Databaser skal køre optimalt, men det er ikke så let en opgave. INFORMATIONSSCHEMA-databasen kan være dit hemmelige våben i krigen om databaseoptimering.
Vi er vant til at oprette databaser ved hjælp af en grafisk grænseflade eller en række SQL-kommandoer. Det er helt fint, men det er også godt at forstå lidt om, hvad der foregår i baggrunden. Dette er vigtigt for oprettelse, vedligeholdelse og optimering af en database, og det er også en god måde at spore ændringer, der sker 'bag kulisserne'.
I denne artikel vil vi se på en håndfuld SQL-forespørgsler, der kan hjælpe dig med at kigge ind i, hvordan en MySQL-database fungerer.
INFORMATION_SCHEMA-databasen
Vi har allerede diskuteret INFORMATION_SCHEMA database i denne artikel. Hvis du ikke allerede har læst den, vil jeg helt klart anbefale dig at gøre det, før du fortsætter.
Hvis du har brug for en genopfriskning på INFORMATION_SCHEMA database – eller hvis du beslutter dig for ikke at læse den første artikel – her er nogle grundlæggende fakta, du skal vide:
INFORMATION_SCHEMAdatabasen er en del af ANSI-standarden. Vi vil arbejde med MySQL, men andre RDBMS'er har deres varianter. Du kan finde versioner til H2 Database, HSQLDB, MariaDB, Microsoft SQL Server og PostgreSQL.- Dette er den database, der holder styr på alle andre databaser på serveren; vi finder beskrivelser af alle objekter her.
- Som enhver anden database er
INFORMATION_SCHEMAdatabasen indeholder en række relaterede tabeller og information om forskellige objekter. - Du kan forespørge denne database ved hjælp af SQL og bruge resultaterne til at:
- Overvåg databasestatus og ydeevne, og
- Generer automatisk kode baseret på forespørgselsresultater.
Lad os nu gå videre til at forespørge på INFORMATION_SCHEMA-databasen. Vi starter med at se på den datamodel, vi skal bruge.
Datamodellen
Den model, vi vil bruge i denne artikel, er vist nedenfor.
Dette er en forenklet model, der giver os mulighed for at gemme oplysninger om klasser, instruktører, studerende og andre relaterede detaljer. Lad os kort gennemgå tabellerne.
Vi gemmer listen over instruktører i lecturer bord. For hver underviser optager vi et first_name og en last_name .
class tabel viser alle de klasser, vi har på vores skole. For hver post i denne tabel gemmer vi class_name , underviserens ID, en planlagt start_date og end_date , og eventuelle yderligere class_details . For nemheds skyld antager jeg, at vi kun har én underviser pr. klasse.
Undervisningen er normalt organiseret som en række forelæsninger. De kræver generelt en eller flere eksamener. Vi gemmer lister over relaterede forelæsninger og eksamener i lecture og exam tabeller. Begge vil have ID'et for den relaterede klasse og den forventede start_time og end_time .
Nu mangler vi elever til vores klasser. En liste over alle elever er gemt i student bord. Endnu en gang gemmer vi kun first_name og last_name af hver elev.
Den sidste ting, vi skal gøre, er at spore elevernes aktiviteter. Vi gemmer en liste over hver klasse, som en elev har tilmeldt sig, elevens tilstedeværelsesrekord og deres eksamensresultater. Hver af de resterende tre tabeller – on_class , on_lecture og on_exam – vil have en reference til eleven og en reference til den relevante tabel. Kun on_exam tabel vil have en ekstra værdi:karakter.
Ja, denne model er meget enkel. Vi kunne tilføje mange andre detaljer om studerende, undervisere og klasser. Vi kunne gemme historiske værdier, når poster opdateres eller slettes. Alligevel vil denne model være nok til formålet med denne artikel.
Oprettelse af en database
Vi er klar til at oprette en database på vores lokale server og undersøge, hvad der sker inde i den. Vi eksporterer modellen (i Vertabelo) ved hjælp af "Generate SQL script ”-knappen.
Så opretter vi en database på MySQL Server-instansen. Jeg kaldte min database "classes_and_students ”.
