Meget produktions-T-SQL-kode er skrevet med den implicitte antagelse, at de underliggende data ikke vil ændre sig under udførelsen. Som vi så i den forrige artikel i denne serie, er dette en usikker antagelse, fordi data og indeksposter kan bevæge sig rundt under os, selv under udførelsen af en enkelt erklæring.
Hvor T-SQL-programmøren er opmærksom på den slags korrektheds- og dataintegritetsproblemer, der kan opstå på grund af samtidige dataændringer af andre processer, er den løsning, der oftest tilbydes, at indpakke de sårbare udsagn i en transaktion. Det er ikke klart, hvordan den samme slags ræsonnement ville blive anvendt på enkeltudsagnssagen, som allerede er pakket ind i en automatisk forpligtelsestransaktion som standard.
Hvis man ser bort fra det et øjeblik, synes ideen om at beskytte et vigtigt område af T-SQL-kode med en transaktion at være baseret på en misforståelse af den beskyttelse, der tilbydes af ACID-transaktionsegenskaberne. Det vigtige element i dette akronym for denne diskussion er Isolationen ejendom. Tanken er, at brug af en transaktion automatisk giver fuldstændig isolation fra virkningerne af andre samtidige aktiviteter.
Sandheden i sagen er, at transaktioner under SERIALIZABLE kun give en grad af isolation, som afhænger af det aktuelt effektive transaktionsisolationsniveau. For at forstå, hvad alt dette betyder for vores daglige T SQL-kodningspraksis, vil vi først tage et detaljeret kig på det serialiserbare isolationsniveau.
Serialiserbar isolering
Serialiserbar er det mest isolerede af standardtransaktionsisolationsniveauerne. Det er også standard isolationsniveau specificeret af SQL-standarden, selvom SQL Server (som de fleste kommercielle databasesystemer) adskiller sig fra standarden i denne henseende. Standard isolationsniveauet i SQL Server er læseforpligtet, et lavere isolationsniveau, som vi vil udforske senere i serien.
Definitionen af det serialiserbare isolationsniveau i SQL-92-standarden indeholder følgende tekst (min fremhævelse):
En serialiserbar udførelse er defineret som en udførelse af operationerne ved samtidig udførelse af SQL-transaktioner, der producerer den samme effekt som en seriel udførelse af de samme SQL-transaktioner. En seriel eksekvering er en, hvor hver SQL-transaktion udføres til fuldførelse, før den næste SQL-transaktion begynder.
Der er en vigtig skelnen her mellem virkelig serialiseret eksekvering (hvor hver transaktion faktisk udelukkende kører til fuldførelse, før den næste starter) og serialiserbar isolation, hvor transaktioner kun skal have de samme virkninger som om de blev udført serielt (i en eller anden uspecificeret rækkefølge).
For at sige det på en anden måde, har et rigtigt databasesystem lov til fysisk at overlappe udførelse af serialiserbare transaktioner i tide (derved øger samtidighed), så længe virkningerne af disse transaktioner stadig svarer til en mulig rækkefølge for seriel udførelse. Med andre ord er serialiserbare transaktioner potentielt serialiserbare snarere end at blive faktisk serialiseret .
Logisk serialiserbare transaktioner
Forlad alle fysiske overvejelser (som låsning) et øjeblik, og tænk kun på den logiske behandling af to samtidige serialiserbare transaktioner.
Overvej en tabel, der indeholder et stort antal rækker, hvoraf fem tilfældigvis opfylder et interessant forespørgselsprædikat. En serialiserbar transaktion T1 begynder at tælle antallet af rækker i tabellen, der matcher dette prædikat. Nogen tid efter T1 begynder, men før den forpligter sig, en anden serialiserbar transaktion T2 starter. Transaktion T2 tilføjer fire nye rækker, der også opfylder forespørgselsprædikatet til tabellen, og forpligter. Diagrammet nedenfor viser tidssekvensen af hændelser:

Spørgsmålet er, hvor mange rækker skal forespørgslen i serialiserbar transaktion T1 tælle? Husk, at vi udelukkende tænker på de logiske krav her, så undgå at tænke på, hvilke låse der kan tages og så videre.
De to transaktioner overlapper hinanden fysisk i tid, hvilket er fint. Serialiserbar isolation kræver kun, at resultaterne af disse to transaktioner svarer til en mulig seriel eksekvering. Der er helt klart to muligheder for en logisk seriel plan for transaktioner T1 og T2 :
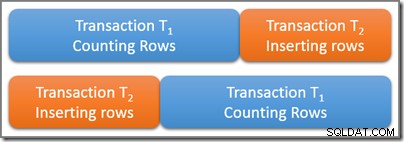
Brug af den første mulige serielle tidsplan (T1 derefter T2 ) T1 tælleforespørgsel ville se fem rækker , fordi den anden transaktion ikke starter, før den første er fuldført. Ved at bruge det andet mulige logiske skema, T1 forespørgslen ville tælle ni rækker , fordi indsættelsen med fire rækker blev logisk afsluttet, før tælletransaktionen begyndte.
Begge svar er logisk korrekte under serialiserbar isolation. Derudover er intet andet svar muligt (så transaktion T1 kunne for eksempel ikke tælle syv rækker). Hvilket af de to mulige resultater, der rent faktisk observeres, afhænger af præcis timing og en række implementeringsdetaljer, der er specifikke for den anvendte databasemotor.
Bemærk, at vi ikke konkluderer, at transaktionerne faktisk på en eller anden måde er omordnet i tide. Den fysiske udførelse er fri til at overlappe som vist i det første diagram, så længe databasemotoren sikrer, at resultaterne afspejler, hvad der ville være sket, hvis de var eksekveret i en af de to mulige serielle sekvenser.
