Alle mine indlæg i år har handlet om knæfald på ventestatistikker, men i dette indlæg afviger jeg fra det tema for at tale om en bestemt fejlbjørn af mig:sidetælleren for forventet levetid (som jeg vil kalde PLE) ).
Hvad betyder PLE?
Der er alle mulige slags forkerte udsagn om forventet sidelevetid derude på internettet, og de mest uhyggelige er dem, der angiver, at værdien 300 er tærsklen for, hvor du skal være bekymret.
For at forstå, hvorfor denne udtalelse er så misvisende, skal du forstå, hvad PLE faktisk er.
Definitionen af PLE er den forventede tid i sekunder, som en datafilside læst ind i bufferpuljen (cachen i hukommelsen af datafilsider) vil forblive i hukommelsen, før den skubbes ud af hukommelsen for at give plads til en anden data fil side. En anden måde at tænke PLE på er et øjeblikkeligt mål for trykket på bufferpuljen for at gøre ledig plads til sider, der læses fra disken. For begge disse definitioner er et højere tal bedre.
Hvad er en god PLE-tærskel?
En PLE på 300 betyder, at hele din bufferpulje bliver effektivt skyllet ud og genlæses hvert femte minut. Da tærskelvejledningen for PLE på 300 første gang blev givet af Microsoft, omkring 2005/2006, kan det tal have givet mere mening, da den gennemsnitlige mængde hukommelse på en server var meget lavere.
I dag, hvor servere rutinemæssigt har 64 GB, 128 GB og større mængder hukommelse, vil det sandsynligvis være årsagen til et ødelæggende ydelsesproblem at have nogenlunde så mange data, der læses fra disken hvert femte minut.
I virkeligheden, når PLE svæver på eller under 300, er din server allerede i alvorlige vanskeligheder. Du ville begynde at være bekymret, langt før PLE er så lav.
Så hvad er tærsklen til at bruge, når du skal være bekymret?
Nå, det er bare pointen. Jeg kan ikke give dig en tærskel, da det tal vil variere for alle. Hvis du virkelig vil have et nummer at bruge, kom min kollega Jonathan Kehayias med en formel:
( Buffer pool hukommelse i GB / 4 ) x 300Selv det tal er noget vilkårligt, og dit kilometertal vil variere.
Jeg kan ikke lide at anbefale nogen tal. Mit råd er, at du måler din PLE, når ydeevnen er på det ønskede niveau – det er den tærskel, du bruger.
Så begynder du at bekymre dig, så snart PLE falder under den tærskel? Nej. Du begynder at bekymre dig, når PLE falder under denne tærskel og forbliver under denne tærskel, eller hvis den falder brat, og du ved ikke hvorfor.
Dette skyldes, at der er nogle operationer, der vil forårsage et PLE-fald (f.eks. at køre DBCC CHECKDB eller indeksgenopbygninger kan gøre det nogle gange) og giver ikke anledning til bekymring. Men hvis du ser et stort PLE-fald, og du ikke ved, hvad der forårsager det, er det, du skal være bekymret.
Du undrer dig måske over, hvordan DBCC CHECKDB kan forårsage et PLE-fald, når det gør ugunst og prøver hårdt på at undgå at skylle bufferpuljen med de data, den bruger (se dette blogindlæg for en forklaring). Det skyldes, at forespørgselsudførelseshukommelsen tildeles for DBCC CHECKDB er fejlberegnet af Query Optimizer og kan forårsage en stor reduktion i størrelsen af bufferpuljen (hukommelsen til bevillingen er stjålet fra bufferpuljen) og et deraf følgende fald i PLE.
Hvordan overvåger du PLE?
Det her er det vanskelige. De fleste mennesker vil gå direkte til Buffer Manager performance-objekt i PerfMon og overvåg Page life expectancy tæller. Er dette den rigtige tilgang? Mest sandsynligt ikke.
Jeg vil sige, at et stort flertal af servere derude i dag bruger NUMA-arkitektur, og dette har en dybtgående effekt på, hvordan du overvåger PLE.
Når NUMA er involveret, opdeles bufferpuljen i bufferknudepunkter, med én bufferknude pr. NUMA-knude, som SQL Server kan ’se’. Hver bufferknude sporer PLE separat og Buffer Manager:Page life expectancy tæller er gennemsnittet af bufferknudepunktets PLE'er. Hvis du bare overvåger den overordnede bufferpulje PLE, så kan trykket på en af bufferknuderne være maskeret af gennemsnittet (jeg diskuterer dette i et blogindlæg her).
