Ydeevne er ekstremt vigtig i mange forbrugerprodukter som e-handel, betalingssystemer, spil, transportapps og så videre. Selvom databaser internt er optimeret gennem flere mekanismer til at opfylde deres ydeevnekrav i den moderne verden, afhænger meget også af applikationsudvikleren - det er trods alt kun en udvikler, der ved, hvilke forespørgsler applikationen skal udføre.
Udviklere, der beskæftiger sig med relationelle databaser, har brugt eller i det mindste hørt om indeksering, og det er et meget almindeligt koncept i databaseverdenen. Den vigtigste del er dog at forstå, hvad der skal indekseres, og hvordan indekseringen vil øge forespørgselssvartiden. For at gøre det skal du forstå, hvordan du vil forespørge i dine databasetabeller. Et ordentligt indeks kan kun oprettes, når du ved præcis, hvordan dine forespørgsler og dataadgangsmønstre ser ud.
I enkel terminologi, kortlægger et indeks søgenøgler til tilsvarende data på disken ved at bruge forskellige datastrukturer i hukommelsen og på disken. Indeks bruges til at gøre søgningen hurtigere ved at reducere antallet af poster, der skal søges efter.
For det meste oprettes et indeks på de kolonner, der er angivet i WHERE klausul i en forespørgsel, da databasen henter og filtrerer data fra tabellerne baseret på disse kolonner. Hvis du ikke opretter et indeks, scanner databasen alle rækkerne, filtrerer de matchende rækker fra og returnerer resultatet. Med millioner af registreringer kan denne scanning tage mange sekunder, og denne høje responstid gør API'er og applikationer langsommere og ubrugelige. Lad os se et eksempel -
Vi vil bruge MySQL med en standard InnoDB-databasemotor, selvom koncepter, der er forklaret i denne artikel, er mere eller mindre de samme i andre databaseservere såvel som Oracle, MSSQL osv.
Opret en tabel kaldet index_demo med følgende skema:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
); Hvordan verificerer vi, at vi bruger InnoDB-motoren?
Kør nedenstående kommando:
SHOW TABLE STATUS WHERE name = 'index_demo' \G; 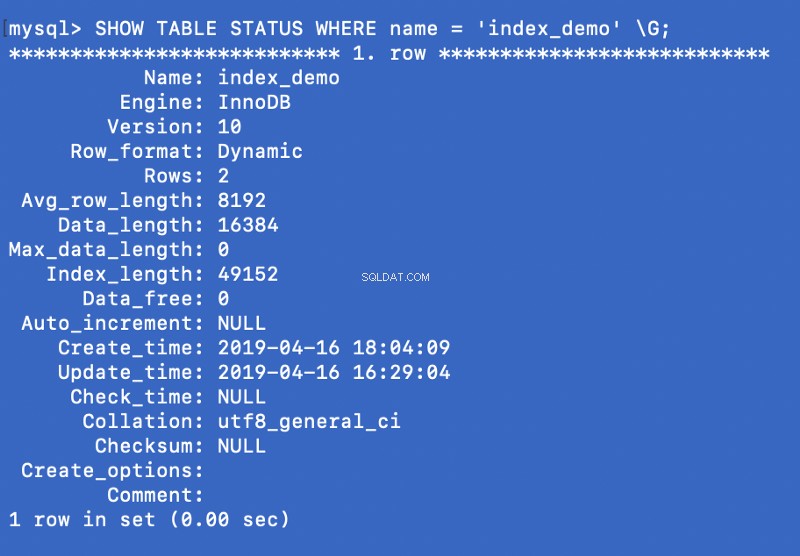
Engine kolonnen i ovenstående skærmbillede repræsenterer den motor, der bruges til at oprette tabellen. Her InnoDB bruges.
Indsæt nu nogle tilfældige data i tabellen, min tabel med 5 rækker ser sådan ud:
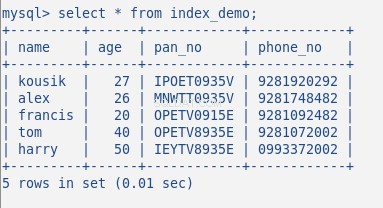
Jeg har ikke oprettet noget indeks indtil nu på denne tabel. Lad os bekræfte dette med kommandoen:SHOW INDEX . Det returnerer 0 resultater.

