At have referencetabeller i din database er ikke nogen big deal, ikke? Du skal blot binde en kode eller ID med en beskrivelse for hver referencetype. Men hvad hvis du bogstaveligt talt har snesevis og snesevis af referencetabeller? Er der et alternativ til metoden med ét bord pr. type? Læs videre for at finde en generisk og udvidelsesbar databasedesign til håndtering af alle dine referencedata.
Dette usædvanligt udseende diagram er et fugleperspektiv af en logisk datamodel (LDM), der indeholder alle referencetyperne for et virksomhedssystem. Det er fra en uddannelsesinstitution, men det kan gælde datamodellen for enhver form for organisation. Jo større modellen er, jo flere referencetyper vil du sandsynligvis finde.
Med referencetyper mener jeg referencedata eller opslagsværdier eller – hvis du vil være flash – taksonomier . Typisk bruges de her definerede værdier i rullelister i din applikations brugergrænseflade. De kan også optræde som overskrifter på en rapport.
Denne særlige datamodel havde omkring 100 referencetyper. Lad os zoome ind og se på kun to af dem.
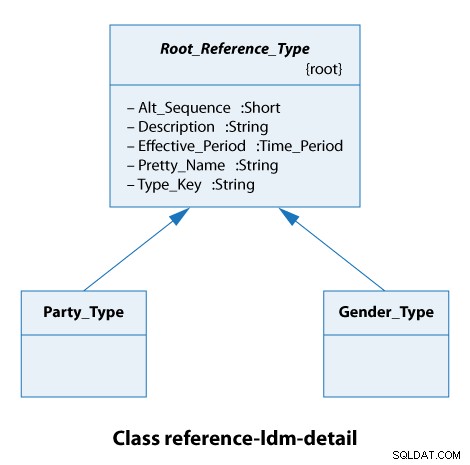
Fra dette klassediagram ser vi, at alle referencetyper udvider Root_Reference_Type . I praksis betyder det blot, at alle vores referencetyper har de samme attributter fra Alt_Sequence gennem til Type_Key inklusive, som vist nedenfor.
| Attribut | Beskrivelse |
|---|---|
Alt_Sequence | Bruges til at definere en alternativ sekvens, når en ikke-alfabetisk rækkefølge er påkrævet. |
Description | Beskrivelsen af typen. |
Effective_Period | Definerer effektivt, om referenceindgangen er aktiveret eller ej. Når først en reference er blevet brugt, kan den ikke slettes på grund af referencemæssige begrænsninger; det kan kun deaktiveres. |
| Det smukke navn for typen. Dette er, hvad brugeren ser på skærmen. |
Type_Key | Den unikke interne NØGLE for typen. Dette er skjult for brugeren, men applikationsudviklere kan gøre udstrakt brug af dette i deres SQL. |
Festtypen her er enten en organisation eller en person. Typerne af køn er mandlige og kvindelige. Så det er virkelig simple sager.
Den traditionelle referencetabelløsning
Så hvordan skal vi implementere den logiske model i den fysiske verden af en egentlig database?
Vi kunne antage, at hver referencetype vil blive knyttet til sin egen tabel. Du kan referere til dette som det mere traditionelle et-bord-pr-klasse opløsning. Det er simpelt nok og ville se sådan ud:
Ulempen ved dette er, at der kan være dusinvis og dusinvis af disse tabeller, som alle har de samme kolonner, som alle laver meget det samme.
Desuden skaber vi måske meget mere udviklingsarbejde . Hvis der kræves en brugergrænseflade for hver type, for at administratorer kan vedligeholde værdierne, bliver mængden af arbejde hurtigt mangedoblet. Der er ingen faste regler for dette – det afhænger virkelig af dit udviklingsmiljø – så du bliver nødt til at tale med dine udviklere at forstå, hvilken effekt dette har.
Men i betragtning af at alle vores referencetyper har de samme attributter eller kolonner, er der en mere generisk måde at implementere vores logiske datamodel på? Ja der er! Og det kræver kun to borde .
Tobordsløsningen
Den første diskussion, jeg nogensinde havde om dette emne, var tilbage i midten af 90'erne, da jeg arbejdede for et London Market-forsikringsselskab. Dengang gik vi direkte til fysisk design og brugte mest naturlige/forretningsnøgler, ikke ID'er. Hvor referencedata fandtes, besluttede vi at beholde én tabel pr. type, der var sammensat af en unik kode (VARCHAR PK) og en beskrivelse. Faktisk var der langt færre referencetabeller dengang. Oftere end ikke vil et begrænset sæt forretningskoder blive brugt i en kolonne, muligvis med en defineret databasekontrolbegrænsning; der ville ikke være nogen referencetabel overhovedet.
