Det følgende er et uddrag fra vores hvidbog "Sådan designer du meget tilgængelige Open Source-databasemiljøer", som kan downloades gratis.
Et par ord om "Høj tilgængelighed"
I disse dage er høj tilgængelighed et must for enhver seriøs implementering. Længe forbi er dage, hvor du kunne planlægge en nedetid af din database i flere timer for at udføre en vedligeholdelse. Hvis dine tjenester ikke er tilgængelige, mister du kunder og penge. Derfor har det typisk en af de højeste prioriteter at gøre et databasemiljø yderst tilgængeligt.
Dette udgør en betydelig udfordring for databaseadministratorer. Først og fremmest, hvordan kan du se, om dit miljø er meget tilgængeligt eller ej? Hvordan ville du måle det? Hvad er de trin, du skal tage for at forbedre tilgængeligheden? Hvordan designer man sit setup, så det bliver meget tilgængeligt fra begyndelsen?
Der er mange mange HA-løsninger tilgængelige i MySQL (og MariaDB) økosystemet, men hvordan ved vi, hvilke vi kan stole på? Nogle løsninger fungerer muligvis under visse specifikke forhold, men kan forårsage flere problemer, når de anvendes uden for disse forhold. Selv en grundlæggende funktionalitet som MySQL-replikering, der kan konfigureres på mange måder, kan forårsage betydelig skade - for eksempel cirkulær replikering med flere skrivbare mastere. Selvom det er nemt at konfigurere en 'multi-master opsætning' ved hjælp af replikering, kan det meget nemt bryde og efterlade os med divergerende datasæt på forskellige servere. For en database, som ofte betragtes som den eneste kilde til sandhed, kan kompromitteret dataintegritet have katastrofale konsekvenser.
I de følgende kapitler vil vi diskutere kravene til høj tilgængelighed i database
opsætninger, og hvordan man designer systemet fra bunden.
Måling af høj tilgængelighed
Hvad er høj tilgængelighed? For at kunne afgøre, om et givet miljø er meget tilgængeligt eller ej, skal man have nogle målinger for det. Der er adskillige måder, du kan måle høj tilgængelighed på, vi vil fokusere på nogle af de mest basale ting.
Lad os dog først tænke på, hvad hele denne høje tilgængelighed handler om? Hvad er dens formål? Det handler om at sikre, at dit miljø tjener sit formål. Formål kan defineres på mange måder, men typisk vil det handle om at levere en service. I databaseverdenen er det typisk noget relateret til data. Det kan være at sende data til din interne applikation. Det kan være at gemme data og gøre dem forespørgbare ved hjælp af analytiske processer. Det kan være at gemme nogle data for dine brugere, og give dem, når de bliver bedt om det. Når vi er klar over formålet, kan vi fastslå de involverede succesfaktorer. Dette vil hjælpe os med at definere, hvad høj tilgængelighed betyder i vores specifikke tilfælde.
SLA'er
Service Level Agreement (SLA). Det er også ret almindeligt at definere SLA'er for interne tjenester. Hvad er en SLA? Det er en definition af det serviceniveau, du planlægger at levere til dine kunder. Dette er for, at de bedre kan forstå, hvilket stabilitetsniveau du planlægger for en tjeneste, de har købt eller planlægger at købe. Der er adskillige metoder, du kan bruge til at udarbejde en SLA, men typiske er:
- Tjenestens tilgængelighed (procent)
- Tjenestens reaktionsevne - latenstid (gennemsnit, maks., 95 percentil, 99 percentil)
- Pakketab over netværket (procent)
- Throughput (gennemsnit, minimum, 95 percentil, 99 percentil)
Det kan dog blive mere komplekst end som så. I et opdelt miljø med flere brugere kan du definere, lad os sige, din SLA som:"Tjenesten vil være tilgængelig 99,99 % af tiden, nedetid erklæres, når mere end 2 % af brugerne er berørt. Ingen hændelse kan tage mere end 15 minutter at blive løst”. En sådan SLA kan også udvides til at inkorporere forespørgselssvartid:"nedetid kaldes, hvis 99 percentilen af latens for forespørgsler overstiger 200 millisekunder".
