Når brugere anmoder om data fra et system, vil de normalt gerne se dem i en bestemt rækkefølge... selv når de returnerer tusindvis af rækker. Som mange DBA'er og udviklere ved, kan ORDER BY indføre kaos i en forespørgselsplan, fordi det kræver, at dataene sorteres. Dette kan nogle gange kræve en SORT-operatør som en del af udførelse af forespørgsler, hvilket kan være en dyr operation, især hvis estimater er slået fra, og det spildes til disken. I en ideel verden er dataene allerede sorteret takket være et indeks (indekser og sorteringer er meget komplementære). Vi taler ofte om at oprette et dækkende indeks for at tilfredsstille en forespørgsel – så optimeringsværktøjet ikke behøver at gå tilbage til basistabellen eller klyngeindekset for at få yderligere kolonner. Og du har måske hørt folk sige, at rækkefølgen af kolonnerne i indekset har betydning. Har du nogensinde overvejet, hvordan det påvirker dine SORT-operationer?
Undersøgelse af ORDER BY og sorteringer
Vi starter med en ny kopi af AdventureWorks2014-databasen på en SQL Server 2014-instans (version 12.0.2000). Hvis vi kører en simpel SELECT-forespørgsel mod Sales.SalesOrderHeader uden ORDER BY, ser vi en almindelig gammel Clustered Index Scan (ved hjælp af SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Forespørgsel uden ORDER BY, klynget indeksscanning
Forespørgsel uden ORDER BY, klynget indeksscanning
Lad os nu tilføje en BESTIL EFTER for at se, hvordan planen ændrer sig:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
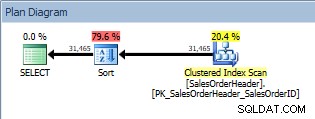 Forespørgsel med en ORDER BY, klynget indeksscanning og en sortering
Forespørgsel med en ORDER BY, klynget indeksscanning og en sortering
Ud over Clustered Index Scan har vi nu en sortering introduceret af optimizeren, og dens estimerede omkostninger er væsentligt højere end scanningen. Nu er estimerede omkostninger kun estimeret, og vi kan ikke med absolut sikkerhed sige her, at Sorten tog 79,6% af omkostningerne ved forespørgslen. For virkelig at forstå, hvor dyrt sorten er, skal vi også se på IO STATISTICS, hvilket er ud over dagens mål.
Hvis dette nu var en forespørgsel, der blev udført ofte i dit miljø, ville du sandsynligvis overveje at tilføje et indeks for at understøtte det. I dette tilfælde er der ingen WHERE-klausul, vi henter bare fire kolonner og sorterer efter en af dem. Et logisk første forsøg på et indeks ville være:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Vi kører vores forespørgsel igen efter at have tilføjet indekset, som har alle de kolonner, vi ønsker, og husk, at indekset har gjort arbejdet med at sortere dataene. Vi ser nu en indeksscanning mod vores nye ikke-klyngede indeks:
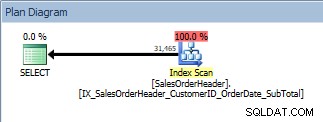 Forespørgsel med en ORDER BY, det nye, ikke-klyngede indeks scannes
Forespørgsel med en ORDER BY, det nye, ikke-klyngede indeks scannes
Det er gode nyheder. Men hvad sker der, hvis nogen ændrer denne forespørgsel – enten fordi brugere kan angive, hvilke kolonner de vil bestille efter, eller fordi en udvikler har anmodet om en ændring? For eksempel vil brugere måske gerne se kunde-id'erne og salgsordre-id'erne i faldende rækkefølge:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
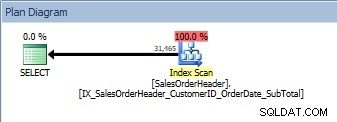 Forespørgsel med to kolonner i ORDER BY, det nye, ikke-klyngede indeks scannes
