Et understøttende indeks kan potentielt hjælpe med at undgå behovet for eksplicit sortering i forespørgselsplanen ved optimering af T-SQL-forespørgsler, der involverer vinduesfunktioner. Ved et understøttende indeks, Jeg mener en med vinduespartitionering og bestillingselementer som indeksnøgle, og resten af de kolonner, der vises i forespørgslen som indekset inkluderede kolonner. Jeg refererer ofte til et sådant indekseringsmønster som en POC indeks som et akronym for partitionering , bestilling, og dækning . Hvis et partitionerings- eller bestillingselement ikke vises i vinduesfunktionen, udelader du naturligvis denne del fra indeksdefinitionen.
Men hvad med forespørgsler, der involverer flere vinduesfunktioner med forskellige bestillingsbehov? På samme måde, hvad hvis andre elementer i forespørgslen udover vinduesfunktioner også kræver at arrangere inputdata som bestilt i planen, såsom en præsentation ORDER BY-klausul? Disse kan resultere i, at forskellige dele af planen skal behandle inputdataene i forskellige rækkefølger.
Under sådanne omstændigheder vil du typisk acceptere, at eksplicit sortering er uundgåelig i planen. Du kan finde ud af, at det syntaktiske arrangement af udtryk i forespørgslen kan påvirke hvor mange eksplicitte sorteringsoperatører får du i planen. Ved at følge nogle grundlæggende tips kan du nogle gange reducere antallet af eksplicitte sorteringsoperatorer, hvilket naturligvis kan have stor indflydelse på forespørgslens ydeevne.
Miljø til demoer
I mine eksempler vil jeg bruge prøvedatabasen PerformanceV5. Du kan downloade kildekoden for at oprette og udfylde denne database her.
Jeg kørte alle eksemplerne på SQL Server 2019 Developer, hvor batch-tilstand på rowstore er tilgængelig.
I denne artikel vil jeg fokusere på tips, der har at gøre med potentialet for vinduesfunktionens beregning i planen til at stole på bestilte inputdata uden at kræve en ekstra eksplicit sorteringsaktivitet i planen. Dette er relevant, når optimizeren bruger en seriel eller parallel rækketilstandsbehandling af vinduesfunktioner, og når der bruges en seriel batch-mode Window Aggregate-operator.
SQL Server understøtter i øjeblikket ikke en effektiv kombination af en parallel ordrebevarende input forud for en parallel batch-mode Window Aggregate-operator. Så for at bruge en parallel batch-mode Window Aggregate-operator, skal optimeringsværktøjet injicere en mellemliggende parallel batch-mode sorteringsoperator, selv når input allerede er forudbestilt.
For nemheds skyld kan du forhindre parallelisme i alle eksempler vist i denne artikel. For at opnå dette uden at skulle tilføje et tip til alle forespørgsler og uden at indstille en server-dækkende konfigurationsindstilling, kan du indstille den databaseomfattede konfigurationsindstilling MAXDOP til 1 , sådan:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Husk at sætte den tilbage til 0, når du er færdig med at teste eksemplerne i denne artikel. Jeg minder dig om det til sidst.
Alternativt kan du forhindre parallelisme på sessionsniveau med den udokumenterede DBCC OPTIMIZER_WHATIF kommando, som sådan:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
For at nulstille indstillingen, når du er færdig, skal du aktivere den igen med værdien 0 som antallet af CPU'er.
Når du er færdig med at prøve alle eksemplerne i denne artikel med parallelitet deaktiveret, anbefaler jeg at aktivere parallelisme og prøve alle eksempler igen for at se, hvad der ændrer sig.
Tip 1 og 2
Før jeg starter med tipsene, lad os først se på et simpelt eksempel med en vinduesfunktion designet til at drage fordel af et supp class="border indent shadow orting index.
Overvej følgende forespørgsel, som jeg vil referere til som forespørgsel 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Du skal ikke bekymre dig om, at eksemplet er konstrueret. Der er ingen god forretningsgrund til at beregne en løbende total af ordre-id'er – denne tabel har en anstændig størrelse med 1MM rækker, og jeg ønskede at vise et simpelt eksempel med en almindelig vinduesfunktion, såsom en, der anvender en løbende totalberegning.