Nine
Tilgængelighed måles typisk i "ni", lad os se på, hvad præcis en given mængde "ni" garanterer. Tabellen nedenfor er taget fra Wikipedia:
| Tilgængelighed % | Nedetid pr. år | Nedetid pr. måned | Nedetid pr. uge | Nedetid pr. dag |
|---|---|---|---|---|
| 90 % ("one ni") | 36,5 dage | 72 timer | 16,8 timer | 2,4 timer |
| 95 % ("halvanden niere") | 18,25 dage | 36 timer | 8,4 timer | 1,2 timer |
| 97 % | 10,96 dage | 21,6 timer | 5.04 timer | 43,2 min. |
| 98 % | 7.30 dage | 14,4 timer | 3,36 timer | 28,8 min. |
| 99 % ("to nire") | 3,65 dage | 7.20 timer | 1,68 timer | 14,4 min. |
| 99,5 % ("to en halv nire") | 1,83 dage | 3,60 timer | 50,4 min. | 7,2 min. |
| 99,8 % | 17.52 timer | 86,23 min. | 20,16 min. | 2,88 min. |
| 99,9 % ("tre niere") | 8,76 timer | 43,8 min. | 10,1 min. | 1,44 min. |
| 99,95 % ("tre en halv ni") | 4,38 timer | 21,56 min. | 5,04 min. | 43,2 s |
| 99,99 % ("fire nire") | 52,56 min. | 4,38 min. | 1,01 min. | 8,64 s |
| 99,995 % ("fire en halv nire") | 26,28 min. | 2,16 min. | 30.24 s | 4.32 s |
| 99,999 % ("fem niere") | 5,26 min. | 25,9 s | 6.05 s | 864,3 ms |
| 99,9999 % ("seks nire") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999 % ("syv niere") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999 % ("otte niere") | 315.569 ms | 26.297 ms | 6.048 ms | 0,864 ms |
| 99,9999999 % ("ni nire") | 31.5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Som vi kan se, eskalerer det hurtigt. Fem ni (99.999 % tilgængelighed) svarer til 5,26 minutters nedetid i løbet af et år. Tilgængelighed kan også beregnes i forskellige, mindre intervaller:pr. måned, pr. uge, pr. dag. Husk disse tal, da de vil være nyttige, når vi begynder at diskutere omkostningerne forbundet med at opretholde forskellige niveauer af tilgængelighed.
Måling af tilgængelighed
For at fortælle om der er nedetid eller ej, skal man have indsigt i miljøet. Du skal spore de metrics, der definerer tilgængeligheden af dine systemer. Det er vigtigt at huske på, at du bør måle det fra en kundes synspunkt og tage det bredere billede i betragtning. Det er lige meget, om dine databaser er oppe, hvis, lad os sige, på grund af et netværksproblem, ingen applikationer kan nå dem. Hver enkelt byggesten i din opsætning har sin indflydelse på tilgængeligheden.
Et af de gode steder, hvor man kan lede efter tilgængelighedsdata, er webserverlogfiler. Alle anmodninger, der endte med fejl, betyder, at der er sket noget. Det kan være HTTP-fejl 500 returneret af applikationen, fordi databaseforbindelsen mislykkedes. Det kunne være programmatiske fejl, der peger på nogle databaseproblemer, og som endte i Apaches fejllog. Du kan også bruge simpel metrik som oppetid for databaseservere, selvom det med mere komplekse SLA'er kan være vanskeligt at bestemme, hvordan utilgængeligheden af en database påvirkede din brugerbase. Lige meget hvad du gør, bør du bruge mere end én metrik - dette er nødvendigt for at fange problemer, der kunne være sket på forskellige lag af dit miljø.
Magisk tal:"Tre"
Selvom høj tilgængelighed også handler om redundans, er tre i tilfælde af databaseklynger et magisk tal. Det er ikke nok at have to noder til redundans - sådan opsætning giver ikke nogen indbygget høj tilgængelighed. Sikker på, det kan være bedre end blot en enkelt knude, men menneskelig indgriben er påkrævet for at gendanne tjenester. Lad os se, hvorfor det er sådan.
