En af de mange forbedringer af eksekveringsplanen i SQL Server 2012 var tilføjelsen af trådreservation og brugsinformation til parallelle eksekveringsplaner. Dette indlæg ser på præcis, hvad disse tal betyder, og giver yderligere indsigt i at forstå parallel eksekvering.
Overvej at følgende forespørgsel køres mod en forstørret version af AdventureWorks-databasen:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Forespørgselsoptimeringsværktøjet vælger en parallel eksekveringsplan:
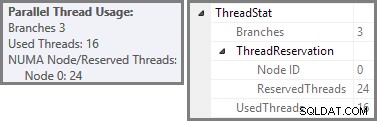
Plan Explorer viser parallelle trådbrugsdetaljer i rodknudeværktøjstip. For at se de samme oplysninger i SSMS skal du klikke på planens rodknude, åbne vinduet Egenskaber og udvide ThreadStat node. Ved at bruge en maskine med otte logiske processorer, der er tilgængelige for SQL Server at bruge, vises trådbrugsoplysningerne fra en typisk kørsel af denne forespørgsel nedenfor, Plan Explorer til venstre, SSMS-visning til højre:
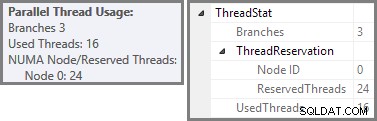
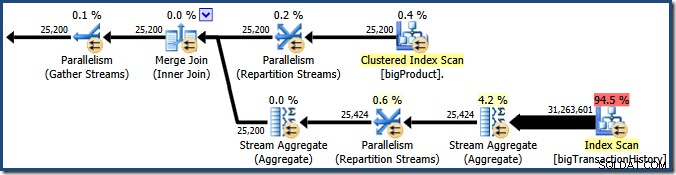
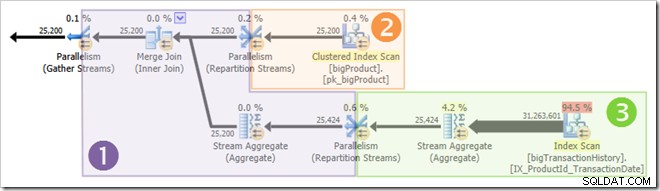
Skærmbilledet viser udførelsesmotoren, der reserverede 24 tråde til denne forespørgsel, og afsluttede med 16 af dem. Det viser også, at forespørgselsplanen har tre grene , selvom det ikke præcist siger, hvad en gren er. Hvis du har læst min Simple Talk-artikel om udførelse af parallel forespørgsel, vil du vide, at grene er sektioner af en parallel forespørgselsplan afgrænset af udvekslingsoperatører. Diagrammet nedenfor tegner grænserne og nummererer grenene (klik for at forstørre):

Gren 2 (orange)
Lad os først se lidt mere detaljeret på gren to:
Ved en grad af parallelisme (DOP) på otte er der otte tråde, der kører denne gren af forespørgselsplanen. Det er vigtigt at forstå, at dette er hele udførelsesplanen for så vidt angår disse otte tråde – de har intet kendskab til den bredere plan.
I en seriel eksekveringsplan læser en enkelt tråd data fra en datakilde, behandler rækkerne gennem en række planoperatorer og returnerer resultater til destinationen (som for eksempel kan være et SSMS-forespørgselsresultatvindue eller en databasetabel).
I en filial i en parallel eksekveringsplan er situationen meget ens:hver tråd læser data fra en kilde, behandler rækkerne gennem en række planoperatører og returnerer resultater til destinationen. Forskellene er, at destinationen er en udvekslingsoperatør (parallelisme), og datakilden kan også være en udveksling.
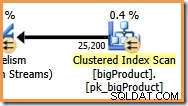
I den orange gren er datakilden en Clustered Index Scan, og destinationen er højre side af en Repartition Streams-udveksling. Den højre side af en børs er kendt som producentsiden , fordi den forbinder til en filial, der tilføjer data til centralen.
De otte tråde i den orange gren samarbejder om at scanne tabellen og tilføje rækker til udvekslingen. Udvekslingen samler rækker til pakker i sidestørrelse. Når en pakke er fuld, skubbes den hen over centralen til den anden side. Hvis udvekslingen har en anden tom pakke tilgængelig at udfylde, fortsætter processen, indtil alle datakilderækker er blevet behandlet (eller udvekslingen løber tør for tomme pakker).