Efter POC-indekseringsskemaet opretter du følgende indeks for at understøtte forespørgslen:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Planen for denne forespørgsel er vist i figur 1.
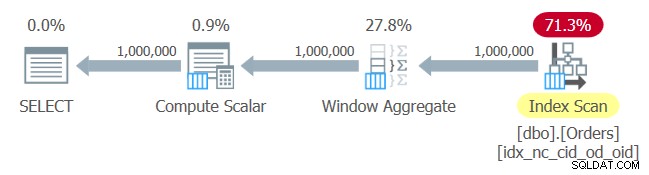 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Ingen overraskelser her. Planen anvender en indeksordrescanning af det indeks, du lige har oprettet, og leverer de bestilte data til Window Aggregate-operatøren uden behov for eksplicit sortering.
Overvej derefter følgende forespørgsel, som involverer flere vinduesfunktioner med forskellige bestillingsbehov, samt en præsentations ORDER BY-klausul:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Jeg vil referere til denne forespørgsel som forespørgsel 2. Planen for denne forespørgsel er vist i figur 2.
 Figur 2:Plan for forespørgsel 2
Figur 2:Plan for forespørgsel 2
Bemærk, at der er fire sorteringsoperatører i planen.
Hvis du analyserer de forskellige vinduesfunktioner og præsentationsbestillingsbehov, vil du opdage, at der er tre forskellige bestillingsbehov:
- custid, orderdate, orderid
- ordre-id
- custid, orderid
Givet en af dem (den første på listen ovenfor) kan understøttes af det indeks, du oprettede tidligere, ville du forvente kun at se to sorteringer i planen. Så hvorfor har planen fire slags? Det ser ud til, at SQL Server ikke forsøger at være for sofistikeret med at omarrangere behandlingsrækkefølgen af funktionerne i planen for at minimere sorteringer. Den behandler funktionerne i planen i den rækkefølge, de vises i forespørgslen. Det er i det mindste tilfældet for den første forekomst af hvert enkelt bestillingsbehov, men jeg vil uddybe dette kort.
Du kan fjerne behovet for nogle af slagsen i planen ved at anvende følgende to enkle fremgangsmåder:
Tip 1:Hvis du har et indeks, der understøtter nogle af vinduesfunktionerne i forespørgslen, skal du angive dem først.
Tip 2:Hvis forespørgslen involverer vinduesfunktioner med samme bestillingsbehov som præsentationsrækkefølgen i forespørgslen, skal du angive disse funktioner til sidst.
Ved at følge disse tips omarrangerer du udseenderækkefølgen af vinduesfunktionerne i forespørgslen sådan:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Jeg vil referere til denne forespørgsel som forespørgsel 3. Planen for denne forespørgsel er vist i figur 3.
 Figur 3:Plan for forespørgsel 3
Figur 3:Plan for forespørgsel 3
Som du kan se, har planen nu kun to slags.
Tip 3
SQL Server forsøger ikke at være for sofistikeret til at omarrangere behandlingsrækkefølgen af vinduesfunktioner i et forsøg på at minimere sorteringer i planen. Det er dog i stand til en vis simpel omarrangering. Den scanner vinduesfunktionerne baseret på udseenderækkefølgen i forespørgslen, og hver gang den registrerer et nyt særskilt bestillingsbehov, ser den fremad efter yderligere vinduesfunktioner med samme bestillingsbehov, og hvis den finder dem, grupperer den dem sammen med den første forekomst. I nogle tilfælde kan den endda bruge den samme operator til at beregne flere vinduesfunktioner.
Overvej følgende forespørgsel som et eksempel:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Jeg vil referere til denne forespørgsel som forespørgsel 4. Planen for denne forespørgsel er vist i figur 4.
