SQL Server-forespørgselsudførelsesmotoren har to måder at implementere en logisk 'union alle'-operation ved at bruge de fysiske operatører Sammenkædning og Sammenflet sammenkædning. Selvom den logiske operation er den samme, er der vigtige forskelle mellem de to fysiske operatører, som kan gøre en enorm forskel for effektiviteten af dine eksekveringsplaner.
Forespørgselsoptimeringsværktøjet gør et rimeligt stykke arbejde med at vælge mellem de to muligheder i mange tilfælde, men det er langt fra perfekt på dette område. Denne artikel beskriver mulighederne for justering af forespørgsler, der præsenteres af Merge Join Concatenation, og beskriver den interne adfærd og overvejelser, du skal være opmærksom på for at få mest muligt ud af det.
Sammenkædning

Sammenkædningsoperatoren er relativt enkel:dens output er resultatet af fuldstændig læsning fra hver af dens input i rækkefølge. Sammenkædningsoperatoren er en n-ær fysisk operatør, hvilket betyder, at den kan have '2...n' input. For at illustrere det, lad os gense det AdventureWorks-baserede eksempel fra min tidligere artikel, "Omskrivning af forespørgsler for at forbedre ydeevnen":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Følgende forespørgsel viser produkt- og transaktions-id'er for seks bestemte produkter:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Den producerer en udførelsesplan med en sammenkædningsoperator med seks input, som det ses i SQL Sentry Plan Explorer:
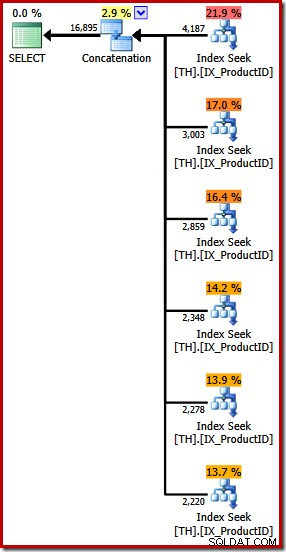
Planen ovenfor indeholder en separat indekssøgning for hvert anført produkt-id, i samme rækkefølge som angivet i forespørgslen (læses ovenfra og ned). Den øverste indekssøgning er for produkt 870, den næste nede er for produkt 873, derefter 921 og så videre. Intet af det er selvfølgelig garanteret adfærd, det er bare noget interessant at observere.
Jeg nævnte før, at sammenkædningsoperatøren danner sit output ved at læse fra sine input i rækkefølge. Når denne plan er eksekveret, er der en god chance for, at resultatsættet viser rækker for produkt 870 først, derefter 873, 921, 712, 707 og til sidst produkt 711. Igen, dette er ikke garanteret, fordi vi ikke har specificeret en ORDRE BY-klausul, men den viser, hvordan sammenkædning fungerer internt.
En SSIS "udførelsesplan"
Af årsager, der vil give mening om et øjeblik, kan du overveje, hvordan vi kan designe en SSIS-pakke til at udføre den samme opgave. Vi kunne bestemt også skrive det hele som en enkelt T-SQL-sætning i SSIS, men den mere interessante mulighed er at oprette en separat datakilde for hvert produkt og bruge en SSIS "Union All"-komponent i stedet for SQL Server-sammenkædningen operatør:
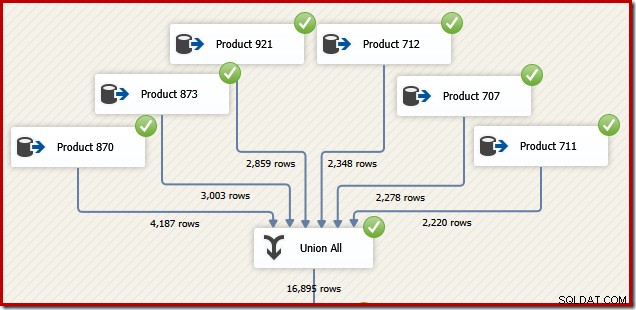
Forestil dig nu, at vi har brug for det endelige output fra det dataflow i transaktions-id-rækkefølge. En mulighed ville være at tilføje en eksplicit Sorter-komponent efter Union All:
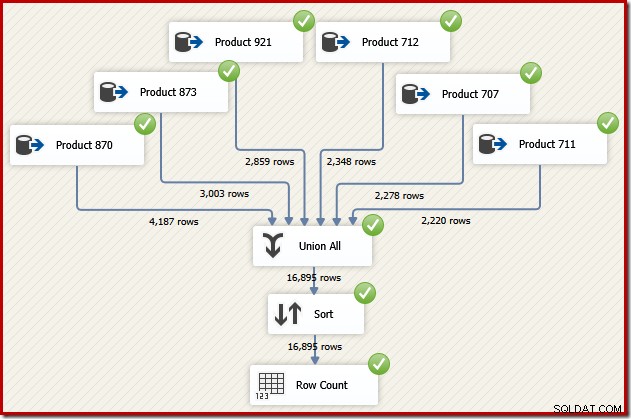
Det ville helt sikkert gøre jobbet, men en dygtig og erfaren SSIS-designer ville indse, at der er en bedre mulighed:læs kildedataene for hvert produkt i transaktions-id-rækkefølgen (ved brug af indekset), og brug derefter en ordrebevarende operation til at kombinere sættene .