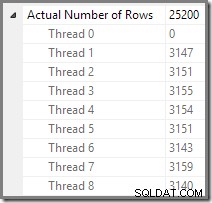
Vi kan se antallet af rækker, der er behandlet på hver tråd ved at bruge Plan Tree-visningen i Plan Explorer:
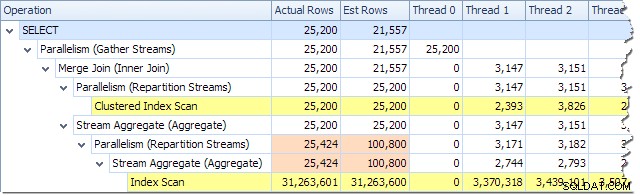
Plan Explorer gør det nemt at se, hvordan rækker er fordelt på tværs af tråde for alle de fysiske operationer i planen. I SSMS er du begrænset til at se rækkefordeling for en enkelt planoperatør. For at gøre dette skal du klikke på et operatørikon, åbne vinduet Egenskaber og derefter udvide noden Faktisk antal rækker. Grafikken nedenfor viser SSMS-information for Repartition Streams-knuden ved grænsen mellem den orange og lilla gren:
Afdeling tre (grøn)
Gren tre ligner gren to, men den indeholder en ekstra Stream Aggregate-operator. Den grønne gren har også otte tråde, hvilket gør i alt seksten set indtil videre. De otte grønne grentråde læser data fra en ikke-klynget indeksscanning, udfører en form for aggregering og sender resultaterne til producentsiden af en anden Repartition Streams-børs.
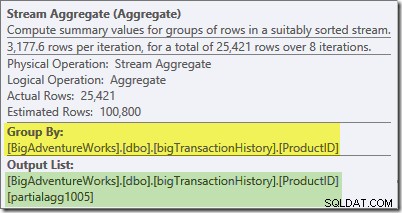
Plan Explorer-værktøjstip til Stream Aggregate viser, at det grupperes efter produkt-id og beregner et udtryk mærket partialagg1005 :
Fanen Udtryk viser, at udtrykket er resultatet af at tælle rækkerne i hver gruppe:

Streamaggregatet beregner en delvis (også kendt som 'lokal') aggregat. Den delvise (eller lokale) kvalifikation betyder simpelthen, at hver tråd beregner aggregatet på de rækker, den ser. Rækker fra indeksscanningen fordeles mellem tråde ved hjælp af en efterspørgselsbaseret ordning:der er ingen fast fordeling af rækker før tid; tråde modtager en række rækker fra scanningen, når de spørger efter dem. Hvilke rækker der ender på hvilke tråde er i det væsentlige tilfældigt, fordi det afhænger af timingproblemer og andre faktorer.
Hver tråd ser forskellige rækker fra scanningen, men rækker med samme produkt-id kan ses af mere end én tråd. Samlingen er 'delvis', fordi subtotaler for en bestemt produkt-id-gruppe kan vises på mere end én tråd; den er 'lokal', fordi hver tråd beregner sit resultat kun baseret på de rækker, den tilfældigvis modtager. Lad os f.eks. sige, at der er 1.000 rækker for produkt-id #1 i tabellen. En tråd kan tilfældigvis se 432 af disse rækker, mens en anden kan se 568. Begge tråde vil have en delvis antal rækker for produkt ID #1 (432 i den ene tråd, 568 i den anden).
Delvis aggregering er en ydeevneoptimering, fordi den reducerer rækkeantallet tidligere, end det ellers ville være muligt. I den grønne gren resulterer tidlig aggregering i, at færre rækker samles til pakker og skubbes hen over Repartition Stream-udvekslingen.
Gren 1 (lilla)

Den lilla gren har otte flere tråde, hvilket er fireogtyve indtil videre. Hver tråd i denne gren læser rækker fra de to Repartition Streams-udvekslinger og skriver rækker til en Gather Streams-udveksling. Denne gren kan virke kompliceret og ukendt, men den læser bare rækker fra en datakilde og sender resultater til en destination, ligesom enhver anden forespørgselsplan.
Den højre side af planen viser data, der læses fra den anden side af de to Repartition Streams-udvekslinger set i de orange og grønne grene. Denne (venstre) side af børsen er kendt som forbrugeren side, fordi tråde, der er knyttet her, er læse- (forbrugende) rækker. De otte lilla grentråde er forbrugere af data på de to Repartition Streams-udvekslinger.