Men spillet er gået videre siden da. Dette er hvad en to-bord løsning kan se sådan ud:
Som du kan se, er denne fysiske datamodel meget enkel. Men det er helt anderledes end den logiske model, og ikke fordi noget er blevet pæreformet. Det er fordi en række ting blev gjort som en del af fysisk design .
reference_type tabel repræsenterer hver enkelt referenceklasse fra LDM. Så hvis du har 20 referencetyper i din LDM, har du 20 rækker af metadata i tabellen. reference_value tabel indeholder de tilladte værdier for alle referencetyperne.
På tidspunktet for dette projekt var der nogle ret livlige diskussioner mellem udviklere. Nogle foretrak løsningen med to borde, og andre foretrak et-bord-pr-type metode.
Der er fordele og ulemper ved hver løsning. Som du måske kan gætte, var udviklerne for det meste bekymrede over mængden af arbejde, brugergrænsefladen ville tage. Nogle mente, at det ville være ret hurtigt at slå en admin-brugergrænseflade sammen for hvert bord. Andre mente, at det ville være mere komplekst at bygge en enkelt administrationsgrænseflade, men i sidste ende kunne betale sig.
På netop dette projekt blev to-bords løsningen favoriseret. Lad os se på det mere detaljeret.
Det udvidelige og fleksible referencedatamønster
Da din datamodel udvikler sig over tid, og der kræves nye referencetyper, behøver du ikke blive ved med at foretage ændringer i din database for hver ny referencetype. Du skal blot definere nye konfigurationsdata. For at gøre dette skal du tilføje en ny række til reference_type tabel og tilføje dens kontrollerede liste over tilladte værdier til reference_value tabel.
Et vigtigt koncept i denne løsning er det at definere effektive tidsperioder for visse værdier. For eksempel kan din organisation have brug for at registrere en ny reference_value af 'Bevis for ID', som vil være acceptabelt på et senere tidspunkt. Det er et simpelt spørgsmål om at tilføje den nye reference_value med effective_period_from dato korrekt indstillet. Dette kan gøres på forhånd. Før den dato ankommer, vises den nye post ikke i rullelisten over værdier, som brugere af din applikation ser. Dette skyldes, at din applikation kun viser værdier, der er aktuelle eller aktiverede.
På den anden side skal du muligvis forhindre brugere i at bruge en bestemt reference_value . I så fald skal du bare opdatere den med effective_period_to dato korrekt indstillet. Når den dag er gået, vises værdien ikke længere i rullelisten. Den bliver deaktiveret fra det tidspunkt. Men fordi den stadig fysisk eksisterer som en række i tabellen, bevares henvisningsintegriteten for de tabeller, hvor det allerede er blevet refereret.
Nu hvor vi arbejdede på to-tabel-løsningen, blev det klart, at nogle yderligere kolonner ville være nyttige på reference_type bord. Disse var for det meste centreret om brugergrænsefladeproblemer.
For eksempel pretty_name på reference_type tabel blev tilføjet til brug i brugergrænsefladen. Det er nyttigt for store taksonomier at bruge et vindue med en søgefunktion. Derefter pretty_name kunne bruges til vinduets titel.
På den anden side, hvis en rulleliste med værdier er tilstrækkelig, pretty_name kunne bruges til LOV-prompten. På en lignende måde kunne beskrivelse bruges i brugergrænsefladen til at udfylde roll-over-hjælp.
Et kig på typen af konfiguration eller metadata, der indgår i disse tabeller, vil hjælpe med at afklare tingene lidt.
Sådan administreres alt det
Selvom eksemplet her er meget simpelt, kan referenceværdierne for et stort projekt hurtigt blive ret komplekse. Så det kan være tilrådeligt at vedligeholde alt dette i et regneark. Hvis det er tilfældet, kan du bruge selve regnearket til at generere SQL ved hjælp af strengsammenkædning. Dette indsættes i scripts, som udføres mod måldatabaserne, der understøtter udviklingslivscyklussen og produktionsdatabasen (live). Dette sæder databasen med alle de nødvendige referencedata.
Her er konfigurationsdataene for de to LDM-typer, Gender_Type og Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Der er en række i reference_type for hver LDM-undertype af Root_Reference_Type . Beskrivelsen i reference_type er taget fra LDM klassebeskrivelsen. For Gender_Type , ville dette lyde "Identificerer en persons køn". DML-uddragene viser forskellene i beskrivelser mellem type og værdi, som kan bruges i brugergrænsefladen eller i rapporter.
