Vi laver alle fejl, og vi kan alle lære af andres fejl. I dette indlæg vil vi tage et kig på adskillige online ressourcer for at undgå dårligt databasedesign, der kan føre til mange problemer og koste både tid og penge. Og i en kommende artikel fortæller vi dig, hvor du kan finde tips og bedste praksis.
Databasedesignfejl og fejl, der skal undgås
Der er adskillige onlineressourcer til at hjælpe databasedesignere med at undgå almindelige fejl og fejl. Denne artikel er naturligvis ikke en udtømmende liste over alle artikler derude. I stedet har vi gennemgået og kommenteret en række forskellige kilder, så du kan finde den, der passer bedst til dig.
Vores anbefaling
Hvis der kun er én artikel blandt disse ressourcer, som du skal læse, bør det være 'Sådan får du databasedesign frygteligt forkert' fra Robert Sheldon
Lad os starte med DATAVERSITY-bloggen, der giver et bredt sæt af ganske gode ressourcer:
Primærnøgle- og fremmednøglefejl skal undgås
af Michael Blaha | DATAVERSITY blog | 2. september 2015
Flere databasedesignfejl – forvirring med mange-til-mange-relationer
af Michael Blaha | DATAVERSITY blog | 30. september 2015
Diverse databasedesignfejl
af Michael Blaha | DATAVERSITY blog | 26. oktober 2015
Michael Blaha har bidraget med et flot sæt af tre artikler. Hver artikel omhandler forskellige faldgruber ved databasemodellering og fysisk design; emner omfatter nøgler, relationer og generelle fejl. Derudover er der diskussioner med Michael vedrørende nogle af punkterne. Hvis du leder efter faldgruber omkring nøgler og relationer, ville dette være et godt sted at starte.
Mr. Blaha udtaler, at "omkring 20 % af databaserne overtræder primære nøgleregler". Wow! Det betyder, at omkring 20 % af databaseudviklerne ikke oprettede primære nøgler korrekt. Hvis denne statistik er sand, så viser den virkelig vigtigheden af datamodelleringsværktøjer, der kraftigt "opmuntrer" eller endda kræver, at modelbyggere definerer primære nøgler.
Mr. Blaha deler også heuristikken om, at "omkring 50 % af databaserne" har udenlandske nøgleproblemer (i henhold til hans erfaring med ældre databaser, som han har studeret). Han minder os om at undgå uformel kobling mellem tabeller ved at indlejre værdien fra en tabel i en anden i stedet for at bruge en fremmednøgle.
Jeg har set dette problem mange gange. Jeg indrømmer, at uformel kobling kan kræves af den funktionalitet, der skal implementeres, men oftere opstår det på grund af simpel dovenskab. For eksempel vil vi måske vise bruger-id'et for en person, der har ændret noget, så vi gemmer bruger-id'et direkte i tabellen. Men hvad hvis denne bruger ændrer sit bruger-id? Så er dette uformelle link brudt. Dette skyldes ofte dårligt design og modellering.
Design af din database:Top 5 fejl, der skal undgås
af Henrique Netzka | DATAVERSITY blog | 2. november 2015
Jeg var lidt skuffet over denne artikel, da den havde et par ret specifikke elementer (lagring af protokol i en CLOB) og et par meget generelle (tænk på lokalisering). Generelt er artiklen fin, men er det virkelig de 5 bedste fejl, der skal undgås? Efter min mening er der flere andre almindelige fejl, der bør komme på listen.
