Sammenkædningen af to eller flere datasæt er oftest udtrykt i T-SQL ved hjælp af UNION ALL klausul. I betragtning af at SQL Server optimizer ofte kan omarrangere ting som joins og aggregater for at forbedre ydeevnen, er det ganske rimeligt at forvente, at SQL Server også ville overveje at omarrangere sammenkædningsinput, hvor dette ville give en fordel. For eksempel kunne optimeringsværktøjet overveje fordelene ved at omskrive A UNION ALL B som B UNION ALL A .
Faktisk gør SQL Server optimizer ikke gør dette. Mere præcist var der en vis begrænset understøttelse af genbestilling af sammenkædningsinput i SQL Server-udgivelser op til 2008 R2, men dette blev fjernet i SQL Server 2012, og er ikke dukket op igen siden.
SQL Server 2008 R2
Intuitivt har rækkefølgen af sammenkædningsinput kun betydning, hvis der er et rækkemål . Som standard optimerer SQL Server eksekveringsplaner på grundlag af, at alle kvalificerende rækker vil blive returneret til klienten. Når et rækkemål er i kraft, forsøger optimeringsværktøjet at finde en eksekveringsplan, der vil producere de første par rækker hurtigt.
Rækkemål kan indstilles på en række måder, for eksempel ved at bruge TOP , en FAST n forespørgselstip, eller ved at bruge EXISTS (som i sagens natur højst skal finde én række). Hvor der ikke er noget rækkemål (dvs. klienten kræver alle rækker), er det generelt ligegyldigt, i hvilken rækkefølge sammenkædningsinputsene læses:Hvert input vil blive behandlet fuldt ud til sidst under alle omstændigheder.
Den begrænsede support i versioner op til SQL Server 2008 R2 gælder, hvor der er et mål om nøjagtig én række . I denne specifikke situation vil SQL Server omarrangere sammenkædningsinput på basis af forventede omkostninger.
Dette gøres ikke under omkostningsbaseret optimering (som man kunne forvente), men snarere som en sidste øjebliks efter-optimering omskrivning af det normale optimeringsoutput. Dette arrangement har den fordel, at det ikke øger det omkostningsbaserede plansøgningsrum (potentielt et alternativ for hver mulig genbestilling), mens det stadig producerer en plan, der er optimeret til hurtigt at returnere den første række.
Eksempler
Følgende eksempler bruger to tabeller med identisk indhold:En million rækker med heltal fra én til en million. Én tabel er en bunke uden ikke-klyngede indekser; den anden har et unikt klynget indeks:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Intet rækkemål
Følgende forespørgsel leder efter de samme rækker i hver tabel og returnerer sammenkædningen af de to sæt:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Udførelsesplanen, der er produceret af forespørgselsoptimeringsværktøjet, er:
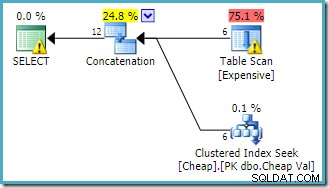
Advarslen på roden SELECT operatøren gør os opmærksom på det åbenlyse manglende indeks på heap-bordet. Advarslen på Table Scan-operatøren er tilføjet af Sentry One Plan Explorer. Det henleder vores opmærksomhed på I/O-omkostningerne for det resterende prædikat gemt i scanningen.
Rækkefølgen af inputs til Sammenkædningen er ligegyldig her, for vi har ikke sat et rækkemål. Begge input læses fuldt ud for at returnere alle resultatrækker. Af interesse (selvom dette ikke er garanteret) skal du bemærke, at rækkefølgen af input følger den tekstmæssige rækkefølge af den oprindelige forespørgsel. Bemærk også, at rækkefølgen af de endelige resultatrækker heller ikke er angivet, da vi ikke brugte en ORDER BY på øverste niveau. klausul. Vi antager, at det er bevidst, og at den endelige bestilling er uden betydning for den aktuelle opgave.
Hvis vi vender om den skrevne rækkefølge af tabellerne i forespørgslen sådan:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Udførelsesplanen følger ændringen og får først adgang til den klyngede tabel (igen, dette er ikke garanteret):
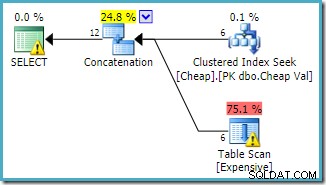
Begge forespørgsler kan forventes at have de samme ydeevnekarakteristika, da de udfører de samme operationer, bare i en anden rækkefølge.