 Figur 4:Plan for forespørgsel 4
Figur 4:Plan for forespørgsel 4
Vinduesfunktioner med samme bestillingsbehov er ikke grupperet sammen i forespørgslen. Der er dog stadig kun to slags i planen. Dette skyldes, at det, der tæller med hensyn til behandlingsrækkefølgen i planen, er den første forekomst af hvert enkelt bestillingsbehov. Dette fører mig til det tredje tip.
Tip 3:Sørg for at følge tip 1 og 2 for den første forekomst af hvert enkelt bestillingsbehov. Efterfølgende forekomster af det samme bestillingsbehov, selvom det ikke er tilstødende, identificeres og grupperes sammen med det første.
Tip 4 og 5
Antag, at du vil returnere kolonner, der stammer fra vinduesberegninger, i en bestemt venstre-til-højre rækkefølge i outputtet. Men hvad nu hvis rækkefølgen ikke er den samme som rækkefølgen, der vil minimere sorteringer i planen?
Antag f.eks., at du vil have det samme resultat som det, der blev produceret af forespørgsel 2 i form af venstre-til-højre kolonnerækkefølge i outputtet (kolonnerækkefølge:andre kolonner, sum2, sum1, sum3), men du vil hellere have samme plan som den, du fik for forespørgsel 3 (kolonnerækkefølge:andre kolonner, sum1, sum3, sum2), som fik to sorteringer i stedet for fire.
Det kan lade sig gøre, hvis du er bekendt med det fjerde tip.
Tip 4:De førnævnte anbefalinger gælder for udseenderækkefølgen af vinduesfunktioner i koden, selvom inden for et navngivet tabeludtryk, såsom en CTE eller visning, og selvom den ydre forespørgsel returnerer kolonnerne i en anden rækkefølge end i navngivet tabeludtryk. Derfor, hvis du skal returnere kolonner i en bestemt rækkefølge i outputtet, og det er anderledes end den optimale rækkefølge i forhold til at minimere sorteringer i planen, skal du følge tipsene med hensyn til udseenderækkefølge i et navngivet tabeludtryk, og returnere kolonnerne i den ydre forespørgsel i den ønskede outputrækkefølge.
Følgende forespørgsel, som jeg vil referere til som forespørgsel 5, illustrerer denne teknik:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Planen for denne forespørgsel er vist i figur 5.
 Figur 5:Plan for forespørgsel 5
Figur 5:Plan for forespørgsel 5
Du får stadig kun to sorteringer i planen på trods af, at kolonnerækkefølgen i outputtet er:andre kolonner, sum2, sum1, sum3, ligesom i forespørgsel 2.
En advarsel til dette trick med det navngivne tabeludtryk er, at hvis dine kolonner i tabeludtrykket ikke refereres af den ydre forespørgsel, er de udelukket fra planen og tæller derfor ikke.
Overvej følgende forespørgsel, som jeg vil referere til som forespørgsel 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Her refereres alle tabeludtrykskolonner af den ydre forespørgsel, så optimering sker baseret på den første særskilte forekomst af hvert bestillingsbehov i tabeludtrykket:
- max1:custid, orderdate, orderid
- max3:ordre-id
- max2:custid, orderid
Dette resulterer i en plan med kun to sorteringer som vist i figur 6.
 Figur 6:Plan for forespørgsel 6
Figur 6:Plan for forespørgsel 6
Skift nu kun den ydre forespørgsel ved at fjerne referencerne til max2, max1, max3, avg2, avg1 og avg3, sådan:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Jeg vil referere til denne forespørgsel som forespørgsel 7. Beregningerne af max1, max3, max2, avg1, avg3 og avg2 i tabeludtrykket er irrelevante for den ydre forespørgsel, så de er udelukket. De resterende beregninger, der involverer vinduesfunktioner i tabeludtrykket, som er relevante for den ydre forespørgsel, er dem af sum2, sum1 og sum3. Desværre optræder de ikke i tabeludtrykket i optimal rækkefølge i forhold til at minimere sorteringer. Som du kan se i planen for denne forespørgsel som vist i figur 7, er der fire typer.
