"Men det kørte fint på vores udviklingsserver!"
Hvor mange gange hørte jeg det, når der opstod problemer med SQL-forespørgselsydeevne her og der? Jeg sagde det selv dengang. Jeg formodede, at en forespørgsel, der kører på mindre end et sekund, ville køre fint på produktionsservere. Men jeg tog fejl.
Kan du relatere til denne oplevelse? Hvis du stadig er i denne båd i dag af en eller anden grund, er dette indlæg for dig. Det vil give dig en bedre metrik til at finjustere din SQL-forespørgselsydeevne. Vi vil tale om tre af de mest kritiske tal i STATISTICS IO.
Som et eksempel vil vi bruge prøvedatabasen AdventureWorks.
Inden du begynder at køre forespørgsler nedenfor, skal du slå STATISTICS IO til. Sådan gør du det i et forespørgselsvindue:
BRUG AdventureWorksGOSET STATISTICS IO TIL Når du kører en forespørgsel med STATISTICS IO ON, vises forskellige meddelelser. Du kan se disse på fanen Meddelelser i forespørgselsvinduet i SQL Server Management Studio (se figur 1):
Nu hvor vi er færdige med den korte intro, lad os grave dybere.
1. Høj logisk læsning
Det første punkt på vores liste er den mest almindelige synder - høj logisk læsning.
Logiske læsninger er antallet af sider læst fra datacachen. En side er 8 KB stor. Datacache henviser på den anden side til RAM brugt af SQL Server.
Logisk læsning er afgørende for justering af ydeevne. Denne faktor definerer, hvor meget en SQL Server skal bruge for at producere det nødvendige resultatsæt. Derfor er den eneste ting at huske:Jo højere de logiske læsninger er, jo længere skal SQL Serveren arbejde. Det betyder, at din forespørgsel vil være langsommere. Reducer antallet af logiske læsninger, og du vil øge din forespørgselsydeevne.
Men hvorfor bruge logiske læsninger i stedet for forløbet tid?
- Den forløbne tid afhænger af andre ting, der udføres af serveren, ikke kun din forespørgsel alene.
- Forløbet tid kan ændre sig fra udviklingsserver til produktionsserver. Dette sker, når begge servere har forskellige kapaciteter og hardware- og softwarekonfigurationer.
At stole på den forløbne tid vil få dig til at sige:"Men det kørte fint i vores udviklingsserver!" før eller siden.
Hvorfor bruge logiske læsninger i stedet for fysiske læsninger?
- Fysiske læsninger er antallet af sider læst fra diske til datacachen (i hukommelsen). Når først de sider, der er nødvendige i en forespørgsel, er i datacachen, er der ingen grund til at genlæse dem fra diske.
- Når den samme forespørgsel køres igen, vil fysiske læsninger være nul.
Logisk læsning er det logiske valg til finjustering af SQL-forespørgselsydeevne.
For at se dette i aktion, lad os gå videre til et eksempel.
Eksempel på logiske læsninger
Antag, at du skal have listen over kunder med ordrer afsendt den 11. juli 2011. Du kommer med denne ret enkle forespørgsel nedenfor:
VÆLG d.FirstName,d.MiddleName,d.LastName,d.Suffix,a.OrderDate,a.ShipDate,a.Status,b.ProductID,b.OrderQty,b.UnitPriceFROM Sales.SalesOrderHeader aINNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID =b.SalesOrderIDINNER JOIN Sales.Customer c ON a.CustomerID =c.CustomerIDINNER JOIN Person.Person d ON c.PersonID =D.BusinessEntityIDWHERE a.201/Date1'ship Det er ligetil. Denne forespørgsel vil have følgende output:

Derefter tjekker du STATISTICS IO-resultatet af denne forespørgsel:

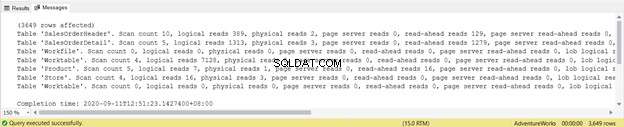
Outputtet viser de logiske læsninger af hver af de fire tabeller, der bruges i forespørgslen. I alt er summen af de logiske læsninger 729. Du kan også se fysiske læsninger med en samlet sum på 21. Prøv dog at køre forespørgslen igen, så bliver den nul.