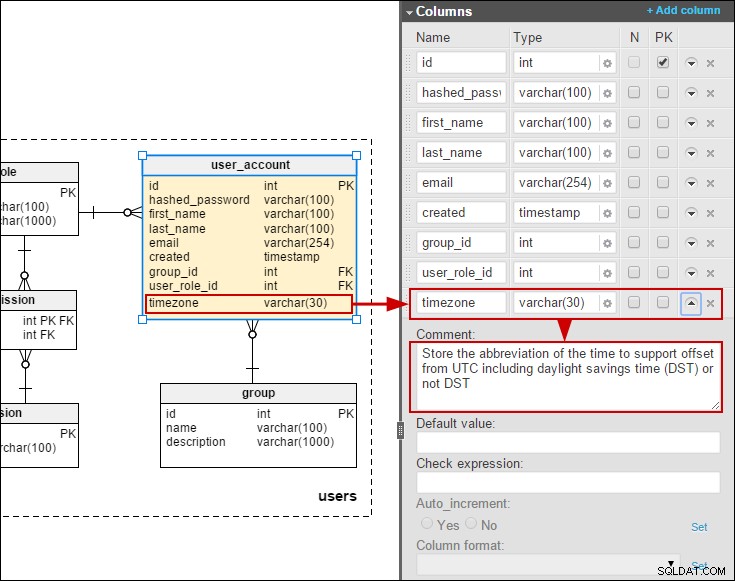
Men positivt er dette en af de få artikler, der nævner globalisering og lokalisering på nogen meningsfuld måde. Jeg arbejder i et meget flersproget miljø og har set flere forfærdelige implementeringer af lokalisering, så jeg var glad for at finde dette problem nævnt. Sprogkolonner og tidszonekolonner kan virke indlysende, men de optræder meget sjældent i databasemodeller.
Når det er sagt, tænkte jeg, at det ville være interessant at skabe en model, der inkluderer oversættelser, der kan ændres af slutbrugere (i modsætning til at bruge ressourcebundter). For noget tid siden skrev jeg om en model til en online undersøgelsesdatabase. Her har jeg modelleret en forenklet oversættelse af spørgsmål og svarvalg:
Hvis vi antager, at vi skal tillade slutbrugere at vedligeholde oversættelserne, ville den foretrukne metode være at tilføje oversættelsestabeller til spørgsmål og svar:
Jeg har også tilføjet en tidszone til user_account tabel, så vi kan gemme datoer/klokkeslæt i brugernes lokale tid:
7 almindelige databasedesignfejl
af Grzegorz Kaczor | Vertabelo blog | 17. juli 2015
Jeg vil lave en lille selvpromovering her. Vi bestræber os på regelmæssigt at poste interessante og engagerende artikler her.
Denne særlige artikel påpeger flere vigtige områder af bekymring, såsom navngivning, indeksering, volumenovervejelser og revisionsspor. Artiklen går endda ind på problemer relateret til specifikke DBM-systemer, såsom Oracle-begrænsninger på tabelnavne. Jeg kan rigtig godt lide fine klare eksempler, selvom de illustrerer, hvordan designere laver fejl og fejler.
Det er naturligvis ikke muligt at liste alle designfejl, og de angivne er muligvis ikke dine mest almindelige fejl. Når vi skriver om almindelige fejl, er det dem, vi har lavet eller har fundet i andres arbejde, vi trækker på. En komplet liste over fejl, rangeret i forhold til hyppighed, ville være umulig for en enkelt person at kompilere. Ikke desto mindre tror jeg, at denne artikel giver flere nyttige indsigter om potentielle faldgruber. Det er samlet set en god solid ressource.
Mens hr. Kaczor fremsætter flere interessante pointer i sin artikel, fandt jeg hans kommentarer om "ikke at tage højde for mulig mængde eller trafik" ret interessante. Især anbefalingen om at adskille hyppigt anvendte data fra historiske data er særlig relevant. Dette er en løsning, som vi ofte bruger i vores meddelelsesapplikationer; vi skal have en søgbar historik over alle beskeder, men de beskeder, der med størst sandsynlighed vil blive tilgået, er dem, der er blevet sendt inden for de seneste par dage. Så at opdele "aktive" eller nyere data, der ofte tilgås (en meget mindre mængde data) fra langsigtede historiske data (den store masse af data) er generelt en meget god teknik.
Almindelige databasedesignfejl
af Troy Blake | Senior DBA blog | 11. juli 2015
Troy Blakes artikel er en anden god ressource, selvom jeg måske har omdøbt denne artikel til "Almindelige SQL Server-designfejl".
For eksempel har vi kommentaren:"lagrede procedurer er din bedste ven, når det kommer til at bruge SQL Server effektivt". Det er fint, men er dette en almindelig generel fejl, eller er det mere specifikt for SQL Server? Jeg ville være nødt til at vælge, at dette er lidt SQL Server-specifikt, da der er ulemper ved at bruge lagrede procedurer, som at ende med leverandørspecifikke lagrede procedurer og dermed leverandør-lock-in. Så jeg er ikke fan af at inkludere "Not Using Stored Procedures" på denne liste.
