Jeg har for nylig modtaget et e-mail-spørgsmål fra en person i fællesskabet om CLR_MANUAL_EVENT ventetype; specifikt, hvordan man fejlfinder problemer med denne ventetid, der pludselig bliver udbredt for en eksisterende arbejdsbyrde, der var stærkt afhængig af geografiske datatyper og forespørgsler ved hjælp af de rumlige metoder i SQL Server.
Som konsulent er mit første spørgsmål næsten altid:"Hvad er ændret?" Men i dette tilfælde, som i så mange tilfælde, var jeg sikker på, at intet var ændret med applikationens kode eller arbejdsbelastningsmønstre. Så mit første stop var at trække op CLR_MANUAL_EVENT vent i SQLskills.com Wait Types Library for at se, hvilke andre oplysninger vi allerede havde indsamlet om denne ventetype, da det normalt ikke er en ventetid, som jeg ser problemer med i SQL Server. Det, jeg fandt virkelig interessant, var diagrammet/varmekortet over hændelser for denne ventetype leveret af SentryOne øverst på siden:
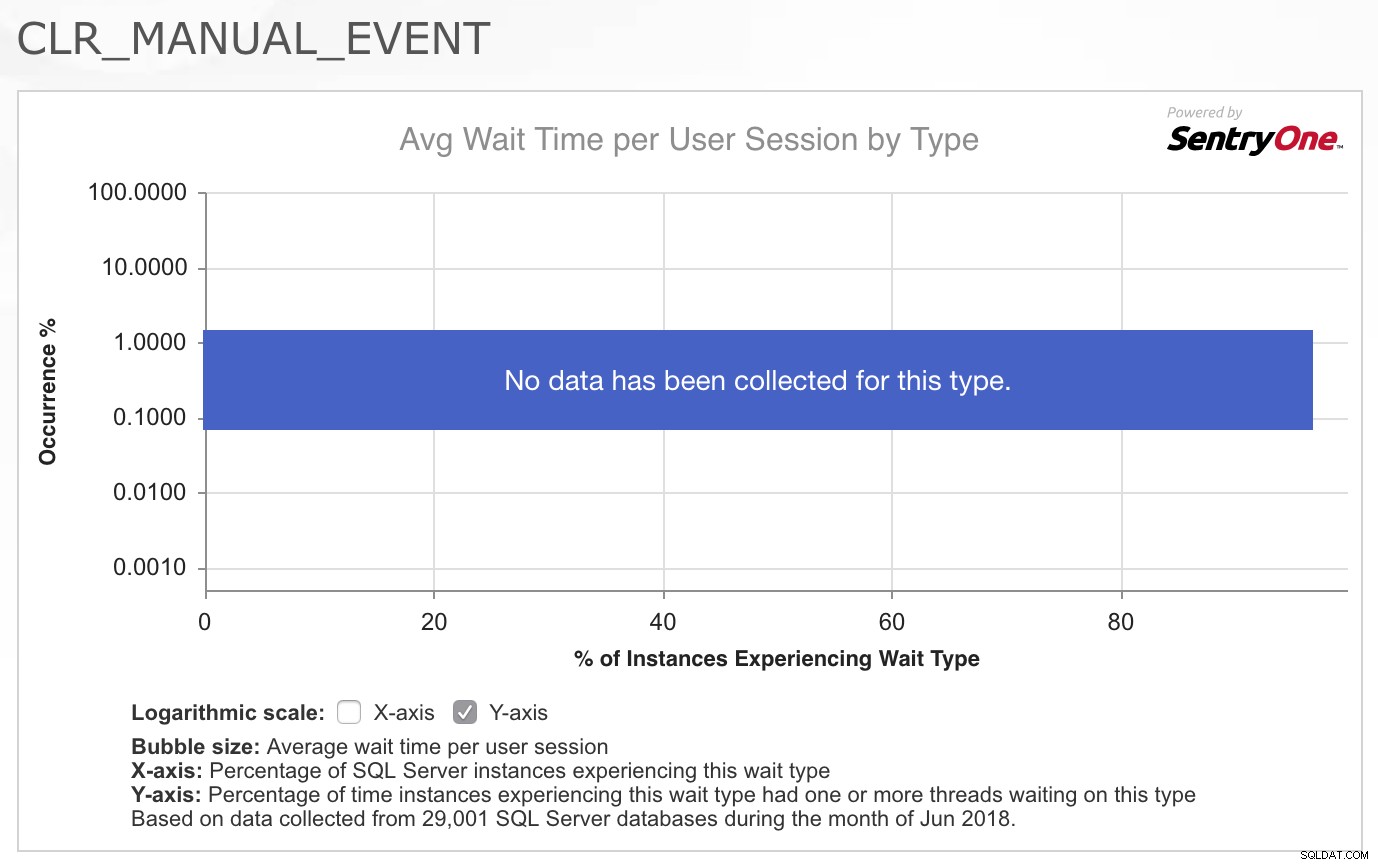
Det faktum, at der ikke er blevet indsamlet data for denne type gennem et godt tværsnit af deres kunder, bekræftede virkelig for mig, at dette ikke er noget, der normalt er et problem, så jeg var fascineret af det faktum, at denne specifikke arbejdsbyrde nu udviste problemer med denne ventetid. Jeg var ikke sikker på, hvor jeg skulle gå hen for at undersøge problemet nærmere, så jeg svarede på e-mailen og sagde, at jeg var ked af, at jeg ikke kunne hjælpe yderligere, fordi jeg ikke havde nogen idé om, hvad der ville forårsage bogstaveligt talt snesevis af tråde, der udfører rumlige forespørgsler til begynder pludselig at skulle vente i 2-4 sekunder ad gangen på denne ventetype.