På dette tidspunkt, hvis vi kører en simpel SELECT forespørgsel, da der ikke er noget brugerdefineret indeks, vil forespørgslen scanne hele tabellen for at finde ud af resultatet:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex'; 
EXPLAIN viser, hvordan forespørgselsmotoren planlægger at udføre forespørgslen. I ovenstående skærmbillede kan du se, at rows kolonne returnerer 5 &possible_keys returnerer null . possible_keys repræsenterer alle tilgængelige indekser, der kan bruges i denne forespørgsel. key kolonne repræsenterer, hvilket indeks der faktisk skal bruges ud af alle mulige indekser i denne forespørgsel.
Primær nøgle:
Ovenstående forespørgsel er meget ineffektiv. Lad os optimere denne forespørgsel. Vi laver phone_no kolonne en PRIMARY KEY forudsat at der ikke kan eksistere to brugere i vores system med det samme telefonnummer. Tag følgende i betragtning, når du opretter en primær nøgle:
- En primær nøgle bør være en del af mange vitale forespørgsler i din ansøgning.
- Primær nøgle er en begrænsning, der unikt identificerer hver række i en tabel. Hvis flere kolonner er en del af den primære nøgle, skal denne kombination være unik for hver række.
- Primær nøgle skal være Non-null. Gør aldrig felter, der kan nulstilles, til din primære nøgle. Ved ANSI SQL-standarder bør primærnøgler være sammenlignelige med hinanden, og du bør helt sikkert kunne se, om værdien af primærnøglekolonnen for en bestemt række er større, mindre eller lig med den samme fra den anden række. Siden
NULLbetyder en udefineret værdi i SQL-standarder, du kan ikke deterministisk sammenligneNULLmed enhver anden værdi, så logiskNULLer ikke tilladt. - Den ideelle primære nøgletype bør være et tal som
INTellerBIGINTfordi heltalssammenligninger er hurtigere, så det vil være meget hurtigt at gå gennem indekset.
Ofte definerer vi et id felt som AUTO INCREMENT i tabeller og brug det som en primær nøgle, men valget af en primær nøgle afhænger af udviklerne.
Hvad hvis du ikke selv opretter en primær nøgle?
Det er ikke obligatorisk at oprette en primær nøgle selv. Hvis du ikke har defineret en primær nøgle, opretter InnoDB implicit en til dig, fordi InnoDB ved design skal have en primær nøgle i hver tabel. Så når du senere opretter en primærnøgle til den tabel, sletter InnoDB den tidligere automatisk definerede primærnøgle.
Da vi ikke har nogen primær nøgle defineret lige nu, lad os se, hvad InnoDB som standard oprettede for os:
SHOW EXTENDED INDEX FROM index_demo; 
EXTENDED viser alle de indekser, der ikke kan bruges af brugeren, men administreres fuldstændigt af MySQL.
Her ser vi, at MySQL har defineret et sammensat indeks (vi vil diskutere sammensatte indekser senere) på DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR , &alle kolonner defineret i tabellen. I mangel af en brugerdefineret primærnøgle, bruges dette indeks til at finde poster unikt.
Hvad er forskellen mellem nøgle og indeks?
Selvom begreberne key &index bruges i flæng, key betyder en begrænsning på kolonnens opførsel. I dette tilfælde er begrænsningen, at den primære nøgle er et felt, der ikke kan nulstilles, hvilket unikt identificerer hver række. På den anden side, index er en speciel datastruktur, der letter datasøgning på tværs af tabellen.
Lad os nu oprette det primære indeks på phone_no &undersøg det oprettede indeks:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Bemærk, at CREATE INDEX kan ikke bruges til at oprette et primært indeks, men ALTER TABLE bruges.

I ovenstående skærmbillede ser vi, at der oprettes ét primært indeks i kolonnen phone_no . Kolonnerne i følgende billeder er beskrevet som følger:
Table :Tabellen, som indekset er oprettet på.
Non_unique :Hvis værdien er 1, er indekset ikke unikt, hvis værdien er 0, er indekset unikt.
Key_name :Navnet på det oprettede indeks. Navnet på det primære indeks er altid PRIMARY i MySQL, uanset om du har angivet et indeksnavn eller ej, mens du oprettede indekset.
Seq_in_index :Løbenummeret for kolonnen i indekset. Hvis flere kolonner er en del af indekset, vil sekvensnummeret blive tildelt baseret på, hvordan kolonnerne blev ordnet under indeksets oprettelsestid. Sekvensnummer starter fra 1.
