Det kan være svært at implementere en brugervenlig søgning, men det kan også gøres meget effektivt. Hvordan ved jeg det? For ikke længe siden havde jeg brug for at implementere en søgemaskine på en mobilapp. Appen blev bygget på den ioniske ramme og ville oprette forbindelse til en CakePHP 2-backend. Ideen var at vise resultater, mens brugeren skrev. Der var flere muligheder for dette, men ikke alle opfyldte mit projekts krav.
For at illustrere, hvad denne slags opgave indebærer, lad os forestille os at søge efter sange og deres mulige relationer (såsom kunstnere, albums osv.).
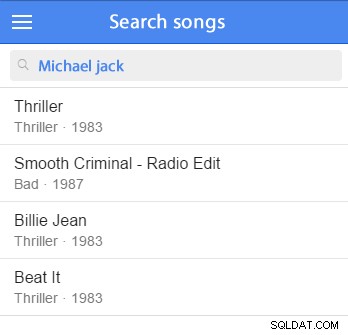
Posterne skulle sorteres efter relevans, hvilket ville afhænge af, om søgeordet matchede felter fra selve posten eller fra andre kolonner i relaterede tabeller. Desuden bør søgningen implementere mindst nogle grundlæggende ordstammer. (Stammen bruges til at få rodformen for et ord. "Stængler", "stammer", "stammer" og "stammer" har alle den samme rod:"stamme".)
Den fremgangsmåde, der præsenteres her, blev testet med flere hundrede tusinde poster og var i stand til at hente nyttige resultater, mens brugeren skrev.
Fuldtekstsøgeprodukter at overveje
Der er flere måder, vi kan implementere denne form for søgning på. Vores projekt havde nogle begrænsninger i forhold til tid og serverressourcer, så vi var nødt til at holde løsningen så enkel som muligt. Et par kandidater dukkede til sidst op:
Elasticsearch
Elasticsearch giver fuldtekstsøgninger i en dokumentorienteret tjeneste. Det er designet til at håndtere enorme mængder belastning på en distribueret måde:det kan rangere resultater efter relevans, udføre sammenlægninger og arbejde med ordstammer og synonymer. Dette værktøj er beregnet til realtidssøgninger. Fra deres hjemmeside:
Elasticsearch bygger distribuerede muligheder oven på Apache Lucene for at give de mest kraftfulde fuldtekstsøgningsmuligheder, der er tilgængelige. Kraftfuld, udviklervenlig forespørgsels-API understøtter flersproget søgning, geolokalisering, kontekstuelle, mente-du-forslag, autofuldførelse og resultatuddrag.
Elasticsearch kan fungere som en REST-tjeneste, svare på http-forespørgsler, og den kan sættes op meget hurtigt. Men at starte motoren som en service kræver, at du har nogle serveradgangsrettigheder. Og hvis din hostingudbyder ikke understøtter Elasticsearch ud af boksen, skal du installere nogle pakker.
Den nederste linje er, at dette produkt er en god mulighed, hvis du ønsker en bundsolid søgeløsning. (Bemærk:Du har muligvis brug for en VPS eller dedikeret server, da hardwarekravene er ret krævende.)
Sphinx
Ligesom Elasticsearch leverer Sphinx også et meget solidt fuldtekstsøgeprodukt:Craigslist serverer mere end 300.000.000 forespørgsler om dagen med det. Sphinx giver ikke en indbygget RESTful-grænseflade. Det er implementeret i C, med et mindre hardware footprint end Elasticsearch (som er implementeret i Java og kan køre på ethvert OS med en jvm). Du skal også have root-adgang til serveren med noget dedikeret RAM/CPU for at køre Sphinx korrekt.
MySQL fuldtekstsøgning
Historisk set blev fuldtekstsøgninger understøttet i MyISAM-motorer. Efter version 5.6 understøttede MySQL også fuldtekstsøgninger i InnoDB-lagringsmotorer. Dette har været gode nyheder, da det gør det muligt for udviklere at drage fordel af InnoDBs referenceintegritet, evne til at udføre transaktioner og rækkeniveaulåse.
Der er grundlæggende to tilgange til fuldtekstsøgninger i MySQL:naturligt sprog og boolsk tilstand. (En tredje mulighed forstærker den naturlige sprogsøgning med en anden udvidelsesforespørgsel.)
