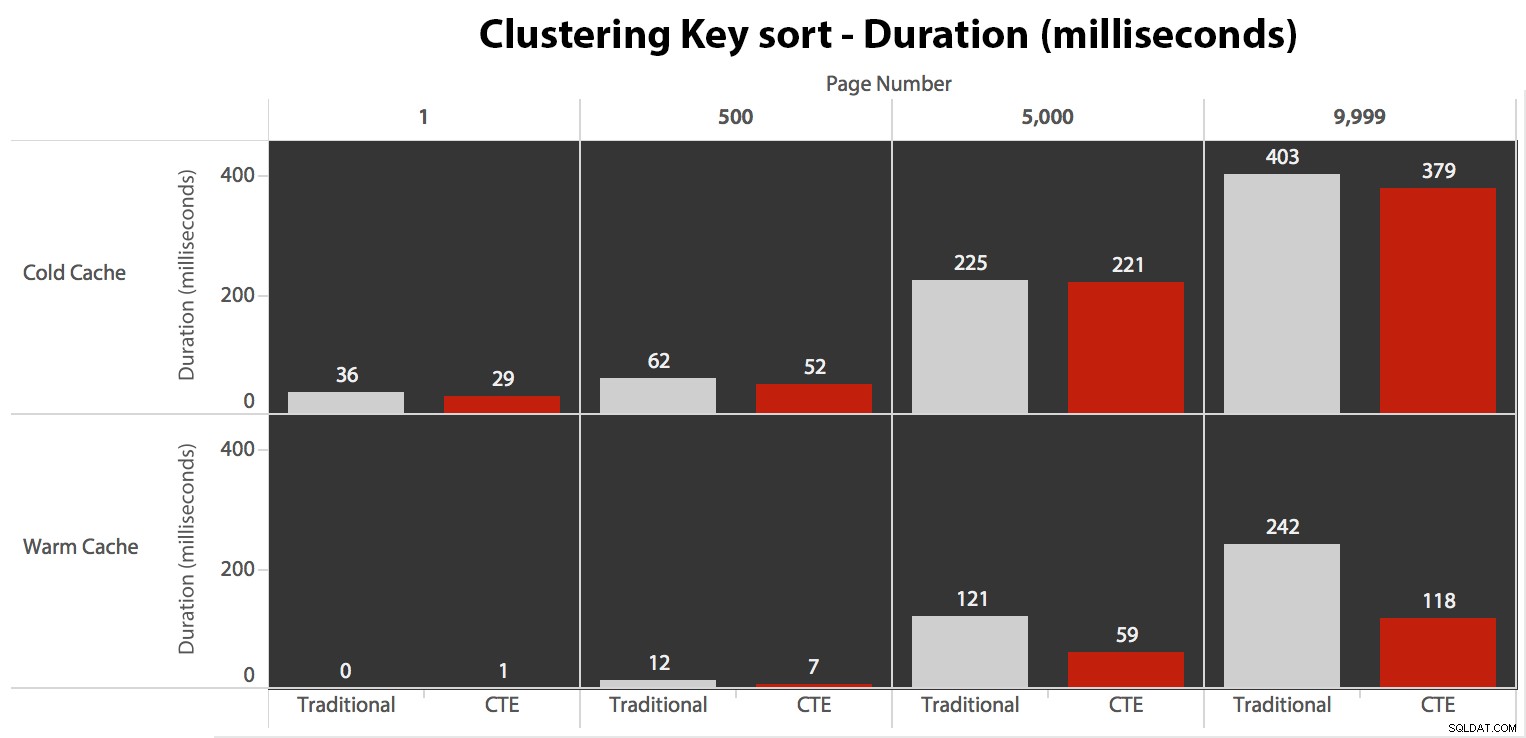
Til sidst varighederne:
Den traditionelle tilgang viser et meget tydeligt opsving i varigheden, når du marcherer mod slutningen af pagineringen. CTE-tilgangen viser også et ikke-lineært mønster, men det er langt mindre udtalt og giver bedre timing ved hvert sidetal. Vi ser 117 millisekunder for den næstsidste side, i forhold til den traditionelle tilgang, der kommer ind på næsten to sekunder.