Collation :hvordan kolonnen er sorteret i indekset. A betyder stigende, D betyder faldende, NULL betyder ikke sorteret.
Cardinality :Det estimerede antal unikke værdier i indekset. Mere kardinalitet betyder større chancer for, at forespørgselsoptimeringsværktøjet vælger indekset for forespørgsler.
Sub_part :Indekspræfikset. Det er NULL hvis hele kolonnen er indekseret. Ellers viser den antallet af indekserede bytes, hvis kolonnen er delvist indekseret. Vi vil definere delvist indeks senere.
Packed :Angiver, hvordan nøglen er pakket; NULL hvis det ikke er.
Null :YES hvis kolonnen kan indeholde NULL værdier og blank, hvis den ikke gør det.
Index_type :Angiver, hvilken indekseringsdatastruktur der bruges til dette indeks. Nogle mulige kandidater er - BTREE , HASH , RTREE , eller FULLTEXT .
Comment :Oplysningerne om indekset er ikke beskrevet i dets egen kolonne.
Index_comment :Kommentaren til indekset angivet, da du oprettede indekset med COMMENT attribut.
Lad os nu se, om dette indeks reducerer antallet af rækker, der vil blive søgt efter en given phone_no i WHERE klausul i en forespørgsel.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002'; 
I dette øjebliksbillede skal du bemærke, at rows kolonnen har returneret 1 kun possible_keys &key begge returnerer PRIMARY . Så det betyder i bund og grund at bruge det primære indeks navngivet som PRIMARY (navnet tildeles automatisk, når du opretter den primære nøgle), forespørgselsoptimeringsværktøjet går bare direkte til posten og henter den. Det er meget effektivt. Det er præcis, hvad et indeks er til – for at minimere søgeomfanget på bekostning af ekstra plads.
Clustered Index:
Et clustered index er samlokaliseret med dataene i det samme tablespace eller samme diskfil. Du kan overveje, at et klynget indeks er et B-Tree indeks, hvis bladknuder er de faktiske datablokke på disken, da indekset og dataene ligger sammen. Denne type indeks organiserer fysisk dataene på disken i henhold til den logiske rækkefølge af indeksnøglen.
Hvad betyder fysisk dataorganisering?
Fysisk er data organiseret på disk på tværs af tusinder eller millioner af disk/datablokke. For et klynget indeks er det ikke obligatorisk, at alle diskblokkene er smitsomt lagret. Fysiske datablokke flyttes hele tiden rundt her og der af OS, når det er nødvendigt. Et databasesystem har ikke nogen absolut kontrol over, hvordan det fysiske datarum administreres, men inde i en datablok kan poster lagres eller administreres i den logiske rækkefølge af indeksnøglen. Følgende forenklede diagram forklarer det:
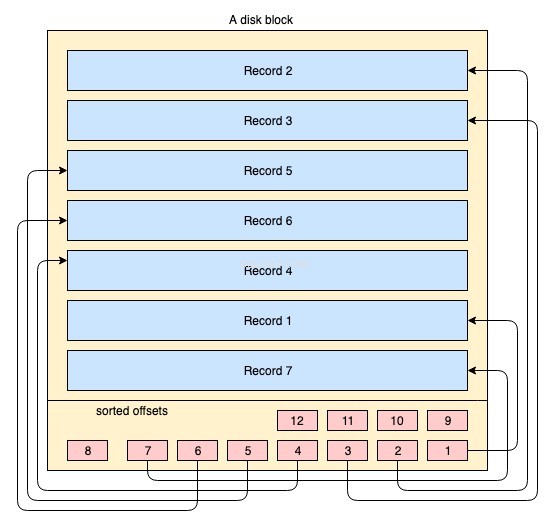
- Det gulfarvede store rektangel repræsenterer en diskblok/datablok
- de blåfarvede rektangler repræsenterer data gemt som rækker inde i den blok
- sidefodområdet repræsenterer indekset for den blok, hvor rødfarvede små rektangler findes i sorteret rækkefølge efter en bestemt nøgle. Disse små blokke er intet andet end en slags pointer, der peger på forskydninger af posterne.