Serialiserbar og samtidighedsfænomenerne
Ud over logisk serialisering nævner SQL-standarden også, at en transaktion, der opererer på det serialiserbare isolationsniveau, ikke må opleve visse samtidighedsfænomener. Den må ikke læse uforpligtende data (ingen dirty reads). ); og når først data er blevet læst, skal en gentagelse af den samme operation returnere nøjagtigt det samme sæt data (gentagelige læsninger uden fantomer ).
Standarden gør en pointe med at sige, at disse samtidighedsfænomener er udelukket på det serialiserbare isolationsniveau som en direkte konsekvens at kræve, at transaktionen skal være logisk serialiserbar. Med andre ord er serialiseringskravet tilstrækkeligt i sig selv for at undgå snavset læsning, ikke-gentagelig læsning og phantom concurrency fænomener. Derimod er det ikke tilstrækkeligt at undgå de tre samtidighedsfænomener alene for at garantere serialisering, som vi snart vil se.
Intuitivt undgår serialiserbare transaktioner alle samtidighedsrelaterede fænomener, fordi de er forpligtet til at opføre sig, som om de var udført i fuldstændig isolation. I den forstand matcher det serialiserbare transaktionsisoleringsniveau de almindelige forventninger hos T-SQL-programmører ganske nøje.
Serialiserbare implementeringer
SQL Server bruger tilfældigvis en låseimplementering af det serialiserbare isolationsniveau, hvor fysiske låse erhverves og holdes til slutningen af transaktionen (deraf det forældede tabeltip HOLDLOCK som et synonym for SERIALIZABLE ).
Denne strategi er ikke helt nok til at give en teknisk garanti for fuld serialiserbarhed, fordi nye eller ændrede data kan dukke op i en række rækker, der tidligere er blevet behandlet af transaktionen. Dette samtidighedsfænomen er kendt som et fantom og kan resultere i effekter, som ikke kunne være opstået i nogen seriel tidsplan.
For at sikre beskyttelse mod fænomenet phantom concurrency kan låse, der er taget af SQL Server på det serialiserbare isolationsniveau, også inkorporere nøgleområdelåsning for at forhindre nye eller ændrede rækker i at blive vist mellem tidligere undersøgte indeksnøgleværdier. Rækkeviddelåse er ikke altid erhvervet under det serialiserbare isolationsniveau; alt, hvad vi generelt kan sige, er, at SQL Server altid anskaffer tilstrækkelige låse til at opfylde de logiske krav til det serialiserbare isolationsniveau. Faktisk opnår låseimplementeringer ret ofte flere og strengere låse, end der reelt er brug for for at garantere serialisering, men jeg afviger.
Låsning er blot en af de mulige fysiske implementeringer af det serialiserbare isolationsniveau. Vi bør være omhyggelige med mentalt at adskille den specifikke adfærd i SQL Server-låseimplementeringen fra den logiske definition af serialiserbar.
Som et eksempel på en alternativ fysisk strategi, se PostgreSQL-implementeringen af serialiserbar snapshot-isolering, selvom dette kun er et alternativ. Hver anden fysisk implementering har selvfølgelig sine egne styrker og svagheder. Som en sidebemærkning skal du bemærke, at Oracle stadig ikke leverer en fuldt kompatibel implementering af det serialiserbare isolationsniveau. Det har et isolationsniveau navngivet kan serialiseres, men det garanterer ikke rigtigt, at transaktioner udføres i henhold til en mulig seriel tidsplan. Oracle giver i stedet snapshot-isolering når der anmodes om serialiserbar, på omtrent samme måde som PostgreSQL gjorde før serialiserbar snapshot-isolering (SSI ) blev implementeret.
Snapshot-isolering forhindrer ikke samtidige anomalier som skriveskævhed, hvilket ikke er muligt under virkelig serialiserbar isolation. Hvis du er interesseret, kan du finde eksempler på skriveskævhed og andre samtidighedseffekter tilladt af snapshot-isolering på SSI-linket ovenfor. Vi vil også diskutere SQL Server-implementeringen af snapshot-isolationsniveau senere i serien.
Et punkt-i-tidsvisning?
En af grundene til, at jeg har brugt tid på at tale om forskellene mellem logisk serialiserbarhed og fysisk serialiseret eksekvering, er, at det ellers er nemt at udlede garantier, som måske ikke eksisterer. For eksempel, hvis du tænker på serialiserbare transaktioner som faktisk ved at udføre den ene efter den anden, kan du udlede, at en serialiserbar transaktion nødvendigvis vil se databasen, som den eksisterede ved starten af transaktionen, hvilket giver et punkt-i-tidsvisning.
Faktisk er dette en implementeringsspecifik detalje. Husk det foregående eksempel, hvor serialiserbar transaktion T1 kan lovligt tælle fem eller ni rækker. Hvis et tæller på ni returneres, vil den første transaktion tydeligt se rækker, der ikke eksisterede i det øjeblik, transaktionen startede. Dette resultat er muligt i SQL Server, men ikke i PostgreSQL SSI, selvom begge implementeringer overholder den logiske adfærd, der er specificeret for det serialiserbare isolationsniveau.
I SQL Server ser serialiserbare transaktioner ikke nødvendigvis dataene, som de eksisterede ved starten af transaktionen. Detaljerne i SQL Server-implementeringen betyder snarere, at en serialiserbar transaktion ser de seneste forpligtede data fra det øjeblik, dataene først blev låst for adgang. Derudover garanteres det, at sættet af senest læste data i sidste ende ikke ændrer sit medlemskab, før transaktionen slutter.
Næste gang
Den næste del i denne serie undersøger det gentagelige læseisoleringsniveau, som giver svagere transaktionsisoleringsgarantier end det, der kan serialiseres.
[ Se indekset for hele serien ]