En dag senere modtog jeg en venlig opfølgende e-mail fra den person, der stillede spørgsmålet, som informerede mig om, at de havde løst problemet. Faktisk havde intet i den faktiske applikationsarbejdsmængde ændret sig, men der skete en ændring i miljøet. En tredjeparts softwarepakke blev installeret på alle serverne i deres infrastruktur af deres sikkerhedsteam, og denne software indsamlede data med fem minutters intervaller og fik .NET-affaldsindsamlingsbehandlingen til at køre utroligt aggressivt og "gå amok" som de sagde. Bevæbnet med disse oplysninger og noget af min tidligere viden om .NET-udvikling besluttede jeg, at jeg ville lege lidt med dette og se, om jeg kunne genskabe adfærden, og hvordan vi kunne gå videre med fejlfinding af årsagerne.
Baggrundsoplysninger
I årenes løb har jeg altid fulgt PSSQL-bloggen på MSDN, og det er normalt et af mine steder, når jeg husker, at jeg har læst om et problem relateret til SQL Server på et tidspunkt tidligere, men jeg kan' ikke huske alle detaljerne.
Der er et blogindlæg med titlen Høj ventetid på CLR_MANUAL_EVENT og CLR_AUTO_EVENT af Jack Li fra 2008, der forklarer, hvorfor disse ventetider sikkert kan ignoreres i den samlede sys.dm_os_wait_stats DMV, da ventetiden forekommer under normale forhold, men den omhandler ikke, hvad man skal gøre, hvis ventetiderne er for lange, eller hvad der kan forårsage, at de bliver set på tværs af flere tråde i sys.dm_os_waiting_tasks aktivt.
Der er et andet blogindlæg af Jack Li fra 2013 med titlen Et ydeevneproblem, der involverer CLR-affaldsindsamling og indstilling af SQL CPU-tilhørsforhold som jeg refererer til i vores IEPTO2 performance tuning-klasse, når jeg taler om overvejelser om flere instanser, og hvordan .NET Garbage Collector (GC), der udløses af én instans, kan påvirke de andre instanser på den samme server.
GC'en i .NET eksisterer for at reducere hukommelsesforbruget af applikationer, der bruger CLR ved at tillade, at hukommelsen allokeret til objekter bliver ryddet op automatisk, hvilket eliminerer behovet for, at udviklere manuelt skal håndtere hukommelsesallokering og -deallokering i den grad, der kræves af uadministreret kode . GC-funktionaliteten er dokumenteret i Books Online, hvis du gerne vil vide mere om, hvordan det fungerer, men de specifikke detaljer ud over det faktum, at samlinger kan blokere, er ikke vigtige for fejlfinding af aktive ventetider på CLR_MANUAL_EVENT i SQL Server yderligere.
Kom til roden af problemet
Med viden om, at skraldindsamling fra .NET var det, der forårsagede problemet, besluttede jeg at eksperimentere med en enkelt rumlig forespørgsel mod AdventureWorks2016 og et meget simpelt PowerShell-script til at kalde skraldeopsamleren manuelt i en løkke for at spore, hvad der sker i sys.dm_os_waiting_tasks inde i SQL Server for forespørgslen:
USE AdventureWorks2016; GO SELECT a.SpatialLocation.ToString(), a.City, b.SpatialLocation.ToString(), b.City FROM Person.Address AS a INNER JOIN Person.Address AS b ON a.SpatialLocation.STDistance(b.SpatialLocation) <= 100 ORDER BY a.SpatialLocation.STDistance(b.SpatialLocation);
Denne forespørgsel sammenligner alle adresserne i Person.Address tabel mod hinanden for at finde enhver adresse, der er inden for 100 meter fra enhver anden adresse i tabellen. Dette skaber en langvarig parallel opgave inde i SQL Server, der også producerer et stort kartesisk resultat. Hvis du beslutter dig for at reproducere denne adfærd på egen hånd, skal du ikke forvente, at dette fuldfører eller returnerer resultaterne. Når forespørgslen kører, begynder den overordnede tråd for opgaven at vente på CXPACKET venter, og forespørgslen fortsætter med at behandle i flere minutter. Men det, jeg var interesseret i, var, hvad der sker, når affaldsindsamling sker i CLR-runtimen, eller hvis GC'en påkaldes, så jeg brugte et simpelt PowerShell-script, der ville sløjfe og manuelt tvinge GC'en til at køre.
