Load balancers er en vigtig komponent i enhver høj tilgængelig databaseopsætning. De bruges til at øge kapaciteten og pålideligheden af dine kritiske systemer og applikationer ved at forhindre en server i at blive overbelastet. Vi taler meget om dem på Severalnines-bloggen, såsom hvorfor du har brug for dem, og hvordan de fungerer. En af de mest populære load balancere til MySQL og MariaDB er HAProxy.
Funktionsmæssigt er HAProxy ikke sammenlignelig med ProxySQL eller MaxScale. HAProxy er dog en hurtig, robust belastningsbalancer, der vil fungere perfekt i ethvert miljø, så længe applikationen kan udføre læse/skrive-opdelingen og sende SELECT-forespørgsler til én backend og alle skrivninger og SELECT...TIL OPDATERING til en separat backend.
Det er meget vigtigt at holde styr på alle metrics, der stilles til rådighed af HAProxy; du skal være i stand til at kende status for din proxy, især for at vide, om du er stødt på problemer.
ClusterControl har altid gjort en HAProxy-statusside tilgængelig, der viser proxyens tilstand i realtid. Nu, med de nye Prometheus-baserede SCUMM (Severalnines ClusterControl Unified Monitoring &Management) dashboards, er det nemt at spore, hvordan disse metrics ændrer sig over tid.
