I tidligere blogindlæg har vi dækket emner til overvågning af din Galera-klynge, uanset om det er MySQL eller MariaDB. Selvom teknologiversionerne ikke adskiller sig meget, har MariaDB Cluster nogle store ændringer siden version 10.4.2. I denne version understøtter den Galera Cluster 4 og har nogle fantastiske nye funktioner, som vi vil se på i dette blogindlæg.
For begyndere, der endnu ikke er fortrolige med MariaDB Cluster, er en praktisk talt synkron multi-master-klynge til MariaDB. Den er kun tilgængelig på Linux og understøtter kun XtraDB/InnoDB-lagringsmotorerne (selvom der er eksperimentel understøttelse af MyISAM - se systemvariablen wsrep_replicate_myisam).
Softwaren er en bundtet teknologi, der drives af MariaDB Server, MySQL-wsrep patch til MySQL Server og MariaDB Server udviklet af Codership (understøtter Unix-lignende OS) og Galera wsrep-udbyderbiblioteket.
Du kan sammenligne dette produkt med MySQL Group Replication eller med MySQL InnoDB Cluster, som har til formål at give høj tilgængelighed. (Selvom de er forskellige med hensyn til principper og tilgange til at give HA.)
Nu hvor vi har dækket det grundlæggende, vil vi i denne blog give tips, som vi synes er nyttige, når vi overvåger din MariaDB-klynge.
The Essentials of MariaDB Cluster
Når du begynder at bruge MariaDB Cluster, skal du identificere, hvad der præcist er dit formål, og hvorfor du har valgt MariaDB Cluster i første omgang. Først skal du fordøje, hvad der er funktionerne og deres fordele, når du bruger MariaDB Cluster. Grunden til at identificere disse er, fordi det i bund og grund er det, der skal overvåges og kontrolleres, for at du kan bestemme ydeevne, normale helbredsforhold, og om det kører i overensstemmelse med dine planer.
I bund og grund identificeres det som ingen slaveforsinkelse, ingen tabte transaktioner, læseskalerbarhed og mindre klientforsinkelser. Så kan der opstå spørgsmål som, hvordan gør det ingen slaveforsinkelse eller tabte transaktioner? Hvordan gør det, at læsning er skalerbar eller med mindre forsinkelser på klientsiden? Disse områder er et af de nøgleområder, du skal se og overvåge, især for tung produktionsbrug.
Selvom selve MariaDB-klyngen kan tilpasses i overensstemmelse hermed. Anvendelse af ændringer til standardadfærden såsom pc.weight eller pc.ignore_quorum, eller endda brug af multicast med UDP til et stort antal noder, kan påvirke den måde, du overvåger din MariaDB-klynge på. Men på den anden side er de mest essentielle statusvariabler sædvanligvis din guldkant her ved at vide, at tilstanden og flowet af din klynge fungerer fint, eller at dens nedbrydende viser et muligt problem, der på forhånd kan føre til en katastrofal fiasko.
Overvåg altid din serveraktivitet (netværk, disk, indlæsning, hukommelse og CPU)
Overvågning af din serveraktivitet kan også være en kompleks opgave, hvis du har en meget kompliceret stak, der er flettet ind i din databasearkitektur. For en MariaDB-klynge er det dog altid bedst at have dine noder opsat så dedikeret, men alligevel enkle som muligt. Selvom det ikke begrænser dig fra at bruge alle de ekstra ressourcer, er nedenfor de fælles nøgleområder, du skal se nærmere på.
Netværk
Galera Cluster 4 har streamingreplikering som en af nøglefunktionerne og ændringerne fra den tidligere version. Da streaming-replikering adresserer de ulemper, den havde i de tidligere udgivelser, men tillader den at administrere mere end 2 GB skrivesæt siden Galera Cluster 4. Dette tillader store transaktioner at blive fragmenteret, og det anbefales stærkt at aktivere dette alene på sessionsniveau. Dette betyder, at overvågning af din netværksaktivitet er meget vigtig og afgørende for den normale aktivitet i din MariaDB-klynge. Dette vil hjælpe dig med at identificere, hvilken node der havde mest eller højeste netværkstrafik baseret på tidsperioden.
