I denne artikel vil vi fokusere på operationelle analyser i realtid og hvordan man anvender denne tilgang til en OLTP-database. Når vi ser på den traditionelle analytiske model, kan vi se OLTP og analytiske miljøer er separate strukturer. Først og fremmest skal de traditionelle analytiske modelmiljøer skabe ETL (Extract, Transform and Load) opgaver. Fordi vi skal overføre transaktionsdata til datavarehuset. Disse typer af arkitektur har nogle ulemper. De er omkostninger, kompleksitet og dataforsinkelse. For at fjerne disse ulemper har vi brug for en anden tilgang.
Operationsanalyse i realtid
Microsoft annoncerede Real-Time Operational Analytics i SQL Server 2016. Muligheden for denne funktion er at kombinere transaktionsdatabase og analytisk forespørgselsarbejdsbelastning uden problemer med ydeevnen. Real-Time Operational Analytics giver:
- hybrid struktur
- transaktionelle og analytiske forespørgsler kan udføres på samme tid
- forårsager ingen problemer med ydeevne og forsinkelse.
- en enkel implementering.
Denne funktion kan overvinde ulemperne ved det traditionelle analytiske miljø. Hovedtemaet for denne funktion er, at kolonnelagerindekset opretholder en kopi af data uden at påvirke transaktionssystemets ydeevne. Dette tema gør det muligt for de analytiske forespørgsler at udføre uden at påvirke ydeevnen. Så dette minimerer præstationspåvirkningen. Hovedbegrænsningen ved denne funktion er, at vi ikke kan indsamle data fra forskellige datakilder.
Ikke-klyngede kolonnebutiksindeks
SQL Server 2016 introducerer opdaterbart "Non-Clustered Column Store Index". Det ikke-Clustered Column Store Index er et kolonnebaseret indeks, som giver ydeevnefordele til analytiske forespørgsler. Denne funktion lader os skabe real-time operationelle analytiske rammer. Det betyder, at vi kan udføre transaktioner og analytiske forespørgsler på samme tid. Overvej, at vi har brug for månedlige samlede salg. I en traditionel model skal vi udvikle ETL-opgaver, datamart og datavarehus. Men i realtid operationelle analyser kan vi gøre det uden at kræve noget datavarehus eller ændringer i OLTP-strukturen. Vi behøver kun at oprette passende ikke-klyngede kolonnelagerindeks.
Arkitektur af ikke-klynget kolonnelagerindeks
Lad os kort se på arkitekturen af ikke-klyngede kolonnelagerindeks og køremekanisme. Det ikke-klyngede kolonnelagerindeks indeholder en kopi af en del af eller alle rækkerne og kolonnerne i den underliggende tabel. Hovedtemaet for ikke-klyngede kolonnelagerindeks er at bevare en kopi af dataene og bruge denne kopi af data. Så denne mekanisme minimerer indvirkningen på transaktionsdatabaseydelsen. Det ikke-klyngede kolonnelagerindeks kan oprette en eller mere end én kolonne og kan anvende et filter på kolonner.
Når vi indsætter en ny række i en tabel, som har et ikke-klynget kolonnelagerindeks, opretter SQL Server for det første en "rækkegruppe". Rækkegruppe er en logisk struktur, som repræsenterer et sæt rækker. Så gemmer SQL Server disse rækker i et midlertidigt lager. Navnet på dette midlertidige lager er "deltastore". SQL Server bruger dette midlertidige lagerområde, fordi denne mekanisme forbedrer komprimeringsforholdet og reducerer indeksfragmenteringen. Når antallet af rækker når 1.048.577, lukker SQL Server rækkegruppens tilstand. SQL Server komprimerer denne rækkegruppe og ændrer tilstanden til "komprimeret".
Nu vil vi oprette en tabel og tilføje det ikke-klyngede kolonnelagerindeks.