Men på den positive side tror jeg, at forfatteren identificerede nogle meget almindelige fejl, såsom dårlig planlægning, sjusket systemdesign, begrænset dokumentation, svage navnestandarder og mangel på test.
Så jeg vil klassificere dette som en meget nyttig reference for SQL Server-udøvere og en nyttig reference for andre.
Syv datamodelleringsfejl
af Kurt Cagle | LinkedIn | 12. juni 2015
Jeg nød virkelig at læse Mr. Cagles liste over databasemodelleringsfejl. Disse er fra en databasearkitekts syn på tingene; han identificerer klart modelleringsfejl på højere niveau, som bør undgås. Med denne større billedvisning kan du afbryde et potentielt modelleringsrod.
Nogle af de typer, der er nævnt i artiklen, kan findes andre steder, men et par af disse er unikke:At blive abstrakt for tidligt eller blande konceptuelle, logiske og fysiske modeller. Disse nævnes ikke ofte af andre forfattere, sandsynligvis fordi de fokuserer på datamodelleringsprocessen snarere end det større systemsyn.
Især eksemplet med "At blive for abstrakt for tidligt" beskriver en interessant tankeproces med at skabe nogle eksempler på "historier" og teste, hvilke relationer der er vigtige i dette domæne. Dette fokuserer tænkningen på forholdet mellem de objekter, der modelleres. Det resulterer i spørgsmål som hvad er de vigtige relationer i dette domæne ?
Ud fra denne forståelse skaber vi modellen omkring relationer i stedet for at starte ved individuelle domæneemner og bygge relationerne oven på dem. Selvom mange af os måske bruger denne tilgang, er der blandt disse ressourcer ingen andre forfattere, der kommenterede det. Jeg fandt denne beskrivelse og eksemplerne ret interessante.
Sådan får du databasedesign frygteligt forkert
af Robert Sheldon | Simpel snak | 6. marts 2015
Hvis der kun er én artikel blandt disse ressourcer, som du skal læse, bør det være denne fra Robert Sheldon
Det, jeg virkelig godt kan lide ved denne artikel, er, at der for hver af de nævnte fejl er tips til, hvordan man gør det rigtigt. De fleste af disse fokuserer på at undgå fejlen i stedet for at rette den, men jeg tror stadig, at de er meget nyttige. Der er meget lidt teori her; for det meste lige svar om at undgå fejl under datamodellering. Der er et par specifikke SQL Server-punkter, men for det meste bruges SQL Server til at give eksempler på fejlundgåelse eller veje ud af fejl.
Omfanget af artiklen er også ret bredt:den dækker forsømmelse af planlægning, ikke besvær med dokumentation, brug af elendige navnekonventioner, problemer med normalisering (for meget eller for lidt), fejl på taster og begrænsninger, ikke korrekt indeksering og udførelse utilstrækkelig test.
Især kunne jeg godt lide de praktiske råd vedrørende dataintegritet – hvornår man skal bruge kontrolbegrænsninger, og hvornår man skal definere fremmednøgler. Derudover beskriver Mr. Sheldon også situationen, når teams udsætter ansøgningen for at håndhæve integritet. Han er ligetil, når han siger, at en database kan tilgås på flere måder og af adskillige applikationer. Hans konkluderer, at "data bør beskyttes, hvor de befinder sig:i databasen". Dette er så sandt, at det kan gentages til udviklingsteams og ledere for at forklare vigtigheden af at implementere integritetstjek i datamodellen.
Dette er min slags artikel, og du kan se, at andre er enige baseret på de mange kommentarer, der støtter den. Så topkarakterer her; det er en meget værdifuld ressource.
Ti almindelige databasedesignfejl
af Louis Davidson | Simpel snak | 26. februar 2007
Jeg fandt denne artikel ganske god, da den dækkede mange almindelige designfejl. Der var meningsfulde analogier, eksempler, modeller og endda nogle klassiske citater fra William Shakespeare og J.R.R. Tolkien.