Med et rækkemål
Det er klart, at manglen på indeksering på heap-tabellen normalt vil gøre det dyrere at finde specifikke rækker sammenlignet med den samme operation på den klyngede tabel. Hvis vi beder optimeringsværktøjet om en plan, der returnerer den første række hurtigt, ville vi forvente, at SQL Server omarrangerer sammenkædningsinput, så den billige klyngede tabel konsulteres først.
Brug forespørgslen, der nævner heap-tabellen først, og brug af et FAST 1-forespørgselstip til at angive rækkemålet:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Den estimerede eksekveringsplan produceret på en forekomst af SQL Server 2008 R2 er:
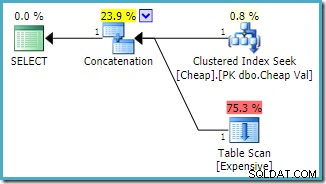
Bemærk, at sammenkædningsindgangene er blevet omarrangeret for at reducere de estimerede omkostninger ved at returnere den første række. Bemærk også, at det manglende indeks og resterende I/O-advarsler er forsvundet. Ingen af problemerne har betydning for denne planform, når målet er at returnere en enkelt række så hurtigt som muligt.
Den samme forespørgsel blev udført på SQL Server 2016 (ved at bruge en af kardinalitetsestimatmodellerne) er:
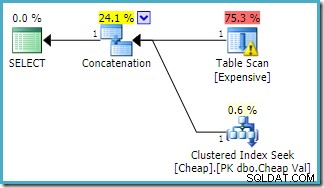
SQL Server 2016 har ikke omorganiseret sammenkædningsinput. Plan Explorer I/O-advarslen er vendt tilbage, men desværre har optimeringsværktøjet ikke produceret en manglende indeksadvarsel denne gang (selvom den er relevant).
Generel genbestilling
Som nævnt er omskrivningen efter optimering, der genbestiller sammenkædningsinput, kun effektiv til:
- SQL Server 2008 R2 og tidligere
- Et rækkemål på præcis én
Hvis vi reelt kun vil have én række returneret i stedet for en plan, der er optimeret til at returnere den første række hurtigt (men som i sidste ende stadig vil returnere alle rækker), kan vi bruge en TOP klausul med en afledt tabel eller fælles tabeludtryk (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; På SQL Server 2008 R2 eller tidligere producerer dette den optimale genbestillede inputplan:
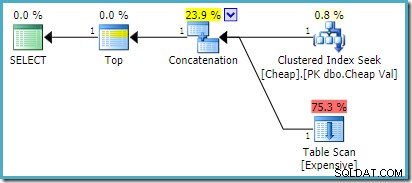
På SQL Server 2012, 2014 og 2016 forekommer der ingen genbestilling efter optimering:
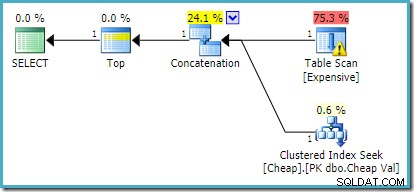
Hvis vi ønsker mere end én række returneret, for eksempel ved at bruge TOP (2) , vil den ønskede omskrivning ikke blive anvendt på SQL Server 2008 R2, selvom en FAST 1 tip bruges også. I den situation skal vi ty til tricks som at bruge TOP med en variabel og en OPTIMIZE FOR tip:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint Forespørgselstippet er tilstrækkeligt til at angive et rækkemål på én, mens kørselsværdien af variablen sikrer, at det ønskede antal rækker (2) returneres.
Den faktiske udførelsesplan på SQL Server 2008 R2 er:
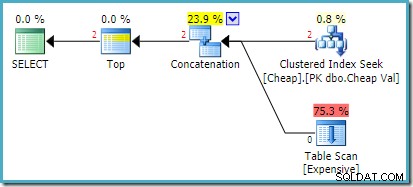
Begge rækker, der returneres, kommer fra det omordnede søgeinput, og tabelscanningen udføres slet ikke. Plan Explorer viser rækkeantallet med rødt, fordi estimatet var for én række (på grund af tippet), mens to rækker blev stødt på under kørslen.