 Figur 7:Plan for forespørgsel 7
Figur 7:Plan for forespørgsel 7
Hvis du tænker, at det er usandsynligt, at du vil have kolonner i den indre forespørgsel, som du ikke vil referere til i den ydre forespørgsel, tænk på synspunkter. Hver gang du forespørger på en visning, kan du være interesseret i en anden undergruppe af kolonnerne. Med dette i tankerne kunne det femte tip hjælpe med at reducere sorteringer i planen.
Tip 5:I den indre forespørgsel i et navngivet tabeludtryk som en CTE eller en visning, grupper alle vinduesfunktioner med de samme bestillingsbehov sammen, og følg tip 1 og 2 i rækkefølgen af grupperne af funktioner.
Følgende kode implementerer en visning baseret på denne anbefaling:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Forespørg nu i visningen, der kun anmoder om de vinduesbaserede resultatkolonner sum2, sum1 og sum3, i denne rækkefølge:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Jeg vil referere til denne forespørgsel som forespørgsel 8. Du får planen vist i figur 8 med kun to sorteringer.
 Figur 8:Plan for forespørgsel 8
Figur 8:Plan for forespørgsel 8
Tip 6
Når du har en forespørgsel med flere vinduesfunktioner med flere forskellige bestillingsbehov, er den almindelige visdom, at du kun kan understøtte én af dem med forudbestilte data via et indeks. Dette er tilfældet, selv når alle vinduesfunktioner har respektive understøttende indekser.
Lad mig demonstrere dette. Husk tidligere, da du oprettede indekset idx_nc_cid_od_oid, som kan understøtte vinduesfunktioner, der kræver data sorteret efter custid, orderdate, orderid, såsom følgende udtryk:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Antag, at du ud over denne vinduesfunktion også har brug for følgende vinduesfunktion i samme forespørgsel:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Denne vinduesfunktion vil drage fordel af følgende indeks:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
Følgende forespørgsel, som jeg vil referere til som forespørgsel 9, påkalder begge vinduesfunktioner:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Planen for denne forespørgsel er vist i figur 9.
 Figur 9:Plan for forespørgsel 9
Figur 9:Plan for forespørgsel 9
Jeg får følgende tidsstatistik for denne forespørgsel på min maskine, med resultater kasseret i SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Som forklaret tidligere scanner SQL Server de vinduesudtryk i rækkefølge, de vises i forespørgslen, og figurerer, at den kan understøtte den første med en ordnet scanning af indekset idx_nc_cid_od_oid. Men så tilføjer den en sorteringsoperatør til planen for at bestille dataene, som den anden vinduesfunktion har brug for. Dette betyder, at planen har N log N-skalering. Det overvejer ikke at bruge indekset idx_nc_cid_oid til at understøtte den anden vinduesfunktion. Du tænker sikkert, at det ikke kan, men prøv at tænke lidt ud af boksen. Kunne du ikke beregne hver af vinduesfunktionerne baseret på dens respektive indeksrækkefølge og derefter samle resultaterne? Teoretisk set kan du, og afhængigt af størrelsen af dataene, tilgængeligheden af indeksering og andre tilgængelige ressourcer, kunne joinversionen nogle gange gøre det bedre. SQL Server overvejer ikke denne tilgang, men du kan helt sikkert implementere den ved selv at skrive joinforbindelsen, som sådan:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Jeg vil referere til denne forespørgsel som forespørgsel 10. Planen for denne forespørgsel er vist i figur 10.