Test den brugerdefinerede sortering
Til sidst ændrede jeg forespørgslen til at bruge Test_3 lagrede procedurer, test af tilfældet, hvor sorteringen blev defineret af brugeren og ikke havde et understøttende indeks. I/O var konsistent på tværs af hvert sæt af tests; grafen er så uinteressant, jeg vil lige linke til den. Lang historie kort:der var lidt over 19.000 læsninger i alle tests. Årsagen er, at hver enkelt variant skulle udføre en fuld scanning på grund af manglen på et indeks til at understøtte bestillingen. Her er planen for den traditionelle tilgang:
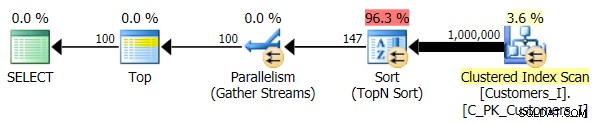
Og mens planen for CTE-versionen af forespørgslen ser alarmerende mere kompleks ud...
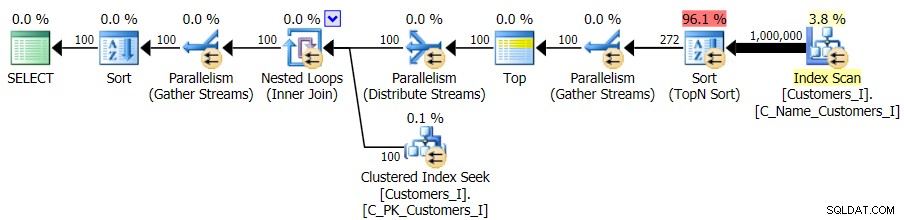
…det fører til kortere varigheder i alle tilfælde undtagen ét. Her er varighederne:
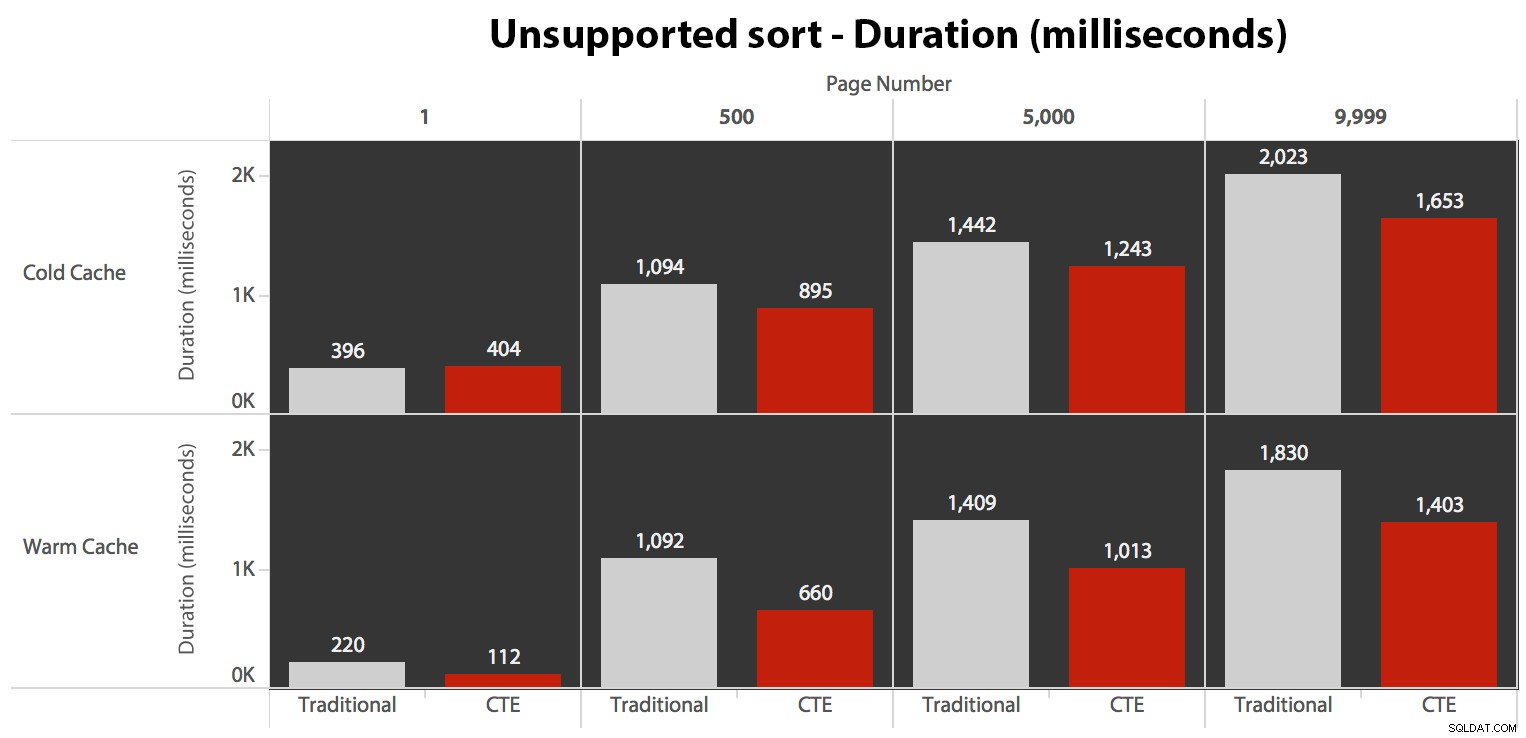
Du kan se, at vi ikke kan få lineær ydeevne her ved brug af nogen af metoderne, men CTE kommer ud i toppen med en god margin (alt fra 16 % til 65 % bedre) i hvert enkelt tilfælde undtagen den kolde cache-forespørgsel mod den første side (hvor den tabte med hele 8 millisekunder). Også interessant at bemærke, at den traditionelle metode overhovedet ikke er hjulpet meget af en varm cache i "midten" (side 500 og 5000); først mod slutningen af sættet er enhver effektivitet værd at nævne.
Højere lydstyrke
Efter individuel test af nogle få eksekveringer og at tage gennemsnit, tænkte jeg, at det også ville give mening at teste en stor mængde transaktioner, der i nogen grad ville simulere reel trafik på et travlt