Uden UNION ALL
Dette problem er heller ikke begrænset til forespørgsler skrevet eksplicit med UNION ALL . Andre konstruktioner såsom EXISTS og OR kan også resultere i, at optimizeren introducerer en sammenkædningsoperator, som kan lide under manglen på input-ombestilling. Der var for nylig et spørgsmål om Database Administrators Stack Exchange med netop dette problem. At transformere forespørgslen fra det spørgsmål til at bruge vores eksempeltabeller:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; Udførelsesplanen på SQL Server 2016 har heap-tabellen på det første input:
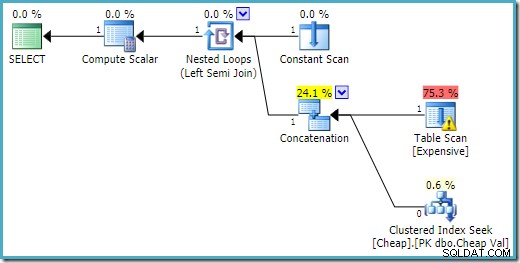
På SQL Server 2008 R2 er rækkefølgen af inputs optimeret til at afspejle den enkelte rækkes mål for semi join:
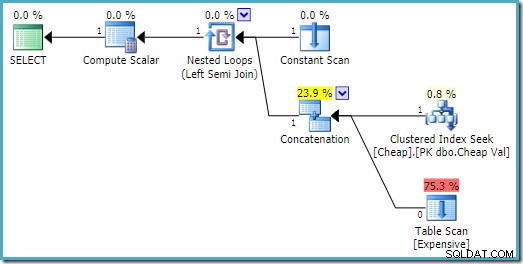
I den mere optimale plan udføres heap-scanningen aldrig.
Løsninger
I nogle tilfælde vil det være tydeligt for forespørgselsskriveren, at et af sammenkædningsinputs altid vil være billigere at køre end de andre. Hvis det er sandt, er det ganske gyldigt at omskrive forespørgslen, så de billigere sammenkædningsinput vises først i skriftlig rækkefølge. Det betyder selvfølgelig, at forespørgselsskriveren skal være opmærksom på denne optimeringsbegrænsning og være forberedt på at stole på udokumenteret adfærd.
Et mere vanskeligt problem opstår, når omkostningerne ved sammenkædningsinput varierer med omstændighederne, måske afhængigt af parameterværdier. Ved hjælp af OPTION (RECOMPILE) vil ikke hjælpe på SQL Server 2012 eller nyere. Denne mulighed kan hjælpe på SQL Server 2008 R2 eller tidligere, men kun hvis kravet til enkeltrækkemål også er opfyldt.
Hvis der er bekymringer om at stole på observeret adfærd (forespørgselsplansammenkædningsinput, der matcher forespørgslens tekstrækkefølge), kan en planvejledning bruges til at fremtvinge planformen. Hvor forskellige inputordrer er optimale til forskellige omstændigheder, kan der bruges flere planguider, hvor betingelserne kan kodes nøjagtigt på forhånd. Dette er dog næppe ideelt.
Sidste tanker
SQL Server-forespørgselsoptimeringsværktøjet indeholder faktisk en omkostningsbaseret udforskningsregel, UNIAReorderInputs , som er i stand til at generere sammenkædningsinput-ordrevariationer og udforske alternativer under omkostningsbaseret optimering (ikke som en enkelt-skuds efter-optimering omskrivning).
Denne regel er i øjeblikket ikke aktiveret til generel brug. Så vidt jeg kan se, er det kun aktiveret, når en plan guide eller USE PLAN hint er til stede. Dette gør det muligt for motoren at gennemtvinge en plan, der blev genereret for en forespørgsel, der kvalificerede sig til omskrivning af input-genbestilling, selv når den aktuelle forespørgsel ikke er kvalificeret.
Min fornemmelse er, at denne udforskningsregel bevidst er begrænset til denne brug, fordi forespørgsler, der ville drage fordel af genbestilling af sammenkædningsinput som en del af omkostningsbaseret optimering, anses for ikke at være tilstrækkeligt almindelige, eller måske fordi der er en bekymring for, at den ekstra indsats ikke ville betale sig. af. Min egen opfattelse er, at genbestilling af input fra sammenkædningsoperatør altid bør undersøges, når et rækkemål er i kraft.
Det er også en skam, at den (mere begrænsede) omskrivning efter optimering ikke er effektiv i SQL Server 2012 eller nyere. Dette kan have været på grund af en subtil fejl, men jeg kunne ikke finde noget om dette i dokumentationen, videnbasen eller på Connect. Jeg har tilføjet et nyt Connect-element her.
Opdatering 9. august 2017 :Dette er nu rettet under sporingsflag 4199 for SQL Server 2014 og 2016, se KB 4023419:
RETNING:Forespørgsel med UNION ALL og et rækkemål kan køre langsommere i SQL Server 2014 eller nyere versioner, når det sammenlignes med SQL Server 2008 R2