Der er mange use cases til at generere en sekvens af værdier i SQL Server. Jeg taler ikke om en vedvarende IDENTITY kolonne (eller den nye SEQUENCE i SQL Server 2012), men snarere et forbigående sæt, der kun skal bruges i en forespørgsels levetid. Eller endda de simpleste tilfælde – som f.eks. blot at tilføje et rækkenummer til hver række i et resultatsæt – som kan involvere tilføjelse af en ROW_NUMBER() funktion til forespørgslen (eller endnu bedre, i præsentationsniveauet, som alligevel skal gennemgå resultaterne række for række).
Jeg taler om lidt mere komplicerede sager. For eksempel kan du have en rapport, der viser salg efter dato. En typisk forespørgsel kan være:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Problemet med denne forespørgsel er, at hvis der ikke er nogen ordrer på en bestemt dag, vil der ikke være nogen række for den dag. Dette kan føre til forvirring, vildledende data eller endda forkerte beregninger (tænk daglige gennemsnit) for downstream-forbrugerne af dataene.
Så der er behov for at udfylde disse huller med de datoer, der ikke er til stede i dataene. Og nogle gange vil folk proppe deres data ind i en #temp-tabel og bruge en WHILE sløjfe eller en markør for at udfylde de manglende datoer én efter én. Jeg vil ikke vise den kode her, fordi jeg ikke ønsker at anbefale dens brug, men jeg har set den overalt.
Før vi går for dybt ind i datoer, lad os dog først tale om tal, da du altid kan bruge en talfølge til at udlede en række af datoer.
Taltabellen
Jeg har længe været fortaler for at gemme en ekstra "taltabel" på disken (og for den sags skyld også en kalendertabel).
Her er en måde at generere en simpel taltabel med 1.000.000 værdier på:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Hvorfor MAXDOP 1? Se Paul Whites blogindlæg og hans Connect-emne vedrørende rækkemål.
Mange mennesker er dog imod tilgangen til hjælpeborde. Deres argument:hvorfor gemme alle disse data på disken (og i hukommelsen), når de kan generere dataene på farten? Min tæller er at være realistisk og tænke over, hvad du optimerer; beregning kan være dyrt, og er du sikker på, at det altid vil være billigere at beregne en række tal i farten? Hvad angår plads, fylder Numbers-tabellen kun omkring 11 MB komprimeret og 17 MB ukomprimeret. Og hvis tabellen refereres ofte nok, bør den altid være i hukommelsen, hvilket gør adgangen hurtig.
Lad os tage et kig på et par eksempler og nogle af de mere almindelige metoder, der bruges til at tilfredsstille dem. Jeg håber, at vi alle kan blive enige om, at vi, selv ved 1.000 værdier, ikke ønsker at løse disse problemer ved hjælp af en loop eller en markør.
Generering af en sekvens på 1.000 numre
Lad os starte enkelt og generere et sæt tal fra 1 til 1.000.
Taltabellen
Selvfølgelig med en taltabel er denne opgave ret enkel:
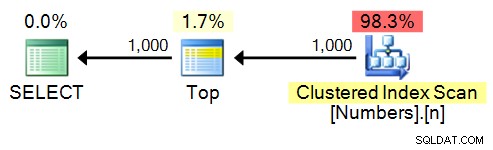
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plan:
spt_values
Dette er en tabel, der bruges af interne lagrede procedurer til forskellige formål. Dets brug online ser ud til at være ret udbredt, selvom det er udokumenteret, ikke understøttet, kan det forsvinde en dag, og fordi det kun indeholder et begrænset, ikke-unik og ikke-sammenhængende sæt værdier. Der er 2.164 unikke og 2.508 samlede værdier i SQL Server 2008 R2; i 2012 er der 2.167 unikke og 2.515 i alt. Dette inkluderer dubletter, negative værdier og selv hvis du bruger DISTINCT , masser af huller, når du kommer ud over tallet 2.048. Så løsningen er at bruge ROW_NUMBER() for at generere en sammenhængende sekvens, startende ved 1, baseret på værdierne i tabellen.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plan:

Når det er sagt, for kun 1.000 værdier kunne du skrive en lidt enklere forespørgsel for at generere den samme sekvens:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Dette fører selvfølgelig til en enklere plan, men går ret hurtigt i stykker (når din sekvens skal være mere end 2.048 rækker):
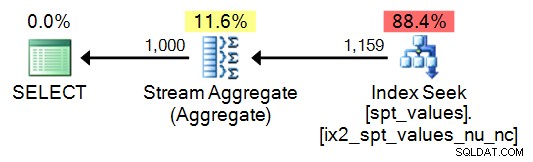
Under alle omstændigheder anbefaler jeg ikke brugen af denne tabel; Jeg inkluderer det til sammenligningsformål, kun fordi jeg ved, hvor meget af det her er derude, og hvor fristende det kan være bare at genbruge kode, du støder på.