Et par af fejlene blev forklaret mere detaljeret end andre, med lange eksempler og SQL-uddrag, som jeg fandt lidt besværlige. Men det er en smagssag.
Igen har vi et par emner, der er specifikke for SQL Server. For eksempel er pointen med ikke at bruge Stored Procedures til at få adgang til data godt for SQL, men SP'er er ikke altid en god idé, når målet er support på flere DBMS'er. Derudover advares vi mod at forsøge at kode generiske T-SQL-objekter. Da jeg sjældent arbejder med SQL Server eller Sybase, fandt jeg ikke dette tip relevant.
Listen minder ret meget om Robert Sheldons, men hvis du primært arbejder på SQL Server, så vil du finde et par ekstra klumper af information.
Fem simple databasedesignfejl, du bør undgå
af Anith Sen Larson | Simpel snak | 16. oktober 2009
Denne artikel giver nogle meningsfulde eksempler for hver af de simple designfejl, den dækker. På den anden side er det snarere fokuseret på lignende typer fejl:almindelige opslagstabeller, entitetsattributværditabeller og attributopdeling.
Observationerne er fine, og artiklen har endda referencer, som plejer at være sjældne. Alligevel vil jeg gerne se mere generelle databasedesignfejl. Disse fejl virkede ret specifikke, men som jeg allerede har skrevet, er de fejl, vi skriver om, generelt dem, vi har personlig erfaring med.
Et element, som jeg kunne lide, var en specifik tommelfingerregel for at beslutte, hvornår man skal bruge en kontrolbegrænsning i forhold til en separat tabel med en fremmednøglebegrænsning. Flere forfattere giver lignende anbefalinger, men hr. Larson opdeler dem i "skal", "overvej" og "stærk sag" - med den indrømmelse, at "design er en blanding af kunst og videnskab og derfor involverer afvejninger". Jeg finder det meget sandt.
Top ti mest almindelige fysiske databasedesignfejl
af Craig Mullins | Data og teknologi i dag | 5. august 2013
Som navnet antyder, er "Top ti mest almindelige fysiske databasedesignfejl" lidt mere orienteret mod fysisk design frem for logisk og konceptuelt design. Ingen af de fejl, forfatter Craig Mullins nævner, skiller sig virkelig ud eller er unikke, så jeg vil anbefale denne information til folk, der arbejder på den fysiske DBA-side.
Derudover er beskrivelserne lidt korte, så det er indimellem svært at se, hvorfor en bestemt fejl kommer til at give problemer. Der er i sagens natur ikke noget galt med korte beskrivelser, men de giver dig ikke ret meget at tænke over. Og ingen eksempler præsenteres.
Der er et interessant punkt rejst i forbindelse med manglende deling af data. Dette punkt nævnes lejlighedsvis i andre artikler, men ikke som en designfejl. Jeg ser dog dette problem ret ofte med databaser, der "genskabes" baseret på meget lignende krav, men af et nyt team eller for et nyt produkt
.Det sker ofte, at produktteamet senere indser, at de gerne ville have brugt data, der allerede var til stede i "faderen" til deres nuværende database. Faktisk burde de dog have forbedret forælderen i stedet for at skabe et nyt afkom. Applikationer er beregnet til at dele data; godt design kan tillade en database at blive genbrugt oftere.
Begår du disse 5 databasedesignfejl?
af Thomas Larock | Thomas Larocks blog | 2. januar 2012
Du vil måske finde et par interessante punkter, når du besvarer Thomas Larocks spørgsmål:Begår du disse 5 databasedesignfejl?
Denne artikel er noget tungt vægtet til nøgler (fremmednøgler, surrogatnøgler og genererede nøgler). Alligevel har det en vigtig pointe:man skal ikke antage, at DBMS-funktionerne er de samme på tværs af alle systemer. Jeg synes, det er en meget god pointe. Det er også en, der ikke findes i de fleste andre artikler, måske fordi mange forfattere fokuserer på og arbejder overvejende med et enkelt DBMS.
Design af en database:7 ting, du ikke vil gøre
af Thomas Larock | Thomas Larocks blog | 16. januar 2013
Mr. Larock genbrugte et par af sine "5 Database Design Fejl", da han skrev "7 Things You Don't Want To Do", men der er andre gode punkter her.