Den venstre side af den lilla gren viser rækker, der skrives til producenten siden af en Gather Streams-børs. De samme otte tråde (det er forbrugere på Repartition Streams-børserne) udfører en producer rolle her.
Hver tråd i den lilla gren kører hver operatør i grenen, ligesom en enkelt tråd udfører hver operation i en seriel udførelsesplan. Den største forskel er, at der er otte tråde, der kører samtidigt, som hver arbejder på en anden række på ethvert givet tidspunkt ved hjælp af forskellige forekomster af forespørgselsplanoperatørerne.
Streamaggregatet i denne gren er globalt samlet. Den kombinerer de delvise (lokale) aggregater beregnet i den grønne gren (husk eksemplet med en 432-tælling i den ene tråd og 568 i den anden) for at producere en kombineret total for hvert produkt-id. Værktøjstippet Plan Explorer viser det globale resultatudtryk, mærket Expr1004:
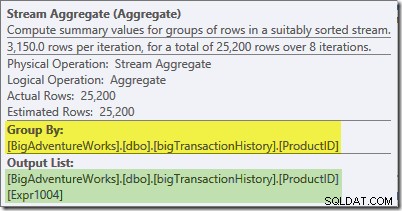
Det korrekte globale resultat pr. produkt-id beregnes ved at summere de delvise aggregater, som fanen Udtryk illustrerer:
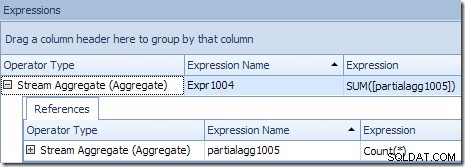
For at fortsætte vores (imaginære) eksempel opnås det korrekte resultat af 1.000 rækker for produkt ID #1 ved at summere de to subtotaler af 432 og 568.
Hver af de otte lilla grentråde læser data fra forbrugersiden af de to Gather Streams-udvekslinger, beregner de globale aggregater, udfører Merge Join på produkt-id'et og tilføjer rækker til Gather Streams-udvekslingen yderst til venstre i den lilla gren. Kerneprocessen er ikke meget anderledes end en almindelig serieplan; forskellene er i, hvor rækker læses fra, hvor de sendes til, og hvordan rækker er fordelt mellem trådene...
Exchange Row Distribution
Den opmærksomme læser vil undre sig over et par detaljer på dette tidspunkt. Hvordan formår den lilla gren at beregne korrekte resultater pr. produkt-id men den grønne gren kunne ikke (resultater for det samme produkt-id var spredt over mange tråde)? Hvis der er otte separate sammenføjninger (én pr. tråd), hvordan garanterer SQL Server, at rækker, der vil blive sammenføjet, ender i samme forekomst af tilslutningen?
Begge disse spørgsmål kan besvares ved at se på den måde, hvorpå de to Repartition Streams udveksler ruterækker fra producentsiden (i den grønne og orange gren) til forbrugersiden (i den lilla gren). Vi vil først se på Repartition Streams-udvekslingen, der grænser op til de orange og lilla grene:
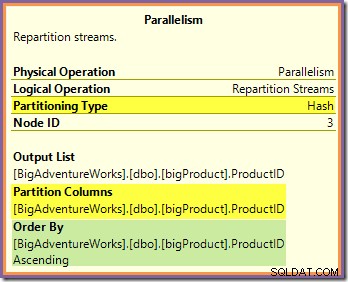
Denne udveksling dirigerer indkommende rækker (fra den orange gren) ved hjælp af en hash-funktion, der anvendes på produkt-id-kolonnen. Effekten er, at alle rækker for et bestemt produkt-id er garanteret skal føres til den samme lilla grentråd. De orange og lilla tråde kender intet til denne routing; alt dette håndteres internt af børsen.
Alle de orange tråde ved er, at de returnerer rækker til den overordnede iterator, der bad om dem (producentsiden af udvekslingen). Ligeledes er alle de lilla tråde 'ved', at de læser rækker fra en datakilde. Udvekslingen bestemmer, hvilken pakke en indgående orange-trådsrække vil gå ind i, og det kan være en hvilken som helst af otte kandidatpakker. På samme måde bestemmer udvekslingen, hvilken pakke der skal læses en række fra for at opfylde en læseanmodning fra en lilla tråd.
Pas på ikke at få et mentalt billede af en bestemt orange (producent) tråd, der er knyttet direkte til en bestemt lilla (forbruger) tråd. Det er ikke sådan denne forespørgselsplan fungerer. En appelsinproducent kan ender med at sende rækker til alle lilla forbrugere – ruten afhænger helt af værdien af produkt-id-kolonnen i hver række, den behandler.