sys.all_objects
En anden tilgang, der har været en af mine favoritter gennem årene, er at bruge sys.all_objects . Ligesom spt_values , er der ingen pålidelig måde at generere en sammenhængende sekvens direkte, og vi har de samme problemer, der handler om et begrænset sæt (lige under 2.000 rækker i SQL Server 2008 R2 og lidt over 2.000 rækker i SQL Server 2012), men for 1.000 rækker vi kan bruge den samme ROW_NUMBER() trick. Grunden til at jeg kan lide denne tilgang er, at (a) der er mindre bekymring for, at denne visning vil forsvinde når som helst snart, (b) selve visningen er dokumenteret og understøttet, og (c) den vil køre på enhver database på enhver version siden SQL Server 2005 uden at skulle krydse databasegrænser (inklusive indeholdte databaser).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plan:

Stablede CTE'er
Jeg mener, at Itzik Ben-Gan fortjener den ultimative ære for denne tilgang; dybest set konstruerer du en CTE med et lille sæt værdier, så opretter du det kartesiske produkt mod sig selv for at generere det antal rækker, du har brug for. Og igen, i stedet for at forsøge at generere et sammenhængende sæt som en del af den underliggende forespørgsel, kan vi bare anvende ROW_NUMBER() til det endelige resultat.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plan:
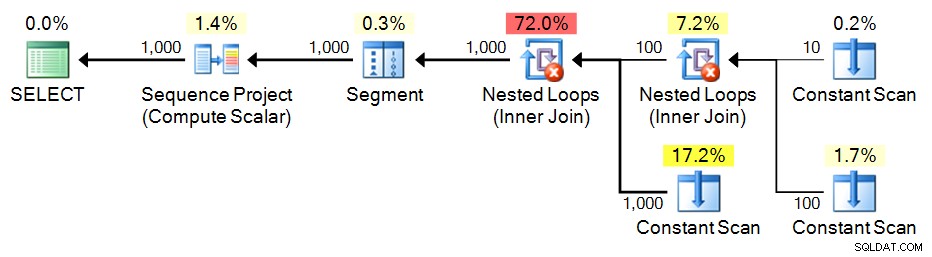
Rekursiv CTE