Records gemmes på diskblokken i enhver vilkårlig rækkefølge. Når der tilføjes nye poster, tilføjes de på den næste ledige plads. Hver gang en eksisterende post opdateres, beslutter OS, om den pågældende post stadig kan passe ind i den samme position, eller en ny position skal allokeres til den post.
Så posternes position håndteres fuldstændigt af OS, og der eksisterer ingen bestemt relation mellem rækkefølgen af to poster. For at hente posterne i den logiske nøglerækkefølge indeholder disksider en indekssektion i sidefoden, indekset indeholder en liste over offset-pointere i nøglerækkefølgen. Hver gang en post ændres eller oprettes, justeres indekset.
På denne måde behøver du virkelig ikke at bekymre dig om rent faktisk at organisere den fysiske post i en bestemt rækkefølge, snarere vedligeholdes en lille indekssektion i den rækkefølge, og det bliver meget nemt at hente eller vedligeholde poster.
Fordel ved Clustered Index:
Denne bestilling eller samplacering af relaterede data gør faktisk et klynget indeks hurtigere. Når data hentes fra disken, læses den komplette blok, der indeholder dataene, af systemet, da vores disk IO-system skriver og læser data i blokke. Så i tilfælde af områdeforespørgsler er det meget muligt, at de sammenstillede data er bufret i hukommelsen. Lad os sige, at du udløser følgende forespørgsel:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
En datablok hentes i hukommelsen, når forespørgslen udføres. Lad os sige, at datablokken indeholder phone_no i området fra 9010000000 til 9030000000 . Så uanset hvilken rækkevidde du har anmodet om i forespørgslen, er blot en delmængde af dataene i blokken. Hvis du nu affyrer den næste forespørgsel for at få alle telefonnumre i området, siger fra 9015000000 til 9019000000 , behøver du ikke at hente flere blokke fra disken. De komplette data kan findes i den aktuelle blok af data, således clustered_index reducerer antallet af disk IO ved at samle relaterede data så meget som muligt i den samme datablok. Denne reducerede disk-IO forårsager forbedring af ydeevnen.
Så hvis du har en velovervejet primærnøgle, og dine forespørgsler er baseret på den primære nøgle, vil ydeevnen være superhurtig.
Begrænsninger for Clustered Index:
Da et klynget indeks påvirker den fysiske organisering af dataene, kan der kun være ét klynget indeks pr. tabel.
Relation mellem primærnøgle og grupperet indeks:
Du kan ikke oprette et klynget indeks manuelt ved hjælp af InnoDB i MySQL. MySQL vælger det for dig. Men hvordan vælger den? Følgende uddrag er fra MySQL-dokumentation:
Når du definerer enPRIMARY KEYpå dit bord,InnoDBbruger det som det klyngede indeks. Definer en primær nøgle for hver tabel, du opretter. Hvis der ikke er nogen logisk unik og ikke-nul kolonne eller et sæt af kolonner, skal du tilføje en ny auto-increment kolonne, hvis værdier udfyldes automatisk.
Hvis du ikke definerer enPRIMARY KEYfor dit bord, finder MySQL den førsteUNIQUEindeks, hvor alle nøglekolonner erNOT NULLogInnoDBbruger det som det klyngede indeks.
Hvis tabellen ikke har nogenPRIMARY KEYeller passendeUNIQUEindeks,InnoDBgenererer internt et skjult klynget indeks med navnetGEN_CLUST_INDEXpå en syntetisk kolonne, der indeholder række-id-værdier. Rækkerne er ordnet efter det ID, derInnoDBtildeler rækkerne i en sådan tabel. Række-id'et er et 6-byte felt, der øges monotont, efterhånden som nye rækker indsættes. Således er rækkerne ordnet efter række-id'et fysisk i indsættelsesrækkefølge.
Kort sagt, MySQL InnoDB-motoren administrerer faktisk det primære indeks som et klynget indeks for at forbedre ydeevnen, så den primære nøgle og den faktiske post på disken er klynget sammen.
