Scalar UDF'er har altid været et tveægget sværd – de er gode til udviklere, som får abstraheret kedelig logik i stedet for at gentage det over hele deres forespørgsler, men de er forfærdelige for runtime-ydeevne i produktionen, fordi optimeringsværktøjet ikke ikke håndtere dem pænt. Det, der i bund og grund sker, er, at UDF-henrettelserne holdes adskilt fra resten af udførelsesplanen, så de bliver kaldt én gang for hver række og kan ikke optimeres baseret på estimeret eller faktisk antal rækker eller foldes ind i resten af planen.
Da vi, på trods af vores bedste indsats siden SQL Server 2000, ikke effektivt kan forhindre, at skalar UDF'er bliver brugt, ville det så ikke være fantastisk at få SQL Server til blot at håndtere dem bedre?
SQL Server 2019 introducerer en ny funktion kaldet Scalar UDF Inlining. I stedet for at holde funktionen adskilt, indarbejdes den i helhedsplanen. Dette fører til en meget bedre eksekveringsplan og til gengæld bedre køretidsydelse.
Men først, for bedre at illustrere kilden til problemet, lad os starte med et par simple tabeller med kun et par rækker i en database, der kører på SQL Server 2017 (eller på 2019, men med et lavere kompatibilitetsniveau):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Nu har vi en simpel forespørgsel, hvor vi vil vise hver medarbejder og navnet på deres primære sprog. Lad os sige, at denne forespørgsel bruges mange steder og/eller på forskellige måder, så i stedet for at indbygge en joinforbindelse i forespørgslen, skriver vi en skalar UDF for at abstrahere den join:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Så ser vores faktiske forespørgsel sådan her ud:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Hvis vi ser på udførelsesplanen for forespørgslen, mangler der noget mærkeligt:
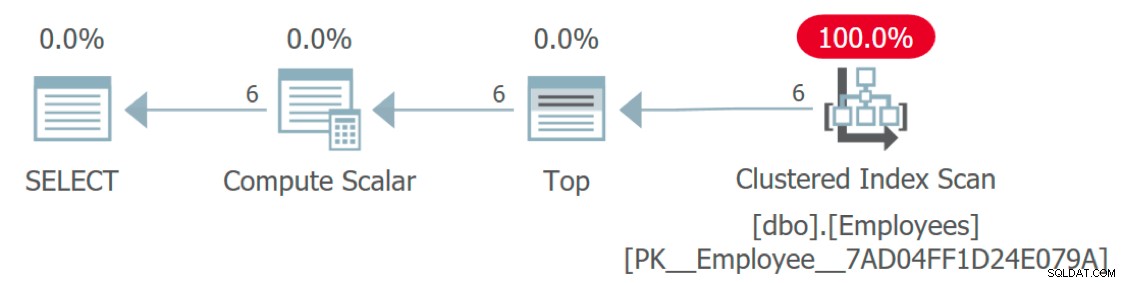 Udførelsesplan, der viser adgang til medarbejdere, men ikke til sprog
Udførelsesplan, der viser adgang til medarbejdere, men ikke til sprog
Hvordan får man adgang til tabellen Sprog? Denne plan ser meget effektiv ud, fordi den – ligesom funktionen selv – abstraherer noget af den involverede kompleksitet. Faktisk er denne grafiske plan identisk med en forespørgsel, der blot tildeler en konstant eller variabel til Language kolonne:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Men hvis du kører en sporing mod den oprindelige forespørgsel, vil du se, at der faktisk er seks kald til funktionen (et for hver række) ud over hovedforespørgslen, men disse planer returneres ikke af SQL Server.