Forespørgsel med to kolonner i ORDER BY, det nye, ikke-klyngede indeks scannes
Vi har samme plan; ingen sorteringsoperator blev tilføjet. Hvis vi ser på indekset ved hjælp af Kimberly Tripps sp_helpindex (nogle kolonner er kollapset for at spare plads), kan vi se, hvorfor planen ikke blev ændret:
 Output af sp_helpindex
Output af sp_helpindex
Nøglekolonnen for indekset er CustomerID, men da SalesOrderID er nøglekolonnen for det klyngede indeks, er det også en del af indeksnøglen, således at data sorteres efter CustomerID, derefter SalesOrderID. Forespørgslen anmodede om data sorteret efter disse to kolonner i faldende rækkefølge. Indekset blev oprettet med begge kolonner stigende, men fordi det er en dobbelt-linket liste, kan indekset læses baglæns. Du kan se dette i ruden Egenskaber i Management Studio for den ikke-klyngede indeksscanningsoperator:
 Egenskabsruden i den ikke-klyngede indeksscanning, der viser, at den var baglæns
Egenskabsruden i den ikke-klyngede indeksscanning, der viser, at den var baglæns
Fantastisk, ingen problemer med den forespørgsel ... men hvad med denne:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
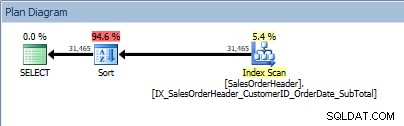 Forespørgsel med to kolonner i ORDER BY, og en sortering tilføjes
Forespørgsel med to kolonner i ORDER BY, og en sortering tilføjes
Vores SORT-operatør dukker op igen, fordi de data, der kommer fra indekset, ikke er sorteret i den ønskede rækkefølge. Vi vil se den samme adfærd, hvis vi sorterer på en af de inkluderede kolonner:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
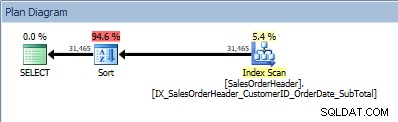 Forespørgsel med to kolonner i ORDER BY, og en sortering tilføjes
Forespørgsel med to kolonner i ORDER BY, og en sortering tilføjes
Hvad sker der, hvis vi (endelig) tilføjer et prædikat og ændrer vores ORDER BY lidt?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
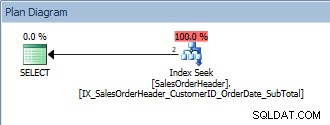 Forespørgsel med et enkelt prædikat og et ORDER BY
Forespørgsel med et enkelt prædikat og et ORDER BY
Denne forespørgsel er ok, fordi SalesOrderID igen er en del af indeksnøglen. For dette ene KundeID er dataene allerede bestilt af SalesOrderID. Hvad hvis vi forespørger efter en række kunde-id'er, sorteret efter SalesOrderID'er?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
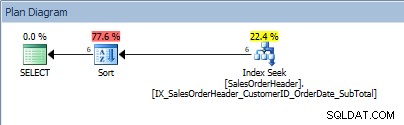 Forespørgsel med en række værdier i prædikatet og en ORDER BY
Forespørgsel med en række værdier i prædikatet og en ORDER BY
Rotter, vores SORT er tilbage. Det faktum, at dataene er bestilt af CustomerID, hjælper kun med at søge indekset for at finde det område af værdier; for ORDER BY SalesOrderID skal optimeringsværktøjet indskyde sorteringen for at placere dataene i den anmodede rækkefølge.
Nu på dette tidspunkt undrer du dig måske over, hvorfor jeg er fikseret på sorteringsoperatoren, der vises i forespørgselsplaner. Det er fordi det er dyrt. Det kan være dyrt med hensyn til ressourcer (hukommelse, IO) og/eller varighed.
Forespørgselsvarighed kan blive påvirket af en sortering, fordi det er en stop-and-go-handling. Hele datasættet skal sorteres, før den næste operation i planen kan finde sted. Hvis der kun skal bestilles nogle få rækker af data, er det ikke så stor en sag. Hvis det er tusinder eller millioner af rækker? Nu venter vi.