Struktur af primær nøgle (clustered) Index:
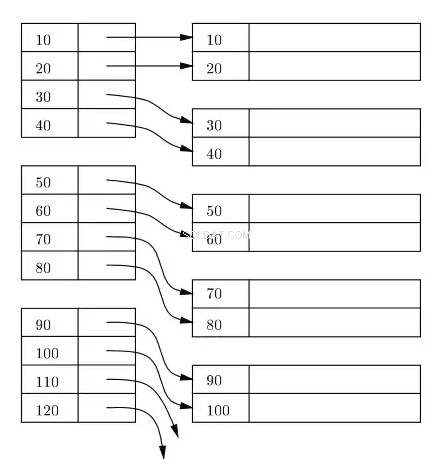
Et indeks vedligeholdes normalt som et B+-træ på disk og i hukommelsen, og ethvert indeks gemmes i blokke på disken. Disse blokke kaldes indeksblokke. Indtastningerne i indeksblokken er altid sorteret på indeks-/søge-tasten. Bladindeksblokken i indekset indeholder en rækkefinder. For det primære indeks refererer rækkelokalisatoren til den virtuelle adresse på den tilsvarende fysiske placering af datablokkene på disken, hvor rækkerne er sorteret efter indeksnøglen.
I det følgende diagram repræsenterer venstre side rektangler bladniveau indeksblokke, og højre side rektangler repræsenterer datablokke. Logisk ser datablokkene ud til at være justeret i en sorteret rækkefølge, men som allerede beskrevet tidligere, kan de faktiske fysiske placeringer være spredt her og der.
Er det muligt at oprette et primært indeks på en ikke-primær nøgle?
I MySQL oprettes automatisk et primært indeks, og vi har allerede beskrevet ovenfor, hvordan MySQL vælger det primære indeks. Men i databaseverdenen er det faktisk ikke nødvendigt at oprette et indeks på den primære nøglekolonne - det primære indeks kan også oprettes på enhver ikke-primær nøglekolonne. Men når de oprettes på den primære nøgle, er alle nøgleposter unikke i indekset, mens det primære indeks i det andet tilfælde også kan have en duplikeret nøgle.
Er det muligt at slette en primær nøgle?
Det er muligt at slette en primær nøgle. Når du sletter en primærnøgle, forsvinder det relaterede klyngeindeks såvel som egenskaben unikhed for den pågældende kolonne.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists" Fordele ved Primary Index:
- Primære indeksbaserede intervalforespørgsler er meget effektive. Der kan være en mulighed for, at den diskblok, som databasen har læst fra disken, indeholder alle de data, der hører til forespørgslen, da det primære indeks er klynget og poster er ordnet fysisk. Så lokaliteten af data kan angives af det primære indeks.
- Enhver forespørgsel, der udnytter den primære nøgle, er meget hurtig.
Ulempe ved primært indeks:
- Da det primære indeks indeholder en direkte reference til datablokadressen gennem det virtuelle adresserum, og diskblokke er fysisk organiseret i rækkefølgen efter indeksnøglen, hver gang operativsystemet foretager en disksideopdeling på grund af
DMLoperationer somINSERT/UPDATE/DELETE, skal det primære indeks også opdateres. SåDMLoperationer lægger et vist pres på det primære indekss ydeevne.
Sekundært indeks:
Ethvert andet indeks end et klynget indeks kaldes et sekundært indeks. Sekundære indekser påvirker ikke fysiske lagerplaceringer i modsætning til primære indekser.
Hvornår har du brug for et sekundært indeks?
Du kan have flere use cases i din applikation, hvor du ikke forespørger databasen med en primær nøgle. I vores eksempel phone_no er den primære nøgle, men vi skal muligvis forespørge databasen med pan_no eller name . I sådanne tilfælde har du brug for sekundære indekser på disse kolonner, hvis frekvensen af sådanne forespørgsler er meget høj.
Hvordan opretter man et sekundært indeks i MySQL?
Den følgende kommando opretter et sekundært indeks i name kolonne i index_demo tabel.
CREATE INDEX secondary_idx_1 ON index_demo (name); 
Struktur af sekundært indeks:
I diagrammet nedenfor repræsenterer de rødfarvede rektangler sekundære indeksblokke. Sekundært indeks vedligeholdes også i B+-træet, og det er sorteret efter den nøgle, hvorpå indekset blev oprettet. Bladknuderne indeholder en kopi af nøglen til de tilsvarende data i det primære indeks.
Så for at forstå, kan du antage, at det sekundære indeks har reference til den primære nøgles adresse, selvom det ikke er tilfældet. Hentning af data gennem det sekundære indeks betyder, at du skal krydse to B+ træer — det ene er selve det sekundære indeks B+ træ, og det andet er det primære indeks B+ træ.