Dette blogindlæg vil udforske de forskellige metrics, der præsenteres i HAProxy SCUMM-dashboardet.
Udforskning af HAProxy Dashboard i ClusterControl
Alle Prometheus- og SCUMM-dashboards er som standard deaktiveret i ClusterControl. Men at implementere dem for en given klynge er blot et spørgsmål om et klik. Hvis du overvåger flere klynger med ClusterControl, kan du genbruge den samme Prometheus-instans for hver klynge.
Når den er implementeret, kan du få adgang til HAProxy-dashboardet. Lad os tage et kig på de tilgængelige data i dashboardet:
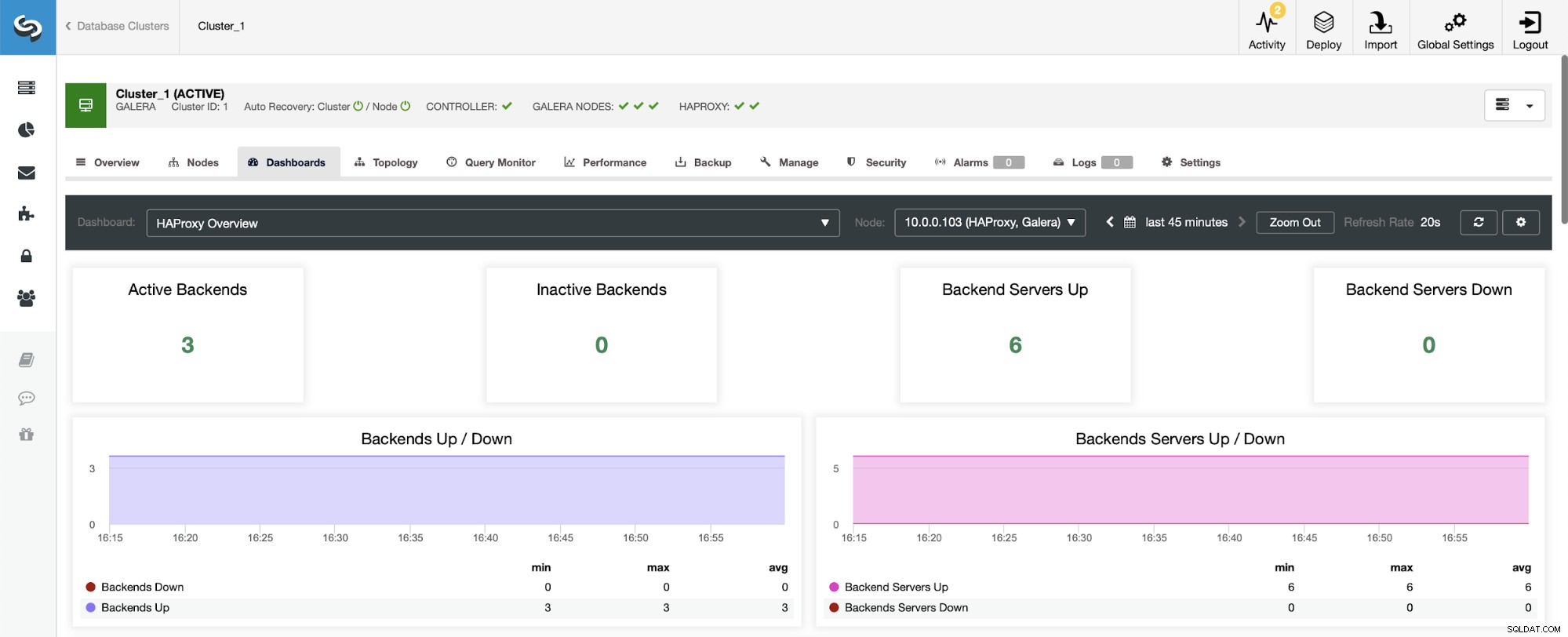
Det første, du vil se, når du navigerer til HAProxy-dashboardet, er oplysninger om tilstanden af dine backends. Bemærk her, at det du ser kan afhænge af klyngetypen og hvordan du har implementeret HAProxy. I dette tilfælde implementerede vi en Galera-klynge, og HAProxy blev implementeret på en round-robin måde. Derfor ser du tre backends til læsninger og tre til skrivninger - seks i alt. Det er også grunden til, at du ser alle backends markeret som "Op."
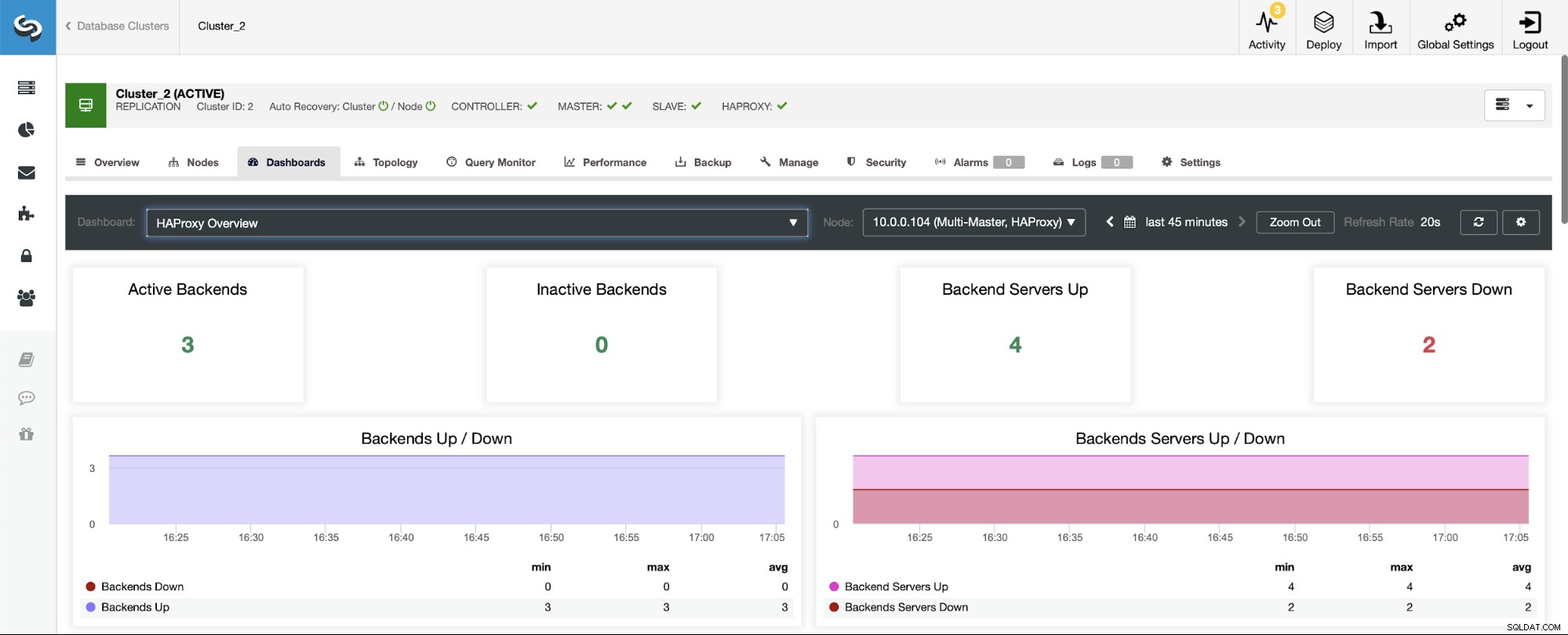
I et scenarie med en replikeringsklynge vil tingene se anderledes ud, da HAProxy vil blive implementeret i en læse/skrive-split, og scripts vil kun holde én vært (master) oppe at køre i forfatterens backend.