I SSIS kaldes den komponent, der kombinerer rækker fra to sorterede datastrømme til et enkelt sorteret dataflow "Merge". Et redesignet SSIS-dataflow, der bruger Merge til at returnere de ønskede rækker i transaktions-id-rækkefølgen, følger:
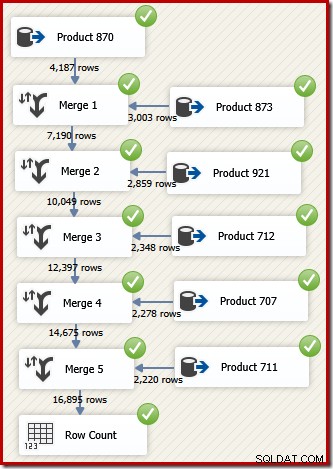
Bemærk, at vi har brug for fem separate Merge-komponenter, fordi Merge er en binær komponent i modsætning til SSIS "Union All"-komponenten, som var n-ær . Det nye fletteflow giver resultater i transaktions-id-rækkefølge uden at kræve en dyr (og blokerende) sorteringskomponent. Faktisk, hvis vi forsøger at tilføje et sortering på transaktions-id efter den endelige fletning, viser SSIS en advarsel for at fortælle os, at strømmen allerede er sorteret på den ønskede måde:
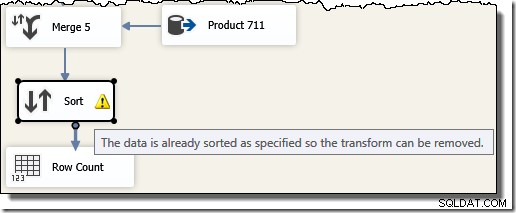
Pointen med SSIS-eksemplet kan nu afsløres. Se på den eksekveringsplan, der er valgt af SQL Server-forespørgselsoptimeringsværktøjet, når vi beder den returnere de originale T-SQL-forespørgselsresultater i transaktions-id-rækkefølgen (ved at tilføje en ORDER BY-klausul):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
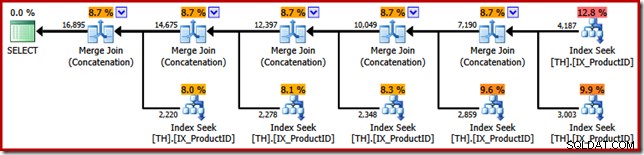
Lighederne med SSIS Merge-pakken er slående; endda ned til behovet for fem binære "Merge"-operatorer. Den ene vigtige forskel er, at SSIS har separate komponenter til "Merge Join" og "Merge", mens SQL Server bruger den samme kerneoperatør til begge.
For at være klar, er Merge Join (Concatenation)-operatørerne i SQL Server-udførelsesplanen ikke udføre en joinforbindelse; motoren genbruger blot den samme fysiske operatør til at implementere ordensbevarende forening.
Skrivning af eksekveringsplaner i SQL Server
SSIS har ikke et dataflowspecifikationssprog og heller ikke en optimizer til at omdanne en sådan specifikation til en eksekverbar Data Flow Task. Det er op til SSIS-pakkedesigneren at indse, at en ordrebevarende fletning er mulig, indstille komponentegenskaber (såsom sorteringsnøgler) korrekt, og derefter sammenligne ydeevne. Dette kræver mere indsats (og dygtighed) fra designerens side, men det giver en meget fin grad af kontrol.
Situationen i SQL Server er den modsatte:vi skriver en forespørgsel specifikation ved at bruge T-SQL-sproget, så afhængig af forespørgselsoptimeringsværktøjet for at udforske implementeringsmuligheder og vælge en effektiv. Vi har ikke mulighed for at konstruere en udførelsesplan direkte. Det meste af tiden er dette yderst ønskværdigt:SQL Server ville uden tvivl være mindre populær, hvis hver forespørgsel krævede, at vi skrev en SSIS-lignende pakke.