Bemærk også, at en pakke med rækker på centralen kun overføres, når den er fuld (eller når producentsiden løber tør for data). Forestil dig udvekslingsfyldningspakkerne en række ad gangen, hvor rækker til en bestemt pakke kan komme fra en hvilken som helst af producentens (orange) tråde. Når en pakke er fuld, sendes den over til forbrugersiden, hvor en bestemt forbrugertråd (lilla) kan begynde at læse fra den.
Repartition Streams-udvekslingen, der grænser op til de grønne og lilla grene, fungerer på en meget lignende måde:
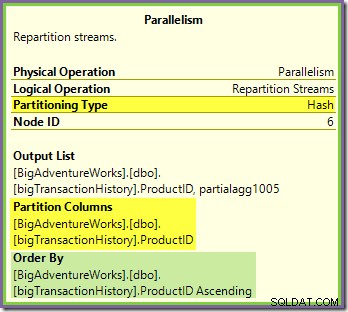
Rækker dirigeres til pakker i denne udveksling ved hjælp af samme hash-funktion på samme partitioneringskolonne hvad angår den orange-lilla udveksling set tidligere. Det betyder, at begge Repartition Streams udveksler ruterækker med det samme produkt-id til den samme lilla grentråd.
Dette forklarer, hvordan Stream Aggregate i den lilla gren er i stand til at beregne globale aggregater – hvis en række med et bestemt produkt-id ses på en bestemt lilla-grentråd, vil denne tråd garanteret se alle rækker for det produkt-id (og nej anden tråd vil).
Den fælles udvekslingspartitioneringskolonne er også join-nøglen for flette-join, så alle rækker, der muligvis kan joine, er garanteret behandlet af den samme (lilla) tråd.
En sidste ting at bemærke er, at begge udvekslinger er ordrebevarende (a.k.a 'sammensmeltning') udvekslinger, som vist i attributten Bestil efter i værktøjstip. Dette opfylder kravet om sammenføjning, at inputrækker skal sorteres på sammenføjningstasterne. Bemærk, at børser aldrig selv sorterer rækker, de kan blot konfigureres til at bevare eksisterende ordre.
Tråd nul
Den sidste del af udførelsesplanen ligger til venstre for Gather Streams-udvekslingen. Den kører altid på en enkelt tråd - den samme som bruges til at køre hele en almindelig serieplan. Denne tråd er altid mærket 'Tråd 0' i udførelsesplaner og kaldes nogle gange 'koordinator'-tråden (en betegnelse jeg ikke finder særlig nyttig).
Tråd nul læser rækker fra forbruger (venstre) side af Gather Streams-børsen og returnerer dem til klienten. Der er ingen tråd nul iteratorer bortset fra udvekslingen i dette eksempel, men hvis der var, ville de alle køre på den samme enkelt tråd. Bemærk, at Gather Streams også er en fusionsbørs (den har en Order By-attribut):

Mere komplekse parallelle planer kan omfatte andre serielle udførelseszoner end den til venstre for den endelige Gather Streams-udveksling. Disse serielle zoner køres ikke i tråd nul, men det er en detalje at udforske en anden gang.
Reserverede og brugte tråde besøgt igen
Vi har set, at denne parallelle plan indeholder tre grene. Dette forklarer, hvorfor SQL Server reserveret 24 tråde (tre grene ved DOP 8). Spørgsmålet er, hvorfor kun 16 tråde er rapporteret som 'brugte' i skærmbilledet ovenfor.
Der er to dele af svaret. Den første del gælder ikke for denne plan, men den er vigtig at vide om alligevel. Antallet af rapporterede filialer er det maksimale antal, der kan udføres samtidigt .
Som du måske ved, "blokerer" visse planoperatører - hvilket betyder, at de skal forbruge alle deres inputrækker, før de kan producere den første outputrække. Det tydeligste eksempel på en blokerende (også kendt som stop-and-go) operatør er Sorter. En sortering kan ikke returnere den første række i sorteret rækkefølge, før den har set hver inputrække, fordi den sidste inputrække måske sorterer først.
Operatører med flere indgange (forbindelser og foreninger, f.eks.) kan være blokerende med hensyn til én indgang, men ikke-blokerende ('pipelined') med hensyn til den anden. Et eksempel på dette er hash join – build-inputtet blokerer, men probe-input er pipelinet. Byg-inputtet blokerer, fordi det opretter hash-tabellen, som proberækkerne testes mod.