Så hvordan vil det hjælpe dig med at forbedre, hvor noder med den højeste netværkstrafik er blevet identificeret? Nå, dette giver dig plads til forbedringer med din databasetopologi eller det arkitektoniske lag i din databaseklynge. Brug af belastningsbalancere eller en databaseproxy giver dig mulighed for proaktivt at konfigurere din databasetrafik, især når du bestemmer, hvilke specifikke skrivninger der skal gå til en specifik node. Lad os sige, at ud af de 3 noder er en af dem mere i stand til at håndtere store og store forespørgsler på grund af forskelle med hardwarespecifikationerne. Dette giver dig mulighed for at administrere mere af dine investeringer og forbedre din kapacitetsplanlægning, efterhånden som kravene til en bestemt tidsperiode ændrer sig.
Disk
Netværksaktivitet har også betydning for din diskydeevne, især under skylletiden. Det er også bedst at bestemme, hvordan forpligtet tid og hentning klarer sig, når høj spidsbelastning nås. Der er tidspunkter, hvor du fylder din databasevært op med ikke kun at være dedikeret til en Galera Cluster-aktivitet, men også blande dig med andre værktøjer som docker, SQL-proxyer såsom ProxySQL eller MaxScale. Dette giver dig kontrol med lavbelastningsservere og giver dig mulighed for at bruge de ledige ressourcer, der kan bruges til andre gavnlige formål, især til din databasearkitekturstak. Når du er i stand til at bestemme, hvilken node ved overvågning har den laveste belastning, men stadig er i stand til at styre sin disk-IO-udnyttelse, så kan du vælge den specifikke node, mens du holder øje med tiden, der går. Igen giver dette dig stadig bedre styring med din kapacitetsplanlægning.
CPU, hukommelse og indlæsningsaktivitet
Lad mig kort beskrive disse tre områder, der skal ses på ved overvågning. I dette afsnit er det altid bedst, at du har bedre observerbarhed af følgende områder på én gang. Det er hurtigere og nemmere at forstå, især ved at udelukke en flaskehals i ydeevnen eller identificere fejl, der får dine noder til at gå i stå, og som også kan påvirke de andre noder og muligheden for at gå ned i klyngen.
Så hvordan hjælper CPU, hukommelse og indlæsningsaktivitet ved overvågning din MariaDB-klynge? Nå, som det jeg har nævnt ovenfor, er det en af de få ting, der endnu er en stor faktor for daglige rutinetjek. Nu hjælper dette dig også med at identificere, om disse er periodiske eller tilfældige hændelser. Hvis det er periodisk, kan det være relateret til sikkerhedskopier, der kører i en af dine Galera-noder, eller det er en massiv forespørgsel, der kræver optimering. For eksempel dårlige forespørgsler uden ordentlige indekser eller ubalanceret brug af datahentning, såsom at lave en strengsammenligning for så stor en streng. Det kan unægtelig være uanvendeligt for databaser af OLTP-typen såsom MariaDB Cluster, især hvis det virkelig er arten og kravene til din applikation. Brug bedre andre analytiske værktøjer såsom MariaDB Columnstore eller andre analytiske behandlingsværktøjer fra tredjepart (Apache Spark, Kafka eller MongoDB osv.) til hentning af store strengedata og/eller strengmatchning.