BEMÆRK:DETTE ER IKKE EN ANBEFALET PRAKSIS I PRODUKTIONSKODE AF MANGE GRUNDE!
while (1 -eq 1) {[System.GC]::Collect() } Da PowerShell-vinduet kørte, begyndte jeg næsten med det samme at se CLR_MANUAL_EVENT venter, der forekommer på de parallelle underopgavetråde (vist nedenfor, hvor exec_context_id er større end nul) i sys.dm_os_waiting_tasks :
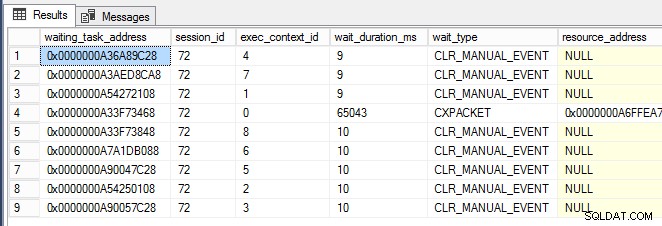
Nu hvor jeg kunne udløse denne adfærd, og det begyndte at blive klart, at SQL Server ikke nødvendigvis er problemet her og måske bare er offer for anden aktivitet, ville jeg vide, hvordan man graver dybere og lokaliserer årsagen til problemet . Det er her, PerfMon var praktisk til at spore .NET CLR-hukommelsestællergruppen for alle opgaver på serveren.
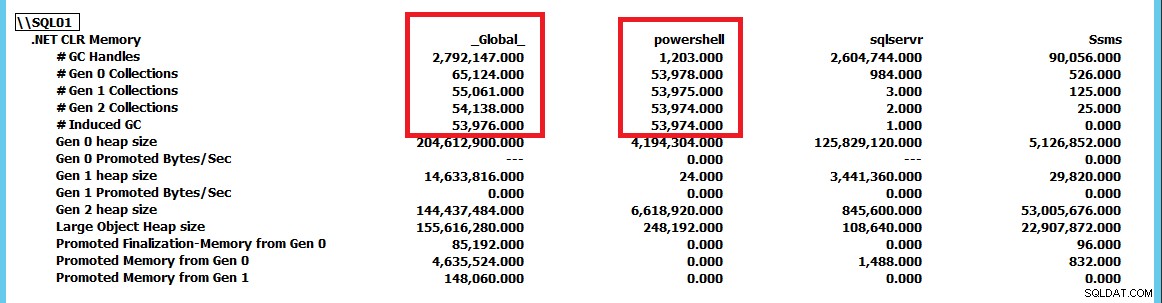
Dette skærmbillede er blevet reduceret for at vise samlingerne for sqlservr og powershell som applikationer sammenlignet med _Global_ samlinger af .NET runtime. Ved at tvinge GC.Collect() at køre konstant, kan vi se, at powershell instans driver GC-samlingerne på serveren. Ved at bruge denne PerfMon-tællergruppe kan vi spore, hvilke applikationer der udfører flest indsamlinger og derfra fortsætte yderligere undersøgelse af problemet. I dette tilfælde elimineres CLR_MANUAL_EVENT blot ved at stoppe PowerShell-scriptet venter inde i SQL Server, og forespørgslen fortsætter med at behandle, indtil vi enten stopper den eller tillader den at returnere de milliarder rækker af resultater, som den ville blive udsendt.
Konklusion
Hvis du har aktive ventetider på CLR_MANUAL_EVENT forårsager langsommere programmer, skal du ikke automatisk antage, at problemet eksisterer inde i SQL Server. SQL Server bruger affaldsindsamling på serverniveau (i det mindste før SQL Server 2017 CU4, hvor små servere med under 2 GB RAM kan bruge affaldsindsamling på klientniveau for at reducere ressourceforbrug). Hvis du ser dette problem opstå i SQL Server, skal du bruge .NET CLR-hukommelsestællergruppen i PerfMon og kontrollere, om en anden applikation driver skraldopsamling i CLR og blokerer CLR-opgaverne internt i SQL Server som følge heraf.