system. Så jeg oprettede et job med 6 trin, et for hver kombination af forespørgselsmetode (traditionel personsøgning vs. CTE) og sorteringstype (klyngenøgle, telefonbog og ikke-understøttet), med en 100-trins sekvens af at ramme de fire sidetal ovenfor , 10 gange hver, og 60 andre sidetal valgt tilfældigt (men det samme for hvert trin). Sådan genererede jeg jobskabelsesscriptet:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Her er den resulterende jobtrinliste og en af trinnets egenskaber:
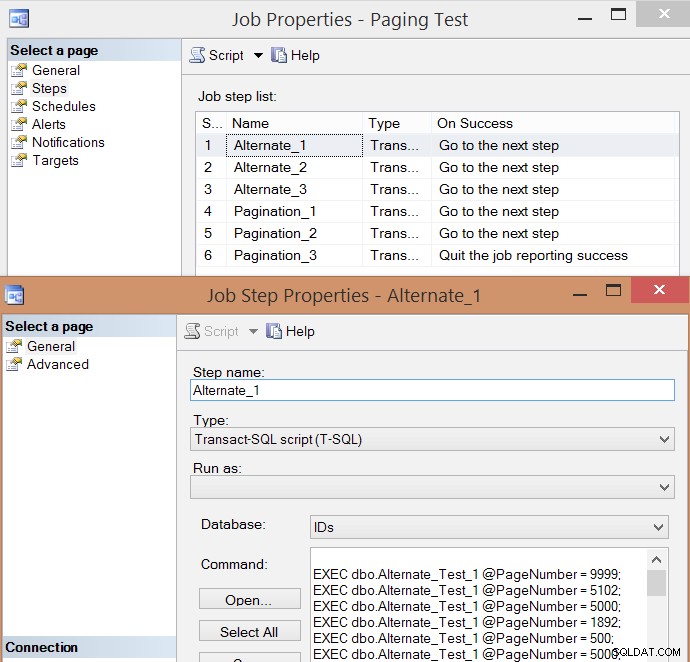
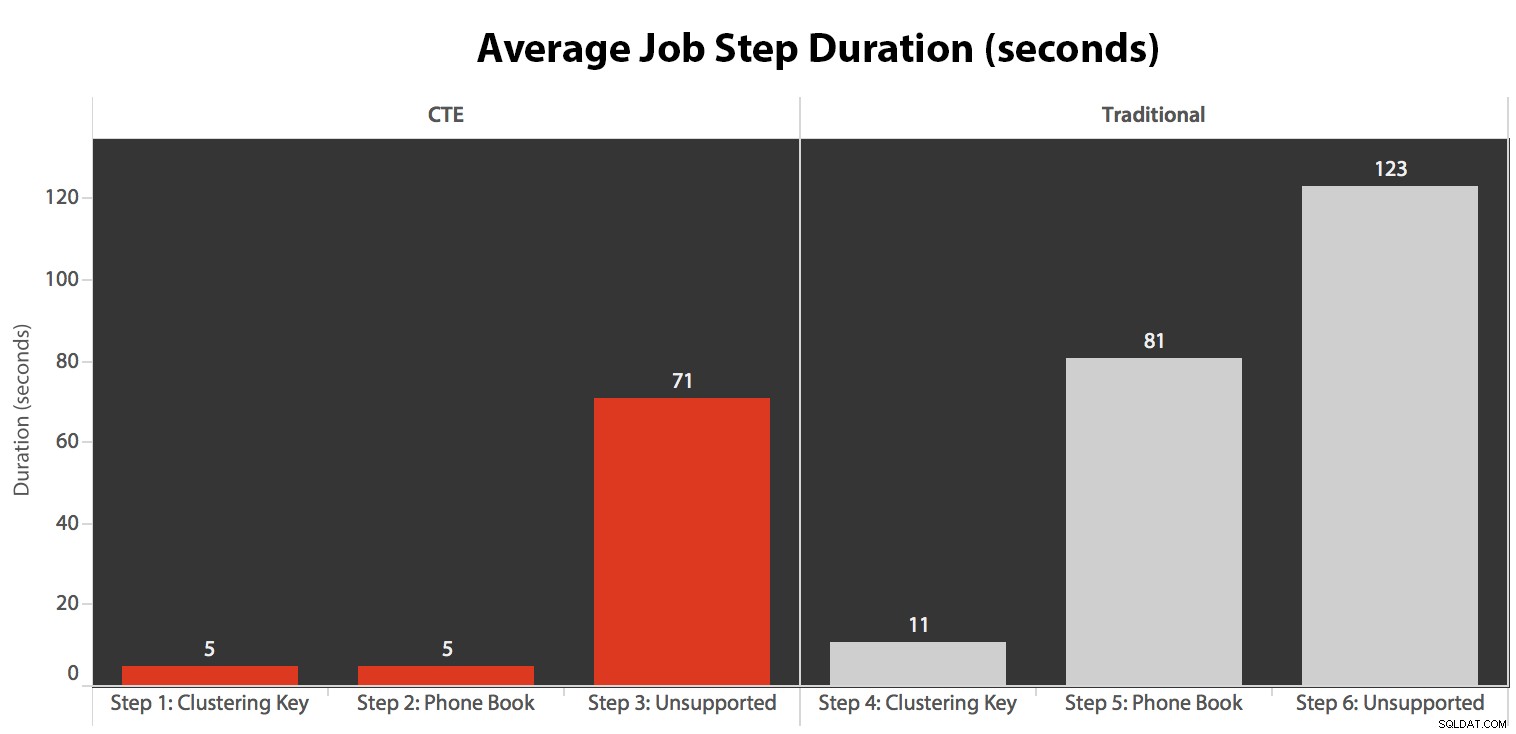
Jeg kørte jobbet fem gange, gennemgik derefter jobhistorikken, og her var de gennemsnitlige køretider for hvert trin:
Jeg korrelerede også en af udførelserne på SQL Sentry Event Manager-kalenderen...