Du kan også bekræfte dette ved at tjekke sys.dm_exec_function_stats , men dette er ikke en garanti :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer vil vise erklæringerne, hvis du genererer en egentlig plan inde fra produktet, men vi kan kun få dem fra sporing, og der er stadig ingen planer indsamlet eller vist for de individuelle funktionskald:
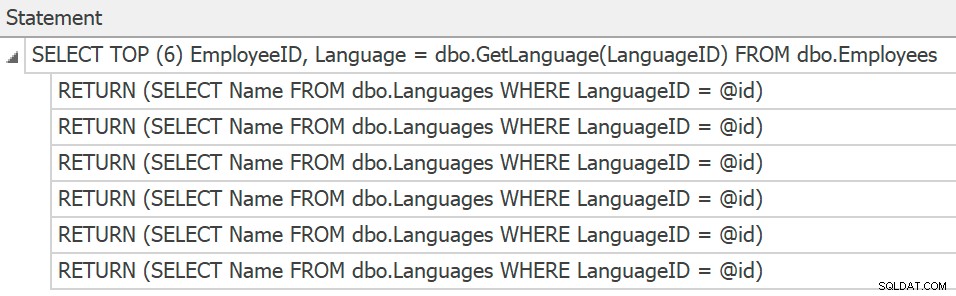 Sporingsudsagn for individuelle skalære UDF-ankaldelser
Sporingsudsagn for individuelle skalære UDF-ankaldelser
Alt dette gør dem meget svære at fejlfinde, fordi du er nødt til at gå på jagt efter dem, selv når du allerede ved, at de er der. Det kan også skabe et rigtig rod i præstationsanalysen, hvis du sammenligner to planer baseret på ting som estimerede omkostninger, fordi ikke kun de relevante operatører gemmer sig fra det fysiske diagram, omkostningerne er heller ikke inkorporeret nogen steder i planen.
Spol frem til SQL Server 2019
Efter alle disse år med problematisk adfærd og obskure grundlæggende årsager, har de gjort det, så nogle funktioner kan optimeres ind i den overordnede eksekveringsplan. Scalar UDF Inlining gør de objekter, de får adgang til, synlige til fejlfinding *og* tillader dem at blive foldet ind i udførelsesplanstrategien. Nu giver kardinalitetsestimater (baseret på statistik) mulighed for join-strategier, der simpelthen ikke var mulige, da funktionen blev kaldt én gang for hver række.
Vi kan bruge det samme eksempel som ovenfor, enten oprette det samme sæt objekter på en SQL Server 2019-database eller skrubbe plancachen og op på kompatibilitetsniveauet til 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Når vi nu kører vores seks-rækkede forespørgsel igen:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Vi får en plan, der inkluderer tabellen Sprog og omkostningerne forbundet med at få adgang til den:
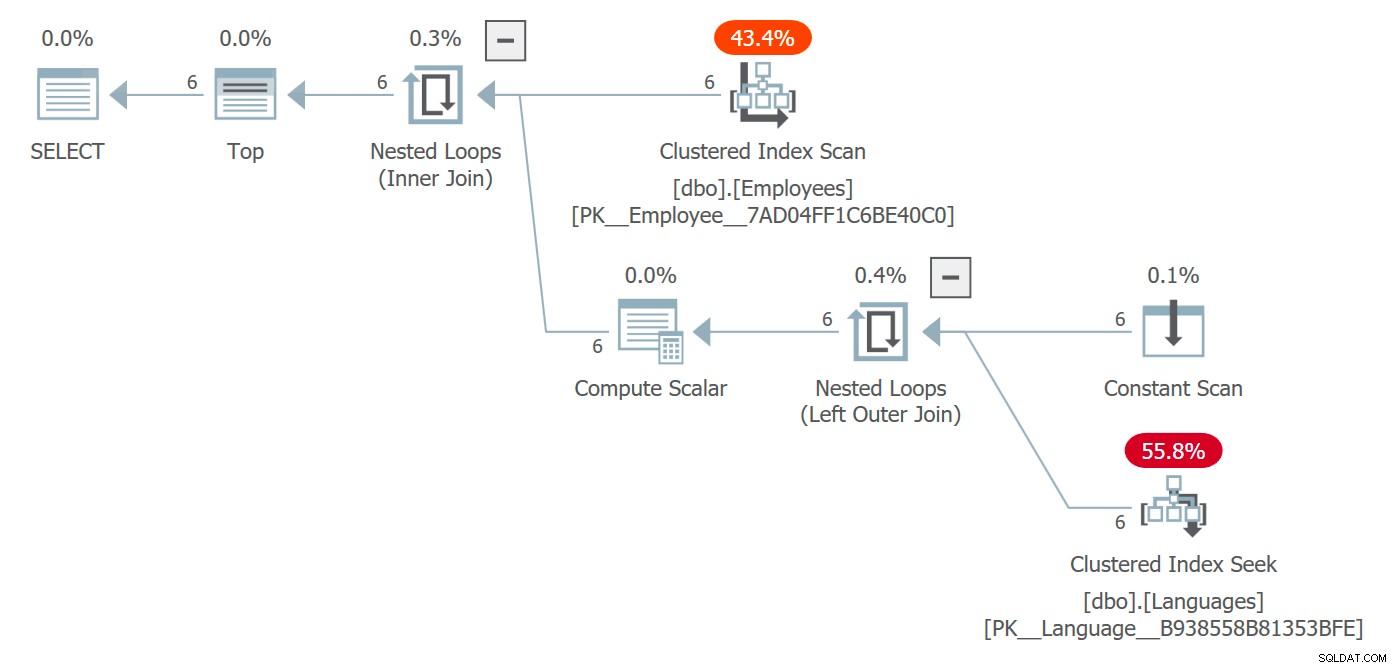 Plan, der inkluderer adgang til objekter, der henvises til i skalar UDF
Plan, der inkluderer adgang til objekter, der henvises til i skalar UDF
Her valgte optimeringsværktøjet en indlejret sløjfesammenføjning, men under andre omstændigheder kunne den have valgt en anden sammenføjningsstrategi, overvejet parallelitet og i det væsentlige været fri til fuldstændig at ændre planformen. Du vil sandsynligvis ikke se dette i en forespørgsel, der returnerer 6 rækker og ikke er et ydeevneproblem på nogen måde, men i større skalaer kunne det.