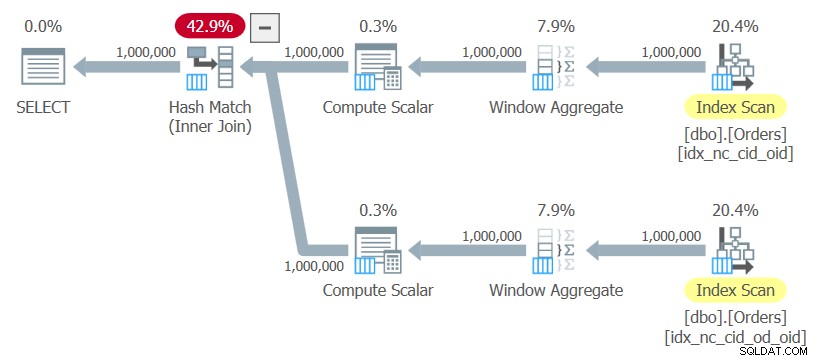 Figur 10:Plan for forespørgsel 10
Figur 10:Plan for forespørgsel 10
Planen bruger ordnede scanninger af de to indekser uden nogen som helst eksplicit sortering, beregner vinduesfunktionerne og bruger en hash-join til at forbinde resultaterne. Denne plan skaleres lineært i forhold til den forrige, som har N log N-skalering.
Jeg får følgende tidsstatistik for denne forespørgsel på min maskine (igen med resultater kasseret i SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
For at opsummere, her er vores sjette tip.
Tip 6:Når du har flere vinduesfunktioner med flere forskellige bestillingsbehov, og du er i stand til at understøtte dem alle med indekser, kan du prøve en joinversion og sammenligne dens ydeevne med forespørgslen uden joinforbindelsen.
Oprydning
Hvis du deaktiverede parallelisme ved at indstille den databaseomfattede konfigurationsindstilling MAXDOP til 1, genaktiver parallelisme ved at indstille den til 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Hvis du brugte den udokumenterede sessionsindstilling DBCC OPTIMIZER_WHATIF med CPU-indstillingen sat til 1, genaktiver parallelisme ved at sætte den til 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Du kan prøve alle eksempler med parallelitet aktiveret igen, hvis du vil.
Brug følgende kode til at rydde op i de nye indekser, du har oprettet:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
Og følgende kode for at fjerne visningen:
DROP VIEW IF EXISTS dbo.MyView;
Følg tipsene for at minimere antallet af sorteringer
Vinduesfunktioner skal behandle de bestilte inputdata. Indeksering kan hjælpe med at eliminere sortering i planen, men normalt kun for et enkelt bestillingsbehov. Forespørgsler med flere bestillingsbehov involverer typisk nogle slags i deres planer. Ved at følge visse tips kan du dog minimere antallet af nødvendige sorteringer. Her er en oversigt over de tips, jeg nævnte i denne artikel:
- Tip 1: Hvis du har et indeks, der understøtter nogle af vinduesfunktionerne i forespørgslen, skal du angive dem først.
- Tip 2: Hvis forespørgslen involverer vinduesfunktioner med samme bestillingsbehov som præsentationsrækkefølgen i forespørgslen, skal du angive disse funktioner sidst.
- Tip 3: Sørg for at følge tip 1 og 2 for den første forekomst af hvert enkelt bestillingsbehov. Efterfølgende forekomster af det samme bestillingsbehov, selvom det ikke er tilstødende, identificeres og grupperes sammen med det første.
- Tip 4: De førnævnte anbefalinger gælder for udseenderækkefølgen af vinduesfunktioner i koden, selvom inden for et navngivet tabeludtryk, såsom en CTE eller visning, og selvom den ydre forespørgsel returnerer kolonnerne i en anden rækkefølge end i det navngivne tabeludtryk. Derfor, hvis du skal returnere kolonner i en bestemt rækkefølge i outputtet, og det er anderledes end den optimale rækkefølge i forhold til at minimere sorteringer i planen, skal du følge tipsene med hensyn til udseenderækkefølge i et navngivet tabeludtryk, og returnere kolonnerne i den ydre forespørgsel i den ønskede outputrækkefølge.
- Tip 5: I den indre forespørgsel i et navngivet tabeludtryk som en CTE eller visning, grupperer du alle vinduesfunktioner med de samme bestillingsbehov sammen, og følg tip 1 og 2 i rækkefølgen af grupperne af funktioner.
- Tip 6: Når du har flere vinduesfunktioner med flere forskellige bestillingsbehov, og du er i stand til at understøtte dem alle med indekser, kan du prøve en joinversion og sammenligne dens ydeevne med forespørgslen uden joinforbindelsen.