Tilføjelse: SQL Server 2012 viser en vis forbedret ydeevne på dette område, men ser ikke ud til at løse de specifikke problemer, der er nævnt nedenfor. Dette skulle tilsyneladende rettes i den næste større version efter SQL Server 2012!
Din plan viser, at de enkelte inserts bruger parametriserede procedurer (muligvis autoparametriserede), så parse-/kompileringstiden for disse bør være minimal.
Jeg tænkte, at jeg ville undersøge dette lidt mere, så opret en loop (script) og prøvede at justere antallet af VALUES klausuler og registrering af kompileringstiden.
Jeg dividerede derefter kompileringstiden med antallet af rækker for at få den gennemsnitlige kompileringstid pr. klausul. Resultaterne er nedenfor
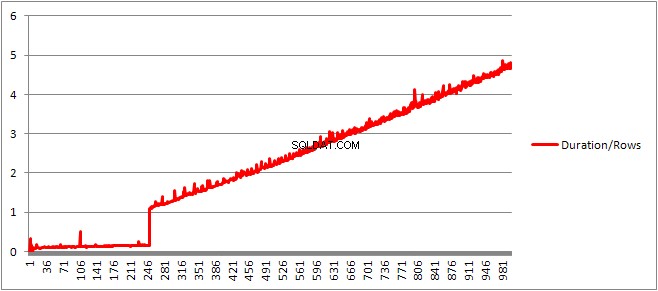
Op til 250 VALUES klausuler præsenterer kompileringstiden/antallet af klausuler har en let opadgående tendens, men intet for dramatisk.
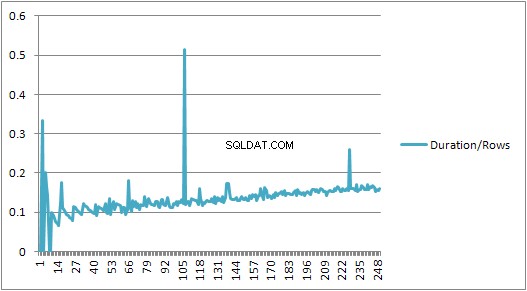
Men så sker der en pludselig ændring.
Den del af dataene er vist nedenfor.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
Den cachelagrede planstørrelse, som var vokset lineært, falder pludselig, men CompileTime øges 7 gange, og CompileMemory skyder op. Dette er afskæringspunktet mellem planen er en automatisk parametriseret (med 1.000 parametre) til en ikke-parametriseret. Derefter ser det ud til at blive lineært mindre effektivt (med hensyn til antallet af værdiklausuler behandlet på en given tid).
Ikke sikker på hvorfor dette skulle være. Formentlig, når den kompilerer en plan for specifikke bogstavelige værdier, skal den udføre en eller anden aktivitet, der ikke skaleres lineært (såsom sortering).
Det ser ikke ud til at påvirke størrelsen af den cachelagrede forespørgselsplan, da jeg prøvede en forespørgsel, der udelukkende består af duplikerede rækker, og ingen af dem påvirker rækkefølgen af outputtet af tabellen med konstanter (og som du indsætter i en bunke tid brugt på sortering ville alligevel være meningsløst, selvom det gjorde det).
Hvis der tilføjes et klynget indeks til tabellen, viser planen stadig et eksplicit sorteringstrin, så det ikke ser ud til at sortere på kompileringstidspunktet for at undgå en sortering under kørslen.

Jeg forsøgte at se på dette i en debugger, men de offentlige symboler for min version af SQL Server 2008 ser ikke ud til at være tilgængelige, så i stedet var jeg nødt til at se på den tilsvarende UNION ALL konstruktion i SQL Server 2005.
Et typisk stakspor er nedenfor
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Så når man går væk fra navnene i stakken, ser det ud til at bruge meget tid på at sammenligne strenge.
Denne KB-artikel angiver, at DeriveNormalizedGroupProperties er forbundet med det, der plejede at blive kaldt normaliseringsstadiet af forespørgselsbehandling
Dette trin kaldes nu binding eller algebrisering, og det tager udtrykket parse træ-output fra det forrige parse-trin og udsender et algebriseret udtrykstræ (forespørgselsprocessortræ) for at gå videre til optimering (triviel planoptimering i dette tilfælde) [ref].
Jeg prøvede endnu et eksperiment (Script), som var at køre den originale test igen, men så på tre forskellige tilfælde.
- Fornavn og efternavn Strenge med en længde på 10 tegn uden dubletter.
- Fornavn og efternavn Streng med en længde på 50 tegn uden dubletter.
- Fornavn og efternavn Strenge med en længde på 10 tegn med alle dubletter.
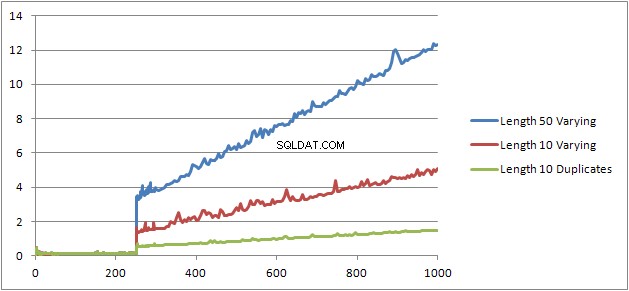
Det kan tydeligt ses, at jo længere strengene er, jo værre bliver tingene, og omvendt, jo flere dubletter, jo bedre bliver tingene. Som tidligere nævnt påvirker dubletter ikke den cachelagrede planstørrelse, så jeg antager, at der skal være en proces med duplikatidentifikation, når selve det algebriserede udtrykstræ konstrueres.
Rediger
Et sted, hvor disse oplysninger udnyttes, er vist af @Lieven her
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
For på kompileringstidspunktet kan den bestemme, at Name kolonnen har ingen dubletter, den springer bestilling efter den sekundære 1/ (ID - ID) over udtryk ved kørselstid (sorteringen i planen har kun én ORDER BY kolonne) og ingen divider med nul-fejl hæves. Hvis dubletter føjes til tabellen, viser sorteringsoperatoren to rækkefølge efter kolonner, og den forventede fejl hæves.