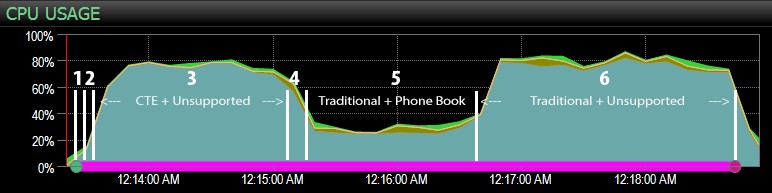
…med SQL Sentry-dashboardet og manuelt markeret nogenlunde, hvor hvert af de seks trin kørte. Her er CPU-brugsdiagrammet fra Windows-siden af dashboardet:
Og fra SQL Server-siden af dashboardet var de interessante målinger i nøgleopslags- og ventegraferne:
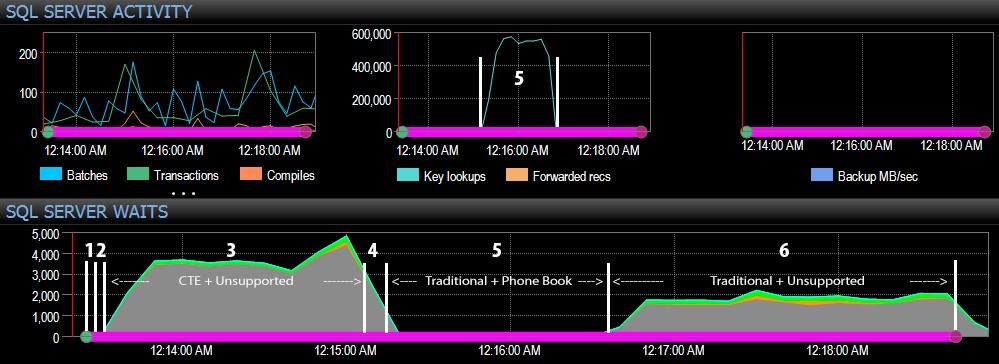
De mest interessante observationer bare fra et rent visuelt perspektiv:
- CPU'en er ret varm, omkring 80 %, under trin 3 (CTE + intet understøttende indeks) og trin 6 (traditionelt + intet understøttende indeks);
- CXPACKET ventetider er relativt høje under trin 3 og i mindre grad under trin 6;
- du kan se det massive spring i nøgleopslag, til næsten 600.000, på omkring et minuts tidsrum (i forhold til trin 5 – den traditionelle tilgang med et telefonbogslignende indeks).
I en fremtidig test – som med mit tidligere indlæg om GUID’er – vil jeg gerne teste dette på et system, hvor dataene ikke passer ind i hukommelsen (nemme at simulere), og hvor diskene er langsomme (ikke så lette at simulere) , da nogle af disse resultater sandsynligvis drager fordel af ting, som ikke alle produktionssystemer har – hurtige diske og tilstrækkelig RAM. Jeg bør også udvide testene til at omfatte flere variationer (ved at bruge tynde og brede kolonner, tynde og brede indekser, et telefonbogsindeks, der faktisk dækker alle outputkolonner, og sortering i begge retninger). Scope creep begrænsede absolut omfanget af min test til dette første sæt af tests.
Sådan forbedres SQL Server-paginering
Sideinddeling behøver ikke altid at være smertefuldt; SQL Server 2012 gør bestemt syntaksen nemmere, men hvis du bare tilslutter den native syntaks, vil du måske ikke altid se en stor fordel. Her har jeg vist, at lidt mere udførlig syntaks ved at bruge en CTE kan føre til meget bedre ydeevne i bedste fald, og uden tvivl ubetydelige ydeevneforskelle i værste tilfælde. Ved at adskille dataplacering fra datahentning i to forskellige trin, kan vi se en enorm fordel i nogle scenarier, uden for højere CXPACKET-venter i ét tilfælde (og selv da sluttede de parallelle forespørgsler hurtigere end de andre forespørgsler, der viste få eller ingen ventetider, så det var usandsynligt, at de ville være den "dårlige" CXPACKET venter, som alle advarer dig om).
Alligevel er selv den hurtigere metode langsom, når der ikke er noget understøttende indeks. Selvom du kan blive fristet til at implementere et indeks for enhver mulig sorteringsalgoritme, en bruger måtte vælge, kan du overveje at give færre muligheder (da vi alle ved, at indekser ikke er gratis). For eksempel, skal din applikation absolut understøtte sortering efter Efternavn stigende *og* Efternavn faldende? Hvis de vil gå direkte til de kunder, hvis efternavn starter med Z, kan de så ikke gå til *sidste* side og arbejde baglæns? Det er en forretnings- og brugervenlighedsbeslutning mere end en teknisk, bare behold den som en mulighed, før du slår indekser på hver sorteringskolonne i begge retninger for at få den bedste ydeevne for selv de mest uklare sorteringsmuligheder.