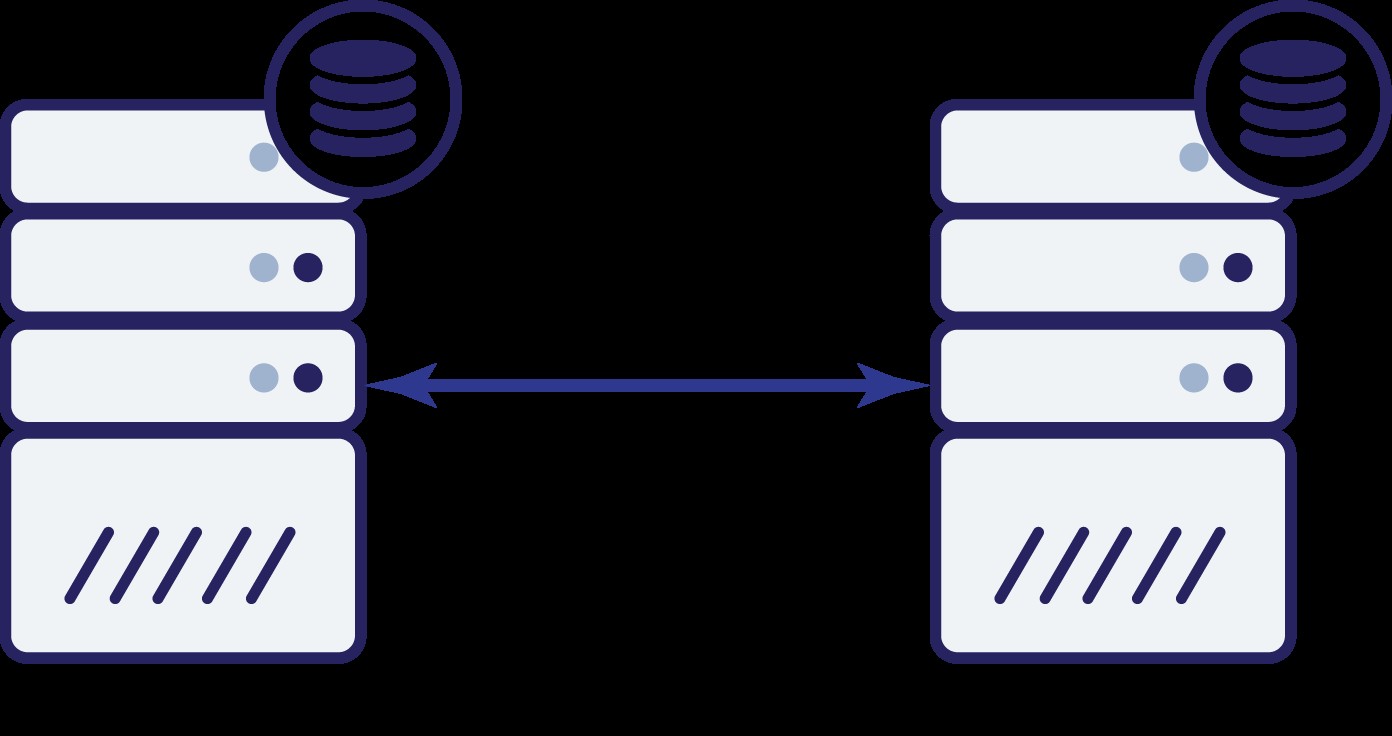
Lad os antage, at vi har to noder, A og B. Der er en netværksforbindelse mellem dem. Lad os antage, at både A og B serverer skrivninger, og at applikationen tilfældigt vælger, hvor den skal forbindes (hvilket betyder, at en del af applikationen vil forbinde til node A, og den anden del vil forbinde til node B). Lad os nu forestille os, at vi har et netværksproblem, som resulterer i tabt netværksforbindelse mellem A og B.
