Et af de filtrerede indeksbrug, der er nævnt i Books Online, vedrører en kolonne, der for det meste indeholder NULL værdier. Ideen er at skabe et filtreret indeks, der udelukker NULLs , hvilket resulterer i et mindre ikke-klynget indeks, der kræver mindre vedligeholdelse end det tilsvarende ufiltrerede indeks. En anden populær brug af filtrerede indekser er at filtrere NULLs fra en UNIQUE indeks, hvilket giver den adfærd, som brugere af andre databasemotorer kan forvente af en standard UNIQUE indeks eller begrænsning:entydighed håndhæves kun for ikke-NULL værdier.
Forespørgselsoptimeringsværktøjet har desværre begrænsninger, hvad angår filtrerede indekser. Dette indlæg ser på et par mindre kendte eksempler.
Eksempeltabeller
Vi vil bruge to tabeller (A &B), der har samme struktur:en surrogat-klyngede primærnøgle, en hovedsagelig-NULL kolonne, der er unik (se bort fra NULLs ), og en udfyldningskolonne, der repræsenterer de andre kolonner, der kan være i en rigtig tabel.
Interessekolonnen er for det meste NULL en, som jeg har erklæret som SPARSE . Den sparsomme mulighed er ikke påkrævet, jeg inkluderer den bare, fordi jeg ikke får meget chance for at bruge den. Under alle omstændigheder SPARSE giver sandsynligvis mening i mange scenarier, hvor kolonnedataene forventes at være for det meste NULL . Du er velkommen til at fjerne den sparsomme attribut fra eksemplerne, hvis du vil.
CREATE TABLE dbo.TableA( pk heltal IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk heltal IDENTITY PRIMARY KEY, data bigint SPARSE NULL, polstring binær(250) NOT NULL DEFAULT 0x);
Hver tabel indeholder tallene fra 1 til 2.000 i datakolonnen med yderligere 40.000 rækker, hvor datakolonnen er NULL :
-- Tal 1 - 2.000INSERT dbo.TableA MED (TABLOCKX) (data)VÆLG TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FRA sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() OVER (ORDER BY (SELECT NULL)); -- NULLsINSERT TOP (40000) dbo.TableA MED (TABLOCKX) (data)VÆLG KONVERTER(bigint, NULL)FRA sys.columns AS cCROSS JOIN sys.columns AS c2; -- Kopiér ind i TableBINSERT dbo.TableB MED (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Begge borde får en UNIQUE filtreret indeks for de 2.000 ikke-NULL dataværdier:
OPRET UNIKT IKKE-KLYGERET INDEKS uqAON dbo.TableA (data) HVOR data IKKE ER NULL; OPRET UNIKT IKKE-KLYNGERET INDEX uqBON dbo.TableB (data) HVOR data IKKE ER NULL;
Outputtet fra DBCC SHOW_STATISTICS opsummerer situationen:
DBCC SHOW_STATISTICS (TabelA, uqA) MED STAT_HEADER;DBCC SHOW_STATISTICS (TabelB, uqB) MED STAT_HEADER;

Eksempelforespørgsel
Forespørgslen nedenfor udfører en simpel sammenføjning af de to tabeller – forestil dig, at tabellerne er i en form for forældre-barn-forhold, og mange af fremmednøglerne er NULL. Noget i den retning alligevel.
VÆLG ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Standard eksekveringsplan
Med SQL Server i standardkonfigurationen vælger optimeringsværktøjet en eksekveringsplan med en parallel indlejret sløjfesammenføjning:
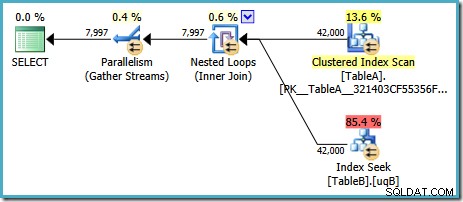
Denne plan har en anslået pris på 7,7768 magic optimizer units™.
