I mit tidligere indlæg om inkrementel statistik, en ny funktion i SQL Server 2014, demonstrerede jeg, hvordan de kan hjælpe med at reducere vedligeholdelsesopgavens varighed. Dette skyldes, at statistik kan opdateres på partitionsniveau, og ændringerne slås sammen i tabellens hovedhistogram. Jeg bemærkede også, at Query Optimizer ikke bruger disse partitionsniveaustatistikker, når de genererer forespørgselsplaner, hvilket kan være noget, som folk havde forventet. Der eksisterer ingen dokumentation for, at inkrementelle statistikker vil eller ikke vil blive brugt af Query Optimizer. Så hvordan ved du det? Du skal teste det. :-)
Opsætningen
Opsætningen for denne test vil ligne den i sidste indlæg, men med færre data. Bemærk, at standardstørrelserne er mindre for datafilerne, og scriptet indlæses kun i nogle få millioner rækker af data:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Når vi opretter det klyngede indeks for dbo.Orders, opretter vi det uden STATISTICS_INCREMENTAL mulighed aktiveret, så vi starter med en traditionel opdelt tabel uden inkrementelle statistikker:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Dernæst indlæser vi omkring 4 millioner rækker, hvilket tager lige under et minut på min maskine:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Efter dataindlæsningen opdaterer vi statistik med en FULLSCAN (så vi kan oprette et konsistent-som-muligt histogram til tests) og derefter verificere, hvilke data vi har i hver partition:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Data i hver partition efter dataindlæsning
Data i hver partition efter dataindlæsning
De fleste af dataene er i 2015-partitionen, men der er også data for 2012, 2013 og 2014. Og hvis vi tjekker outputtet fra den udokumenterede DMV sys.dm_db_stats_properties_internal , kan vi se, at der ikke findes nogen partitionsniveaustatistikker:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal output, der kun viser én statistik for dbo.Orders