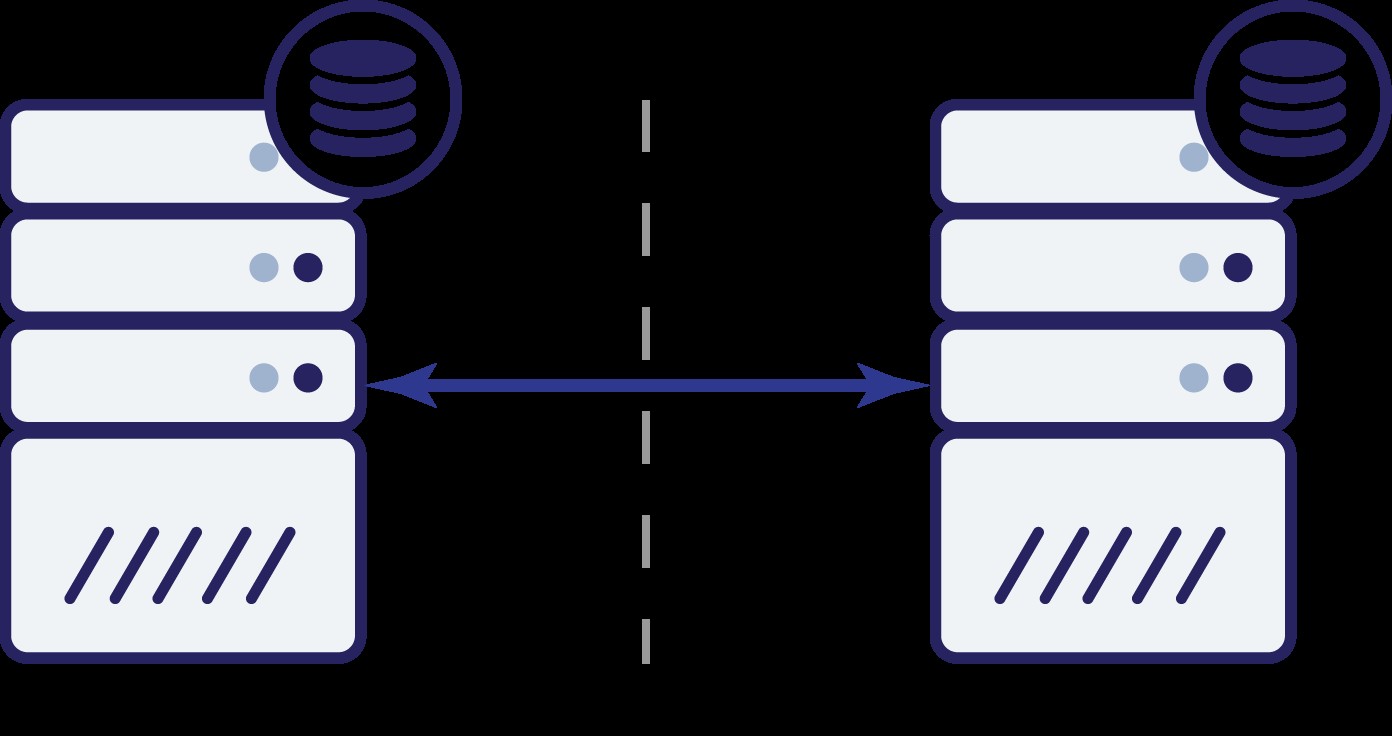
Hvad nu? Hverken A eller B kan kende tilstanden af den anden knude. Der er to handlinger, der kan udføres af begge noder:
- De kan fortsætte med at acceptere trafik
- De kan ophøre med at fungere og nægte at betjene nogen trafik
Lad os tænke på den første mulighed. Så længe den anden node faktisk er nede, er dette den foretrukne handling - vi ønsker, at vores database skal fortsætte med at betjene trafik. Dette er trods alt hovedideen bag høj tilgængelighed. Hvad ville der dog ske, hvis begge noder ville fortsætte med at acceptere trafik, mens de blev afbrudt fra hinanden? Nye data vil blive tilføjet på begge sider, og datasættene vil blive ude af sync. Når netværksproblemet er løst, vil det være en skræmmende opgave at flette disse to datasæt. Derfor er det ikke acceptabelt at holde begge noder oppe og køre. Problemet er - hvordan kan node A fortælle om node B er i live eller ej (og omvendt)? Svaret er - det kan den ikke. Hvis al forbindelse er nede, er der ingen måde at skelne mellem en mislykket node fra et fejlslagen netværk. Som et resultat er den eneste sikre handling, at begge knudepunkter stopper alle operationer og nægter at
servere trafik.