Tag et nærmere kig på de logiske læsninger af SalesOrderHeader . Undrer du dig over, hvorfor den har 689 logiske læsninger? Måske har du tænkt på at inspicere nedenstående forespørgsel's udførelsesplan:
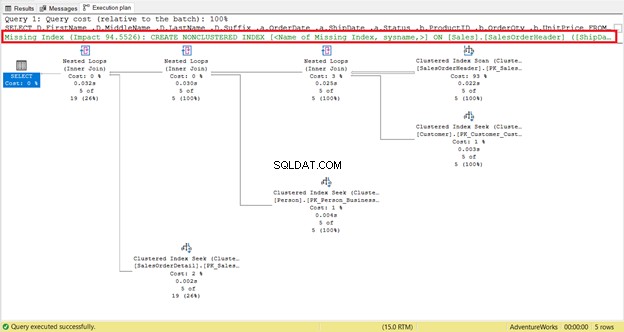
For det første er der en indeksscanning, der skete i SalesOrderHeader med en omkostning på 93%. Hvad kunne der ske? Antag, at du har tjekket dens egenskaber:
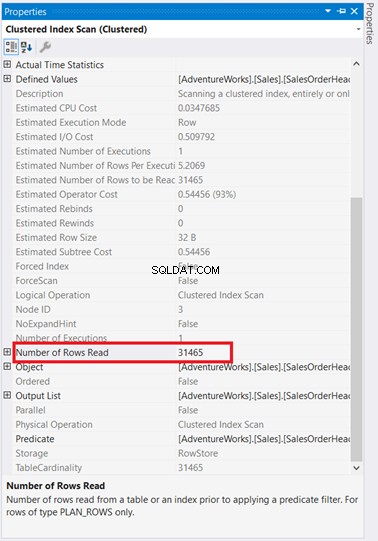
Hov! 31.465 rækker læst for kun 5 rækker returneret? Det er absurd!
Reduktion af antallet af logiske læsninger
Det er ikke så svært at mindske de 31.465 læste rækker. SQL Server har allerede givet os et fingerpeg. Fortsæt til følgende:
TRIN 1:Følg SQL Servers anbefaling og tilføj det manglende indeks
Har du bemærket den manglende indeksanbefaling i udførelsesplanen (figur 4)? Vil det løse problemet?
Der er én måde at finde ud af:
OPRET IKKE KLUSTERET INDEKS [IX_SalesOrderHeader_ShipDate]PÅ [Sales].[SalesOrderHeader] ([ShipDate]) Kør forespørgslen igen, og se ændringerne i STATISTICS IO logiske læsninger.

Som du kan se i STATISTICS IO (Figur 6), er der et enormt fald i logiske læsninger fra 689 til 17. De nye overordnede logiske læsninger er 57, hvilket er en væsentlig forbedring fra 729 logiske læsninger. Men for at være sikker, lad os inspicere udførelsesplanen igen.
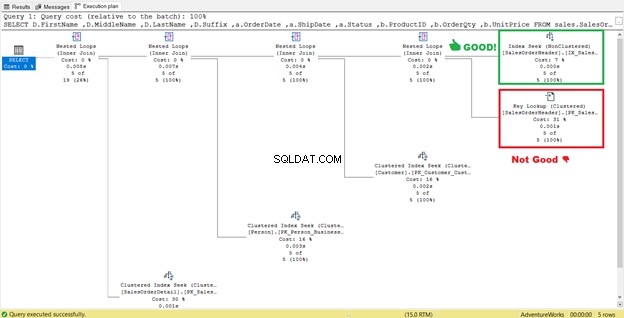
Det ser ud til, at der er en forbedring i planen, hvilket resulterer i reducerede logiske læsninger. Indeksscanningen er nu en indekssøgning. SQL Server behøver ikke længere at inspicere række-for-række for at få posterne med Shipdate=’07/11/2011′ . Men noget lurer stadig i den plan, og det er ikke rigtigt.
Du skal bruge trin 2.
TRIN 2:Ændre indekset og føj til inkluderede kolonner:ordredato, status og kunde-id
Kan du se den nøgleopslagsoperatør i udførelsesplanen (figur 7)? Det betyder, at det oprettede ikke-klyngede indeks ikke er nok – forespørgselsprocessoren skal bruge det klyngede indeks igen.
Lad os tjekke dens egenskaber.