Så med alle disse nøgleområder, der overvåges, er spørgsmålet, hvordan det skal overvåges? Det skal overvåges mindst pr. minut. Med raffineret overvågning, dvs. per-sekund af kollektive målinger kan være ressourcekrævende og meget grådige med hensyn til dine ressourcer. Selvom et halvt minuts kollektivitet er acceptabelt, især hvis dine data og RPO (recovery point goal) er meget lavt, så du har brug for mere detaljerede og realtidsdatamålinger. Det er meget vigtigt, at du er i stand til at overskue hele billedet af din databaseklynge. Bortset fra dette er det også bedst og vigtigt, at når som helst hvilke målinger du overvåger, har du det rigtige værktøj til at få din opmærksomhed, når ting er i fare eller endda bare advarsler. Brug af det rigtige værktøj såsom ClusterControl hjælper dig med at styre disse nøgleområder, der skal overvåges. Jeg bruger her en gratis version eller community-udgave af ClusterControl og hjælper mig med at overvåge mine noder uden besvær fra installation til overvågning af noder med blot et par klik. Se f.eks. skærmbillederne nedenfor:

Visningen er et mere raffineret og hurtigt overblik over, hvad der sker i øjeblikket. En mere granulær graf kan også bruges,
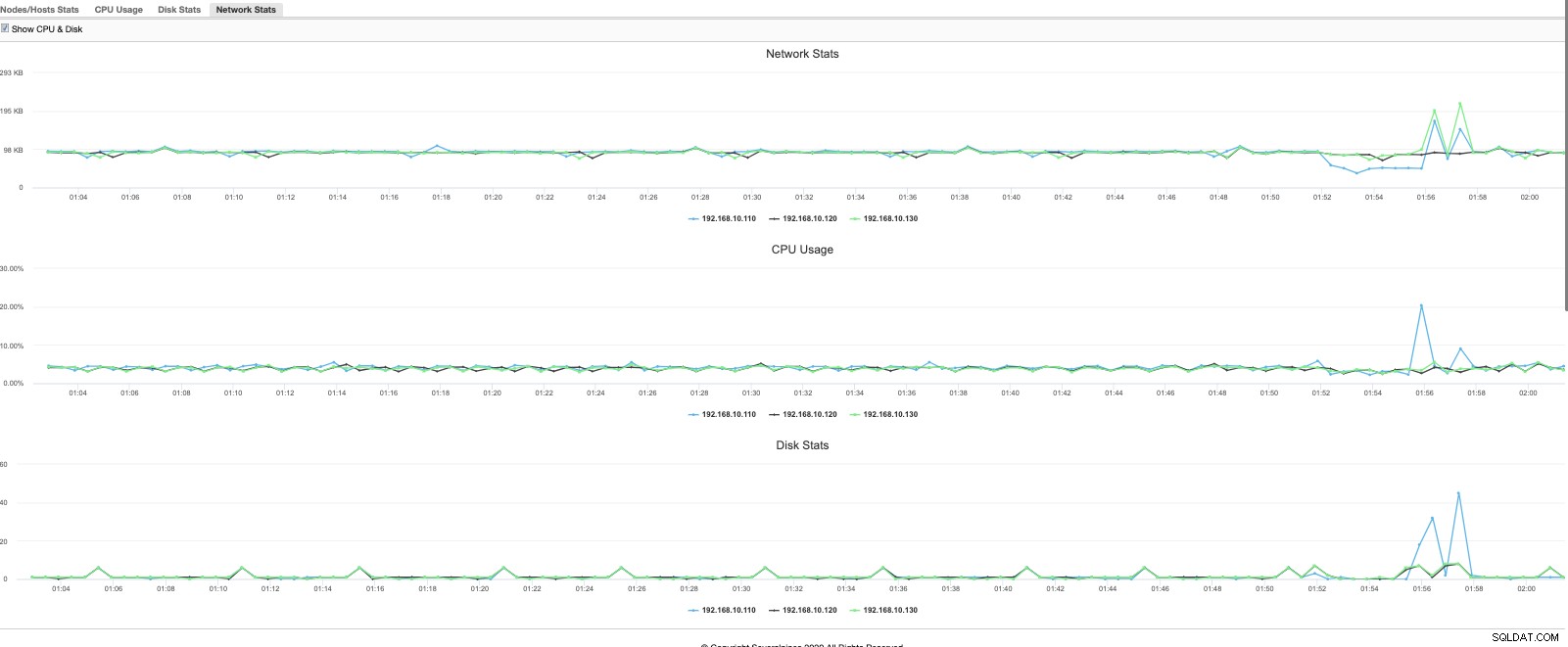
eller med en mere kraftfuld og rig datamodel, som også understøtter forespørgselssprog, kan give dig en analyse af, hvordan din MariaDB-klynge klarer sig baseret på historiske data, der sammenligner dens ydeevne rettidigt. For eksempel,
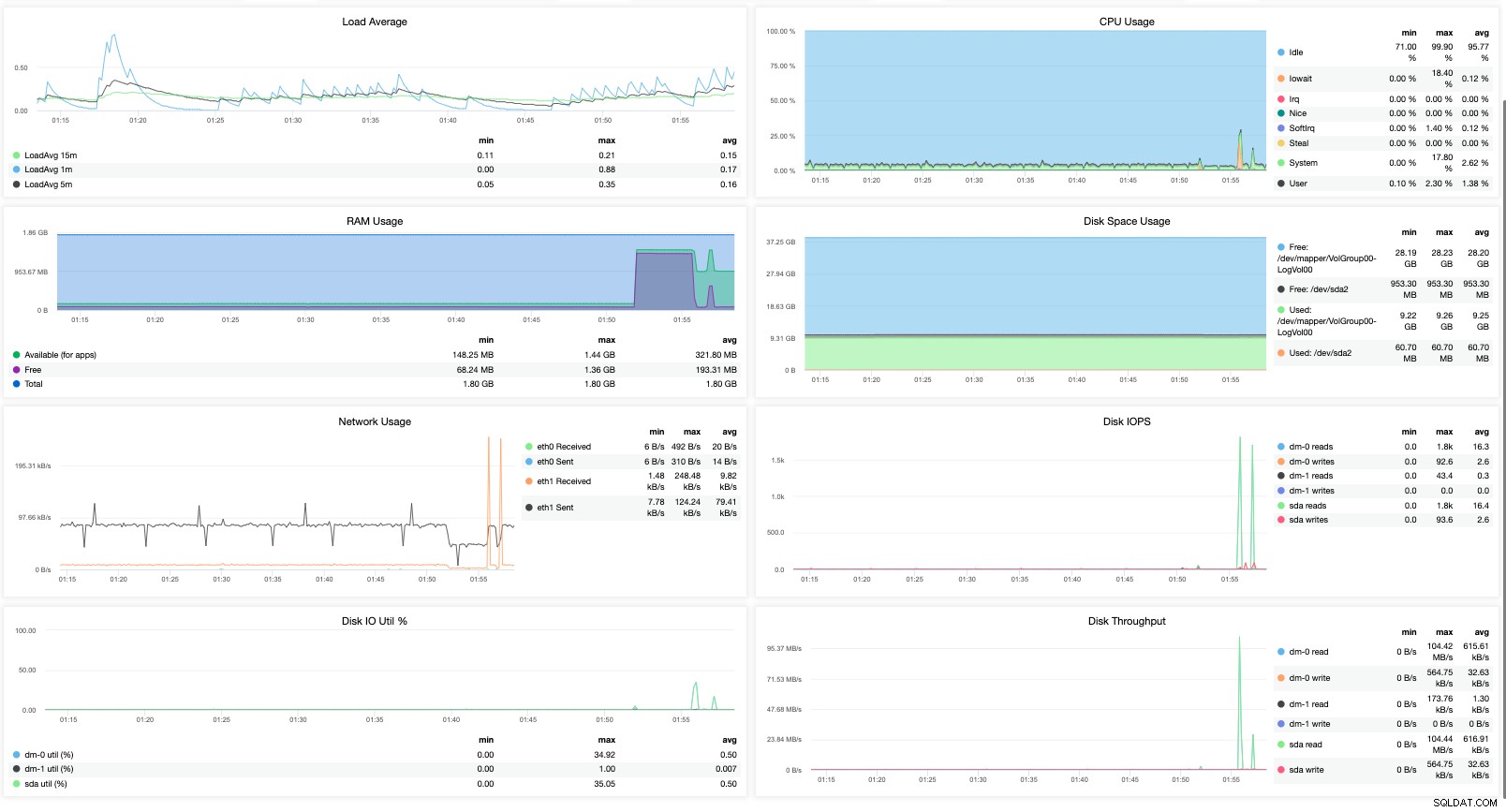
Det giver dig bare mere synlige metrics. Så du kan se, hvor vigtigt det virkelig er at have det rigtige værktøj, når du overvåger din MariaDB-klynge.