Den største forskel mellem den naturlige og booleske tilstand er, at boolean tillader visse operatører som en del af søgningen. For eksempel kan booleske operatorer bruges, hvis et ord har større relevans end andre i forespørgslen, eller hvis et specifikt ord skal være til stede i resultaterne osv. Det er værd at bemærke, at resultaterne i begge tilfælde kan sorteres efter relevansen beregnet af MySQL under søgningen.
Sådan træffer du beslutningerne
Den bedste løsning til vores problem var at bruge InnoDb fuldtekstsøgninger i boolsk tilstand. Hvorfor?
- Vi havde lidt tid til at implementere søgefunktionen.
- På dette tidspunkt havde vi ingen store data at knuse eller en massiv belastning til at kræve noget som Elasticsearch eller Sphinx.
- Vi brugte delt hosting, der ikke understøtter Elasticsearch eller Sphinx, og hardwaren var ret begrænset på dette tidspunkt.
- Selvom vi ønskede ordstammer i vores søgefunktion, var det ikke en deal breaker:vi kunne implementere det (inden for begrænsninger) ved hjælp af en simpel PHP-kodning og datadenormalisering
- Fuldtekstsøgninger i boolesk tilstand kan søge efter ord med jokertegn (for ordstammen) og sortere resultaterne baseret på relevans.
Fuld tekstsøgning i boolesk tilstand
Som nævnt før, er naturlig sprogsøgning den enkleste tilgang:søg blot efter en sætning eller et ord i kolonnerne, hvor du har sat et fuldtekstindeks, og du vil få resultater sorteret efter relevans.
I den normaliserede Vertabelo-model
Lad os se, hvordan en simpel søgning ville fungere. Vi opretter først en prøvetabel:
-- Skabt af Vertabelo (https://vertabelo.com)-- Sidste ændringsdato:2016-04-25 15:01:22.153-- tabeller-- Tabel:artistsCREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, navn varchar(255) IKKE NULL, biotekst IKKE NULL, CONSTRAINT artists_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX artists_idx_1 ON artists (navn);-- Slut på fil.
I naturlig sprogtilstand
Du kan indsætte nogle eksempeldata og begynde at teste. (Det ville være godt at tilføje det til dit eksempeldatasæt.) For eksempel vil vi prøve at søge efter Michael Jackson:
VÆLG *FRA artister WHERE MATCH (artists.name) MOD ('Michael Jackson' I NATURAL LANGUAGE MODE) Denne forespørgsel vil finde poster, der matcher søgetermerne, og vil sortere matchende poster efter relevans; jo bedre match, jo mere relevant er det, og jo højere vil resultatet blive vist på listen.
I boolsk tilstand
Vi kan udføre den samme søgning i boolsk tilstand. Hvis vi ikke anvender nogen operatorer på vores forespørgsel, vil den eneste forskel være, at resultaterne ikke er sorteret efter relevans:
VÆLG *FRA artister WHERE MATCH (artists.name) MOD ('Michael Jackson' I BOOLEAN MODE) Jokertegn-operatoren i boolsk tilstand
Da vi ønsker at søge på stammende ord og delord, skal vi bruge jokertegnsoperatøren (*). Denne operator kan bruges i søgninger i boolesk tilstand, hvorfor vi valgte denne tilstand.
Så lad os frigøre kraften ved boolesk søgning og prøve at søge efter en del af kunstnerens navn. Vi bruger jokertegn-operatøren til at matche enhver kunstner, hvis navn starter med 'Mich':
VÆLG *FRA kunstnere WHERE MATCH (navn) MOD ('Mich*' I BOOLEAN MODE) Sortering efter relevans i boolsk tilstand
Lad os nu se den beregnede relevans for søgningen. Dette vil hjælpe os med at forstå den sortering, vi vil foretage senere med Cake:
VÆLG *, MATCH (navn) MOD ('mich*' I BOOLEAN MODE) SOM rangFRA artister WHERE MATCH (navn) MOD ('mich*' I BOOLEAN MODE)ORDER BY rank DESC Denne forespørgsel henter søgeresultater og den relevansværdi, som MySQL beregner for hver post. Motoroptimeringsværktøjet vil registrere, at vi vælger relevansen, så det vil ikke genere at genberegne rangeringen.
