JPA (Java Persistence Annotation ) er Javas standardløsning til at bygge bro mellem objektorienterede domænemodeller og relationelle databasesystemer. Ideen er at kortlægge Java-klasser til relationelle tabeller og egenskaber for disse klasser til rækkerne i tabellen. Dette ændrer semantikken for den samlede oplevelse af Java-kodning ved problemfrit at samarbejde to forskellige teknologier inden for samme programmeringsparadigme. Denne artikel giver et overblik og dens understøttende implementering i Java.
En oversigt
Relationelle databaser er måske den mest stabile af alle de persistensteknologier, der er tilgængelige inden for databehandling, i stedet for alle de kompleksiteter, der er forbundet med det. Det er fordi i dag, selv i en tid med såkaldte "big data", er "NoSQL" relationelle databaser konsekvent efterspurgte og blomstrende. Relationelle databaser er stabil teknologi, ikke ved blotte ord, men ved dens eksistens gennem årene. NoSQL kan være god til at håndtere store mængder strukturerede data i virksomheden, men de mange transaktionsmæssige arbejdsbelastninger håndteres bedre gennem relationelle databaser. Der er også nogle gode analytiske værktøjer forbundet med relationelle databaser.
For at kommunikere med relationel database har ANSI standardiseret et sprog kaldet SQL (Structured Query Language ). En erklæring skrevet på dette sprog kan bruges både til at definere og manipulere data. Men problemet med SQL i håndteringen af Java er, at de har en uoverensstemmende syntaktisk struktur og meget forskellige i kernen, hvilket betyder, at SQL er proceduremæssigt, mens Java er objektorienteret. Så der søges en fungerende løsning, så Java kan tale på objektorienteret måde, og den relationelle database vil stadig være i stand til at forstå hinanden. JPA er svaret på det opkald og giver mekanismen til at etablere en fungerende løsning mellem de to.
Relation til objektkortlægning
Java-programmer interagerer med relationelle databaser ved at bruge JDBC (Java-databaseforbindelse ) API. En JDBC-driver er nøglen til forbindelsen og tillader et Java-program at manipulere denne database ved at bruge JDBC API. Når forbindelsen er etableret, udløser Java-programmet SQL-forespørgsler i form af String s at kommunikere oprette, indsætte, opdatere og slette handlinger. Dette er tilstrækkeligt til alle praktiske formål, men ubelejligt fra en Java-programmørs synspunkt. Hvad hvis strukturen af relationelle tabeller kan omdannes til rene Java-klasser, og så kan du håndtere dem på den sædvanlige objektorienterede måde? Strukturen af en relationstabel er en logisk repræsentation af data i tabelform. Tabeller er sammensat af kolonner, der beskriver enhedsattributter, og rækker er samlingen af enheder. For eksempel kan en MEDARBEJDER-tabel indeholde følgende entiteter med deres attributter.
| Emp_number | Navn | dept_no | Løn | Sted |
| 112233 | Peter | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Rækker er unikke af primær nøgle (emp_number) i en tabel; dette muliggør en hurtig søgning. En tabel kan være relateret til en eller flere tabeller med en eller anden nøgle, såsom en fremmednøgle (dept_no), der relaterer til den tilsvarende række i en anden tabel.
I henhold til Java Persistence 2.1-specifikationen tilføjer JPA understøttelse af skemagenerering, typekonverteringsmetoder, brug af entitetsgraf i forespørgsler og søgeoperationer, usynkroniseret persistenskontekst, opkald til lagret procedure og indsprøjtning i entitetslytterklasser. Det inkluderer også forbedringer til Java Persistence-forespørgselssproget, Criteria API og til kortlægningen af indbyggede forespørgsler.
Kort sagt, det gør alt for at give den illusion, at der ikke er nogen proceduremæssig del i håndteringen af relationelle databaser, og at alt er objektorienteret.