Sørg for kollektiv overvågning af dine MariaDB-klyngestatistiske variabler
Fra tid til anden kan det ikke være uundgåeligt, at MariaDB Cluster-versioner vil producere nye statistikker for at overvåge eller forbedre karakteren af overvågning af databasen ved at give flere statusvariabler og forfine værdier at se på. Som det jeg har nævnt ovenfor, bruger jeg ClusterControl til at overvåge mine noder i denne eksempelblog. Det betyder dog ikke, at det er det bedste værktøj derude. Jeg mener, PMM fra Percona er meget rig, når det kommer til kollektiv overvågning for hver statistisk variabel, at når MariaDB Cluster har nyere statistiske variabler at tilbyde, kan du udnytte dette og også ændre det, da PMM er et open source-værktøj. Det er en stor fordel, at du også har al synlighed af din MariaDB-klynge, da alle aspekter tæller, især i en produktionsbaseret database, der imødekommer hundredtusindvis af anmodninger i minuttet.
Men lad os komme nærmere ind på problemet her. Hvad er disse statistiske variabler at se nærmere på? Der er mange at regne med for en MariaDB-klynge, men ved igen at fokusere på de funktioner og fordele, som vi tror, du bruger MariaDB-klyngen, hvad den har at tilbyde, så fokuserer vi på det.
Galera Cluster - Flowkontrol
Flowstyringen af din MariaDB-klynge giver dig overblikket over, hvordan replikationstilstanden fungerer overalt i klyngen. Replikeringsprocessen i Galera Cluster bruger en feedback-mekanisme, hvilket betyder, at den signalerer over hele noderne i den klynge og markerer, om noden skal pause eller genoptage replikering i henhold til dens behov. Dette forhindrer også, at enhver node halter for langt, mens de andre anvender de indgående transaktioner. Sådan fungerer flowkontrollen som sin funktion i Galera. Nu skal dette ses og ikke overses, når du overvåger din MariaDB-klynge. Dette, som nævnt i en af fordelene ved at bruge MariaDB Cluster, er, at undgåelsen af at have slavelag. Selvom det er for naivt til at forstå om flowstyringen og slaveforsinkelsen, men med flowkontrol vil det påvirke din Galera-klynges ydeevne, når der er meget kø, og commits eller flushing af sider til disken går meget lavt for sådanne diskproblemer eller det er bare den forespørgsel, der kører, er en dårlig forespørgsel. Hvis du er nybegynder af, hvordan Galera fungerer, kan du være interesseret i at læse dette eksterne indlæg om, hvad der er flowkontrol i Galera.
Bytes sendt/modtaget
De sendte eller modtagne bytes korrelerer med netværksaktiviteten og er endda et af nøgleområderne at se side om side med flowkontrol. Dette giver dig mulighed for at bestemme, hvilken node der er mest påvirket eller tilskriver de præstationsproblemer, der lider i din Galera-klynge. Det er meget vigtigt, da du kan tjekke, om der kan være nogen forringelse med hensyn til hardware, såsom din netværksenhed eller den underliggende lagerenhed, for hvilken synkronisering af beskidte sider kan tage for lang tid at udføre.