Ikke desto mindre (som forklaret i mit tidligere indlæg), kan planen valgt af optimizeren være følsom over for den T-SQL, der bruges til at beskrive de ønskede resultater. Ved at gentage eksemplet fra den artikel kunne vi have skrevet den originale T-SQL-forespørgsel ved hjælp af en alternativ syntaks:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Denne forespørgsel specificerer nøjagtigt det samme resultatsæt som før, men optimeringsværktøjet overvejer ikke en ordrebevarende (flet sammenkædning) plan, og vælger i stedet at scanne det Clustered Index (en meget mindre effektiv mulighed):
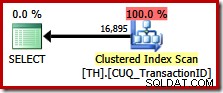
Udnyttelse af ordrebevaring i SQL Server
At undgå unødvendig sortering kan føre til betydelige effektivitetsgevinster, uanset om vi taler om SSIS eller SQL Server. At nå dette mål kan være mere kompliceret og vanskeligt i SQL Server, fordi vi ikke har så finmasket kontrol over udførelsesplanen, men der er stadig ting, vi kan gøre.
Specifikt kan forståelsen af, hvordan SQL Server Merge Join Concatenation-operatøren fungerer internt, hjælpe os med at fortsætte med at skrive klar, relationel T-SQL, samtidig med at forespørgselsoptimeringsværktøjet opfordres til at overveje ordrebevarende (flette) behandlingsmuligheder, hvor det er relevant.
Hvordan Merge Join-sammenkædning fungerer

En almindelig Merge Join kræver, at begge input sorteres på jointasterne. Merge Join Concatenation flettes på den anden side ganske enkelt to allerede bestilte streams til en enkelt ordnet stream – der er ingen join, som sådan.
Dette rejser spørgsmålet:hvad er den 'orden', der er bevaret?
I SSIS skal vi indstille sorteringsnøgleegenskaber på Merge-indgangene for at definere rækkefølgen. SQL Server har ingen ækvivalent til dette. Svaret på spørgsmålet ovenfor er lidt kompliceret, så vi tager det trin for trin.
Overvej følgende eksempel, som anmoder om en fletsammenkædning af to uindekserede heap-tabeller (det enkleste tilfælde):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Disse to tabeller har ingen indekser, og der er ingen ORDER BY-klausul. Hvilken rækkefølge vil "bevare" sammenkædningen af sammenføjningen? For at give dig et øjeblik til at tænke over det, lad os først se på den eksekveringsplan, der er udarbejdet for forespørgslen ovenfor i SQL Server-versioner før 2012:
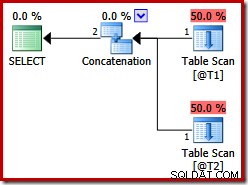
Der er ingen Merge Join-sammenkædning på trods af forespørgselstip:før SQL Server 2012 virker dette tip kun med UNION, ikke UNION ALL. For at få en plan med den ønskede fletteoperatør skal vi deaktivere implementeringen af en logisk UNION ALL (UNIA) ved hjælp af den fysiske operatør Concatenation (CON). Bemærk venligst, at følgende er udokumenteret og ikke understøttet til produktionsbrug:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Denne forespørgsel producerer den samme plan som SQL Server 2012 og 2014 gør med MERGE UNION-forespørgselstip alene:
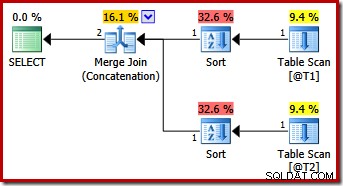
Måske uventet indeholder udførelsesplanen eksplicitte sorteringer på begge input til fusionen. Sorteringsegenskaberne er:
Det giver mening, at en ordrebevarende fletning kræver en konsistent inputrækkefølge, men hvorfor valgte den (c1, c2, c3) i stedet for f.eks. (c3, c1, c2) eller (c2, c3, c1)? Som udgangspunkt sorteres flettesammenkædningsinput på outputprojektionslisten. Vælg-stjernen i forespørgslen udvides til (c1, c2, c3), så det er den valgte rækkefølge.