DROP TABEL, HVIS FINDER Analysis_TableTestCREATE TABLE Analysis_TableTest(ID INT PRIMARY KEY IDENTITY(1,1),Continent_Name VARCHAR(20),Country_Name VARCHAR(20),City_Name VARCHAR(20),Sales_Amnt_GoINT,Amnt>OPRET IKKE-CLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] PÅ [dbo].[Analysis_TableTest]( [Country_Name], [City_Name] , Sales_Amnt) MED (DROP_EXISTING =OFF, =PRIMARY]_UDON [Prøv>KOMPRESSION]I dette trin vil vi indsætte flere rækker og se på egenskaberne for det ikke-klyngede kolonnelagerindeks.
INSERT INTO Analysis_TableTest VALUES('Europa','Tyskland','München','100','12')INSERT INTO Analysis_TableTest VALUES('Europa','Tyrkiet','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europa','Frankrig','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GODenne forespørgsel vil vise rækkegruppens tilstande, det samlede antal rækkers størrelse og andre værdier.
SELECT i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull FROM sys.indexes AS i JOIN sys.column_store_row_groups AS CSRowGroups ON i.object_id =CSRowGroups.object_id OG i.index_id =CSRowGroups.index_id BESTILLE EFTER object_name(i.object_id), i.pre>group_id,
Billedet ovenfor viser os deltastore-tilstanden og det samlede antal rækker, der ikke er komprimeret. Nu vil vi udfylde flere data i tabellen, og når antallet af rækker når 1.048.577, vil SQL Server lukke den første rækkegruppe og åbne en ny rækkegruppe.
INSERT INTO Analysis_TableTest VALUES('Europa','Tyskland','München','100','12')INSERT INTO Analysis_TableTest VALUES('Europa','Tyrkiet','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europa','Frankrig','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asien','Japan','Tokyo','190','17')GO 2000000
SQL Server vil komprimere denne rækkegruppe og oprette en ny rækkegruppe. Indstillingen "COMPRESSION_DELAY" giver os mulighed for at kontrollere, hvor længe rækkegruppen venter i lukket status.
Når vi kører indeksets vedligeholdelseskommandoer (omorganisere, genopbygge), fjernes de slettede rækker fysisk, og indekset defragmenteres.
Når vi opdaterer (slet + indsæt) nogle rækker i denne tabel, markeres de slettede rækker som "slettet", og nye opdaterede rækker indsættes i deltalageret.
Analytisk forespørgselsydeevnebenchmark
I denne overskrift vil vi udfylde data til Analysis_TableTest-tabellen. Jeg indsatte 4 millioner poster. (Du skal teste dette trin og de næste trin i dit testmiljø. Ydelsesproblemer kan opstå, og også DBCC DROPCLEANBUFFERS-kommandoen kan skade ydeevnen. Denne kommando vil fjerne alle bufferdataene i bufferpuljen.)
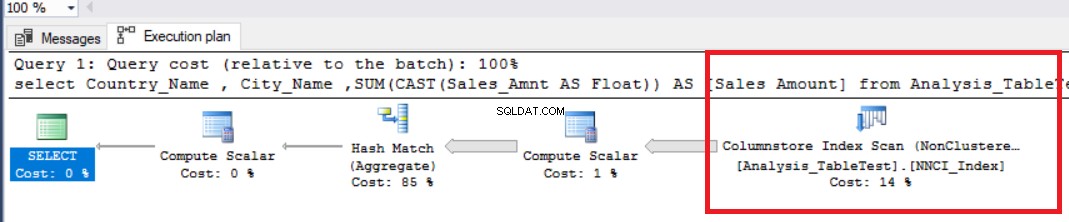
Nu vil vi køre følgende analytiske forespørgsel og undersøge ydeevneværdierne.