Lad os nu tænke på, hvordan en tredje knude kan hjælpe os i sådan en situation.
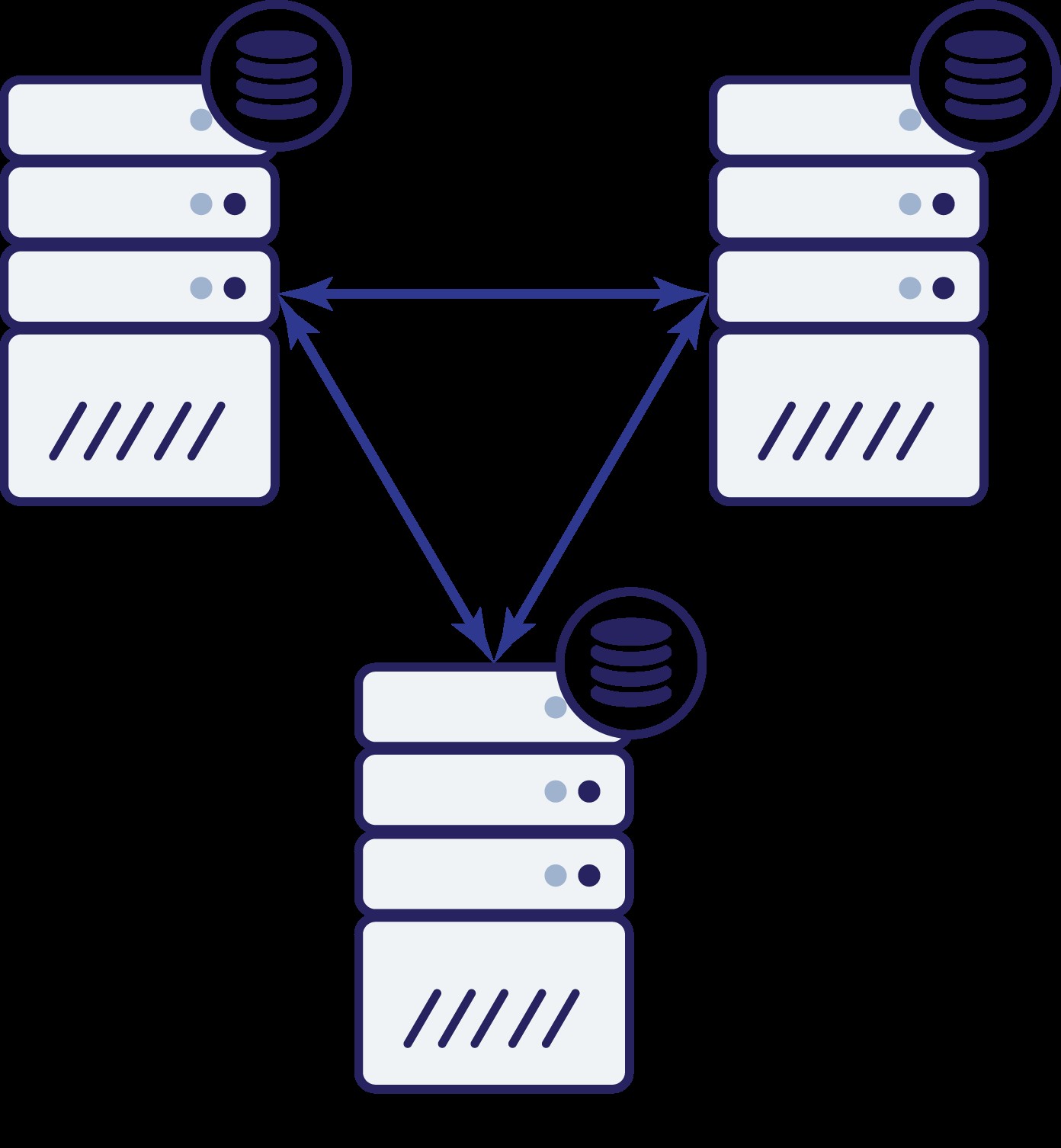
Så vi har nu tre noder:A, B og C. Alle er indbyrdes forbundne, alle håndterer læsninger og skrivninger.