Så hvis din server bruger NUMA, er du nødt til at overvåge den individuelle Buffer Node:Page life expectancy tællere (der vil være ét Buffer Node-performanceobjekt for hver NUMA-node), ellers er du god til at overvåge Buffer Manager:Page life expectancy tæller.
Endnu bedre er det at bruge et overvågningsværktøj som SQL Sentry Performance Advisor, som viser denne tæller som en del af dashboardet under hensyntagen til NUMA-knuderne på serveren og giver dig mulighed for nemt at konfigurere advarsler.
Eksempler på brug af Performance Advisor
Nedenfor er et eksempel på en skærmoptagelse fra Performance Advisor for et system med en enkelt NUMA-node:
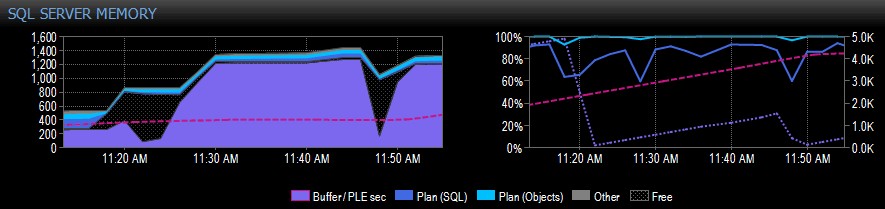
På højre side af optagelsen er den lyserøde stiplede linje PLE mellem kl. 10.30 og omkring 11.20 - det stiger støt op til 5.000 eller deromkring, et rigtig sundt tal. Lige før klokken 11.20 er der et kæmpe fald, og så begynder det at stige igen indtil klokken 11.45, hvor det falder igen.
Dette er typisk, hvad du vil se, hvis bufferpuljen er fuld, med alle siderne brugt, og så kører en forespørgsel, der får en enorm mængde forskellige data til at blive læst fra disken, hvilket fortrænger meget af det, der allerede er i hukommelsen og forårsager en brat fald i PLE. Hvis du ikke vidste, hvad der forårsagede noget som dette, ville du gerne undersøge det, som jeg beskriver længere nede.
Som et andet eksempel er skærmbilledet nedenfor fra en af vores Remote DBA-klienter, hvor serveren har to NUMA-noder (du kan se, at der er to lilla PLE-linjer), og hvor vi bruger Performance Advisor i udstrakt grad:

På denne klients server starter der hver morgen omkring kl. 05.00 et indeksvedligeholdelses- og konsistenstjekjob, der får PLE til at falde i begge bufferknuder. Dette er forventet adfærd, så der er ingen grund til at undersøge det, så længe PLE stiger op igen i løbet af dagen.
Hvad kan du gøre ved at droppe PLE?
Hvis årsagen til PLE-faldet ikke er kendt, kan du gøre en række ting:
- Hvis problemet opstår nu, skal du undersøge, hvilke forespørgsler der forårsager læsninger ved at bruge
sys.dm_os_waiting_tasksDMV for at se hvilke tråde, der venter på, at sider bliver læst fra disken (dvs. dem, der venter påPAGEIOLATCH_SH), og ret derefter disse forespørgsler. - Hvis problemet er opstået tidligere, skal du se i sys.dm_exec_query_stats DMV for forespørgsler med et stort antal fysiske læsninger eller bruge et overvågningsværktøj, der kan give dig disse oplysninger (f.eks. Top SQL-visningen i Performance Advisor), og ret så disse forespørgsler.
- Korrelér PLE-faldet med planlagte agentjob, der udfører databasevedligeholdelse.
- Søg efter forespørgsler med meget store hukommelsesbevillinger til udførelse af forespørgsler ved hjælp af
sys.dm_exec_query_memory_grantsDMV, og reparer derefter disse forespørgsler.
Mit tidligere indlæg her forklarer mere om #1 og #2, og et script til at undersøge ventetider på en server og link til deres forespørgselsplaner er her.
"Løs disse forespørgsler" er uden for rammerne af dette indlæg, så jeg lader det ligge til en anden gang eller som en øvelse for læseren ☺
Oversigt
Gå ikke i fælden med at tro på en anbefalet PLE-tærskel, som du måske læser online. Den bedste måde at reagere på PLE-ændringer på er, når PLE falder til under din komfortniveauet er og bliver der – det er indikationen af et præstationsproblem, som du bør undersøge.
I den næste artikel i serien vil jeg diskutere en anden almindelig årsag til knæstød præstationsjustering. Indtil da, god fejlfinding!