Du vil se den reference_type kaldet Gender_Type er blevet tildelt et interval på 13000000 til 13999999 for dets tilknyttede reference_value.ids . I denne model er hver reference_type er tildelt et unikt, ikke-overlappende udvalg af ID'er. Dette er ikke strengt nødvendigt, men det giver os mulighed for at gruppere relaterede værdi-id'er sammen. Det efterligner lidt, hvad du ville få, hvis du havde separate borde. Det er rart at have, men hvis du ikke synes, der er nogen fordel i dette, så kan du undvære det.
En anden kolonne, der blev tilføjet til PDM'en, er admin_role . Her er hvorfor.
Hvem er administratorerne
Nogle taksonomier kan have værdier tilføjet eller fjernet med ringe eller ingen indflydelse. Dette vil ske, når ingen programmer gør brug af værdierne i deres logik, eller når typen ikke er forbundet med andre systemer. I sådanne tilfælde er det sikkert for brugeradministratorer at holde disse opdaterede.
Men i andre tilfælde skal der udvises meget mere omhu. En ny referenceværdi kan forårsage utilsigtede konsekvenser for programlogik eller for downstream-systemer.
Antag for eksempel, at vi føjer følgende til kønstypetaksonomien:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Dette bliver hurtigt et problem, hvis vi har følgende logik indbygget et sted:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Det er klart, at "hvis du ikke er mand, skal du være kvinde"-logikken ikke længere gælder i den udvidede taksonomi.
Det er her admin_role kolonne kommer i spil. Det blev født ud fra diskussioner med udviklerne om det fysiske design, og det fungerede sammen med deres UI-løsning. Men hvis en-tabel-pr-klasse-løsningen var blevet valgt, så reference_type ikke ville have eksisteret. De metadata, den indeholdt, ville være blevet hårdkodet i applikationen Gender_Type bord – , som hverken er fleksibelt eller strækbart.
Kun brugere med det korrekte privilegium kan administrere taksonomien. Dette vil sandsynligvis være baseret på fagekspertise (SMV ). På den anden side kan nogle taksonomier være nødt til at blive administreret af IT for at muliggøre konsekvensanalyse, grundig testning og for at eventuelle kodeændringer frigives harmonisk i tide til den nye konfiguration. (Om dette gøres ved ændringsanmodninger eller på anden måde er op til din organisation.)
Du har muligvis bemærket, at revisionskolonnerne created_by , created_date , updated_by og updated_date er slet ikke nævnt i ovenstående script. Igen, hvis du ikke er interesseret i disse, behøver du ikke bruge dem. Denne særlige organisation havde en standard, der forpligtede til at have revisionskolonner på alle borde.
Triggers:Hold tingene konsekvente
Triggere sikrer, at disse revisionskolonner er konsekvent opdateret, uanset hvad kilden til SQL'en er (scripts, din applikation, planlagte batchopdateringer, ad-hoc-opdateringer osv.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Min baggrund er for det meste Oracle, og desværre begrænser Oracle identifikatorer til 30 bytes. For at undgå at overskride dette, får hver tabel et kort alias på tre til fem tegn, og andre tabelrelaterede artefakter bruger dette alias i deres navne. Så reference_value 's alias er reva – de første to tegn fra hvert ord. Før rækkeindsættelse og før rækkeopdatering forkortes til bri og bru henholdsvis. Sekvensnavnet reva_seq , og så videre.
Håndkodning af triggere som denne, bord efter bord, kræver en masse demoraliserende kedelpladearbejde for udviklere. Heldigvis kan disse triggere oprettes via kodegenerering , men det er emnet for en anden artikel!
Vigtigheden af nøgler
ref_type_key og type_key kolonner er begge begrænset til 30 bytes. Dette gør det muligt at bruge dem i PIVOT-type SQL-forespørgsler (i Oracle. Andre databaser har muligvis ikke den samme begrænsning af identifikatorlængde).
Fordi nøgleunik er sikret af databasen, og triggeren sikrer, at dens værdi forbliver den samme for alle tider, kan og bør disse nøgler bruges i forespørgsler og kode for at gøre dem mere læselige . Hvad mener jeg med dette? Nå, i stedet for:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Du skriver:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Dybest set staver nøglen tydeligt, hvad forespørgslen gør .
Fra LDM til PDM, med plads til at vokse
Rejsen fra LDM til PDM er ikke nødvendigvis en lige vej. Det er heller ikke en direkte forvandling fra det ene til det andet. Det er en separat proces, der introducerer sine egne overvejelser og sine egne bekymringer.
Hvordan modellerer du referencedataene i din database?