SET STATISTICS TID ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSvælg Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount]fra Analysis_TableTest group byCountry_Name ,City_Name
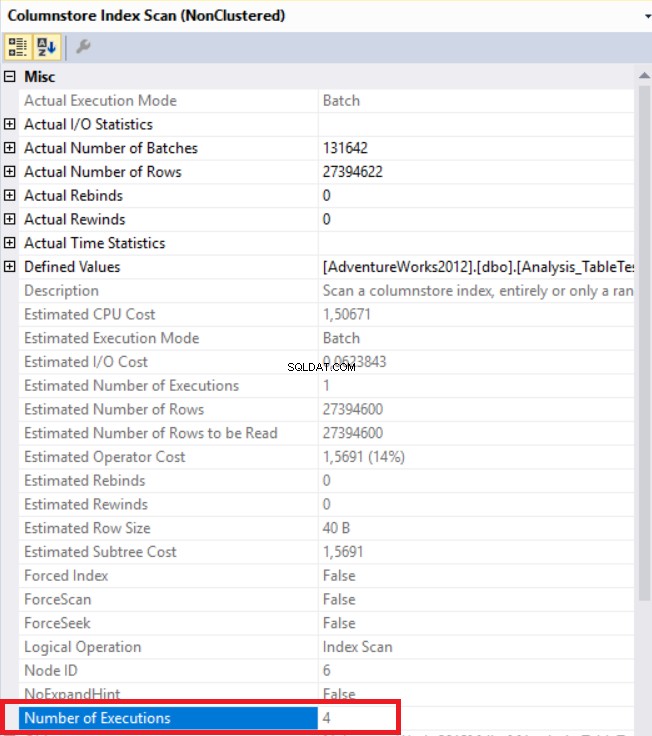
I ovenstående billede kan vi se den ikke-klyngede kolonnelagerindeksscanningsoperator. Nedenstående tabel viser CPU- og udførelsestider. Denne forespørgsel bruger 1,765 millisekunder i CPU og afsluttet på 0,791 millisekunder. CPU-tiden er større end den forløbne tid, fordi udførelsesplanen bruger parallelle processorer og fordeler opgaver til 4 processorer. Vi kan se det i "Columnstore Index Scan" operatøregenskaberne. Værdien "Antal henrettelser" angiver dette.
Nu vil vi tilføje et tip til forespørgslen for at reducere antallet af processorer. Vi vil ikke se nogen parallelisme-operator.
SET STATISTICS TID ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSvælg Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount]fra Analysis_TableTest group byCountry_Name ,City_NameOPTION (MAXDOP )
Nedenstående tabel definerer udførelsestider. I dette diagram kan vi se, at den forløbne tid er længere end CPU-tiden, fordi SQL Server kun brugte én processor.
Nu vil vi deaktivere det ikke-klyngede kolonnelagerindeks og udføre den samme forespørgsel.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLEGOSET STATISTICS TIME ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSvælg Country_Name , City_Name ,SUM(CAST(Salgs_Amnt) AS [Salgs_Amnt_Name] AS [Flåd_Navn_MAKS. Analyse_DOP_Navn. 1)
Ovenstående tabel viser os, at det ikke-klyngede kolonnelagerindeks giver en utrolig ydeevne i analytiske forespørgsler. Den kolonnelagerindekserede forespørgsel er cirka fem gange bedre end den anden.
Konklusion
Real-Time Operational Analytics giver utrolig fleksibilitet, fordi vi kan udføre analytiske forespørgsler i OLTP-systemer uden dataforsinkelse. Samtidig påvirker disse analytiske forespørgsler ikke OLTP-databasens ydeevne. Denne funktion giver os mulighed for at administrere transaktionsdata og de analytiske forespørgsler i det samme miljø.
Referencer
Kolonnelagerindekser – Vejledning om dataindlæsning
Kom godt i gang med Column Store for real-time operationelle analyser
Driftsanalyse i realtid
Yderligere læsning:
SQL Server Index Baglæns Scan:Forståelse, Tuning
Brug af indekser i SQL Server-hukommelsesoptimerede tabeller