Overvågning af dine databaseskemaændringer i MySQL/MariaDB giver en enorm hjælp, da det sparer tid ved at analysere din databasevækst, ændringer i tabeldefinitioner, datastørrelse, indeksstørrelse eller rækkestørrelse. For MySQL/MariaDB giver kørsel af en forespørgsel, der refererer til informationsskema sammen med performance_schema, dig samlede resultater til yderligere analyse. Sys-skemaet giver dig visninger, der fungerer som kollektive metrics, der er meget nyttige til at spore databaseændringer eller -aktivitet.
Hvis du har mange databaseservere, ville det være kedeligt at køre en forespørgsel hele tiden. Du skal også fordøje det resultat til et mere læsbart og lettere at forstå.
I denne blog vil vi oprette en automatisering, der ville være nyttig som dit hjælpeværktøj til at have, så din eksisterende database kan overvåges og indsamle metrics vedrørende databaseændringer eller skemaændringsoperationer.
Oprettelse af automatisering til kontrol af databaseskemaobjekter
I denne øvelse vil vi overvåge følgende metrics:
-
Ingen primærnøgletabeller
-
Duplikér indekser
-
Generer en graf for det samlede antal rækker i vores databaseskemaer
-
Generer en graf for den samlede størrelse af vores databaseskemaer
Denne øvelse vil give dig et heads up og kan ændres for at indsamle mere avancerede metrics fra din MySQL/MariaDB-database.
Brug af Puppet til vores IaC og automatisering
Denne øvelse skal bruge Puppet til at give automatisering og generere de forventede resultater baseret på de målinger, vi ønsker at overvåge. Vi dækker ikke installationen og opsætningen af Puppet, inklusive server og klient, så jeg forventer, at du ved, hvordan du bruger Puppet. Du vil måske besøge vores gamle blog Automated Deployment af MySQL Galera Cluster til Amazon AWS med Puppet, som dækker opsætning og installation af Puppet.
Vi bruger den seneste version af Puppet i denne øvelse, men da vores kode består af grundlæggende syntaks, ville den køre for ældre versioner af Puppet.
Foretrukken MySQL-databaseserver
I denne øvelse vil vi bruge Percona Server 8.0.22-13, da jeg foretrækker Percona Server mest til test og nogle mindre udrulninger, enten til forretningsbrug eller personlig brug.
Graphing Tool
Der er tonsvis af muligheder at bruge, især ved brug af Linux-miljøet. I denne blog vil jeg bruge det nemmeste, jeg fandt, og et opensource-værktøj https://quickchart.io/.
Lad os lege med dukke
Den antagelse, jeg har gjort her, er, at du har opsat masterserver med registreret klient, som er klar til at kommunikere med masterserveren for at modtage automatiske implementeringer.
Før vi fortsætter, her er min serveroplysninger:
Hovedserver:192.168.40.200
Client/Agent Server:192.168.40.160
I denne blog er vores klient/agent-server, hvor vores databaseserver kører. I et scenarie i den virkelige verden behøver det ikke at være specielt til overvågning. Så længe det er i stand til at kommunikere sikkert ind i målknuden, så er det også en perfekt opsætning.
Opsæt modulet og koden
-
Gå til masterserveren og i stien /etc/puppetlabs/code/environments/production/module, lad os oprette de nødvendige mapper til denne øvelse:
mkdir schema_change_mon/{files,manifests}
-
Opret de filer, vi har brug for
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Fyld init.pp-scriptet med følgende indhold:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Fyld filen graphing_gen.sh ud. Dette script vil køre på målknuden og generere grafer for det samlede antal rækker i vores database og også den samlede størrelse af vores database. For dette script, lad os gøre det enklere og kun tillade databaser af typen MyISAM eller InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Gå til sidst til modulstibiblioteket eller /etc/puppetlabs/code/environments /produktion i mit setup. Lad os oprette filen manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Fyld derefter filen manifests/schema_change_mon.pp med følgende indhold,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Hvis du er færdig, bør du have følgende træstruktur ligesom min,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppHvad gør vores modul?
Vores modul, som hedder schema_change_mon, indsamler følgende,
exec { "mysql-without-primary-key" :...
Som udfører en mysql-kommando og kører en forespørgsel for at hente tabeller uden primærnøgler. Så,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :som indsamler duplikerede indekser, der findes i databasetabellerne.
Dernæst genererer linjerne grafer baseret på de indsamlede metrics. Dette er de følgende linjer,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Når forespørgslen er kørt, genererer den grafen, som afhænger af API'et leveret af https://quickchart.io/.