Der er dog nogle mærkelige ting ved denne plan. Indekssøgningen bruger vores filtrerede indeks på tabel B, men forespørgslen er drevet af en Clustered Index Scan af tabel A. Join-prædikatet er en lighedstest på datakolonnerne, som vil afvise NULLs (uanset ANSI_NULLS indstilling). Vi havde måske håbet, at optimeringsværktøjet ville udføre nogle avancerede ræsonnementer baseret på den observation, men nej. Denne plan læser hver række fra tabel A (inklusive de 40.000 NULLs ), udfører en søgning i det filtrerede indeks i tabel B for hver enkelt, idet man stoler på, at NULL vil ikke matche NULL i den søgen. Dette er et enormt spild af indsats.
Det mærkelige er, at optimeringsværktøjet må have indset, at joinforbindelsen afviser NULLs for at vælge det filtrerede indeks for tabellen B-søge, men det tænkte ikke på at filtrere NULLs fra tabel A først – eller endnu bedre, for blot at scanne NULL -gratis filtreret indeks på tabel A. Du spekulerer måske på, om dette er en omkostningsbaseret beslutning, måske er statistikken ikke særlig god? Måske skulle vi fremtvinge brugen af det filtrerede indeks med et hint? Antydning af det filtrerede indeks på tabel A resulterer bare i den samme plan med rollerne omvendt – scanning af tabel B og søgning ind i tabel A. Tvingning af det filtrerede indeks for begge tabeller giver fejl 8622 :forespørgselsprocessoren kunne ikke producere en forespørgselsplan.
Tilføjelse af et IKKE NULL-prædikat
Mistanke om årsagen til at være noget at gøre med den underforståede NULL -afvisning af join-prædikatet, tilføjer vi en eksplicit NOT NULL prædikat til ON klausul (eller WHERE klausul, hvis du foretrækker det, kommer det til det samme her):
VÆLG ta.data, tb.dataFRA dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data OG ta.data ER IKKE NULL;
Vi tilføjede NOT NULL tjek til tabel A-kolonnen, fordi den oprindelige plan scannede tabellens klyngede indeks i stedet for at bruge vores filtrerede indeks (søgningen i tabel B var fin - den brugte det filtrerede indeks). Den nye forespørgsel er semantisk nøjagtig den samme som den forrige, men udførelsesplanen er anderledes:
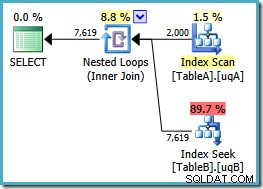
Nu har vi den håbede scanning af det filtrerede indeks i tabel A, der producerer 2.000 ikke-NULL rækker for at drive de indlejrede løkkesøgninger ind i tabel B. Begge tabeller bruger vores filtrerede indekser tilsyneladende optimalt nu:den nye plan koster kun 0,362835 enheder (ned fra 7,7768). Vi kan dog gøre det bedre.
Tilføjelse af to IKKE NULL-prædikater
Den redundante NOT NULL prædikat for tabel A gjorde underværker; hvad sker der, hvis vi også tilføjer en til tabel B?
VÆLG ta.data, tb.dataFRA dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data OG ta.data ER IKKE NULL OG tb.data ER IKKE NULL;
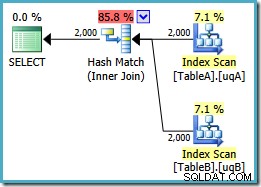
Denne forespørgsel er stadig logisk den samme som de to tidligere forsøg, men udførelsesplanen er anderledes igen:
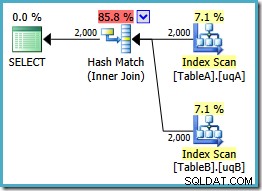
Denne plan opbygger en hash-tabel for de 2.000 rækker fra tabel A og prober derefter efter match ved hjælp af de 2.000 rækker fra tabel B. Det estimerede antal returnerede rækker er meget bedre end tidligere plan (lagde du mærke til estimatet på 7.619 der?), og de anslåede udførelsesomkostninger er faldet igen, fra 0,362835 til 0,0772056 .