Bemærk, det er derfor, du nedenfor ser to backend-servere markeret som "Ned":
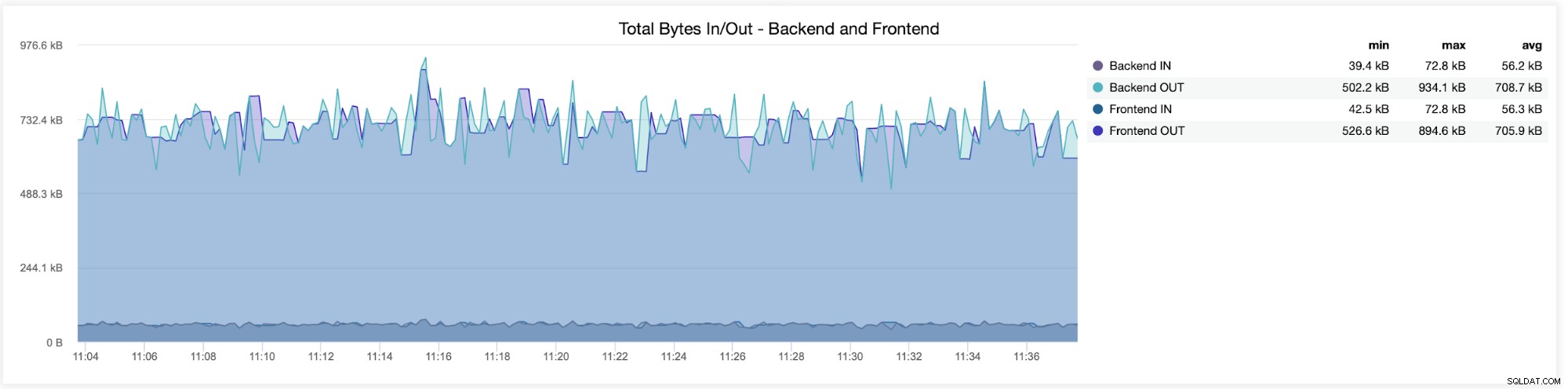
I den følgende graf vil du se de data, der er sendt og modtaget af begge backend (fra HAProxy til databaseserverne) og frontend (mellem HAProxy og klientværter):
Du kan også kontrollere trafikfordelingen mellem backends i din HAProxy-konfiguration. I dette tilfælde har