Her er følgende resultater af grafen:
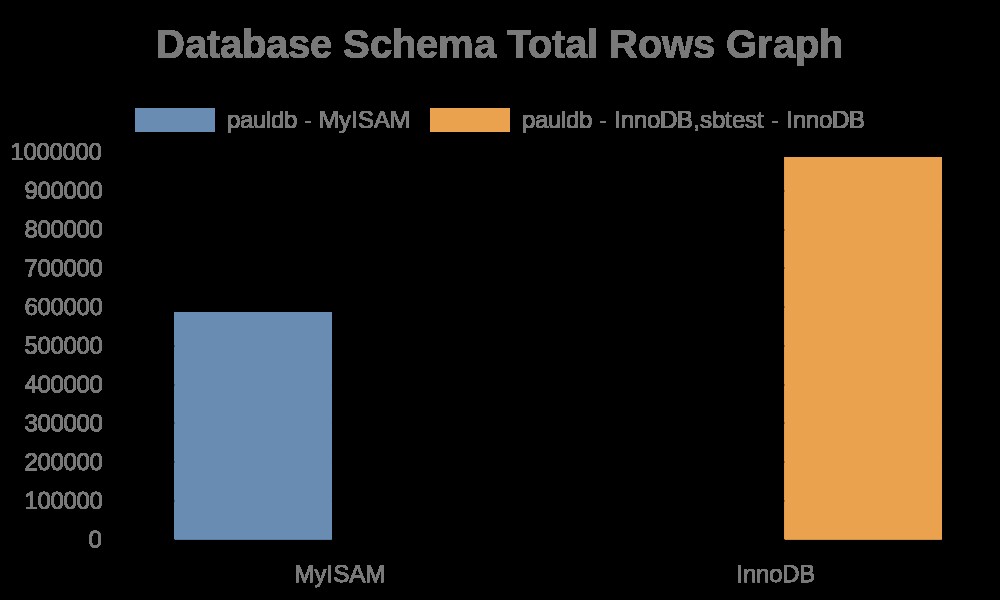
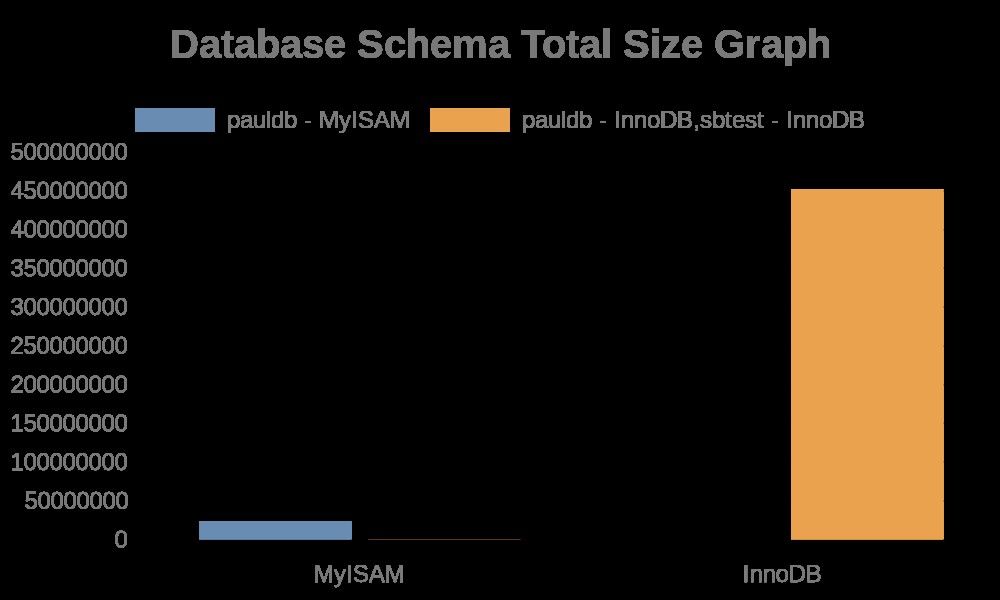
Mens fillogfilerne blot indeholder strenge med dens tabelnavne, indeksnavne. Se resultatet nedenfor,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBHvorfor ikke bruge ClusterControl?