Endelig har vi en rekursiv CTE, som bruger 1 som anker og tilføjer 1, indtil vi rammer maksimum. For en sikkerheds skyld angiver jeg maksimum i både WHERE klausul af den rekursive del og i MAXRECURSION indstilling. Afhængigt af hvor mange numre du har brug for, skal du muligvis indstille MAXRECURSION til 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plan:
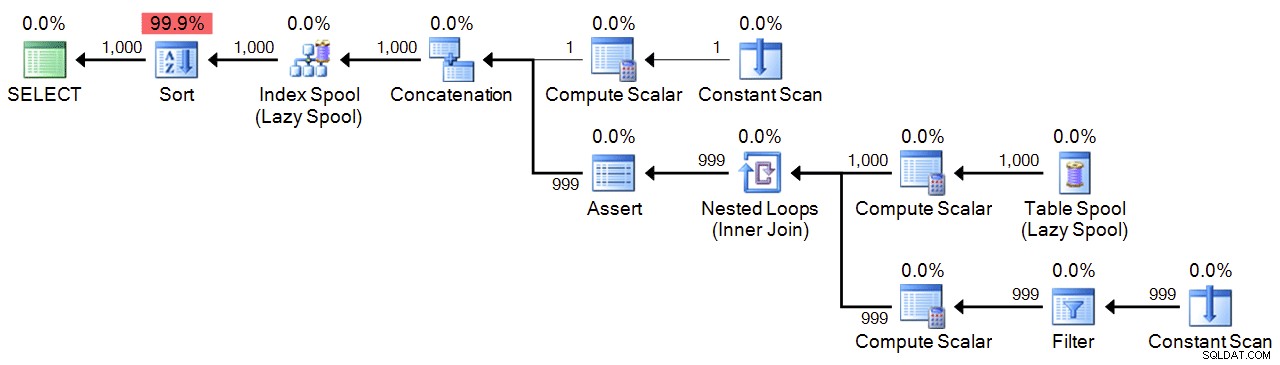
Ydeevne
Med 1.000 værdier er forskellene i ydeevne selvfølgelig ubetydelige, men det kan være nyttigt at se, hvordan disse forskellige muligheder klarer sig:
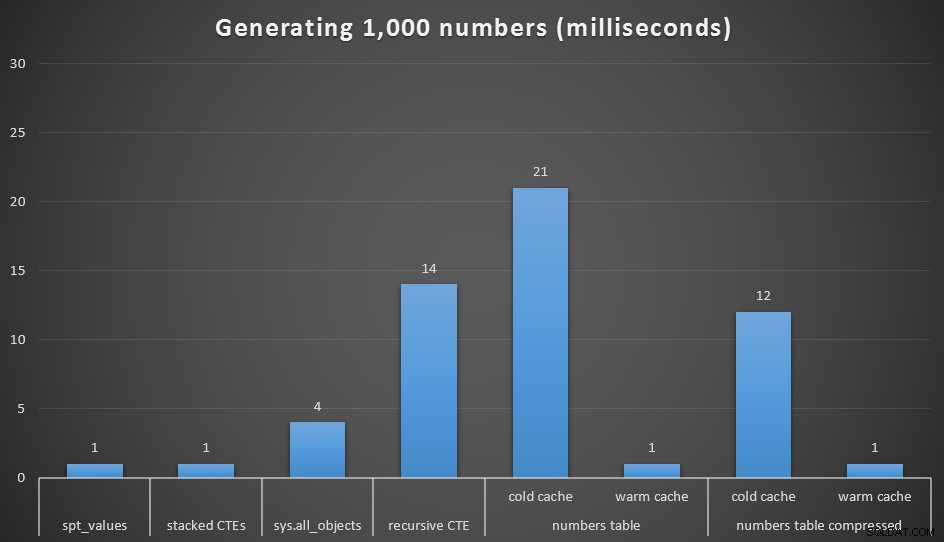
Kørselstid i millisekunder for at generere 1.000 sammenhængende tal
Jeg kørte hver forespørgsel 20 gange og tog gennemsnitlige køretider. Jeg testede også dbo.Numbers tabel, i både komprimeret og ukomprimeret format, og med både en kold cache og en varm cache. Med en varm cache konkurrerer den meget tæt med de andre hurtigste muligheder derude (spt_values , anbefales ikke, og stablede CTE'er), men det første hit er relativt dyrt (selvom jeg næsten griner af at kalde det det).
Fortsættes...
Hvis dette er din typiske use case, og du ikke vil vove dig langt ud over 1.000 rækker, så håber jeg, at jeg har vist de hurtigste måder at generere disse tal på. Hvis din use case er et større antal, eller hvis du leder efter løsninger til at generere sekvenser af datoer, så følg med. Senere i denne serie vil jeg udforske generering af sekvenser på 50.000 og 1.000.000 numre og datointervaller fra en uge til et år.
[ Del 1 | Del 2 | Del 3 ]