Du kan prøve at tvinge en hash-join ved at bruge et tip om originalen eller enkelt-NOT NULL forespørgsler, men du får ikke lavprisplanen vist ovenfor. Optimizeren har bare ikke evnen til fuldt ud at ræsonnere om NULL -afvisende adfærd for joinforbindelsen, da den gælder for vores filtrerede indekser uden begge overflødige prædikater.
Du har lov til at blive overrasket over dette – også selvom det bare er tanken om, at et overflødigt prædikat ikke var nok (sikkert hvis ta.data er NOT NULL og ta.data = tb.data , følger det, at tb.data er også NOT NULL , ikke?)
Stadig ikke perfekt
Det er lidt overraskende at se en hash deltage der. Hvis du er bekendt med de vigtigste forskelle mellem de tre fysiske join-operatører, ved du sikkert, at hash join er en topkandidat, hvor:
- Forudsorteret input er ikke tilgængelig
- Hash-building-input er mindre end sonde-input
- Probeinputtet er ret stort
Ingen af disse ting er sande her. Vores forventning ville være, at den bedste plan for denne forespørgsel og dette datasæt ville være en sammenføjning, der udnytter det bestilte input, der er tilgængeligt fra vores to filtrerede indekser. Vi kan prøve at antyde en sammenføjning, og bibeholde de to ekstra ON klausul prædikater:
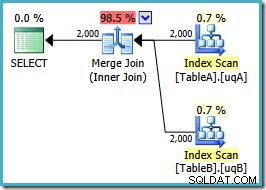
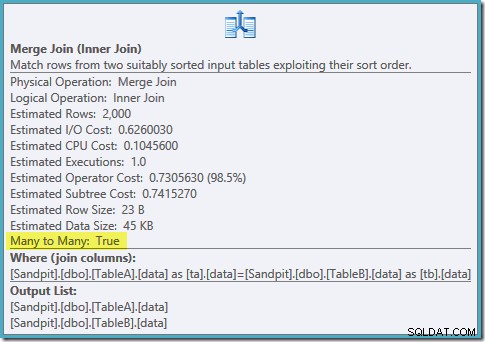
VÆLG ta.data, tb.dataFRA dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data OG ta.data ER IKKE NULL OG tb.data ER IKKE NULLOPTION (FLET JOIN);Planformen er som vi håbede:
En ordnet scanning af begge filtrerede indekser, fantastiske skøn over kardinalitet, fantastisk. Bare et lille problem:denne udførelsesplan er meget værre; de anslåede omkostninger er steget fra 0,0772056 til 0,741527 . Årsagen til springet i estimerede omkostninger afsløres ved at kontrollere egenskaberne for sammenføjningsoperatøren:
Dette er en dyr mange-til-mange join, hvor execution engine skal holde styr på dubletter fra det ydre input i en arbejdstabel og spole tilbage efter behov. Dubletter? Vi scanner et unikt indeks! Det viser sig, at optimeringsværktøjet ikke ved, at et filtreret unikt indeks producerer unikke værdier (tilslut emne her). Faktisk er dette en en-til-en-forbindelse, men optimeringsværktøjet koster det, som om det var mange-til-mange, hvilket forklarer, hvorfor det foretrækker hash join-planen.
En alternativ strategi
Det ser ud til, at vi bliver ved med at støde på optimeringsbegrænsninger, når vi bruger filtrerede indekser her (på trods af, at det er et fremhævet tilfælde i Books Online). Hvad sker der, hvis vi prøver at bruge visninger i stedet for?