Da vores øvelse viser automatiseringen og få databaseskemastatistikker såsom ændringer eller operationer, giver ClusterControl også dette. Der er også andre funktioner udover dette, og du behøver ikke at genopfinde hjulet. ClusterControl kan levere transaktionsloggene såsom dødvande som vist ovenfor, eller langvarige forespørgsler som vist nedenfor:
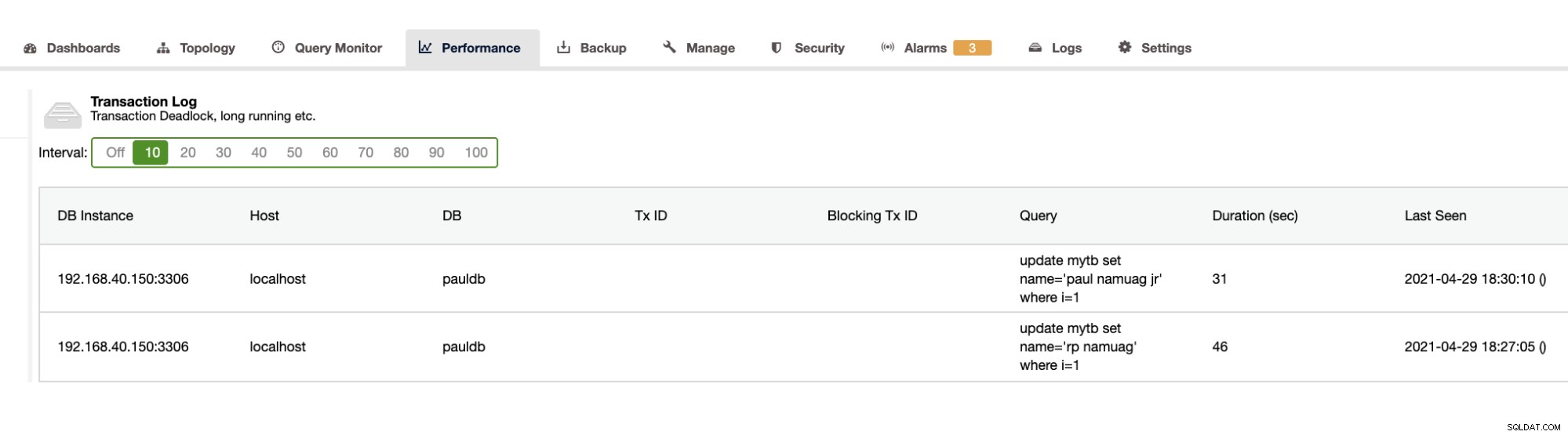
ClusterControl viser også DB-væksten som vist nedenfor,
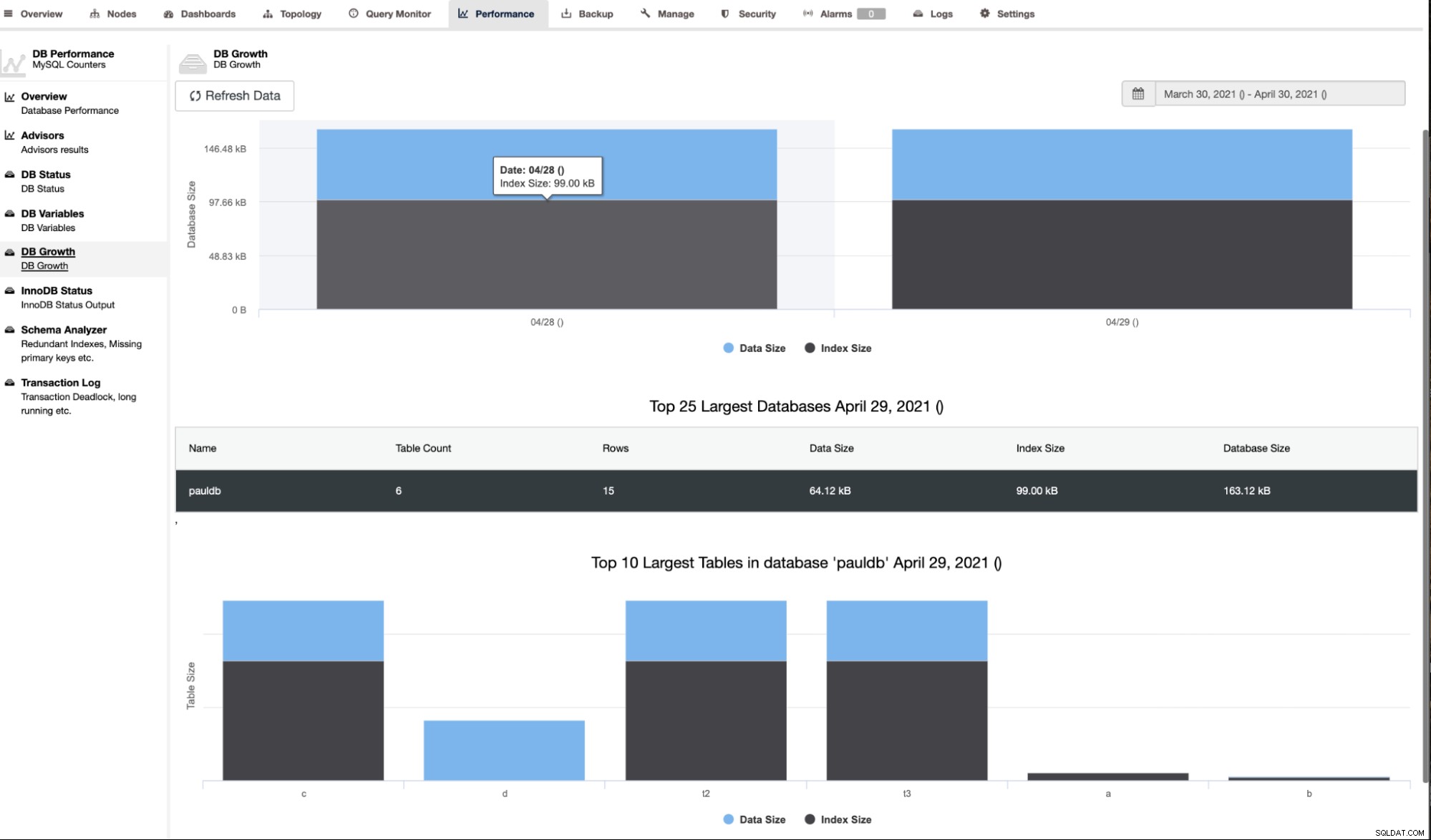
ClusterControl giver også yderligere oplysninger såsom antal rækker, diskstørrelse, indeksstørrelse og samlet størrelse.
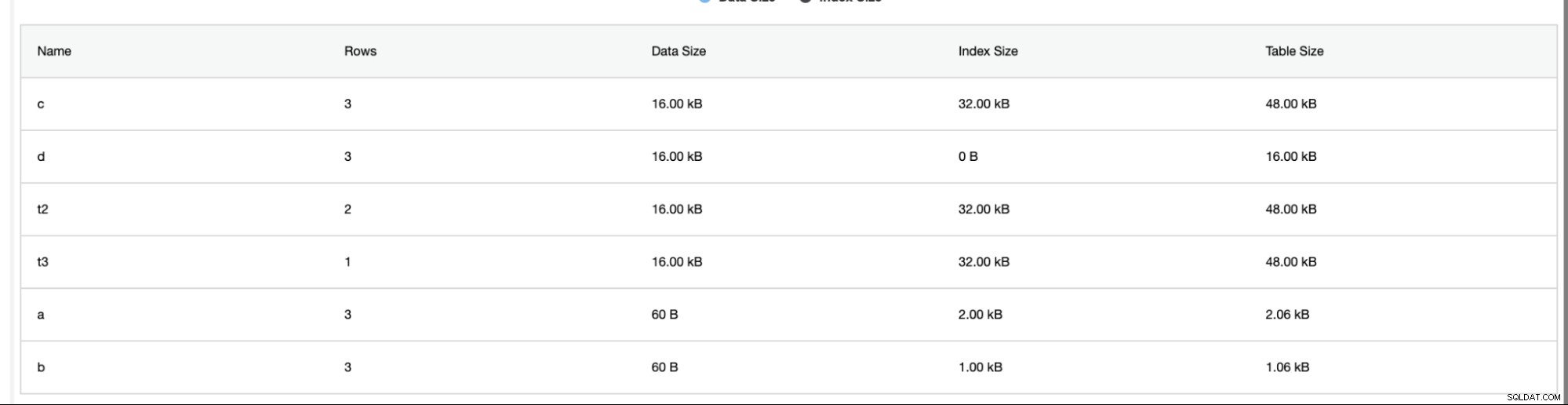
Skemaanalysatoren under fanen Performance -> Schema Analyzer er meget nyttig. Det giver tabeller uden primærnøgler, MyISAM-tabeller og duplikerede indekser,

Den giver også alarmer, hvis der er detekteret duplikerede indekser eller tabeller uden primære taster som nedenfor,

Du kan tjekke flere oplysninger om ClusterControl og dets andre funktioner på vores produktside.
Konklusion
Tilvejebringelse af automatisering til overvågning af dine databaseændringer eller enhver skemastatistik såsom skrivninger, duplikerede indekser, operationsopdateringer såsom DDL-ændringer og mange databaseaktiviteter er meget gavnlige for DBA'erne. Det hjælper med hurtigt at identificere de svage links og problematiske forespørgsler, der ville give dig et overblik over en mulig årsag til dårlige forespørgsler, der ville låse din database eller forælde din database.