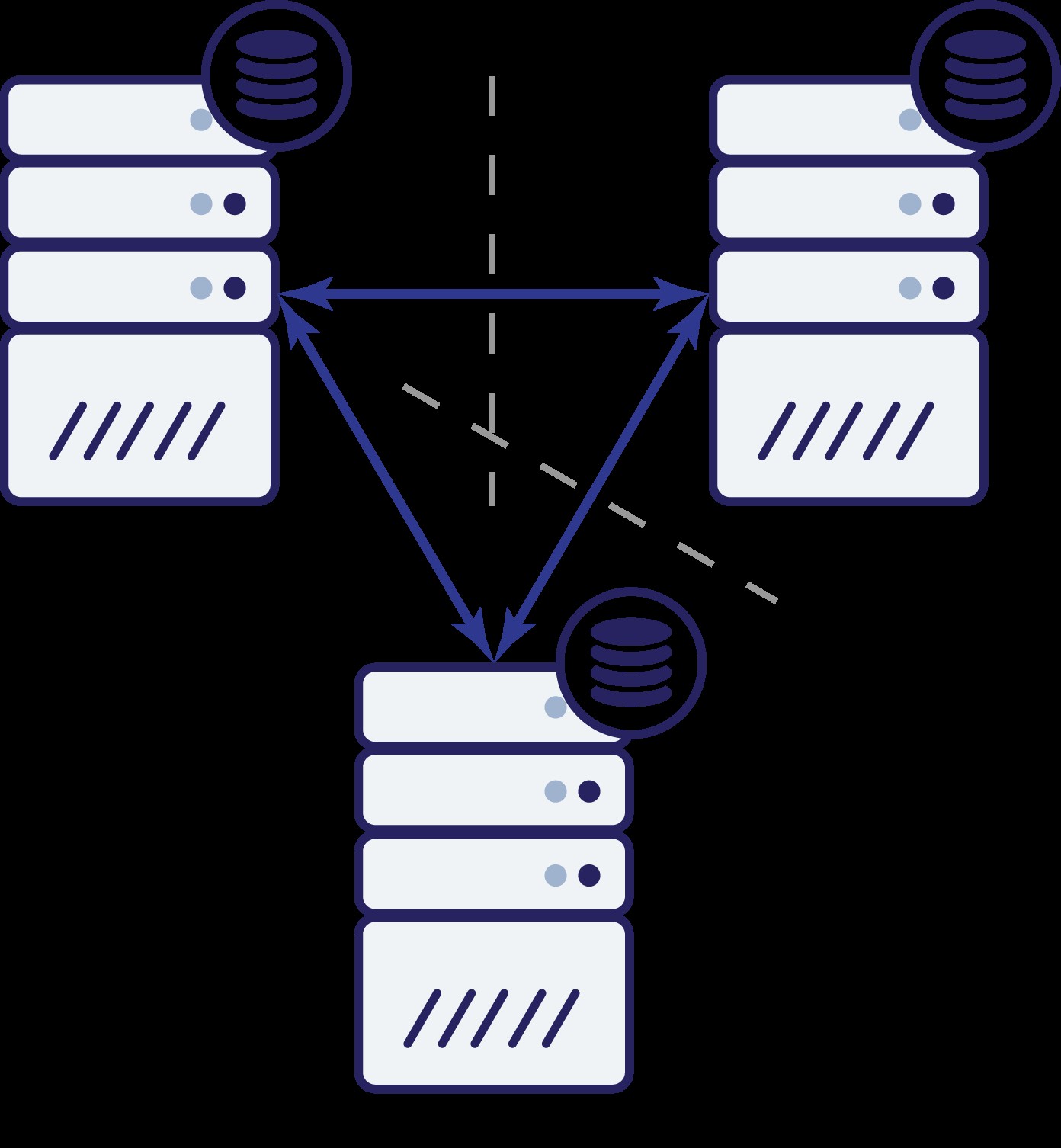
Igen, som i det foregående eksempel, er node B blevet afskåret fra resten af klyngen på grund af netværksproblemer. Hvad kan der så ske? Nå, situationen er ret lig den, vi diskuterede tidligere. To muligheder - node B kan enten være nede (og resten af klyngen skal fortsætte), eller den kan være oppe, i hvilket tilfælde den ikke skal have lov til at håndtere nogen trafik. Kan vi nu fortælle, hvordan klyngens tilstand er? Faktisk, ja. Vi kan se, at knudepunkter A og C kan tale med hinanden, og som følge heraf kan de blive enige om, at knudepunkt B ikke er tilgængelig. De vil ikke være i stand til at fortælle, hvorfor det skete, men hvad de ved er, at ud af tre noder i klyngen har to stadig forbindelse mellem hinanden. I betragtning af at disse to noder udgør størstedelen af klyngen, gør det muligt at fortsætte med at håndtere trafik. Samtidig kan knudepunkt B også trække, at problemet er på sin side. Den kan ikke få adgang til hverken node A eller node C, hvilket gør node B adskilt fra resten af klyngen. Da det er isoleret og ikke er en del af et flertal (1 af 3), er den eneste sikre handling, den kan tage, at stoppe med at betjene trafik og nægte at acceptere nogen forespørgsler, hvilket sikrer, at datadrift ikke sker.
Det betyder selvfølgelig ikke, at du kun kan have tre noder i klyngen. Hvis du vil have bedre fejltolerance, kan du tilføje flere. Husk dog, at det skal være et ulige tal, hvis du vil forbedre høj tilgængelighed. Vi talte også om "knuder" i eksemplerne ovenfor. Husk, at dette også gælder for datacentre, tilgængelighedszoner