vi to backends, og forespørgslerne sendes via port 3308, som fungerer som round-robin adgangspunkt til vores Galera-klynge:
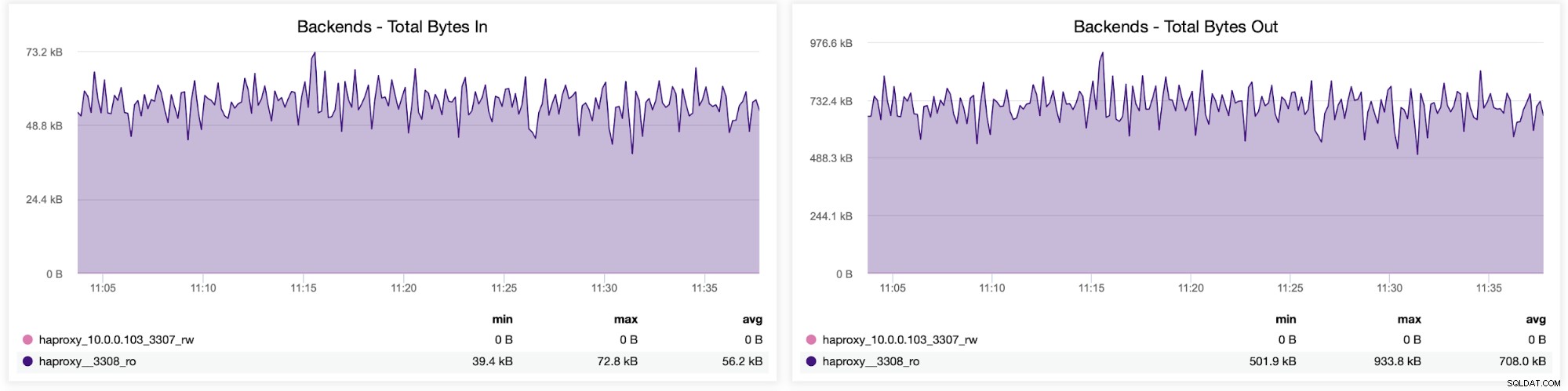
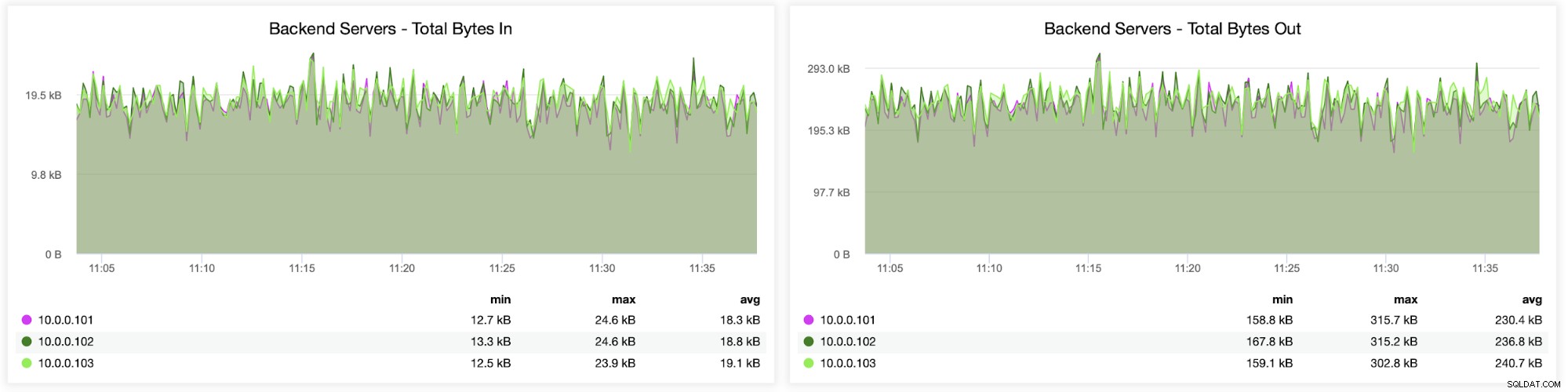
Dernæst kan du se, hvordan trafikken blev fordelt på tværs af alle backend-servere. I dette scenarie – på grund af round-robin adgangsmønsteret – var data mere eller mindre jævnt fordelt på tværs af alle tre backend Galera-servere:
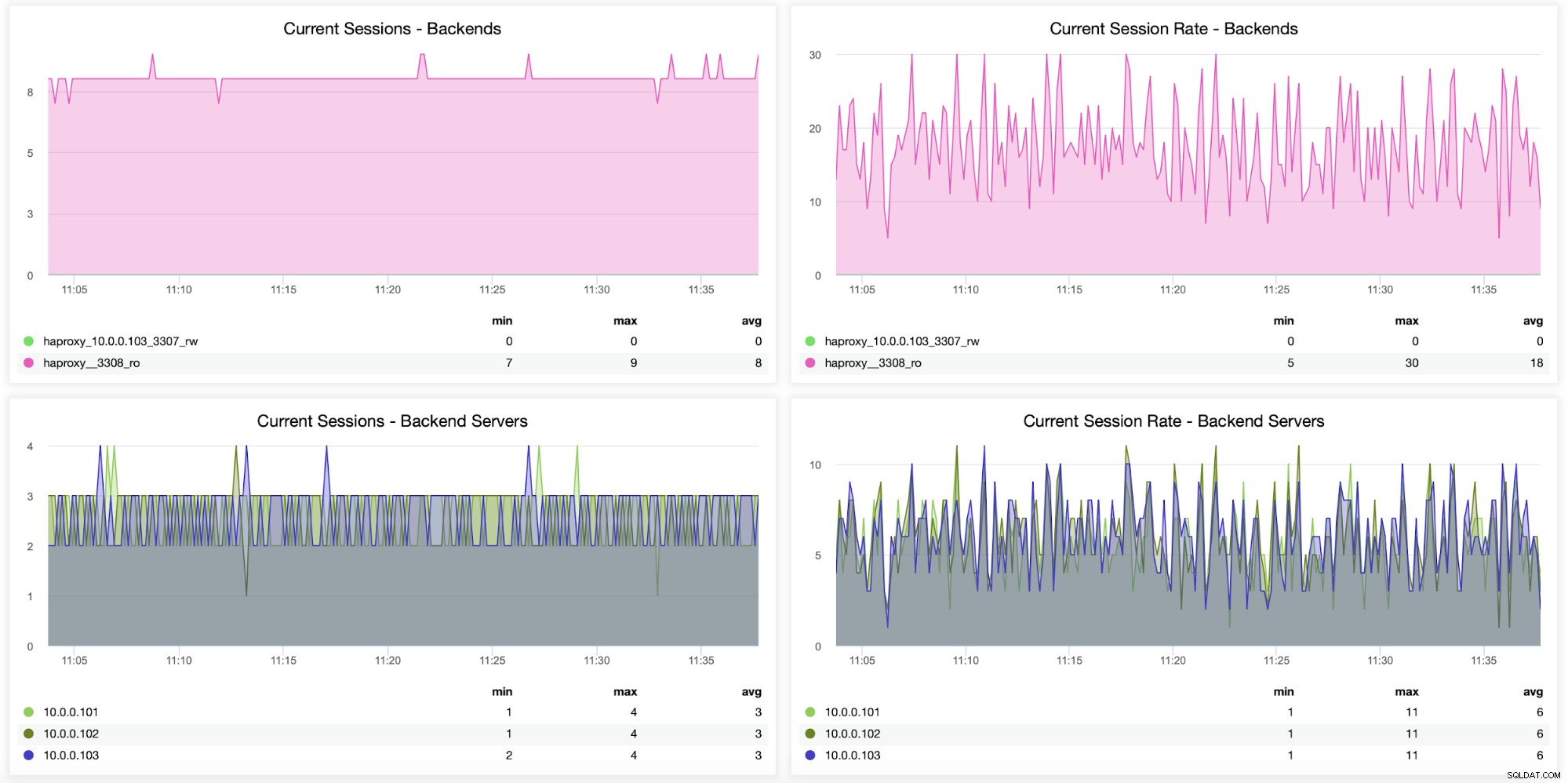
Information om sessioner, herunder hvor mange sessioner der blev åbnet fra HAProxy til backend servere, kan også overvåges, som det ses i følgende graf. Du kan også spore, hvor mange gange i sekundet en ny session blev åbnet til backend, og hvordan disse metrics ser ud på basis af backend-server.