Den næste ting, vi skal gøre, er at køre et tidligere genereret SQL-script.
Nu har vi databasen med alle dens objekter (tabeller, primære og fremmede nøgler, alternative nøgler).
Databasestørrelse
Efter scriptet er kørt, data om "classes and students ” databasen er gemt i INFORMATION_SCHEMA database. Disse data findes i mange forskellige tabeller. Jeg vil ikke liste dem alle igen her; det gjorde vi i den forrige artikel.
Lad os se, hvordan vi kan bruge standard SQL på denne database. Jeg starter med en meget vigtig forespørgsel:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Vi forespørger kun på INFORMATION_SCHEMA.TABLES bord her. Denne tabel burde give os mere end nok detaljer om alle borde på serveren. Bemærk venligst, at jeg kun har filtreret tabeller fra "classes_and_students " database ved hjælp af SET variabel i den første linje og senere ved at bruge denne værdi i forespørgslen. De fleste tabeller indeholder kolonnerne TABLE_NAME og TABLE_SCHEMA , som angiver tabellen og skemaet/databasen disse data tilhører.
Denne forespørgsel returnerer den aktuelle størrelse af vores database og den ledige plads, der er reserveret til vores database. Her er det faktiske resultat:

Som forventet er størrelsen på vores tomme database mindre end 1 MB, og den reserverede ledige plads er meget større.
Tabelstørrelser og -egenskaber
Den næste interessante ting at gøre ville være at se på størrelserne på tabellerne i vores database. For at gøre det bruger vi følgende forespørgsel:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
Forespørgslen er næsten identisk med den forrige, med én undtagelse:Resultatet er grupperet på tabelniveau.
Her er et billede af resultatet returneret af denne forespørgsel:
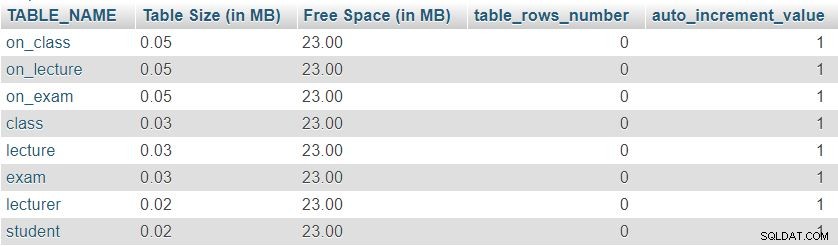
For det første kan vi bemærke, at alle otte tabeller har en minimal "Tabelstørrelse" reserveret til tabeldefinition, som inkluderer kolonnerne, primærnøgle og indeks. "Fri plads" er ligeligt fordelt mellem alle tabeller.
Vi kan også se antallet af rækker i øjeblikket i hver tabel og den aktuelle værdi af auto_increment ejendom for hvert bord. Da alle tabeller er helt tomme, har vi ingen data og auto_increment er sat til 1 (en værdi, der vil blive tildelt den næste indsatte række).
Primære nøgler
Hver tabel bør have en primær nøgleværdi defineret, så det er klogt at tjekke, om dette er sandt for vores database. En måde at gøre dette på er ved at forbinde en liste over alle tabeller med en liste over begrænsninger. Dette burde give os de oplysninger, vi har brug for.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
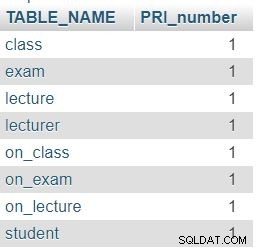
_NAME Vi har også brugt INFORMATION_SCHEMA.COLUMNS tabel i denne forespørgsel. Mens den første del af forespørgslen blot vil returnere alle tabeller i databasen, vil den anden del (efter LEFT JOIN ) vil tælle antallet af PRI'er i disse tabeller. Vi brugte LEFT JOIN fordi vi vil se om en tabel har 0 PRI i COLUMNS tabel.
Som forventet indeholder hver tabel i vores database nøjagtig én kolonne med primær nøgle (PRI).
“Øer”?