Interessant nok findes nogle af de pointer, som hr. Larock fremfører, ikke i mange andre kilder. Du får et par ret unikke observationer, som "ingen præstationsforventninger". Dette er en alvorlig fejl, og en der, baseret på min erfaring, sker ret ofte. Selv når man udvikler applikationskoden, er det ofte efter at datamodellen, databasen og selve applikationen er blevet oprettet, at folk begynder at tænke på de ikke-funktionelle krav (hvornår ikke-funktionelle tests skal oprettes) og begynder at definere præstationsforventninger .
Omvendt er der et par punkter, som jeg ikke ville have med på min egen Top Ti-liste, såsom "going big, just in case". Jeg kan se pointen, men det er ikke så højt på min liste, når jeg laver en datamodel. Der er ingen specificitet for et bestemt DBM-system, så det er en bonus.
For at konkludere, kan mange af disse punkter være indkapslet under punktet:"forstår ikke kravene", som virkelig er på min top 10 fejlliste.
Sådan undgår du 8 almindelige databaseudviklingsfejl
af Base36 | 6. december 2012
Jeg var ret interesseret i at læse denne artikel. Jeg var dog en smule skuffet. Der er ikke megen diskussion om undgåelse, og pointen med artiklen synes virkelig at være "det er almindelige databasefejl" og "hvorfor de er fejl"; beskrivelser af, hvordan man undgår fejlen, er mindre fremtrædende.
Derudover er nogle af artiklens Top 8 fejl faktisk bestridt. Misbrug af den primære nøgle er et eksempel. Base36 fortæller os, at de skal genereres af systemet og ikke baseret på applikationsdata i rækken. Selvom jeg er enig i dette indtil et punkt, er jeg ikke overbevist om, at alle PK'er skal altid blive genereret; det er lidt for kategorisk.
På den anden side er fejlen med "Hårde sletninger" interessant og ikke ofte nævnt andre steder. Bløde sletninger forårsager andre problemer, men det er rigtigt, at blot markering af en række som inaktiv har sine fordele, når du forsøger at finde ud af, hvor de data blev af, som var i systemet i går. At søge gennem transaktionslogfiler er ikke min idé om en fornøjelig måde at tilbringe en dag på.
Syv dødssynder ved databasedesign
af Jason Tiret | Enterprise Systems Journal | 16. februar 2010
Jeg var ret håbefuld, da jeg begyndte at læse Jason Tirets artikel, "Seven Deadly Sins of Database Design". Så jeg var glad for at opdage, at det ikke kun genbrugte fejl, der findes i adskillige andre artikler. Tværtimod bød det på en "synd", som jeg ikke havde fundet i andre lister:at forsøge at udføre alt databasedesign "up front" og ikke opdatere modellen efter databasen er i produktion, når der foretages ændringer i databasen. (Eller, som Jason udtrykker det, "Ikke at behandle datamodellen som en levende, åndende organisme").
Jeg har set denne fejl mange gange. De fleste mennesker indser først deres fejl, når de skal lave opdateringer til en model, som ikke længere matcher den faktiske database. Selvfølgelig er resultatet en ubrugelig model. Som det hedder i artiklen, "skal ændringerne finde vej tilbage til modellen."
På den anden side er størstedelen af Jasons listepunkter ret velkendte. Beskrivelserne er gode, men der er ikke ret mange eksempler. Flere eksempler og detaljer ville være nyttige.
De mest almindelige databasedesignfejl
af Brian Prince | eWeek.com | 19. marts 2008

Artiklen "De mest almindelige databasedesignfejl" er faktisk en række dias fra en præsentation. Der er et par interessante tanker, men nogle af de unikke genstande er måske lidt esoteriske. Jeg har punkter som "Lær RAID at kende" og involvering af interessenter i tankerne.
Generelt vil jeg ikke sætte dette på din læseliste, medmindre du er fokuseret på generelle spørgsmål (planlægning, navngivning, normalisering, indekser) og fysiske detaljer.
10 almindelige designfejl
af davidm | SQL Server-blogs – SQLTeam.com | 12. september 2005
Nogle af punkterne i "Ti almindelige designfejl" er interessante og relativt nye. Nogle af disse fejl er dog ret kontroversielle, såsom "brug af NULLs" og denormalisering.