Brug af visninger
De følgende to visninger filtrerer bare basistabellerne for at vise rækkerne, hvor datakolonnen er
NOT NULL:OPRET VISNING dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableAWHERE data ER IKKE NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data ER IKKE NULL;Omskrivning af den originale forespørgsel for at bruge visningerne er trivielt:
SELECT v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;Husk, at denne forespørgsel oprindeligt producerede en plan med parallelle indlejrede sløjfer til en pris på 7,7768 enheder. Med visningsreferencerne får vi denne udførelsesplan:
Dette er nøjagtig den samme hash join-plan, som vi skulle tilføje redundante
NOT NULLprædikater at få med de filtrerede indekser (prisen er 0,0772056 enheder som før). Dette forventes, fordi alt, hvad vi i det væsentlige har gjort her, er at skubbe den ekstraNOT NULLprædikater fra forespørgslen til en visning.Indeksering af visningerne
Vi kan også prøve at materialisere visningerne ved at oprette et unikt klynget indeks i pk-kolonnen:
OPRET UNIKT KLUSTERET INDEKS cuq PÅ dbo.VA (pk);OPRET UNIKT KLUSTERET INDEX cuq PÅ dbo.VB (pk);Nu kan vi tilføje unikke ikke-klyngede indekser på den filtrerede datakolonne i den indekserede visning:
OPRET UNIKT IKKE-KLYNGERET INDEX ix PÅ dbo.VA (data);OPRET UNIKT IKKE-KLYNGERET INDEX ix PÅ dbo.VB (data);Bemærk, at filtreringen udføres i visningen, disse ikke-klyngede indekser er ikke i sig selv filtreret.
Den perfekte plan
Vi er nu klar til at køre vores forespørgsel mod visningen ved hjælp af
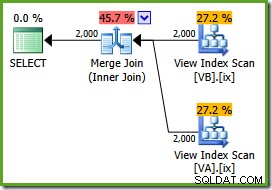
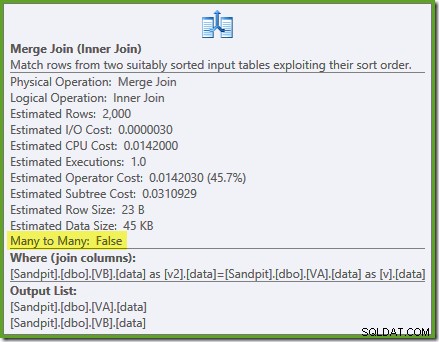
NOEXPANDtabeltip:SELECT v.data, v2.dataFROM dbo.VA AS v MED (NOEXPAND)JOIN dbo.VB AS v2 MED (NOEXPAND) ON v.data =v2.data;Udførelsesplanen er:
Optimeringsværktøjet kan se de ufiltrerede Ikke-klyngede visningsindekser er unikke, så en mange-til-mange-fusion er ikke nødvendig. Denne endelige udførelsesplan har en anslået pris på 0,0310929 enheder – endnu lavere end hash-sammenføjningsplanen (0,0772056 enheder). Dette bekræfter vores forventning om, at en sammenføjning burde have den laveste estimerede pris for denne forespørgsel og eksempeldatasæt.
NOEXPANDtip er nødvendige selv i Enterprise Edition for at sikre, at den unikke garanti, som visningsindekserne giver, bruges af optimeringsværktøjet.Oversigt
Dette indlæg fremhæver to vigtige optimeringsbegrænsninger med filtrerede indekser:
- Redundante joinprædikater kan være nødvendige for at matche filtrerede indekser
- Filtrerede unikke indekser giver ikke unikkeoplysninger til optimeringsværktøjet
I nogle tilfælde kan det være praktisk blot at tilføje de overflødige prædikater til hver forespørgsel. Alternativet er at indkapsle de ønskede underforståede prædikater i en uindekseret visning. Hash-match-planen i dette indlæg var meget bedre end standardplanen, selvom optimeringsværktøjet burde være i stand til at finde den lidt bedre sammenføjningsplan. Nogle gange skal du muligvis indeksere visningen og bruge NOEXPAND hints (påkrævet alligevel for Standard Edition-forekomster). Under endnu andre omstændigheder vil ingen af disse tilgange være egnede. Beklager det :)