Tilstedeværelsen af blokerende operatører betyder, at en eller flere parallelle grene kan være garanteret at gennemføre, før andre kan begynde. Hvor dette sker, kan SQL Server genbruge de tråde, der bruges til at behandle en afsluttet gren til en senere gren i sekvensen. SQL Server er meget konservativ med hensyn til trådreservation, så kun grene der er garanteret at fuldføre, før en anden begynder, gør brug af denne trådreservationsoptimering. Vores forespørgselsplan indeholder ingen blokerende operatører, så det rapporterede filialantal er kun det samlede antal filialer.
Den anden del af svaret er, at tråde stadig kan genbruges, hvis de opstår at fuldføre før en tråd i en anden gren starter op. Det fulde antal tråde er stadig reserveret i dette tilfælde, men det faktiske forbrug kan være lavere. Hvor mange tråde en parallel plan faktisk bruger, afhænger blandt andet af timing-problemer og kan variere mellem udførelser.
Parallelle tråde begynder ikke alle at køre på samme tid, men igen må detaljerne heraf vente til en anden lejlighed. Lad os se på forespørgselsplanen igen for at se, hvordan tråde kan genbruges på trods af manglen på blokerende operatører:
Det er klart, at tråde i gren et ikke kan færdiggøre før tråde i grene to eller tre starter op, så der er ingen chance for trådgenbrug der. Gren tre er også usandsynlig at fuldføre før enten gren et eller gren to starter op, fordi den har så meget arbejde at gøre (næsten 32 millioner rækker at samle).
Afdeling to er en anden sag. Den relativt lille størrelse af produkttabellen betyder, at der er en anstændig chance for, at filialen kan fuldføre sit arbejde før gren tre starter op. Hvis læsning af produkttabellen ikke resulterer i nogen fysisk I/O, vil det ikke tage ret lang tid for otte tråde at læse de 25.200 rækker og sende dem til den orange-lilla grænse Repartition Streams-udveksling.
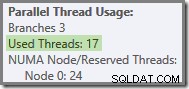
Det er præcis, hvad der skete i de testkørsler, der blev brugt til de skærmbilleder, der er set indtil videre i dette indlæg:De otte orange grentråde blev færdige hurtigt nok til, at de kunne genbruges til den grønne gren. I alt blev der brugt seksten unikke tråde, så det er, hvad udførelsesplanen beretter.
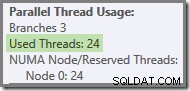
Hvis forespørgslen køres igen med en kold cache, er forsinkelsen introduceret af den fysiske I/O nok til at sikre, at grønne grentråde starter op, før nogen orange grentråde er afsluttet. Ingen tråde genbruges, så udførelsesplanen rapporterer, at alle 24 reserverede tråde faktisk blev brugt:
Mere generelt er et hvilket som helst antal 'brugte tråde' mellem de to yderpunkter (16 og 24 for denne forespørgselsplan) muligt:
Bemærk endelig, at tråden, der kører den serielle del af planen til venstre for de endelige Gather Streams, ikke tælles i de parallelle trådtotaler. Det er ikke en ekstra tråd tilføjet for at imødekomme parallel udførelse.
Sidste tanker
Det smukke ved den udvekslingsmodel, der bruges af SQL Server til at implementere parallel eksekvering, er, at al kompleksiteten ved buffering og flytning af rækker mellem tråde er skjult inde i udvekslingsoperatorer (parallelisme). Resten af planen er opdelt i pæne 'grene', afgrænset af udvekslinger. Inden for en filial opfører hver operatør sig på samme måde, som den gør i en serieplan – i næsten alle tilfælde har filialoperatørerne ingen viden om, at den bredere plan overhovedet bruger parallel udførelse.
Nøglen til at forstå parallel eksekvering er at (mentalt) bryde den parallelle plan fra hinanden ved udvekslingsgrænserne og at forestille sig hver gren som DOP-separat serie planer, der alle udfører samtidighed på et særskilt undersæt af rækker. Husk især, at hver sådan seriel plan kører alle operatørerne i den gren – SQL Server gør ikke køre hver operatør på sin egen tråd!
At forstå den mest detaljerede adfærd kræver en smule omtanke, især om hvordan rækker rutes inden for udvekslinger, og hvordan motoren garanterer korrekte resultater, men så kræver de fleste ting, der er værd at vide, en smule omtanke, ikke?