Klyngeindlæsning
Nå, dette er mere databaseaktiviteten af, hvor mange ændringer eller datahentning der er blevet forespurgt eller udført indtil nu siden serverens oppetid. Det hjælper dig med at udelukke, hvilken slags forespørgsler, der mest påvirker din databaseklyngeydelse. Dette giver dig mulighed for at give plads til forbedringer, især med hensyn til at afbalancere belastningen af dine databaseanmodninger. Brug af ProxySQL hjælper dig her med en mere raffineret og detaljeret tilgang til forespørgselsrouting. Selvom MaxScale også tilbyder denne funktion, har ProxySQL mere granularitet, selvom det også tjener en vis ydeevnepåvirkning eller omkostninger. Virkningen kommer, når du kun har én ProxySQL som SQL-proxy til at udarbejde forespørgselsrutingen, og det kan kæmpe, når der er høj trafik i gang. Har omkostninger, hvis du tilføjer flere ProxySQL noder for at balancere mere af trafikken, som en underliggende KeepAlived. Selvom dette er en perfekt kombination, men den kan køres til en lav pris, indtil det er nødvendigt. Men hvordan vil du være i stand til at afgøre, om det er nødvendigt, ikke? Det er spørgsmålet, der forbliver her, så et skarpt øje til at overvåge disse nøgleområder er meget vigtigt, ikke kun for observerbarhed, men også for at forbedre ydeevnen af din databaseklynge, som tiden går.
