Python er meget populær i disse dage. Da Python er et alment programmeringssprog, kan det også bruges til at udføre Extract, Transform, Load (ETL) processen. Forskellige ETL-moduler er tilgængelige, men i dag holder vi os til kombinationen af Python og MySQL. Vi bruger Python til at fremkalde lagrede procedurer og forberede og udføre SQL-sætninger.
Vi vil bruge to lignende, men forskellige tilgange. Først vil vi påberåbe os lagrede procedurer, der vil gøre hele jobbet, og derefter analyserer vi, hvordan vi kunne gøre den samme proces uden lagrede procedurer ved at bruge MySQL-kode i Python.
Parat? Før vi graver ind, lad os se på datamodellen – eller datamodeller, da der er to af dem i denne artikel.
Datamodellerne
Vi skal bruge to datamodeller, en til at gemme vores driftsdata og den anden til at gemme vores rapporteringsdata.
Den første model er vist på billedet ovenfor. Denne model bruges til at gemme operationelle (live) data for en abonnementsbaseret virksomhed. For mere indsigt i denne model, se venligst vores tidligere artikel, Creating a DWH, Part One:A Subscription Business Data Model.
At adskille drifts- og rapporteringsdata er normalt en meget klog beslutning. For at opnå denne adskillelse skal vi oprette et datavarehus (DWH). Det gjorde vi allerede; du kan se modellen på billedet ovenfor. Denne model er også beskrevet detaljeret i indlægget Creating a DWH, Part Two:A Subscription Business Data Model.
Til sidst skal vi udtrække data fra livedatabasen, transformere dem og indlæse dem i vores DWH. Vi har allerede gjort dette ved at bruge SQL-lagrede procedurer. Du kan finde en beskrivelse af, hvad vi ønsker at opnå sammen med nogle kodeeksempler i Creating a Data Warehouse, Del 3:A Subscription Business Data Model.
Hvis du har brug for yderligere information om DWH'er, anbefaler vi at læse disse artikler:
- Stjerneskemaet
- Snefnugskemaet
- Stjerneskema vs. snefnugskema.
Vores opgave i dag er at erstatte SQL-lagrede procedurer med Python-kode. Vi er klar til at lave noget Python-magi. Lad os starte med kun at bruge lagrede procedurer i Python.
Metode 1:ETL ved hjælp af lagrede procedurer
Før vi begynder at beskrive processen, er det vigtigt at nævne, at vi har to databaser på vores server.
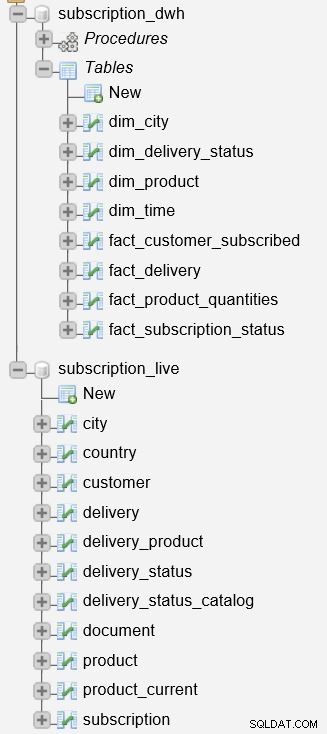
subscription_live databasen bruges til at gemme transaktions-/livedata, mens subscription_dwh er vores rapporteringsdatabase (DWH).
Vi har allerede beskrevet de lagrede procedurer, der bruges til at opdatere dimensions- og faktatabeller. De vil læse data fra subscription_live databasen, kombinere den med data i subscription_dwh database, og indsæt nye data i subscription_dwh database. Disse to procedurer er:
p_update_dimensions– Opdaterer dimensionstabellernedim_timeogdim_city.p_update_facts– Opdaterer to faktatabeller,fact_customer_subscribedogfact_subscription_status.
Hvis du vil se den komplette kode for disse procedurer, skal du læse Oprettelse af et datavarehus, del 3:En abonnementsforretningsdatamodel.