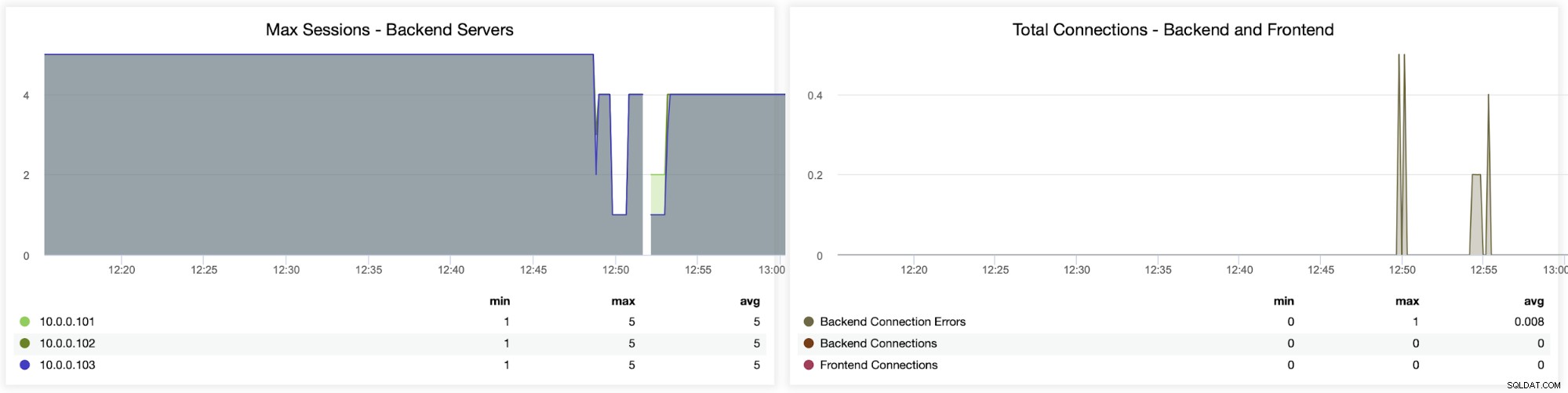
De følgende to grafer viser det maksimale antal sessioner pr. backend-server, og hvornår tilslutningsproblemer dukkede op. Dette kan være ret nyttigt til fejlretningsformål, hvor du rammer en konfigurationsfejl på din HAProxy-instans, og forbindelserne begynder at falde.
Denne næste graf er potentielt mere værdifuld, da den viser forskellige metrics relateret