Som sådan er der tonsvis af variabler at se på i en MariaDB-klynge. Det vigtigste her, du skal tage højde for, er det værktøj, du bruger til at overvåge din databaseklynge. Som nævnt tidligere foretrækker jeg at bruge den gratis version af ClusterControl (Community Edition) her i denne blog, da det giver mig flere måder med fleksibilitet at se på i en Galera Cluster. Se eksemplet nedenfor,
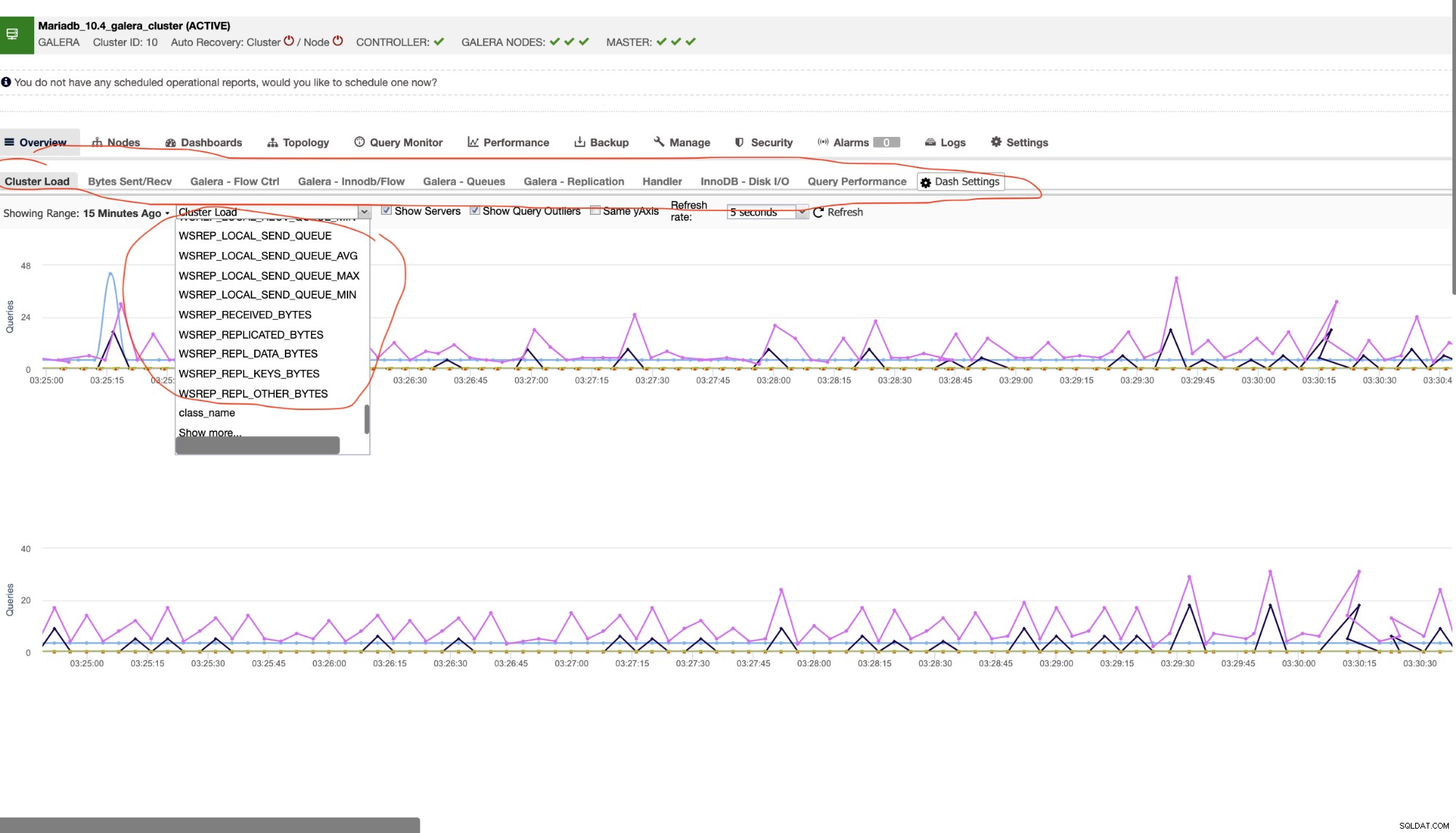
Jeg har markeret eller sat en cirkel med rødt de faner, der giver mig mulighed for visuelt at overvåge sundheden for min MariaDB Cluster. Lad os sige, at hvis din applikation er grådig over at bruge streamingreplikering fra tid til anden, og den sender et stort antal fragmenter (stor netværksoverførsel) til klyngeinteraktivitet, er det bedst at bestemme, hvor godt dine noder kan håndtere stress. Især under stresstest, før du skubber specifikke ændringer i din applikation, er det altid bedst at prøve at teste for at bestemme kapacitetsstyringen af dit applikationsprodukt og afgøre, om dine nuværende databasenoder og design kan håndtere belastningen af dine applikationskrav.