osv. Hvis du har to datacentre, der hver har det samme antal noder (lad os sige tre noder hver), og du mister forbindelsen mellem disse to DC'er, gælder de samme principper her - du kan ikke se, hvilken halvdel af klyngen der skal begynde at håndtere trafik. For at kunne fortælle det, skal du have en observatør i et tredje datacenter. Det kan være endnu et sæt noder, eller bare en enkelt vært, med opgaven
at observere tilstanden for resterende dataregistreringer og deltage i at træffe beslutninger (et eksempel her ville være Galera-voldgiftsmanden).
Enkelte fejlpunkter
Høj tilgængelighed handler om at fjerne single points of failure (SPOF) og ikke at introducere nye i processen. Hvad er SPOF'erne? Enhver del af din infrastruktur, som, når den fejler, bringer nedetid som defineret i SLA, kaldes en SPOF. Infrastrukturdesign kræver en holistisk tilgang, de forskellige komponenter kan ikke designes uafhængigt af hinanden. Mest sandsynligt er du ikke ansvarlig for hele designet -
databaseadministratorer har en tendens til at fokusere på databaser og ikke for eksempel netværkslaget. Alligevel skal du huske de andre dele og arbejde med de teams, der er ansvarlige for dem, for at sikre, at ikke kun den del, du er ansvarlig for, er designet korrekt, men også at de resterende dele af infrastrukturen er designet ved hjælp af samme principper. Oven i det hjælper sådan viden om, hvordan hele
infrastrukturen er designet, dig også med at designe databasestakken. At vide, hvilke problemer der kan ske, hjælper med at opbygge nogle mekanismer for at forhindre dem i at påvirke tilgængeligheden af databasen.