Nu er vi klar til at skrive et simpelt Python-script, der forbinder til serveren og udfører ETL-processen. Lad os først tage et kig på hele scriptet (etl_procedures.py ). Så forklarer vi de vigtigste dele.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Import af moduler og tilslutning til databasen
Python bruger moduler til at gemme definitioner og udsagn. Du kan bruge et eksisterende modul eller skrive dit eget. Brug af eksisterende moduler vil forenkle dit liv, fordi du bruger forudskrevet kode, men at skrive dit eget modul er også meget nyttigt. Når du afslutter Python-fortolkeren og kører den igen, mister du funktioner og variabler, du tidligere har defineret. Selvfølgelig vil du ikke skrive den samme kode igen og igen. For at undgå det kan du gemme dine definitioner i et modul og importere det til Python.
Tilbage til etl_procedures.py . I vores program starter vi med at importere MySQL Connector:
# import MySQL connector import mysql.connector
MySQL Connector til Python bruges som en standardiseret driver, der forbinder til en MySQL server/database. Du skal downloade det og installere det, hvis du ikke tidligere har gjort det. Udover at oprette forbindelse til databasen, tilbyder den en række metoder og egenskaber til at arbejde med en database. Vi vil bruge nogle af dem, men du kan tjekke den komplette dokumentation her.
Dernæst skal vi oprette forbindelse til vores database:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
Den første linje vil oprette forbindelse til en server (i dette tilfælde opretter jeg forbindelse til min lokale maskine) ved hjælp af dine legitimationsoplysninger (erstat
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Jeg har med vilje kun oprettet forbindelse til en server og ikke til en bestemt database, fordi jeg vil bruge to databaser placeret på den samme server.
Den næste kommando – print – er her blot en meddelelse om, at vi blev tilsluttet. Selvom det ikke har nogen programmeringsmæssig betydning, kan det bruges til at fejlsøge koden, hvis noget gik galt i scriptet.
Den sidste linje i denne del er:
cursor =connection.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Opkaldsprocedurer
Den forrige del var generel og kunne bruges til andre databaserelaterede opgaver. Følgende del af koden er specifikt til ETL:kalder vores lagrede procedurer med cursor.callproc kommando. Det ser sådan ud:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Opkaldsprocedurer er stort set selvforklarende. Efter hvert opkald blev der tilføjet en printkommando. Igen giver dette os bare en notifikation om, at alt gik okay.
Bekræft og luk
Den sidste del af scriptet forpligter databaseændringerne og lukker alle brugte objekter:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Opkaldsprocedurer er stort set selvforklarende. Efter hvert opkald blev der tilføjet en printkommando. Igen giver dette os bare en notifikation om, at alt gik okay.
Forpligtelse er afgørende her; uden det vil der ikke være nogen ændringer i databasen, selvom du kaldte en procedure eller udførte en SQL-sætning.
Kørsel af scriptet
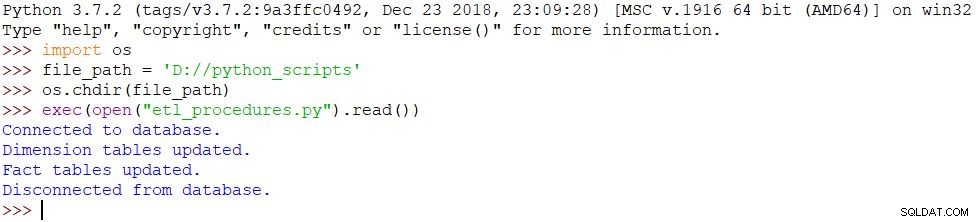
Den sidste ting vi skal gøre er at køre vores script. Vi bruger følgende kommandoer i Python Shell for at opnå det:
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())Scriptet udføres, og alle ændringer foretages i databasen i overensstemmelse hermed. Resultatet kan ses på billedet nedenfor.
Metode 2:ETL ved hjælp af Python og MySQL
Den ovenfor præsenterede tilgang adskiller sig ikke meget fra tilgangen til at kalde lagrede procedurer direkte i MySQL. Den eneste forskel er, at nu har vi et manuskript, der vil gøre hele arbejdet for os.
Vi kunne bruge en anden tilgang:at sætte alt inde i Python-scriptet. Vi inkluderer Python-sætninger, men vi forbereder også SQL-forespørgsler og udfører dem på databasen. Kildedatabasen (live) og destinationsdatabasen (DWH) er de samme som i eksemplet med lagrede procedurer.