Sortér efter Merge Output Projection List
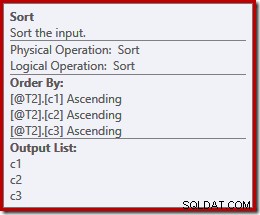
For yderligere at illustrere pointen kan vi selv udvide select-stjernen (som vi burde!) ved at vælge en anden rækkefølge (c3, c2, c1), mens vi er i gang:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Sorteringerne ændres nu til at matche (c3, c2, c1):
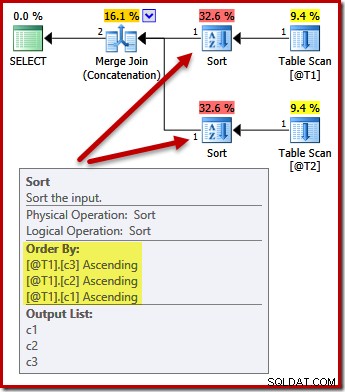
Igen, forespørgslen output ordre (forudsat at vi skulle tilføje nogle data til tabellerne) er ikke garanteret at blive sorteret som vist, fordi vi ikke har nogen ORDER BY-klausul. Disse eksempler er blot beregnet til at vise, hvordan optimeringsværktøjet vælger en indledende sorteringsrækkefølge for input, i mangel af anden grund til at sortere.
Modstridende sorteringsrækkefølger
Overvej nu, hvad der sker, hvis vi forlader projektionslisten som (c3, c2, c1) og tilføjer et krav om at sortere forespørgselsresultaterne efter (c1, c2, c3). Vil input til fletningen stadig sorteres efter (c3, c2, c1) med en efterfletningssortering på (c1, c2, c3) for at opfylde ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Nej. Optimeringsværktøjet er smart nok til at undgå at sortere to gange:
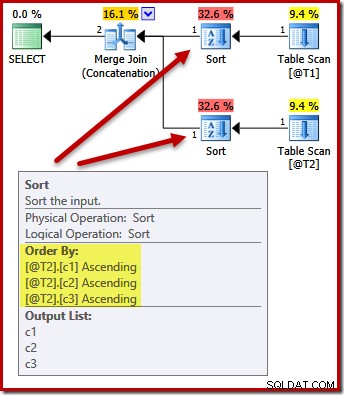
At sortere begge input på (c1, c2, c3) er helt acceptabelt for flettesammenkædningen, så der kræves ingen dobbeltsortering.
Bemærk, at denne plan gør garantere, at rækkefølgen af resultater vil være (c1, c2, c3). Planen ser ud som de tidligere planer uden ORDER BY, men ikke alle de interne detaljer er præsenteret i brugersynlige udførelsesplaner.
Effekten af unikhed
Ved valg af sorteringsrækkefølge for fletteindgangene, påvirkes optimeringsværktøjet også af eventuelle unikke garantier, der findes. Overvej følgende eksempel med fem kolonner, men bemærk de forskellige kolonnerækkefølger i UNION ALL-operationen:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
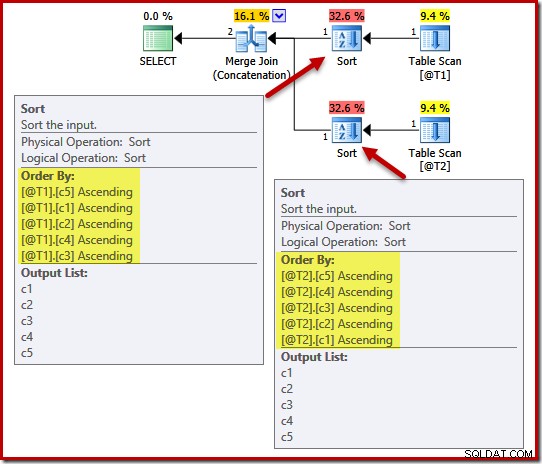
Udførelsesplanen inkluderer sorteringer på (c5, c1, c2, c4, c3) for tabel @T1 og (c5, c4, c3, c2, c1) for tabel @T2:
For at demonstrere effekten af unikhed på disse typer vil vi tilføje en UNIK begrænsning til kolonne c1 i tabel T1 og kolonne c4 i tabel T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
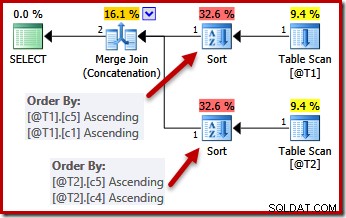
Pointen med unikhed er, at optimizeren ved, at den kan stoppe med at sortere, så snart den støder på en kolonne, der med garanti er unik. Sortering efter yderligere kolonner, efter at en unik nøgle er stødt på, vil per definition ikke påvirke den endelige sorteringsrækkefølge.
Med UNIQUE-begrænsningerne på plads kan optimeringsværktøjet forenkle (c5, c1, c2, c4, c3) sorteringslisten for T1 til (c5, c1), fordi c1 er unik. På samme måde er (c5, c4, c3, c2, c1) sorteringslisten for T2 forenklet til (c5, c4), fordi c4 er en nøgle:
Parallelisme
Forenklingen på grund af en unik nøgle er ikke perfekt implementeret. I en parallel plan er strømmene opdelt, så alle rækker for samme forekomst af fletningen ender på den samme tråd. Denne datasætpartitionering er baseret på flettekolonnerne og ikke forenklet ved tilstedeværelsen af en nøgle.