Selv på en fællesskabsudgave af ClusterControl er jeg i stand til at samle detaljerede og mere raffinerede resultater af sundheden for min MariaDB Cluster. Se nedenfor,
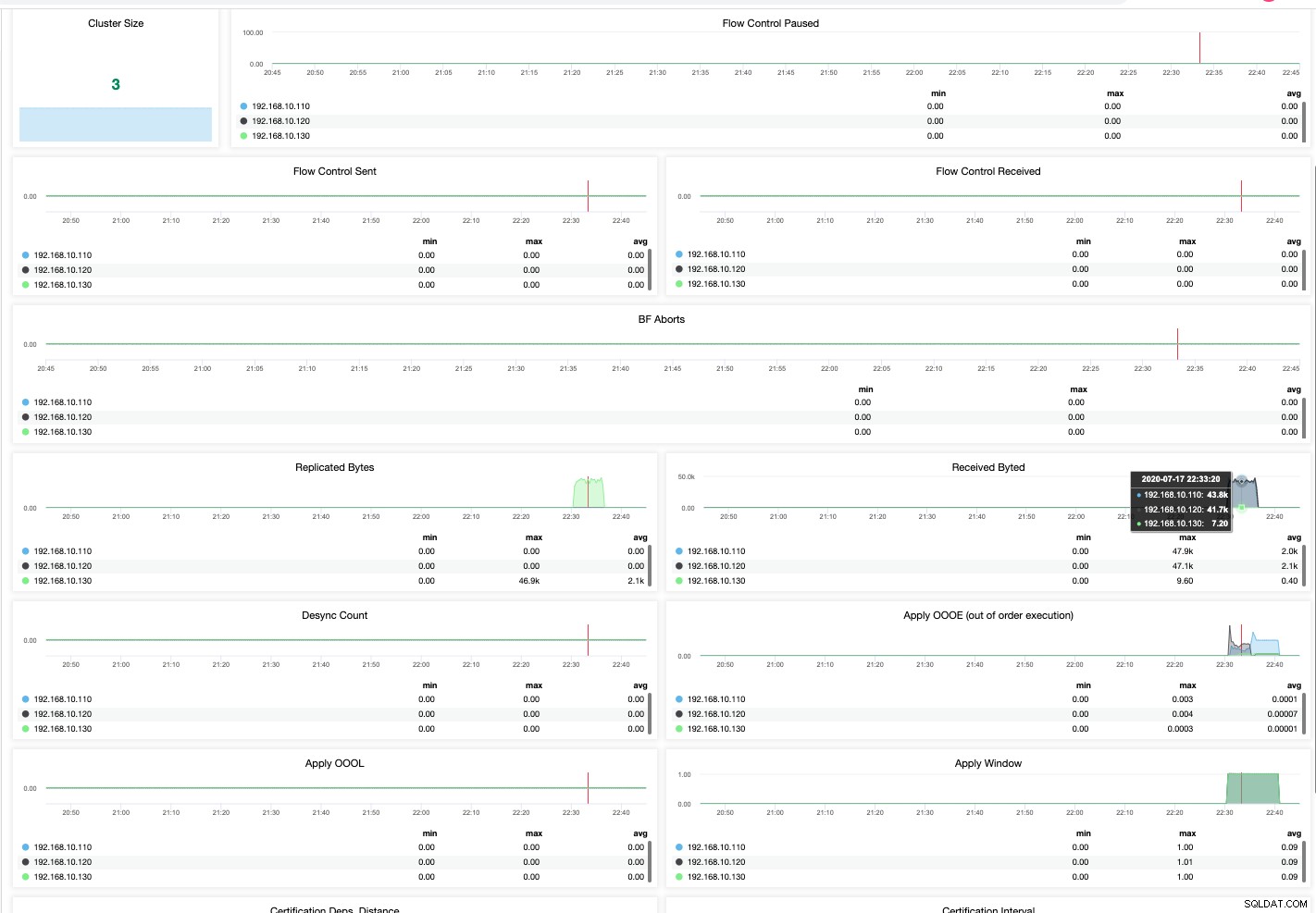
Sådan skal du gribe overvågningen af din MariaDB-klynge an. En perfekt visualisering er altid nemmere og hurtigere at administrere. Når tingene går sydpå, har du ikke råd til at miste din produktivitet, og nedetiden kan også påvirke din virksomhed. Selvom det at have gratis ikke giver dig den luksus og komfort, når du administrerer databaser med stor trafik, er det at have alarmer, meddelelser og databasestyring i ét område en walk-in-the-park-tilføjelse, som ClusterControl kan gøre.
Konklusion
MariaDB Cluster er ikke så enkel at overvåge sammenlignet med de traditionelle asynkrone MySQL/MariaDB master-slave-opsætninger. Det fungerer anderledes, og du skal have de rigtige værktøjer til at bestemme, hvad der foregår, og hvad der skal ind i din databaseklynge. Forbered altid din kapacitetsplanlægning forud, før du kører din MariaDB Cluster uden ordentlig overvågning på forhånd. Det er altid bedst, at din databasebelastning og aktivitet er kendt før en katastrofal begivenhed.