Ud over den overordnede forespørgselsvarighed skal vi også tænke på ressourceforbrug. Lad os tage de 31.465 rækker, vi har arbejdet med, og skubbe dem ind i en tabelvariabel, og derefter køre den første forespørgsel med ORDER BY på kunde-id:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
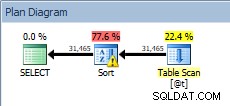 Forespørgsel mod tabelvariablen med sorteringen
Forespørgsel mod tabelvariablen med sorteringen
Vores SORT er tilbage, og denne gang har den en advarsel (bemærk den gule trekant med udråbstegn). Advarsler er ikke gode. Hvis vi ser på egenskaberne af den slags, kan vi se en advarsel, "Operatøren brugte tempdb til at spilde data under udførelse med spildniveau 1":
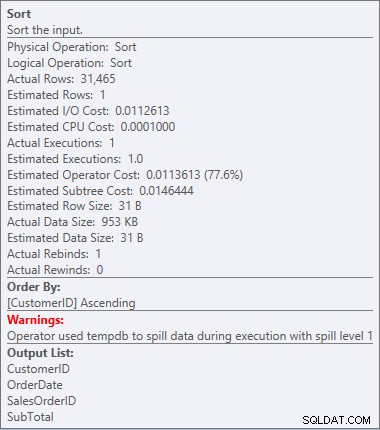 Sorteringsadvarsel
Sorteringsadvarsel
Det er ikke noget, jeg ønsker at se i en plan. Optimizeren lavede et skøn over, hvor meget plads den ville bruge i hukommelsen for at sortere dataene, og den anmodede om den hukommelse. Men da den faktisk havde alle data og gik for at sortere dem, indså motoren, at der ikke var nok hukommelse (optimeringsværktøjet bad om for lidt!), så sorteringsoperationen spildte. I nogle tilfælde kan dette spilde til disken, hvilket betyder læsning og skrivning - som er langsom. Ikke alene venter vi bare på at få styr på dataene, det er endnu langsommere, fordi vi ikke kan gøre det hele i hukommelsen. Hvorfor bad optimizeren ikke om nok hukommelse? Den havde et dårligt skøn over de data, den skulle bruge til at sortere:
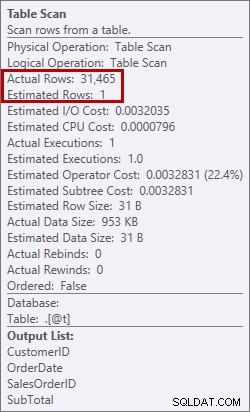 Estimering af 1 række versus faktisk på 31.465 rækker
Estimering af 1 række versus faktisk på 31.465 rækker
I dette tilfælde fremtvang jeg et dårligt skøn ved at bruge en tabelvariabel. Der er kendte problemer med statistikestimater og tabelvariable (Aaron Bertrand har et godt indlæg om muligheder for at forsøge at løse dette), og her mente optimeringsværktøjet, at kun 1 række ville blive returneret fra tabelscanningen, ikke 31.465.
Valgmuligheder
Så hvad kan du som DBA eller udvikler gøre for at undgå SORTERINGER i dine forespørgselsplaner? Det hurtige svar er:"Bestil ikke dine data." Men det er ikke altid realistisk. I nogle tilfælde kan du overføre denne sortering til klienten eller til et applikationslag – men brugerne skal stadig vente med at sortere dataene på denne lag. I de situationer, hvor du ikke kan ændre, hvordan applikationen fungerer, kan du starte med at se på dine indekser.
Hvis du understøtter en applikation, der giver brugerne mulighed for at køre ad-hoc-forespørgsler eller ændre sorteringsrækkefølgen, så de kan se dataene ordnet, som de vil, vil du have den sværeste tid (men det er ikke en tabt sag, så stop ikke med at læse endnu!). Du kan ikke indeksere for hver mulighed. Det er ineffektivt, og du vil skabe flere problemer, end du løser. Dit bedste bud her er at tale med brugerne (jeg ved godt, nogle gange er det skræmmende at forlade dit hjørne af skoven, men prøv det). For de forespørgsler, brugerne kører oftest, skal du finde ud af, hvordan de typisk kan lide at se dataene. Ja, du kan også få dette fra planens cache – du kan hente forespørgsler og planer, indtil du er glad for at se, hvad de laver. Men det er hurtigere at tale med brugerne. Den ekstra fordel er, at du kan forklare, hvorfor du spørger, og hvorfor den idé at "sortere på alle kolonnerne, fordi jeg kan" ikke er så god. At vide er halvdelen af kampen. Hvis du kan bruge lidt tid på at uddanne dine superbrugere og de brugere, der træner nye mennesker, kan du måske gøre noget godt.
Hvis du understøtter en applikation med begrænsede ORDER BY-muligheder, kan du lave nogle reelle analyser. Gennemgå, hvilke ORDER BY-varianter der findes, afgør, hvilke kombinationer der udføres oftest, og indekser for at understøtte disse forespørgsler. Du vil sandsynligvis ikke ramme alle, men du kan stadig få indflydelse. Du kan tage det et skridt videre ved at tale med dine udviklere og oplyse dem om problemet, og hvordan man løser det.
Endelig, når du ser på forespørgselsplaner med SORT-operationer, skal du ikke bare fokusere på at fjerne sorteringen. Se på hvor sorteringen sker i planen. Hvis det sker langt til venstre for planen, og er typisk nogle få rækker, kan der være andre områder med en større forbedringsfaktor at fokusere på. Sorteringen til venstre er det mønster, vi fokuserede på i dag, men en sortering forekommer ikke altid på grund af en ORDER BY. Hvis du ser en sortering yderst til højre i planen, og der er mange rækker, der bevæger sig gennem den del af planen, ved du, at du har fundet et godt sted at begynde at tune.