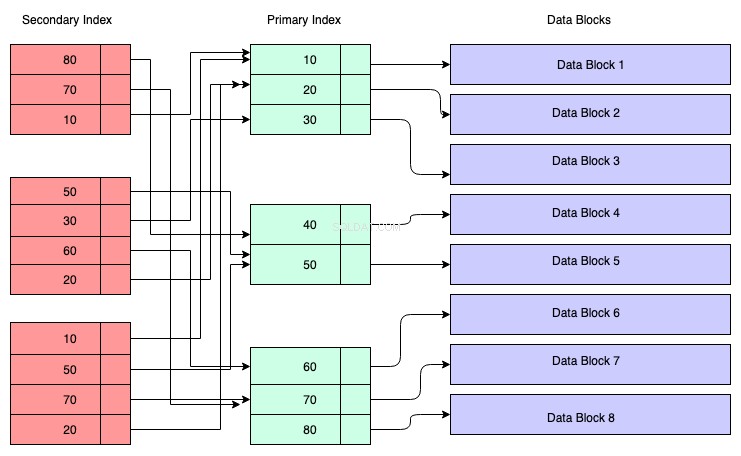
Fordele ved et sekundært indeks:
Logisk set kan du oprette så mange sekundære indekser, som du vil. Men i virkeligheden, hvor mange indekser der faktisk kræves, kræver en seriøs tankeproces, da hvert indeks har sin egen straf.
Ulempe ved et sekundært indeks:
Med DML handlinger som DELETE / INSERT , skal det sekundære indeks også opdateres, så kopien af den primære nøglekolonne kan slettes/indsættes. I sådanne tilfælde kan eksistensen af masser af sekundære indekser skabe problemer.
Også, hvis en primær nøgle er meget stor som en URL , da sekundære indekser indeholder en kopi af den primære nøglekolonneværdi, kan den være ineffektiv med hensyn til lagring. Flere sekundære nøgler betyder et større antal duplikerede kopier af den primære nøglekolonneværdi, så mere lagerplads i tilfælde af en stor primærnøgle. Også den primære nøgle gemmer selv nøglerne, så den kombinerede effekt på opbevaring vil være meget høj.
Overvejelse før du sletter et primært indeks:
I MySQL kan du slette et primært indeks ved at slippe den primære nøgle. Vi har allerede set, at et sekundært indeks afhænger af et primært indeks. Så hvis du sletter et primært indeks, skal alle sekundære indekser opdateres til at indeholde en kopi af den nye primære indeksnøgle, som MySQL automatisk justerer.
Denne proces er dyr, når der findes flere sekundære indekser. Også andre tabeller kan have en fremmednøglereference til den primære nøgle, så du skal slette disse fremmednøglereferencer, før du sletter den primære nøgle.
Når en primær nøgle slettes, opretter MySQL automatisk en anden primær nøgle internt, og det er en dyr operation.
UNIKT nøgleindeks:
Ligesom primærnøgler kan unikke nøgler også identificere poster unikt med én forskel – den unikke nøglekolonne kan indeholde null værdier.
I modsætning til andre databaseservere kan en unik nøglekolonne i MySQL have lige så mange null værdier som muligt. I SQL-standard, null betyder en udefineret værdi. Så hvis MySQL kun skal indeholde én null værdi i en unik nøglekolonne, skal den antage, at alle nulværdier er de samme.
Men logisk set er dette ikke korrekt, da null betyder udefineret - og udefinerede værdier kan ikke sammenlignes med hinanden, det er karakteren af null . Som MySQL ikke kan hævde, om alle null s betyder det samme, det tillader flere null værdier i kolonnen.
Den følgende kommando viser, hvordan man opretter et unikt nøgleindeks i MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no); 
Kompositindeks:
MySQL lader dig definere indekser på flere kolonner, op til 16 kolonner. Dette indeks kaldes et Multi-column / Composite / Compound indeks.
Lad os sige, at vi har et indeks defineret på 4 kolonner - col1 , col2 , col3 , col4 . Med et sammensat indeks har vi søgemuligheder på col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Så vi kan bruge et hvilket som helst venstre sidepræfiks i de indekserede kolonner, men vi kan ikke udelade en kolonne fra midten og bruge det som - (col1, col3) eller (col1, col2, col4) eller col3 eller col4 osv. Disse er ugyldige kombinationer.