Planen afspejler, at funktionen ikke kaldes pr. række – mens søgningen faktisk udføres seks gange, kan du se, at selve funktionen ikke længere vises i sys.dm_exec_function_stats . En ulempe, du kan tage væk, er, at hvis du bruger denne DMV til at afgøre, om en funktion aktivt bliver brugt (som vi ofte gør til procedurer og indekser), vil den ikke længere være pålidelig.
Forbehold
Ikke enhver skalarfunktion er inlinebar, og selv når en funktion *er* inlinebar, vil den ikke nødvendigvis være inlinet i hvert scenarie. Dette har ofte at gøre med enten kompleksiteten af funktionen, kompleksiteten af den involverede forespørgsel eller kombinationen af begge. Du kan kontrollere, om en funktion er inlinebar i sys.sql_modules katalogvisning:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
Og hvis du af en eller anden grund ikke ønsker, at en bestemt funktion (eller nogen funktion i en database) skal indlejres, behøver du ikke stole på databasens kompatibilitetsniveau for at kontrollere denne adfærd. Jeg har aldrig kunnet lide den løse kobling, som er beslægtet med at skifte rum for at se et andet tv-program i stedet for blot at skifte kanal. Du kan styre dette på modulniveau ved hjælp af INLINE-indstillingen:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
Og du kan kontrollere dette på databaseniveau, men adskilt fra kompatibilitetsniveau:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Selvom du skal have en ret god brugskasse for at svinge den hammer, IMHO.
Konklusion
Nu foreslår jeg ikke, at du kan gå og abstrahere hvert stykke logik til en skalar UDF og antage, at nu vil SQL Server bare tage sig af alle sager. Hvis du har en database med meget skalær UDF-brug, bør du downloade den seneste SQL Server 2019 CTP, gendanne en sikkerhedskopi af din database der og tjekke DMV'en for at se, hvor mange af disse funktioner, der vil være inlineable, når tiden kommer. Det kan være et vigtigt punkt, næste gang du argumenterer for en opgradering, da du i det væsentlige vil få al den ydeevne og spildte fejlfindingstid tilbage.
I mellemtiden, hvis du lider af skalær UDF-ydeevne, og du ikke vil opgradere til SQL Server 2019 på et tidspunkt, kan der være andre måder at afhjælpe problemet/problemerne på.
Bemærk:Jeg skrev og stillede denne artikel i kø, før jeg indså, at jeg allerede havde postet et andet stykke andetsteds.