Hit-fremhævning er en funktion, som mange mennesker ønsker, at SQL Servers fuldtekstsøgning ville understøtte indbygget. Det er her, du kan returnere hele dokumentet (eller et uddrag) og påpege de ord eller sætninger, der hjalp med at matche dokumentet med søgningen. At gøre det på en effektiv og præcis måde er ingen nem opgave, som jeg fandt ud af ved første hånd.
Som et eksempel på hit-highlighting:Når du udfører en søgning i Google eller Bing, får du nøgleordene med fed skrift i både titlen og uddraget (klik på et af billederne for at forstørre):

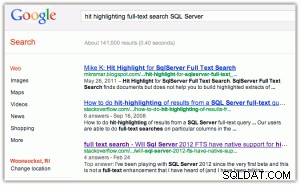
[Som en side, finder jeg to ting morsomme her:(1) at Bing favoriserer Microsoft-ejendomme meget mere end Google gør, og (2) at Bing gider returnere 2,2 millioner resultater, hvoraf mange sandsynligvis er irrelevante.]
Disse uddrag kaldes almindeligvis "snippets" eller "forespørgselsbaserede opsummeringer." Vi har efterspurgt denne funktionalitet i SQL Server i nogen tid, men har endnu ikke hørt nogen gode nyheder fra Microsoft:
- Forbind #295100:Søgeoversigter i fuld tekst (hit-fremhævelse)
- Forbind #722324:Det ville være rart, hvis SQL Full Text Search gav støtte til uddrag/fremhævning
Spørgsmålet dukker også op på Stack Overflow fra tid til anden:
- Sådan laver du hit-fremhævelse af resultater fra en SQL Server-fuldtekstforespørgsel
- Vil SQL Server 2012 FTS have indbygget understøttelse af hitfremhævning?
Der er nogle delløsninger. Dette script fra Mike Kramar, for eksempel, vil producere et hit-fremhævet uddrag, men anvender ikke den samme logik (såsom sprogspecifikke ordbrydere) på selve dokumentet. Det bruger også et absolut tegnantal, så uddraget kan begynde og slutte med delord (som jeg vil demonstrere kort). Sidstnævnte er ret let at rette, men et andet problem er, at det indlæser hele dokumentet i hukommelsen i stedet for at udføre nogen form for streaming. Jeg formoder, at i fuldtekstindekser med store dokumentstørrelser vil dette være et mærkbart præstationshit. Indtil videre vil jeg fokusere på en relativt lille gennemsnitlig dokumentstørrelse (35 KB).
Et simpelt eksempel
Så lad os sige, at vi har en meget simpel tabel med et defineret fuldtekstindeks:
CREATE FULLTEXT CATALOG [FTSDemo];GO CREATE TABLE [dbo].[Dokument]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Dato] DATE NOT NULL , [Titel] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID));GO OPRET FULLTEXT INDEX ON [dbo].[Dokument]( [Content] LANGUAGE [Engelsk] , [Titel] LANGUAGE [Engelsk])KEY INDEX [PK_Document] ON ([FTSDemo]);
Denne tabel er fyldt med nogle få dokumenter (specifikt 7), såsom uafhængighedserklæringen og Nelson Mandelas "Jeg er parat til at dø"-tale. En typisk fuldtekstsøgning i denne tabel kan være:
SELECT d.Title, d.[Indhold]FRA dbo.[Dokument] AS d INNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS t ON d.ID =t.[KEY] BESTIL EFTER [RANK] DESC;
Resultatet returnerer 4 rækker ud af 7:

Bruger nu en UDF-funktion som Mike Kramars:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FRA dbo.[Dokument] SOM MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument) ], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;
Resultaterne viser, hvordan uddraget fungerer:a <SPAN> tag injiceres ved det første søgeord, og uddraget er skåret ud baseret på en forskydning fra denne position (uden hensyn til brug af komplette ord):

(Igen, dette er noget, der kan rettes, men jeg vil være sikker på, at jeg korrekt repræsenterer det, der er derude nu.)
ThinkHighlight
Eran Meyuchas fra Interactive Thoughts har udviklet en komponent, der løser mange af disse problemer. ThinkHighlight er implementeret som en CLR-samling med to CLR-skalar-værdisatte funktioner:
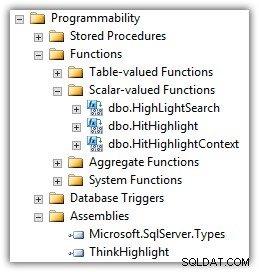
(Du vil også se Mike Kramars UDF på listen over funktioner.)
Nu, uden at komme ind på alle detaljerne om installation og aktivering af assembly på dit system, her er, hvordan ovenstående forespørgsel ville blive repræsenteret med ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] SOM MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') SOM tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC; Resultaterne viser, hvordan de mest relevante søgeord fremhæves, og et uddrag er afledt af det, der er baseret på hele ord og en forskydning fra det udtryk, der fremhæves:

Nogle yderligere fordele, som jeg ikke har demonstreret her, inkluderer muligheden for at vælge forskellige opsummeringsstrategier, kontrollere præsentationen af hvert søgeord (i stedet for alle) ved hjælp af unik CSS, samt understøttelse af flere sprog og endda dokumenter i binært format (de fleste IFilters er understøttet).
Ydeevneresultater
Til at begynde med testede jeg runtime-metrikkene for de tre forespørgsler ved hjælp af SQL Sentry Plan Explorer mod tabellen med 7 rækker. Resultaterne var:

Dernæst ville jeg se, hvordan de ville sammenlignes med en meget større datastørrelse. Jeg indsatte tabellen i sig selv, indtil jeg var på 4.000 rækker, og kørte derefter følgende forespørgsel:
SET STATISTICS TIME ON;GO SELECT /* FTS */ d.Titel, d.[Indhold]FRA dbo.[Dokument] AS d INNER JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT /* UDF */ d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:fed', 100)FRA dbo.[Dokument] AS MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Dokument] SOM MIDDAG JOIN CONTAINSTABLE(dbo.[Dokument], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC;GO SET STATISTICS TIME OFF;GO
Jeg overvågede også sys.dm_exec_memory_grants, mens forespørgslerne kørte, for at opfange eventuelle uoverensstemmelser i hukommelsesbevillinger. Resultater i gennemsnit over 10 kørsler:
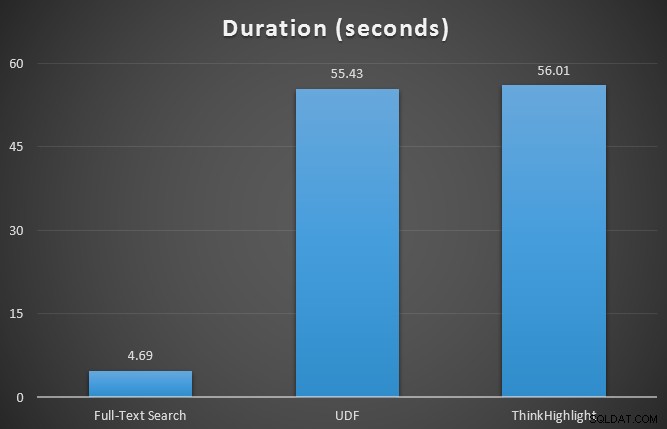
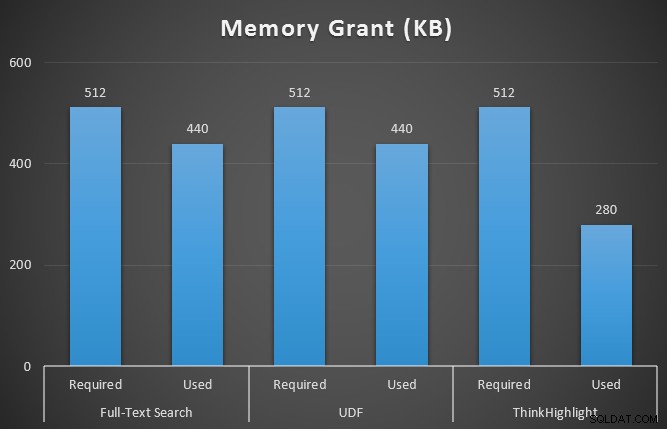
Mens begge hit-fremhævningsmuligheder pådrager sig en betydelig straf for slet ikke at fremhæve, repræsenterer ThinkHighlight-løsningen – med mere fleksible muligheder – en meget marginal trinvis omkostning i form af varighed (~1 %), mens den bruger betydeligt mindre hukommelse (36 %) end UDF-varianten.
Konklusion
Det bør ikke komme som en overraskelse, at hit-fremhævning er en dyr operation, og baseret på kompleksiteten af det, der skal understøttes (tænk flere sprog), at der findes meget få løsninger derude. Jeg synes, Mike Kramar har gjort et fremragende stykke arbejde med at producere en baseline UDF, der giver dig en god måde at løse problemet på, men jeg blev glædeligt overrasket over at finde et mere robust kommercielt tilbud – og fandt det meget stabilt, selv i beta-form. Jeg planlægger at udføre mere grundige test ved at bruge et bredere udvalg af dokumentstørrelser og -typer. I mellemtiden, hvis hit-highlight er en del af dine ansøgningskrav, bør du prøve Mike Kramars UDF og overveje at tage ThinkHighlight til en prøvetur.