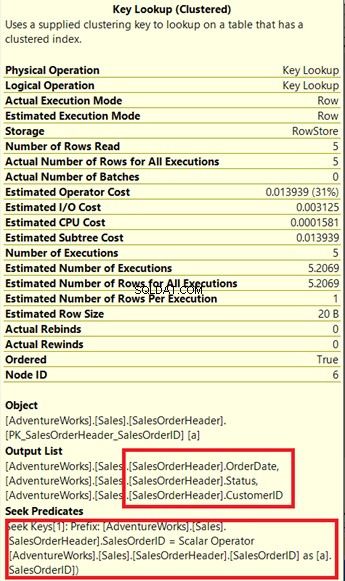
Bemærk den vedlagte boks under Outputliste . Det sker, at vi har brug for OrderDate , Status og Kunde-id i resultatsættet. For at opnå disse værdier brugte forespørgselsprocessoren det klyngede indeks (se Søg prædikater ) for at komme til bordet.
Vi er nødt til at fjerne det nøgleopslag. Løsningen er at inkludere OrderDate , Status og Kunde-id kolonner ind i det tidligere oprettede indeks.
- Højreklik på IX_SalesOrderHeader_ShipDate i SSMS.
- Vælg Egenskaber .
- Klik på Inkluderede kolonner fanen.
- Tilføj Ordredato , Status og Kunde-id .
- Klik på OK .
Når du har genskabt indekset, skal du køre forespørgslen igen. Vil dette fjerne Nøgleopslag og reducere logiske læsninger?

Det virkede! Fra 17 logiske læsninger ned til 2 (Figur 9).
Og Nøgleopslag ?
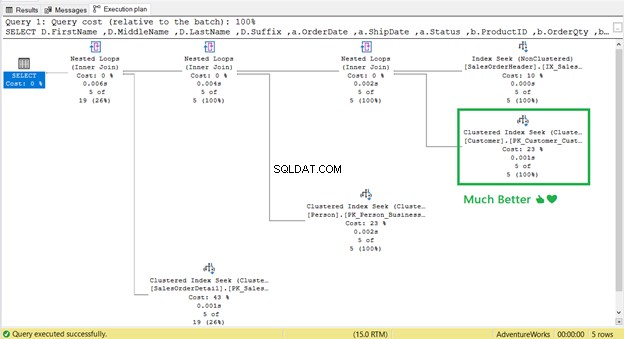
Det er væk! Klyngeret indekssøgning har erstattet nøgleopslag.
The Takeaway
Så hvad har vi lært?
En af de primære måder at reducere logiske læsninger og forbedre SQL-forespørgselsydeevne er at oprette et passende indeks. Men der er en hage. I vores eksempel reducerede det de logiske læsninger. Nogle gange vil det modsatte være rigtigt. Det kan også påvirke ydeevnen af andre relaterede forespørgsler.
Tjek derfor altid STATISTICS IO og udførelsesplanen efter oprettelse af indekset.
2. Logiske aflæsninger med høj lob
Det er meget det samme som punkt #1, men det vil omhandle datatyper tekst , ntekst , billede , varchar (maks. ), nvarchar (maks. ), varbinær (maks. ), eller kolonnebutik indekssider.
Lad os henvise til et eksempel:generering af lob logiske læsninger.
Eksempel på Lob Logical Reads
Antag, at du vil vise et produkt med dets pris, farve, miniaturebillede og et større billede på en webside. Således kommer du med en indledende forespørgsel som vist nedenfor:
VÆLG a.ProductID,a.Name AS ProductName,a.ListPrice,a.Color,b.Name AS ProductSubcategory,d.ThumbNailPhoto,d.LargePhotoFROM Production.Product aINNER JOIN Production.Product Undercategory b PÅ en. ProductSubcategoryID =b.ProductSubcategoryIDINNER JOIN Production.ProductProductPhoto c ON a.ProductID =c.ProductIDINNER JOIN Production.ProductPhoto d ON c.ProductPhotoID =d.ProductPhotoIDWHERE b.ProductCategoryID =1,BicodeCategoryID =1,Bicode ProductCategoryID =1,Subcode>
Derefter kører du det og ser output som det nedenfor:

Da du er sådan en højtydende fyr (eller pige), tjekker du straks STATISTICS IO. Her er den:

Det føles som noget snavs i dine øjne. 665 lob logiske læsninger? Du kan ikke acceptere dette. For ikke at nævne 194 logiske læsninger hver fra ProductPhoto og ProductProductPhoto tabeller. Du tror virkelig, at denne forespørgsel har brug for nogle ændringer.