Følgende kommandoer opretter 2 sammensatte indekser i vores tabel:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Hvis du har forespørgsler, der indeholder en WHERE klausul på flere kolonner, skriv klausulen i rækkefølgen af kolonnerne i det sammensatte indeks. Indekset vil gavne denne forespørgsel. Faktisk kan du, mens du bestemmer kolonnerne for et sammensat indeks, analysere forskellige anvendelsestilfælde af dit system og prøve at finde den rækkefølge af kolonner, der vil gavne de fleste af dine brugssager.
Sammensatte indekser kan hjælpe dig med JOIN &SELECT også forespørgsler. Eksempel:i følgende SELECT * forespørgsel, composite_index_2 bruges.

Når flere indekser er defineret, vælger MySQL-forespørgselsoptimeringsværktøjet det indeks, der eliminerer det største antal rækker eller scanner så få rækker som muligt for bedre effektivitet.
Hvorfor bruger vi sammensatte indekser ? Hvorfor ikke definere flere sekundære indekser på de kolonner, vi er interesserede i?
MySQL bruger kun ét indeks pr. tabel pr. forespørgsel undtagen UNION. (I en UNION køres hver logisk forespørgsel separat, og resultaterne flettes sammen.) Så at definere flere indekser på flere kolonner garanterer ikke, at disse indekser vil blive brugt, selvom de er en del af forespørgslen.
MySQL vedligeholder noget, der kaldes indeksstatistik, som hjælper MySQL med at udlede, hvordan dataene ser ud i systemet. Indeksstatistik er dog en generilisering, men baseret på disse metadata beslutter MySQL, hvilket indeks der er passende for den aktuelle forespørgsel.
Hvordan fungerer sammensat indeks?
De kolonner, der bruges i sammensatte indekser, er sammenkædet, og disse sammenkædede nøgler gemmes i sorteret rækkefølge ved hjælp af et B+-træ. Når du udfører en søgning, matches sammenkædning af dine søgenøgler med dem i det sammensatte indeks. Så hvis der er uoverensstemmelse mellem rækkefølgen af dine søgenøgler og rækkefølgen af de sammensatte indekskolonner, kan indekset ikke bruges.
I vores eksempel, for den følgende post, dannes en sammensat indeksnøgle ved at sammenkæde pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090 Sådan identificerer du, om du har brug for et sammensat indeks:
- Analyser dine forespørgsler først i henhold til dine brugssituationer. Hvis du ser, at visse felter vises sammen i mange forespørgsler, kan du overveje at oprette et sammensat indeks.
- Hvis du opretter et indeks i
col1&et sammensat indeks i (col1,col2), så skulle kun det sammensatte indeks være fint.col1alene kan betjenes af selve det sammensatte indeks, da det er et præfiks på venstre side af indekset. - Overvej kardinalitet. Hvis kolonner, der bruges i det sammensatte indeks, ender med at have høj kardinalitet tilsammen, er de gode kandidater til det sammensatte indeks.
Dækningsindeks:
Et dækkende indeks er en speciel form for sammensat indeks, hvor alle de kolonner, der er angivet i forespørgslen et eller andet sted, findes i indekset. Så forespørgselsoptimeringsværktøjet behøver ikke at ramme databasen for at få dataene - snarere får den resultatet fra selve indekset. Eksempel:vi har allerede defineret et sammensat indeks på (pan_no, name, age) , så overvej nu følgende forespørgsel:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Kolonnerne nævnt i SELECT &WHERE klausuler er en del af det sammensatte indeks. Så i dette tilfælde kan vi faktisk få værdien af age kolonne fra selve det sammensatte indeks. Lad os se, hvad EXPLAIN er kommandoen viser for denne forespørgsel:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1'; 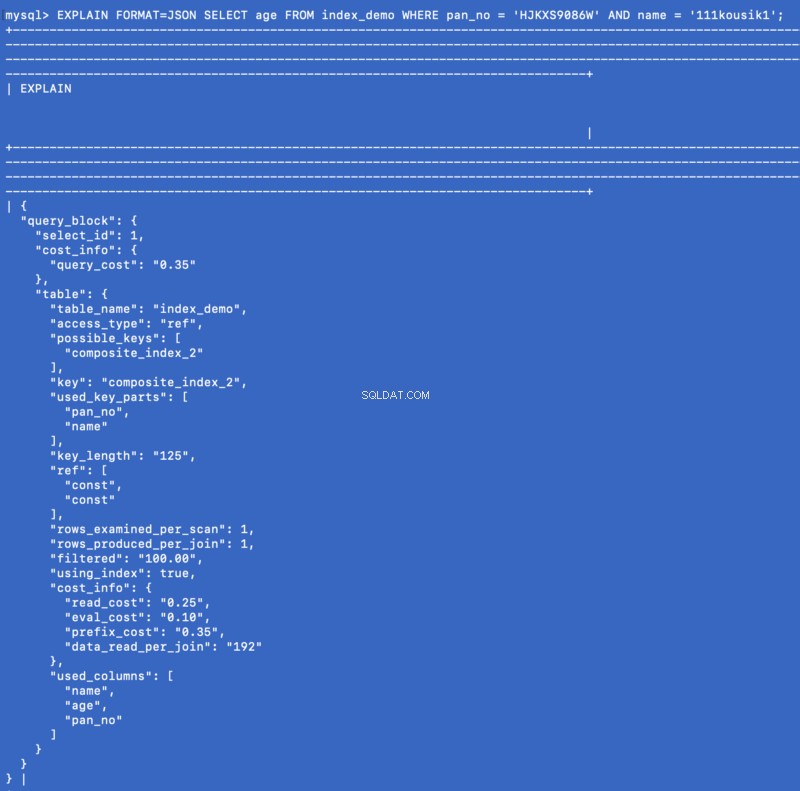
Bemærk i ovenstående svar, at der er en nøgle - using_index som er sat til true hvilket betyder, at det dækkende indeks er blevet brugt til at besvare forespørgslen.
Jeg ved ikke, hvor meget dækkende indekser værdsættes i produktionsmiljøer, men det ser tilsyneladende ud til at være en god optimering, hvis forespørgslen passer til regningen.
Delvis indeks:
Vi ved allerede, at indekser fremskynder vores forespørgsler på bekostning af plads. Jo flere indekser du har, jo større lagerbehov. Vi har allerede oprettet et indeks kaldet secondary_idx_1 i kolonnen name . Kolonnen name kan indeholde store værdier af enhver længde. Også i indekset har rækkelokalisatorernes eller rækkepegernes metadata deres egen størrelse. Så samlet set kan et indeks have en høj lager- og hukommelsesbelastning.
I MySQL er det også muligt at oprette et indeks på de første par bytes data. Eksempel:følgende kommando opretter et indeks på de første 4 bytes af navn. Selvom denne metode reducerer hukommelsesomkostninger med en vis mængde, kan indekset ikke fjerne mange rækker, da de første 4 bytes i dette eksempel kan være fælles på tværs af mange navne. Normalt understøttes denne form for præfiksindeksering på CHAR ,VARCHAR , BINARY , VARBINARY type kolonner.
CREATE INDEX secondary_index_1 ON index_demo (name(4)); Hvad sker der under hætten, når vi definerer et indeks?
Lad os køre SHOW EXTENDED kommando igen:
SHOW EXTENDED INDEX FROM index_demo; 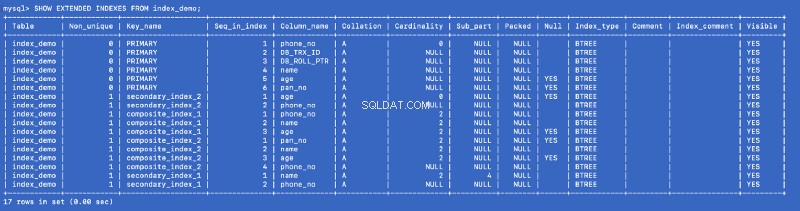
Vi definerede secondary_index_1 på name , men MySQL har oprettet et sammensat indeks på (name , phone_no ) hvor phone_no er den primære nøglekolonne. Vi oprettede secondary_index_2 på age &MySQL oprettede et sammensat indeks på (age , phone_no ). Vi oprettede composite_index_2 på (pan_no , name , age ) &MySQL har oprettet et sammensat indeks på (pan_no , name , age , phone_no ). Det sammensatte indeks composite_index_1 har allerede phone_no som en del af det.
Så uanset hvilket indeks vi opretter, skaber MySQL i baggrunden et sammensat backing-indeks, som igen peger på den primære nøgle. Det betyder, at den primære nøgle er en førsteklasses borger i MySQL-indekseringsverdenen. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html