til fejl håndtering, såsom fejl, anmodningsfejl, genforsøg på backend-siden osv. Der er også en "Sessions"-graf, der viser en oversigt over sessionsmålingerne.
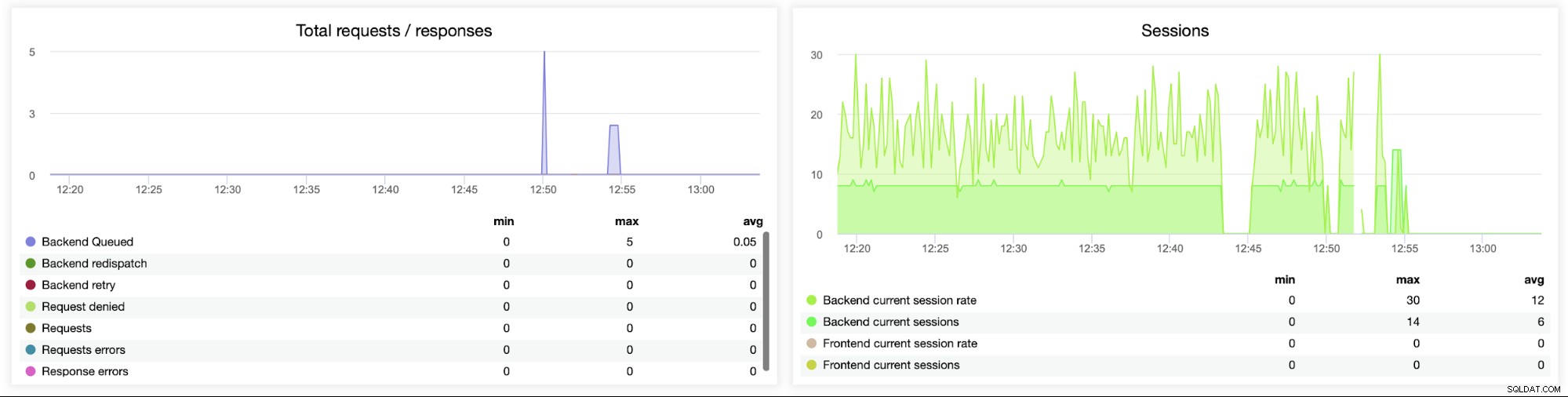
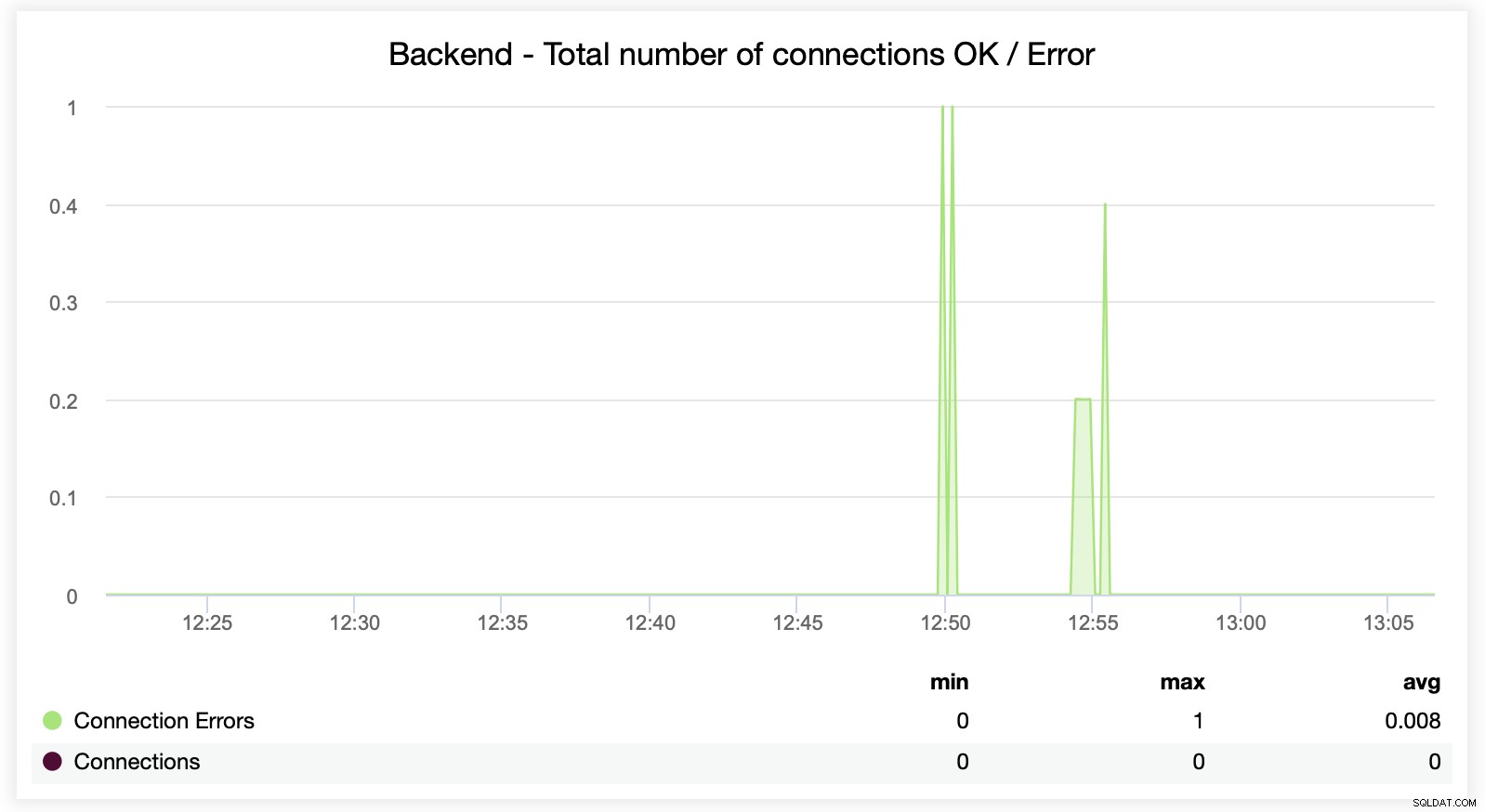
Her kan du se, at ClusterControl sporer forbindelsesfejlene i realtid, som kan hjælpe med at udpege det præcise tidspunkt, hvor problemerne begyndte at udvikle sig.