JPA-implementering
JPA beskriver relationel datastyring i Java-applikation. Det er en specifikation, og der er en række implementeringer af den. Nogle populære implementeringer er Hibernate, EclipseLink og Apache OpenJPA. JPA definerer metadataene via annoteringer i Java-klasser eller via XML-konfigurationsfiler. Vi kan dog bruge både XML og annotering til at beskrive metadataene. I et sådant tilfælde tilsidesætter XML-konfigurationen annoteringerne. Dette er rimeligt, fordi annoteringer er skrevet med Java-koden, hvorimod XML-konfigurationsfiler er eksterne i forhold til Java-kode. Derfor skal der senere, hvis nogen, foretages ændringer i metadataene; i tilfælde af annotationsbaseret konfiguration kræver det direkte Java-kodeadgang. Dette er muligvis ikke altid muligt. I et sådant tilfælde kan vi skrive ny eller ændret metadata-konfiguration i en XML-fil uden antydning af ændring i den originale kode og stadig have den ønskede effekt. Dette er fordelen ved at bruge XML-konfiguration. Annotationsbaseret konfiguration er dog mere bekvem at bruge og er det populære valg blandt programmører.
- Dvale er den populære og mest avancerede blandt alle JPA-implementeringer på grund af Red Hat. Den bruger sine egne tweaks og tilføjede funktioner, der kan bruges ud over dens JPA-implementering. Det har et større fællesskab af brugere og er veldokumenteret. Nogle af de yderligere proprietære funktioner er understøttelse af multi-lejemål, sammenføjning af ikke-tilknyttede enheder i forespørgsler, tidsstemplingsstyring og så videre.
- EclipseLink er baseret på TopLink og er en referenceimplementering af JPA-versioner. Det giver standard JPA-funktioner bortset fra nogle interessante proprietære funktioner, såsom support fra multi-tenancy, håndtering af databaseændringshændelser og så videre.
Brug af JPA i et Java SE-program
For at bruge JPA i et Java-program, skal du bruge en JPA-udbyder såsom Hibernate eller EclipseLink eller et hvilket som helst andet bibliotek. Du har også brug for en JDBC-driver, der forbinder til den specifikke relationsdatabase. For eksempel har vi i følgende kode brugt følgende biblioteker:
- Udbyder: EclipseLink
- JDBC-driver: JDBC-driver til MySQL (Connector/J)
Vi etablerer et forhold mellem to tabeller – medarbejder og afdeling – som én-til-en og én-til-mange, som afbildet i følgende EER-diagram (se figur 1).
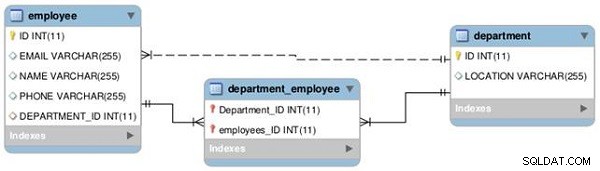
Figur 1: Tabelforhold
medarbejderen tabel er knyttet til en enhedsklasse ved hjælp af annotering som følger:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
Og afdelingen tabel er knyttet til en enhedsklasse som følger:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Konfigurationsfilen, persistence.xml , oprettes i META-INF vejviser. Denne fil indeholder forbindelseskonfigurationen, såsom den anvendte JDBC-driver, brugernavn og adgangskode til databaseadgang og andre relevante oplysninger, der kræves af JPA-udbyderen for at etablere databaseforbindelsen.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Enheder består ikke selv. Logik skal anvendes til at manipulere enheder til at styre deres vedvarende livscyklus. EntityManager grænsefladen leveret af JPA lader applikationen administrere og søge efter enheder i relationsdatabasen. Vi opretter et forespørgselsobjekt ved hjælp af EntityManager at kommunikere med databasen. For at få EntityManager for en given database bruger vi et objekt, der implementerer en EntityManagerFactory interface. Der er en statisk metode, kaldet createEntityManagerFactory , i Persistence klasse, der returnerer EntityManagerFactory for persistensenheden angivet som en streng argument. I den følgende rudimentære implementering har vi implementeret logikken.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Nu er vi klar til at gå og oprette applikationens hovedgrænseflade. Her har vi kun implementeret indsættelsesoperationen af hensyn til enkelheden og pladsbegrænsningerne.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Bemærk: Se venligst den relevante Java API-dokumentation for detaljerede oplysninger om API'er brugt i den foregående kode. |
Konklusion
Som det burde være indlysende, er kerneterminologien for JPA og Persistens kontekst større end glimtet givet her, men at begynde med et hurtigt overblik er bedre end lang indviklet beskidt kode og deres konceptuelle detaljer. Hvis du har lidt programmeringserfaring i kerne JDBC, vil du uden tvivl sætte pris på, hvordan JPA kan gøre dit liv enklere. Vi vil gradvist dykke dybere ned i JPA, efterhånden som vi fortsætter i kommende artikler.