I en nylig tråd om StackExchange havde en bruger følgende problem:
Jeg vil have en forespørgsel, der returnerer den første person i tabellen med et GroupID =2. Hvis der ikke findes nogen med et GroupID =2, vil jeg have den første person med et RolleID =2.
Lad os foreløbig kassere det faktum, at "først" er frygteligt defineret. I virkeligheden var brugeren ligeglad med, hvilken person de fik, om det kom tilfældigt, vilkårligt eller gennem en eksplicit logik ud over deres hovedkriterier. Hvis du ignorerer det, lad os sige, at du har en grundlæggende tabel:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
I den virkelige verden er der sandsynligvis andre kolonner, yderligere begrænsninger, måske fremmednøgler til andre tabeller og helt sikkert andre indekser. Men lad os holde det enkelt og komme med en forespørgsel.
Sandsynlige løsninger
Med det borddesign virker det ligetil at løse problemet, ikke? Det første forsøg, du sandsynligvis ville gøre, er:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Dette bruger TOP og en betinget ORDER BY at behandle de brugere med et GroupID =2 som højere prioritet. Planen for denne forespørgsel er ret enkel, hvor det meste af omkostningerne sker i en slags operation. Her er runtime-metrics mod en tom tabel:
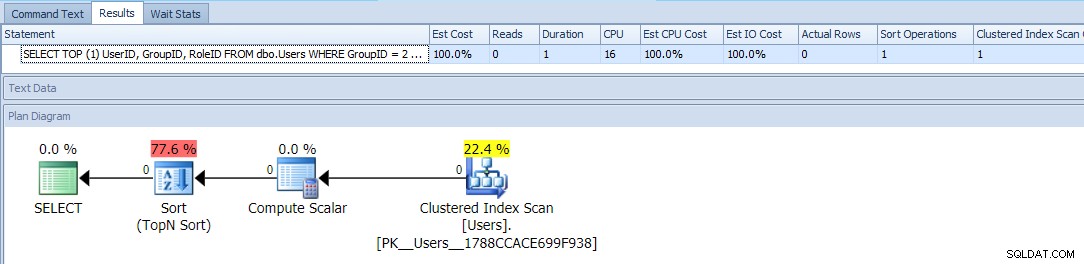
Dette ser ud til at være omtrent så godt, som du kan gøre – en simpel plan, der kun scanner bordet én gang, og bortset fra en irriterende slags, som du burde kunne leve med, ikke noget problem, ikke?
Nå, et andet svar i tråden tilbød denne mere komplekse variation:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Ved første øjekast ville du sikkert tro, at denne forespørgsel er ekstremt mindre effektiv, da den kræver to klyngede indeksscanninger. Det ville du helt sikkert have ret i; her er plan- og runtime-metrics mod en tom tabel:
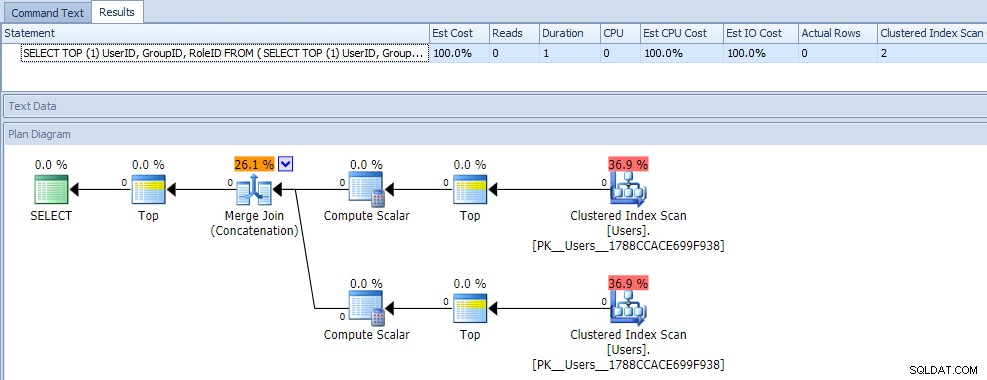
Men lad os nu tilføje data
For at teste disse forespørgsler ville jeg bruge nogle realistiske data. Så først udfyldte jeg 1.000 rækker fra sys.all_objects med modulo-operationer mod object_id for at få en anstændig fordeling:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Når jeg nu kører de to forespørgsler, er her runtime-metrics:

UNION ALL-versionen kommer med lidt mindre I/O (4 læsninger vs. 5), lavere varighed og lavere estimerede samlede omkostninger, mens den betingede ORDER BY-version har lavere estimerede CPU-omkostninger. Dataene her er ret små at drage nogen konklusioner om; Jeg ville bare have det som en indsats i jorden. Lad os nu ændre fordelingen, så de fleste rækker opfylder mindst et af kriterierne (og nogle gange begge):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Denne gang har den betingede ordre af de højeste estimerede omkostninger i både CPU og I/O:

Men igen, ved denne datastørrelse er der relativt ubetydelige indvirkning på varighed og læsninger, og bortset fra de estimerede omkostninger (som alligevel stort set er opgjort), er det svært at erklære en vinder her.
Så lad os tilføje mange flere data
Selvom jeg hellere nyder at bygge eksempeldata fra katalogvisningerne, da alle har dem, vil jeg denne gang tegne Sales.SalesOrderHeaderEnlarged fra AdventureWorks2012, udvidet med dette script fra Jonathan Kehayias på bordet. På mit system har denne tabel 1.258.600 rækker. Følgende script vil indsætte en million af disse rækker i vores dbo.Users tabel:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Okay, når vi nu kører forespørgslerne, ser vi et problem:ORDER BY-variationen er gået parallelt og har udslettet både læsninger og CPU, hvilket giver en næsten 120X forskel i varighed:
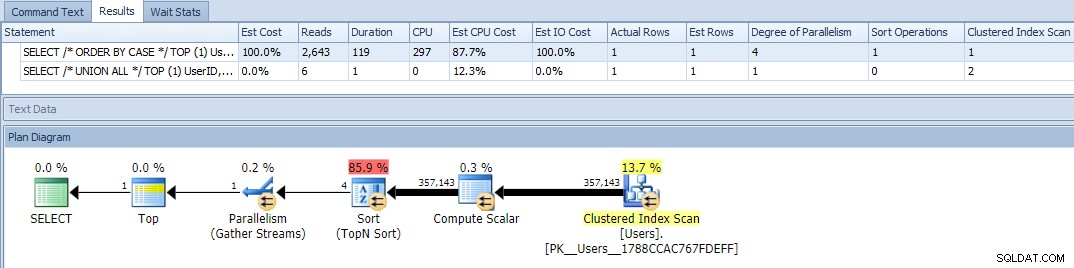
At eliminere parallelisme (ved at bruge MAXDOP) hjalp ikke:
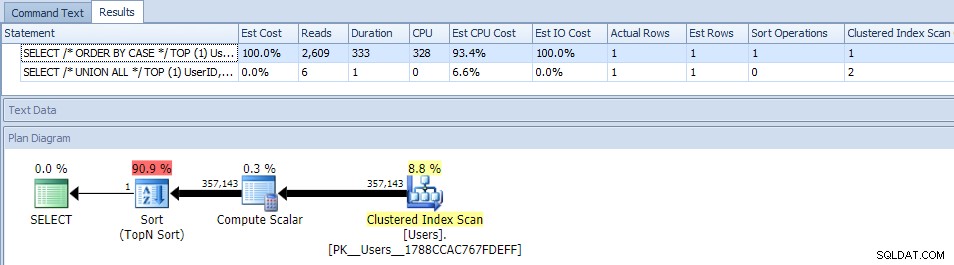
(UNION ALL-planen ser stadig den samme ud.)
Og hvis vi ændrer skævheden til at være lige, hvor 95 % af rækkerne opfylder mindst ét kriterium:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Forespørgslerne viser stadig, at sorteringen er uoverkommelig dyr:

Og med MAXDOP =1 var det meget værre (se bare på varighed):

Til sidst, hvad med 95 % skævhed i begge retninger (f.eks. opfylder de fleste rækker GroupID-kriterierne, eller de fleste rækker opfylder RolleID-kriterierne)? Dette script vil sikre, at mindst 95 % af dataene har GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultaterne er ret ens (jeg vil bare stoppe med at prøve MAXDOP-tinget fra nu af):

Og hvis vi så skæver den anden vej, hvor mindst 95 % af dataene har RolleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Resultater:

Konklusion
I ikke et enkelt tilfælde, som jeg kunne fremstille, overgik den "simpelere" ORDER BY-forespørgsel – selv med en mindre klynget indeksscanning – den mere komplekse UNION ALL-forespørgsel. Nogle gange skal du være meget på vagt over for, hvad SQL Server skal gøre, når du introducerer operationer som sorteringer i din forespørgselssemantik, og ikke stole på enkelheden af planen alene (pyt med den skævhed, du måtte have baseret på tidligere scenarier).
Dit første instinkt kan ofte være korrekt, men jeg vil vædde på, at der er tidspunkter, hvor der er en bedre mulighed, der på overfladen ser ud som om den umuligt kunne fungere bedre. Som i dette eksempel. Jeg bliver en del bedre til at stille spørgsmålstegn ved antagelser, jeg har lavet ud fra observationer, og ikke komme med generelle udsagn som "scanninger fungerer aldrig godt" og "enklere forespørgsler kører altid hurtigere." Hvis du fjerner ordene aldrig og altid fra dit ordforråd, kan du finde på at sætte flere af disse antagelser og generelle udsagn på prøve og ende med at blive meget bedre stillet.