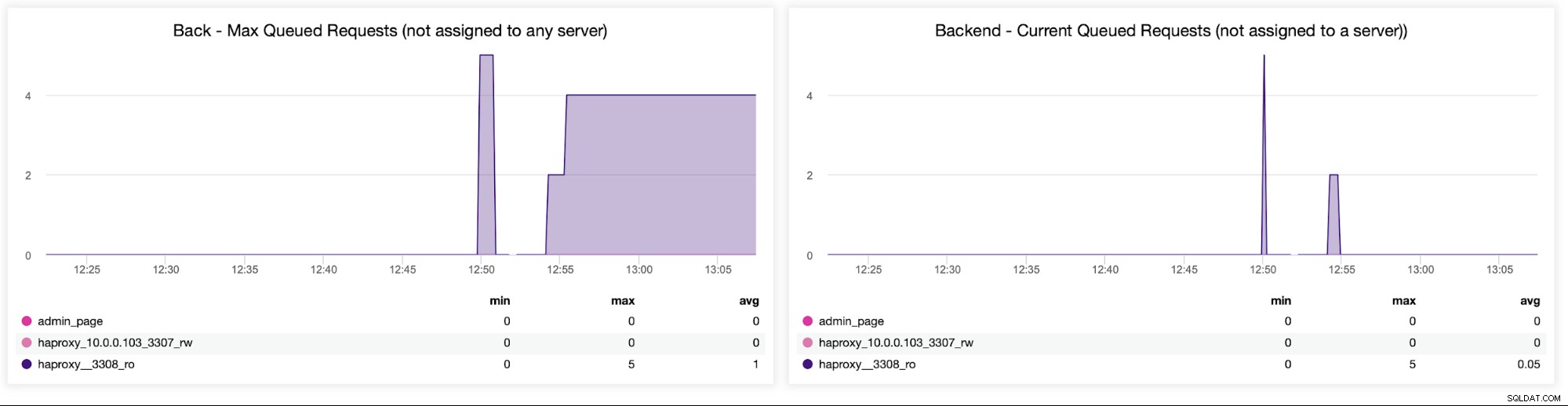
Til sidst vil vi se på følgende to grafer relateret til anmodninger i kø . HAProxy køer anmodninger til backend, hvis backend-serverne er overmættede. Dette kan for eksempel pege på de overbelastede databaseservere, som ikke kan håndtere mere trafik.
Afslutning
Deployering og overvågning af din HAProxy load balancer i ClusterControl kan hjælpe med at gøre det nemt at administrere og overvåge dine forbindelser. At have et klart overblik over ydeevnen af dine backends, trafikfordeling, sessionsmålinger, forbindelsesfejl og antallet af forespørgsler i kø kan hjælpe med at sikre tilgængeligheden og skalerbarheden af enhver databaseopsætning.
ClusterControl gør opsætning og overvågning af load balancers til en leg for enhver databasekonfiguration. Bruger du ikke ClusterControl endnu? Hvis du selv gerne vil se, hvor nemt det er at implementere og overvåge din HAProxy load balancer med ClusterControl, inviterer vi dig til en gratis 30-dages prøveversion af platformen, uden betingelser. For en mere detaljeret gennemgang af, hvorfor og hvordan man bruger HAProxy til belastningsbalancering, se vores tutorial om MySQL belastningsbalancering med HAProxy.