sys.dm_db_stats_properties_internal output, der kun viser én statistik for dbo.Orders
Testen
Testning kræver en simpel forespørgsel, som vi kan bruge til at verificere, at partitioneliminering forekommer, og også kontrollere estimater baseret på statistik. Forespørgslen returnerer ingen data, men det er ligegyldigt, vi er interesserede i, hvad optimizeren tænkte det ville vende tilbage, baseret på statistik:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
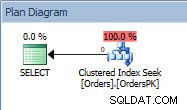 Forespørgselsplan for SELECT-sætningen
Forespørgselsplan for SELECT-sætningen
Planen har en Clustered Index Seek, og hvis vi tjekker egenskaberne, ser vi, at den anslåede 4000 rækker og fik adgang til partition 5, som indeholder 2014-data.
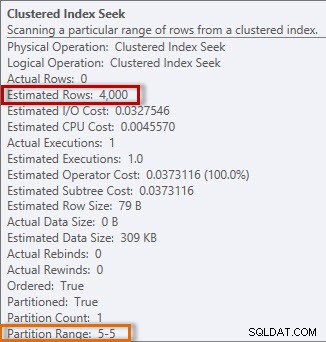 Estimeret og faktisk information fra Clustered Index Seek
Estimeret og faktisk information fra Clustered Index Seek
Hvis vi ser på histogrammet for dbo.Orders-tabellen, specifikt i området for april 2014-data, ser vi, at der ikke er noget trin for 2014-04-01, så optimeringsværktøjet estimerer antallet af rækker for den dato ved hjælp af trinnet for 2014-04-24, hvor AVG_RANGE_ROWS er 4000 (for enhver værdi mellem 2014-02-14 og 2014-04-23 inklusive, vil optimeringsværktøjet anslå, at 4000 rækker vil blive returneret).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
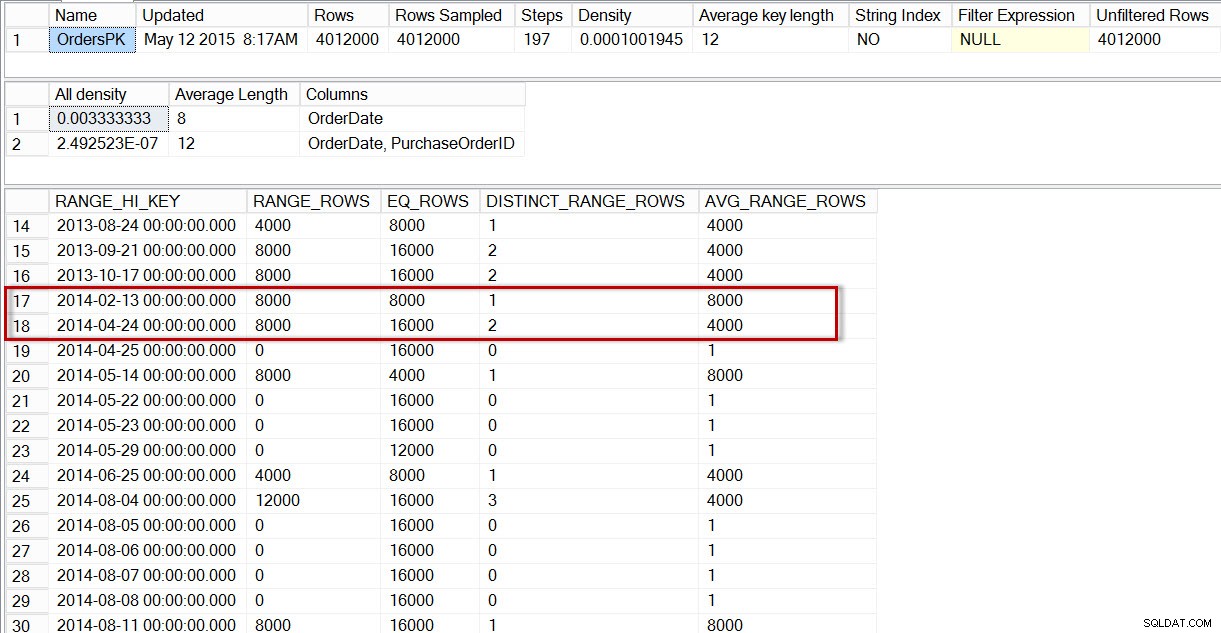 Distribution i dbo.Orders-histogrammet
Distribution i dbo.Orders-histogrammet
Estimatet og planen forventes fuldstændigt. Lad os aktivere inkrementelle statistikker og se, hvad vi får.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Hvis vi kører vores forespørgsel igen mod sys.dm_db_stats_properties_internal , kan vi se den trinvise statistik:
 sys.dm_db_stats_properties_internal viser inkrementelle statistikoplysninger
sys.dm_db_stats_properties_internal viser inkrementelle statistikoplysninger
Lad os nu køre vores forespørgsel igen dbo.Orders, og vi kører DBCC FREEPROCCACHE først for fuldt ud at sikre, at planen ikke genbruges:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Vi får den samme plan og det samme skøn:
Forespørgselsplan for SELECT-sætningen
Estimeret og faktisk information fra Clustered Index Seek
Hvis vi tjekker hovedhistogrammet for dbo.Orders, ser vi næsten det samme histogram som før:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
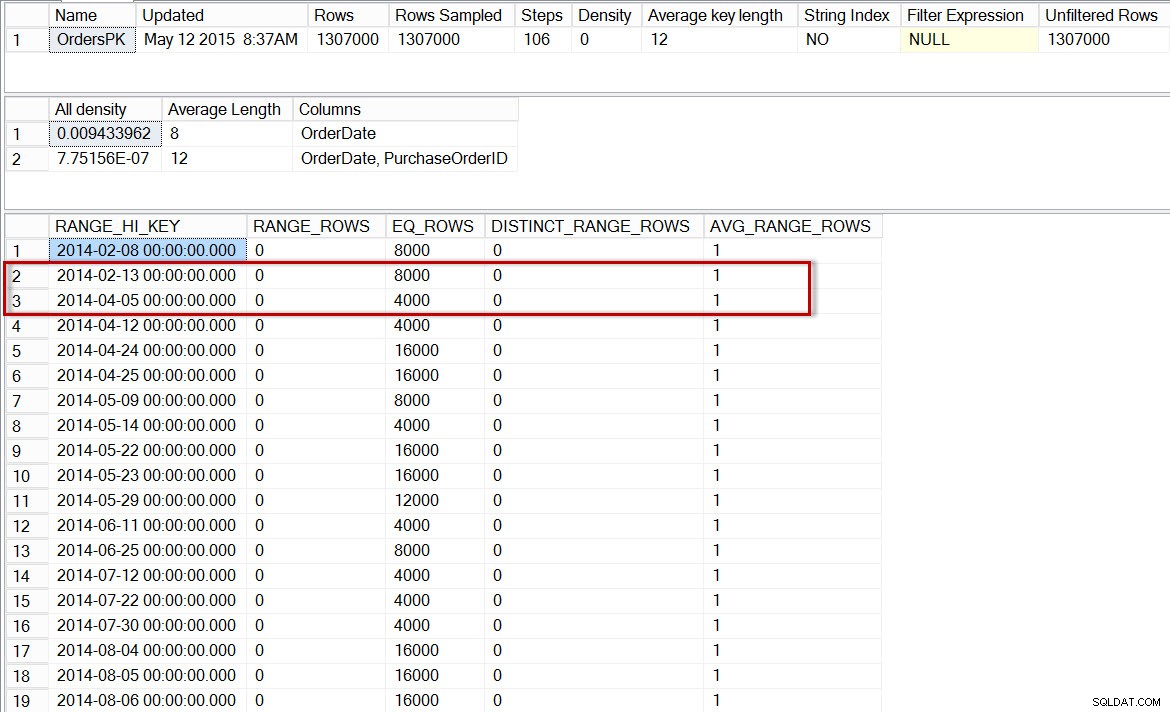 Histogram for dbo.Orders, efter aktivering af inkrementelle statistikker
Histogram for dbo.Orders, efter aktivering af inkrementelle statistikker
Lad os nu tjekke histogrammet for partitionen med 2014-data (vi kan gøre dette ved at bruge udokumenteret sporingsflag 2309, som gør det muligt at angive et partitionsnummer som et ekstra argument til DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogram for 2014-partitionen af dbo.Orders, efter aktivering af inkrementelle statistikker
Her ser vi, at der igen ikke er noget trin for 2014-04-01, men der er 0 RANGE_ROWS mellem 2014-02-13 og 2014-04-05 med en AVG_RANGE_ROWS af 1. Hvis optimeringsværktøjet brugte histogrammet til statistikken på partitionsniveauet, ville estimatet for antallet af rækker for 2014-04-01 være 1.
Bemærk:Partitionen identificeret som brugt i forespørgselsplanen er 5, men du vil bemærke, at DBCC SHOW_STATISTICS erklæringsreferencer partition 6. Antagelsen er en inkonsistens i statistik-metadata (en almindelig off-by-one-fejl, sandsynligvis på grund af 0-baseret vs. 1-baseret optælling), som måske eller måske ikke bliver rettet i fremtiden. Forstå, at sporingsflaget ikke er dokumenteret på nuværende tidspunkt, og at det ikke anbefales at bruge i et produktionsmiljø.
Oversigt
Tilføjelsen af trinvis statistik i SQL Server 2014-udgivelsen er et skridt i den rigtige retning for forbedrede kardinalitetsestimater for partitionerede tabeller. Men som vi har påvist, er den aktuelle værdi af inkrementelle statistikker begrænset til reducerede vedligeholdelsesvarigheder, da disse trinvise statistikker endnu ikke bruges af Query Optimizer.