Ordstammer i fuldtekstsøgning
Når vi inkorporerer ordstammer i en søgning, bliver søgningen mere brugervenlig. Selvom resultatet ikke er et ord i sig selv, forsøger algoritmer at generere den samme rod for afledte ord. For eksempel er stammen "argu" ikke et engelsk ord, men den kan bruges som stammen for "argument", "argued", "argues", "arguing", "Argus" og andre ord.
Stemming forbedrer resultaterne, da brugeren kan indtaste et ord, der ikke har nogen nøjagtig match, men dets "stamme" gør. Selvom PHP stemmer eller Snowballs Python stemmer kunne være en mulighed (hvis du har root SSH adgang til din server), vil vi bruge PorterStemmer.php klassen.
Denne klasse implementerer algoritmen foreslået af Martin Porter til at stamme ord på engelsk. Som angivet af forfatteren på hans websted, er det gratis at bruge til ethvert formål. Bare slip filen i din Vendors-mappe i CakePHP, inkluder biblioteket i din model, og kald den statiske metode for at stamme et ord:
//inkluder biblioteket (skal hedde PorterStemmer.php) i CakePHP's Vendors folderApp::import('Vendor', 'PorterStemmer'); //stamme et ord (ord skal stammes et efter et) echo PorterStemmer::Stem(‘stemming’); //output vil være 'stamme' Vores mål er at gøre søgning hurtig og effektiv og være i stand til at sortere resultater efter deres fuldtekstrelevans. For at gøre dette skal vi bruge ordstamming på to måder:
- Ordene indtastet af brugeren
- Sangrelaterede data (som vi gemmer i kolonner og sorterer efter resultater baseret på relevans)
Den første type ordstamming kan udføres på denne måde:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /fjern uønskede tegn$words =explode(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words as $word) { $stemmedSearch .=PorterStemmer::Stem($ ord). "* ";//vi tilføjer jokertegnet efter hvert ord $unstemmedSearch =$word . "* ";//for at søge i kunstnerkolonnen, der ikke stammer}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //ellers vil mySql klage, da du ikke kan bruge jokertegnet alene $stemmedSearch =""; $unstemmedSearch ="";} Vi har oprettet to strenge:en til at søge efter kunstnernavnet (uden stamme), og en til at søge i de andre stammerkolonner. Dette vil hjælpe os senere med at bygge vores 'mod' del af fuldtekstforespørgslen. Lad os nu se, hvordan vi kan stemple og sortere sangens data.
Denormalisering af sangdata
Vores sorteringskriterier vil være baseret på at matche sangens kunstner (uden stemming) først. Dernæst kommer sangens navn, album og relaterede kategorier. Stemming vil blive brugt på alle de sekundære søgekriterier.
For at illustrere dette, antag, at jeg søger efter 'nirvana', og der er en sang kaldet 'Nirvana Games' af 'XYZ', og en anden sang kaldet 'Polly' af kunstneren 'Nirvana'. Resultaterne bør angive 'Polly' først, da match på kunstnernavnet er vigtigere end et match på sangnavnet (baseret på mine kriterier).
For at gøre dette tilføjede jeg 4 felter i songs tabel, en for hvert af de søge-/sorteringskriterier, vi ønsker:
ALTER TABLE `sange` ADD `denorm_artist` VARCHAR(255) NOT NULL EFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL EFTER`denorm_artist`, TILFØJ `denorm_album` VARCHAR(255) NOT NULL EFTER denorm_trackname`,ADD `denorm_categories` VARCHAR(500) IKKE NULL EFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_kategorier`);
Vores komplette databasemodel ville se sådan ud:
Når du gemmer en sang ved hjælp af add/edit i CakePHP, skal du blot gemme kunstnernavnet i kolonnen denorm_artist uden at dæmme op for det. Tilføj derefter det stammende spornavn i denorm_trackname felt (svarende til, hvad vi gjorde i den søgte tekst) og gem det stammede albums navn i denorm_album kolonne. Til sidst skal du gemme stammekategorien for sangen i denorm_categories felt, sammenkæde ordene og tilføje et mellemrum mellem hvert stammet kategorinavn.