"Øer" er tabeller, der er fuldstændig adskilt fra resten af modellen. De sker, når en tabel ikke indeholder fremmednøgler og ikke refereres til i nogen anden tabel. Dette burde virkelig ikke forekomme, medmindre der er en rigtig god grund, f.eks. når tabeller indeholder parametre eller gemmer resultater eller rapporter inde i modellen.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Hvad er tanken bag denne forespørgsel? Nå, vi bruger INFORMATION_SCHEMA.KEY_COLUMN_USAGE tabel for at teste, om en kolonne i tabellen er en reference til en anden tabel, eller om en kolonne bruges som reference i en anden tabel. Den første del af forespørgslen vælger alle tabellerne. Efter den første LEFT JOIN tæller vi antallet af gange, en kolonne fra denne tabel blev brugt som reference. Efter den anden LEFT JOIN tæller vi antallet af gange, en kolonne fra denne tabel refererede til en anden tabel.
Det returnerede resultat er:
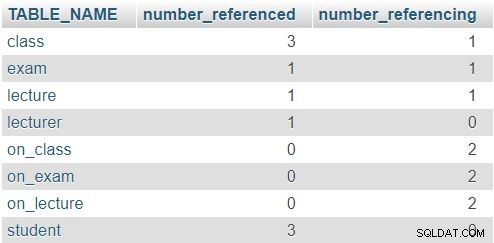
I rækken for class tabel angiver tallene 3 og 1, at denne tabel blev refereret tre gange (i lecture , exam og on_class tabeller), og at den indeholder en attribut, der refererer til en anden tabel (lecturer_id ). De øvrige tabeller følger et lignende mønster, selvom de faktiske tal naturligvis vil være anderledes. Reglen her er, at ingen række skal have et 0 i begge kolonner.
Tilføjelse af rækker
Indtil videre er alt gået som forventet. Vi har med succes importeret vores datamodel fra Vertabelo til den lokale MySQL-server. Alle tabeller indeholder nøgler, præcis som vi vil have dem til, og alle tabeller er relateret til hinanden - der er ingen "øer" i vores model.
Nu vil vi indsætte nogle rækker i vores tabeller og bruge de tidligere demonstrerede forespørgsler til at spore ændringerne i vores database.
Efter at have tilføjet 1.000 rækker i foredragstabellen, kører vi igen forespørgslen fra "Table Sizes and Properties ” afsnit. Det vil returnere følgende resultat:
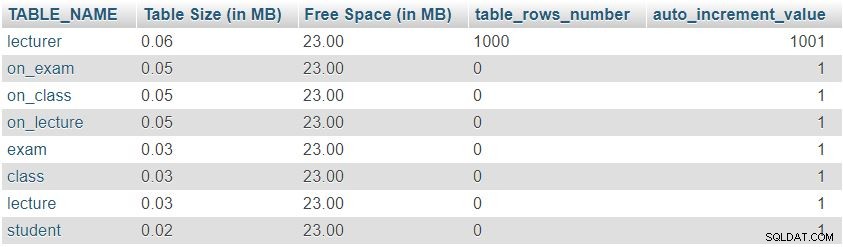
Vi kan nemt bemærke, at antallet af rækker og auto_increment-værdier har ændret sig som forventet, men der var ingen væsentlig ændring i tabelstørrelsen.
Dette var blot et testeksempel; i virkelige situationer vil vi bemærke betydelige ændringer. Antallet af rækker vil ændre sig drastisk i tabeller udfyldt af brugere eller automatiserede processer (dvs. tabeller, der ikke er ordbøger). At tjekke størrelsen af og værdierne i sådanne tabeller er en meget god måde til hurtigt at finde og rette uønsket adfærd.
Vil du dele?
At arbejde med databaser er en konstant stræben efter optimal ydeevne. For at få mere succes i denne forfølgelse bør du bruge ethvert tilgængeligt værktøj. I dag har vi set et par forespørgsler, der er nyttige i vores kamp for bedre ydeevne. Har du fundet andet brugbart? Har du spillet med INFORMATION_SCHEMA database før? Del din oplevelse i kommentarerne nedenfor.