Jeg er enig i, at det er en fejl at oprette alle kolonner som nullable, men at definere en kolonne som nullable kan være påkrævet for en bestemt forretningsfunktion. Kan det derfor betragtes som en generisk fejl? Det tror jeg ikke.
Et andet punkt, jeg er i tvivl om, er de-normalisering. Dette er ikke altid en designfejl. For eksempel kan denormalisering være påkrævet af præstationsmæssige årsager.
Denne artikel mangler også stort set detaljer og eksempler. Samtalerne mellem DBA og programmør eller leder er morsomme, men jeg ville have foretrukket mere konkrete eksempler og detaljerede begrundelser for disse almindelige fejl.
OTLT og EAV:De to store designfejl, som alle begyndere begår
af Tony Andrews | Tony Andrews om Oracle og databaser | 21. oktober 2004
Mr. Andrews' artikel minder os om fejlene "One True Lookup Table" (OTLT) og Entity-Attribute-Value (EAV), som er nævnt i andre artikler. En god pointe ved denne præsentation er, at den fokuserer på disse to fejl, så beskrivelser og eksempler er præcise. Derudover gives en mulig forklaring på, hvorfor nogle designere implementerer OTLT og EAV.
For at minde dig om, ser OTLT-tabellen typisk sådan ud, med poster fra flere domæner smidt ind i den samme tabel:
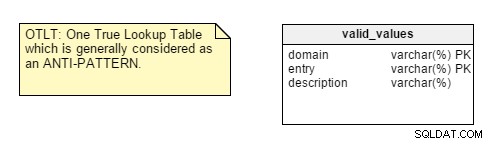
Som sædvanlig er der en diskussion omkring, hvorvidt OTLT er en brugbar løsning og et godt designmønster. Jeg må sige, at jeg holder med anti-OTLT-gruppen; disse tabeller introducerer adskillige problemer. Vi kan bruge analogien med at bruge en enkelt tæller til at repræsentere alle mulige værdier af alle mulige konstanter. Det har jeg aldrig set indtil videre.
Almindelige databasefejl
af John Paul Ashenfelter | Dr. Dobbs | 1. januar 2002
Mr. Ashenfelters artikel opregner hele 15 almindelige databasefejl. Der er endda et par fejl, som ikke ofte er nævnt i andre artikler. Desværre er beskrivelserne relativt korte, og der er ingen eksempler. Denne artikels fortjeneste er, at listen dækker meget og kan bruges som en "tjekliste" over fejl, der skal undgås. Selvom jeg måske ikke klassificerer disse som de vigtigste databasefejl, er de bestemt blandt de mest almindelige.
På en positiv bemærkning er dette en af de få artikler, der nævner behovet for at håndtere internationalisering af formater for data som dato, valuta og adresse. Et eksempel ville være rart her. Det kunne være så simpelt som "vær sikker på, at staten er en nullbar kolonne; i mange lande er der ingen stat forbundet med en adresse”.
Tidligere i denne artikel nævnte jeg andre bekymringer og nogle tilgange til at forberede globaliseringen af din database, såsom tidszoner og oversættelser (lokalisering). Det faktum, at ingen anden artikel nævner bekymringen for valuta- og datoformater, er bekymrende. Er vores databaser forberedt til den globale brug af vores applikationer?
Ædrende omtaler
Der er naturligvis andre artikler, der beskriver almindelige databasedesignfejl og fejl, men vi ønskede at give dig en bred gennemgang af forskellige ressourcer. Du kan finde yderligere information i artikler som:
10 almindelige databasedesignfejl | MIS Klasse Blog | 29. januar 2012
10 almindelige fejl i databasedesign | IDG.se | 24. juni 2010
Online ressourcer:Hvor skal man starte? Hvor skal man hen?
Som tidligere nævnt, er denne liste bestemt ikke beregnet til at være en udtømmende undersøgelse af enhver online artikel, der beskriver databasedesignfejl og fejl. Vi har snarere identificeret flere kilder, der er særligt nyttige eller har et specifikt fokus, som du måske kan finde brugbart.
Du er velkommen til at anbefale yderligere artikler.