Reduktion af Lob Logical Reads
Den tidligere forespørgsel havde 97 rækker returneret. Alle 97 cykler. Tror du, at dette er godt at vise på en webside?
Et indeks kan hjælpe, men hvorfor ikke forenkle forespørgslen først? På denne måde kan du være selektiv med hensyn til, hvad SQL Server vil returnere. Du kan reducere lob logiske læsninger.
- Tilføj et filter for produktunderkategorien, og lad kunden vælge. Inkluder derefter dette i WHERE-sætningen.
- Fjern Produktunderkategorien kolonne, da du vil tilføje et filter for produktunderkategorien.
- Fjern LargePhoto kolonne. Spørg dette, når brugeren vælger et specifikt produkt.
- Brug personsøgning. Kunden vil ikke kunne se alle 97 cykler på én gang.
Baseret på disse operationer beskrevet ovenfor, ændrer vi forespørgslen som følger:
- Fjern Produktunderkategori og LargePhoto kolonner fra resultatsættet.
- Brug OFFSET og FETCH for at imødekomme personsøgning i forespørgslen. Forespørg kun 10 produkter ad gangen.
- Tilføj ProductSubcategoryID i WHERE-klausulen baseret på kundens valg.
- Fjern Produktunderkategorien kolonne i ORDER BY-klausulen.
Forespørgslen vil nu ligne denne:
DECLARE @pageNumber TINYINTDECLARE @noOfRows TINYINT =10 -- hver side vil vise 10 produkter ad gangen.VÆLG a.ProductID,a.Name AS ProductName,a.ListPrice,a.Color,d.ThumbNailPhotoFROM Production.Product aINNER JOIN Production.ProductSubcategory b PÅ a.ProductSubcategoryID =b.ProductSubcategoryIDINNER JOIN Production.ProductProductPhoto c PÅ a.ProductID =c.ProductIDINNER JOIN Production.ProductPhoto d ON c.ProductPhotoID =aIDWHGO. ProductSubcategoryID =2 -- Road BikesORDER BY ProductName, a.ColorOFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY -- skift OFFSET- og FETCH-værdierne baseret på hvilken side brugeren er.
Med ændringerne udført, vil lob logiske læsninger blive bedre? STATISTICS IO rapporterer nu:

ProductPhoto tabellen har nu 0 lob logiske læsninger – fra 665 lob logiske læsninger ned til ingen. Det er en forbedring.
Takeaway
En af måderne at reducere logiske læsninger på er at omskrive forespørgslen for at forenkle den.
Fjern unødvendige kolonner og reducer de returnerede rækker til det mindst nødvendige. Brug OFFSET og FETCH til personsøgning, når det er nødvendigt.
For at sikre, at forespørgselsændringerne har forbedret logiske læsninger og SQL-forespørgselsydeevnen, skal du altid kontrollere STATISTICS IO.
3. Høj logisk læsning af arbejdsbord/arbejdsfil
Endelig er det logisk at læse Worktable og Arbejdsfil . Men hvad er disse tabeller? Hvorfor vises de, når du ikke bruger dem i din forespørgsel?
At have arbejdsbord og Arbejdsfil vises i STATISTICS IO betyder, at SQL Server har brug for meget mere arbejde for at få de ønskede resultater. Det tyr til at bruge midlertidige tabeller i tempdb , nemlig Arbejdsborde og Arbejdsfiler . Det er ikke nødvendigvis skadeligt at have dem i STATISTICS IO-output, så længe logiske læsninger er nul, og det ikke forårsager problemer for serveren.
Disse tabeller kan blive vist, når der blandt andet er en ORDER BY, GROUP BY, CROSS JOIN eller DISTINCT.
Eksempel på logiske læsninger af arbejdstabel/arbejdsfil
Antag, at du skal forespørge alle butikker uden salg af bestemte produkter.