Følgende script bruger ikke-understøttet sporingsflag 8649 til at generere en parallel plan for den tidligere forespørgsel (som ellers er uændret):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
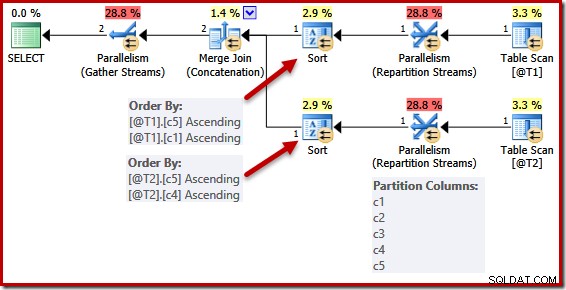
Sorteringslisterne er forenklet som før, men operatørerne for omfordelingsstrømme opdeler stadig over alle kolonner. Hvis denne forenkling blev implementeret konsekvent, ville omfordelingsoperatørerne også operere på (c5, c1) og (c5, c4) alene.
Problemer med ikke-unikke indekser
Den måde, hvorpå optimeringsværktøjet begrunder sorteringskravene for flettesammenkædning, kan resultere i unødvendige sorteringsproblemer, som det næste eksempel viser:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Ser vi på forespørgslen og tilgængelige indekser, ville vi forvente en eksekveringsplan, der udfører en ordnet scanning af de klyngede indekser, ved at bruge flettet sammenkædning for at undgå behovet for enhver sortering. Denne forventning er fuldt ud berettiget, fordi de klyngede indekser giver den rækkefølge, der er angivet i ORDER BY-klausulen. Desværre omfatter den plan, vi faktisk får, to slags:
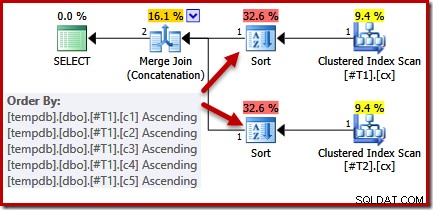
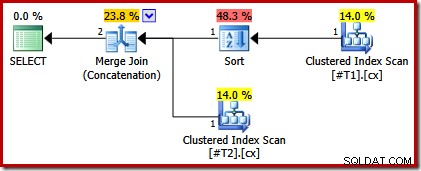
Der er ingen god grund til disse typer, de vises kun, fordi forespørgselsoptimeringslogikken er ufuldkommen. Listen med fletteoutputkolonne (c1, c2, c3, c4, c5) er et supersæt af ORDER BY, men der er ingen unik nøglen til at forenkle denne liste. Som et resultat af dette hul i optimizerens ræsonnement, konkluderer den, at fusionen kræver dets input sorteret efter (c1, c2, c3, c4, c5).
Vi kan verificere denne analyse ved at ændre scriptet for at gøre et af de klyngede indekser unikt:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Udførelsesplanen har nu kun en sortering over tabellen med det ikke-unikke indeks:
Hvis vi nu laver begge dele klyngede indekser unikke, ingen sorteringer vises:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Med begge indekser unikke, kan de indledende sammenflettede inputsorteringslister forenkles til kolonne c1 alene. Den forenklede liste matcher derefter ORDER BY-klausulen nøjagtigt, så ingen sorteringer er nødvendige i den endelige plan:
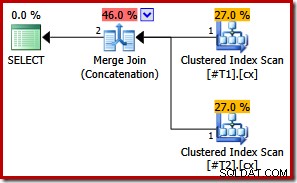
Bemærk, at vi ikke engang har brug for forespørgselstippet i dette sidste eksempel for at få den optimale eksekveringsplan.
Sidste tanker
Det kan være vanskeligt at fjerne sorteringer i en udførelsesplan. I nogle tilfælde kan det være så simpelt som at ændre et eksisterende indeks (eller levere et nyt) for at levere rækker i den påkrævede rækkefølge. Forespørgselsoptimeringsværktøjet udfører generelt et rimeligt stykke arbejde, når passende indekser er tilgængelige.
I (mange) andre tilfælde kan det dog kræve en meget dybere forståelse af udførelsesmotoren, forespørgselsoptimeringen og planoperatørerne selv. At undgå sorteringer er utvivlsomt et avanceret emne til justering af forespørgsler, men også et utroligt givende, når alt kommer rigtigt.