Før vi dykker ned i dette, lad os tage et kig på det komplette script (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Import af moduler og tilslutning til databasen
Endnu en gang bliver vi nødt til at importere MySQL ved hjælp af følgende kode:
import mysql.connector
Vi importerer også datetime-modulet, som vist nedenfor. Vi har brug for dette til dato-relaterede operationer i Python:
from datetime import date
Processen for at oprette forbindelse til databasen er den samme som i det foregående eksempel.
Opdatering af dim_time-dimensionen
For at opdatere dim_time tabel, bliver vi nødt til at kontrollere, om værdien (for i går) allerede er i tabellen. Vi bliver nødt til at bruge Pythons datofunktioner (i stedet for SQL's) for at gøre dette:
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
Den første kodelinje returnerer gårsdagens dato i datovariablen, mens den anden linje gemmer denne værdi som en streng. Vi skal bruge denne som en streng, fordi vi sammenkæder den med en anden streng, når vi bygger SQL-forespørgslen.
Dernæst skal vi teste, om denne dato allerede er i dim_time bord. Efter at have erklæret en markør, forbereder vi SQL-forespørgslen. For at udføre forespørgslen bruger vi cursor.execute kommando:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
Vi gemmer forespørgselsresultatet i resultatet variabel. Resultatet vil have enten 0 eller 1 rækker, så vi kan teste den første kolonne i den første række. Det vil indeholde enten et 0 eller et 1. (Husk, vi kan kun have den samme dato én gang i en dimensionstabel.)
Hvis datoen ikke allerede er i tabellen, forbereder vi de strenge, der vil være en del af SQL-forespørgslen:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Til sidst bygger vi en forespørgsel og udfører den. Dette vil opdatere dim_time tabel, efter at den er begået. Bemærk venligst, at jeg har brugt hele stien til tabellen, inklusive databasenavnet (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
Opdater dim_city-dimensionen
Opdatering af dim_city tabellen er endnu enklere, fordi vi ikke behøver at teste noget før indsatsen. Vi vil faktisk inkludere den test i SQL-forespørgslen.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Her forbereder vi en eksekvering af SQL-forespørgslen. Bemærk, at jeg igen har brugt de fulde stier til tabeller, inklusive navnene på begge databaser (subscription_live og subscription_dwh ).
Opdatering af faktatabellerne
Det sidste, vi skal gøre, er at opdatere vores faktatabeller. Processen er næsten den samme som at opdatere dimensionstabeller:Vi forbereder forespørgsler og udfører dem. Disse forespørgsler er meget mere komplekse, men de er de samme som dem, der bruges i de lagrede procedurer.
Vi har tilføjet én forbedring i forhold til de lagrede procedurer:sletning af eksisterende data for samme dato i faktatabellen. Dette giver os mulighed for at køre et script flere gange på samme dato. Til sidst skal vi forpligte transaktionen og lukke alle objekter og forbindelsen.
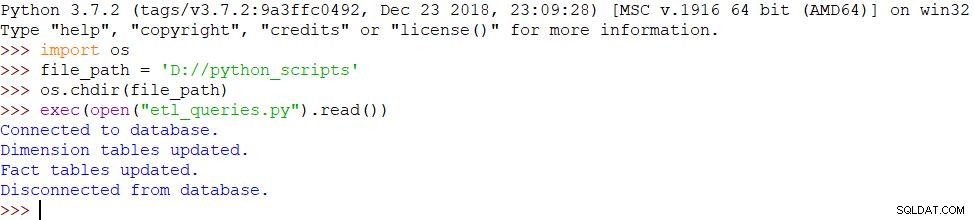
Kørsel af scriptet
Vi har en mindre ændring i denne del, som kalder et andet script:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
Fordi vi har brugt de samme beskeder, og scriptet er gennemført med succes, er resultatet det samme:
Hvordan ville du bruge Python i ETL?
I dag så vi et eksempel på at udføre ETL-processen med et Python-script. Der er andre måder at gøre dette på, f.eks. en række open source-løsninger, der bruger Python-biblioteker til at arbejde med databaser og udføre ETL-processen. I den næste artikel leger vi med en af dem. I mellemtiden er du velkommen til at dele din oplevelse med Python og ETL.