Du kommer i første omgang med følgende:
SELECT DISTINCT a.SalesPersonID,b.ProductID,ISNULL(c.OrderTotal,0) AS OrderTotalFROM Sales.Store ACROSS JOIN Production.Product BLEFT JOIN (SELECT b.SalesPersonID,a.ProductID ,SUM(a. LineTotal) AS OrderTotal FRA Sales.SalesOrderDetail a INNER JOIN Sales.SalesOrderHeader b PÅ a.SalesOrderID =b.SalesOrderID HVOR b.SalesPersonID IKKE ER NULL GROUP BY b.SalesPersonID, a.ProductID, b.OrderSales.PON. c.SalesPersonID OG b.ProductID =c.ProductIDWHERE c.OrderTotal ER NULLORDER AF a.SalesPersonID, b.ProductID
Denne forespørgsel returnerede 3649 rækker:
Lad os tjekke, hvad STATISTICS IO fortæller:

Det er værd at bemærke, at Worktable logiske læsninger er 7128. De overordnede logiske læsninger er 8853. Hvis du tjekker udførelsesplanen, vil du se masser af paralleliteter, hash-matches, spools og indeksscanninger.
Reduktion af logiske læsninger af arbejdsbord/arbejdsfil
Jeg kunne ikke konstruere en enkelt SELECT-sætning med et tilfredsstillende resultat. Det eneste valg er således at opdele SELECT-sætningen i flere forespørgsler. Se nedenfor:
SELECT DISTINCT a.SalesPersonID,b.ProductIDINTO #tmpStoreProductsFROM Sales.Store ACROSS JOIN Production.Product bSELECT b.SalesPersonID,a.ProductID,SUM(a.LineTotal) AS OrderTotalINTO #tmpProductOrderssonFROMSalesPerOlesINSalgINSalg. .SalesOrderHeader b ON a.SalesOrderID =b.SalesOrderIDWHERE b.SalesPersonID IS NOT NULLGROUP BY b.SalesPersonID, a.ProductIDSELECT a.SalesPersonID,a.ProductIDFROM #tmpStoreProducts aLEFT JOIN #tmpPersonPersonID a.SalesPersonID a.SalesPersonl ProductID =b.ProductIDWHERE b.OrderTotal ER NULLORDER BY a.SalesPersonID, a.ProductIDDROP TABLE #tmpProductOrdersPerSalesPersonDROP TABLE #tmpStoreProducts
Den er flere linjer længere, og den bruger midlertidige tabeller. Lad os nu se, hvad STATISTICS IO afslører:
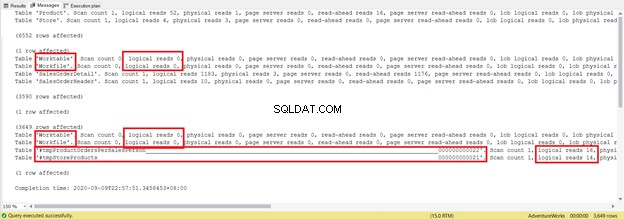
Prøv ikke at fokusere på denne statistiske rapportlængde - det er kun frustrerende. Tilføj i stedet logiske læsninger fra hver tabel.
For i alt 1279 er det et betydeligt fald, da det var 8853 logiske læsninger fra den enkelte SELECT-sætning.
Vi har ikke tilføjet noget indeks til de midlertidige tabeller. Du har muligvis brug for en, hvis mange flere poster er tilføjet til SalesOrderHeader og SalesOrderDetail . Men du forstår pointen.
Takeaway
Nogle gange virker 1 SELECT-sætning god. Men bag kulisserne er det modsatte tilfældet. Arbejdsborde og Arbejdsfiler med høj logisk læsningsforsinkelse for din SQL-forespørgselsydeevne.
Hvis du ikke kan tænke på en anden måde at rekonstruere forespørgslen på, og indekserne er ubrugelige, så prøv "del og hersk"-tilgangen. Arbejdsbordene og Arbejdsfiler vises muligvis stadig på fanen Meddelelse i SSMS, men de logiske læsninger vil være nul. Derfor vil det samlede resultat være mindre logiske læsninger.
Bundlinjen i SQL Query Performance and STATISTICS IO
Hvad er den store sag med disse 3 grimme I/O-statistikker?
Forskellen i SQL-forespørgselsydeevne vil være som nat og dag, hvis du er opmærksom på disse tal og sænker dem. Vi har kun præsenteret nogle måder at reducere logiske læsninger som:
- oprettelse af passende indekser;
- forenkling af forespørgsler – fjernelse af unødvendige kolonner og minimering af resultatsættet;
- opdeling af en forespørgsel i flere forespørgsler.
Der er mere som at opdatere statistik, defragmentere indekser og indstille den rigtige FILLFACTOR. Kan du tilføje mere til dette i kommentarfeltet?
Hvis du kan lide dette opslag, så del det med dine foretrukne sociale medier.