Fuld tekstsøgning og relevanssortering i CakePHP
Fortsætter med eksemplet med at søge efter 'Nirvana', lad os se, hvad en forespørgsel, der ligner denne, kan opnå:
VÆLG nummernavn, MATCH(denorm_artist) MOD ('Nirvana*' I BOOLEAN MODE) som rang1, MATCH(denorm_trackname) AGAINST ('Nirvana*' I BOOLEAN MODE) som rang2, MATCH(denorm_album) MOD ('Nirvana*' I BOOLEAN MODE) som rang3, MATCH(denorm_categories) AGAINST ('Nirvana*' I BOOLEAN MODE) som rang4 FRA sange WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' I BOOLEAN MODE) OR MATCH(denorm_trackname) MODE ('N ' I BOOLEAN MODE) OR MATCH(denorm_album) AGAINST ('Nirvana*' I BOOLEAN MODE) OR MATCH(denorm_categories) AGAINST ('Nirvana*' I BOOLEAN MODE) ORDEN EFTER rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC Vi ville få følgende output:
| spornavn | rang1 | rang 2 | rang 3 | rang 4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| nirvana-spil | 0 | 0,0906190574169159 | 0 | 0 |
For at gøre dette i CakePHP, find metode skal kaldes ved hjælp af en kombination af 'felter', 'betingelser' og 'ordre' parametre. Fortsætter med den tidligere PHP-eksempelkode:
//within Song.php model file $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) MOD ({$unstemmedSearch} I BOOLEAN MODE) as `rank1`", "MATCH(Song. denorm_trackname) MOD ({$stemmedSearch} I BOOLEAN MODE) som `rank2`", "MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} I BOOLEAN MODE) as `rank3`", "MATCH(Song.denorm_categories) AGAINST ( {$stemmedSearch} I BOOLEAN MODE) as `rang4`" );$order ="`rang1` DESC,`rang2` DESC,`rang3`DESC,`rang4`DESC,Sang.spornavn ASC";$betingelser =array( "ELLER" => array( "MATCH(Sang.denorm_artist) MOD ({$unstemmedSearch} I BOOLEAN MODE)", "MATCH(Song.denorm_trackname) MOD ({$stemmedSearch} I BOOLEAN MODE)", "MATCH(Sang. denorm_album) MOD ({$stemmedSearch} I BOOLEAN MODE)", "MATCH(Song.denorm_categories) MOD ({$stemmedSearch} I BOOLEAN MODE)" );$results =$this->find ('all',array('conditions'=>$conditions,'fields'=>$fields,'order'=>$order); $results vil være rækken af sange sorteret efter de kriterier, vi definerede tidligere.
Denne løsning kan bruges til at generere søgninger, der er meningsfulde for brugeren – uden at det kræver for meget tid fra udviklerne eller tilføjer større kompleksitet til koden.
Gør CakePHP-søgninger endnu bedre
Det er værd at nævne, at at "krydre" de denormaliserede kolonner med flere data kan føre til bedre resultater.
Ved at "krydre" mener jeg, at du i de denormaliserede kolonner kunne inkludere flere data fra yderligere kolonner, som du anser for nyttige med det formål at gøre resultaterne mere relevante, for eksempel hvis du vidste, at en kunstners land kunne indgå i søgetermerne, kunne tilføje landet sammen med kunstnernavnet i denorm_artist kolonne. Dette ville forbedre kvaliteten af søgeresultaterne.
Fra min erfaring (afhængigt af de faktiske data, du bruger, og de kolonner, du denormaliserer) har de øverste resultater en tendens til at være virkelig nøjagtige. Dette er fantastisk til mobilapps, da det kan være frustrerende for brugeren at rulle ned ad en lang liste.
Endelig, hvis du har brug for at få flere data fra de tabeller, som sangen relaterer til, kan du altid oprette en join og få kunstneren, kategorier, album, sangkommentarer osv. Hvis du bruger CakePHP's indholdsbare adfærdsfilter, vil jeg gerne foreslå at tilføje EagerLoader-plugin'et for at udføre sammenføjningerne effektivt.
Hvis du har din egen tilgang til at implementere fuldtekstsøgning, så del den i kommentarerne nedenfor. Vi kan alle lære af hinandens erfaringer.