Enhver rentabel virksomhed kræver høj tilgængelighed. Hjemmesider og blogs er ikke anderledes, da selv mindre virksomheder og enkeltpersoner kræver, at deres websteder forbliver live for at bevare deres omdømme.
WordPress er langt det mest populære CMS i verden, der driver millioner af websteder fra små til store. Men hvordan kan du sikre, at din hjemmeside forbliver live. Mere specifikt, hvordan kan jeg sikre, at utilgængeligheden af min database ikke vil påvirke mit websted?
I dette blogindlæg viser vi, hvordan du opnår failover for dit WordPress-websted ved hjælp af ClusterControl.
Opsætningen vi vil bruge til denne blog vil bruge Percona Server 5.7. Vi vil have en anden vært, som indeholder Apache- og Wordpress-applikationen. Vi vil ikke røre ved applikationens højtilgængelighedsdel, men dette er også noget, du vil være sikker på at have. Vi vil bruge ClusterControl til at administrere databaser for at sikre tilgængeligheden, og vi vil bruge en tredje vært til at installere og opsætte selve ClusterControl.
Forudsat at ClusterControl er oppe og køre, bliver vi nødt til at importere vores eksisterende database til den.
Import af en databaseklynge med ClusterControl
Gå til Import Existing Server/Database-indstillingen i installationsguiden.
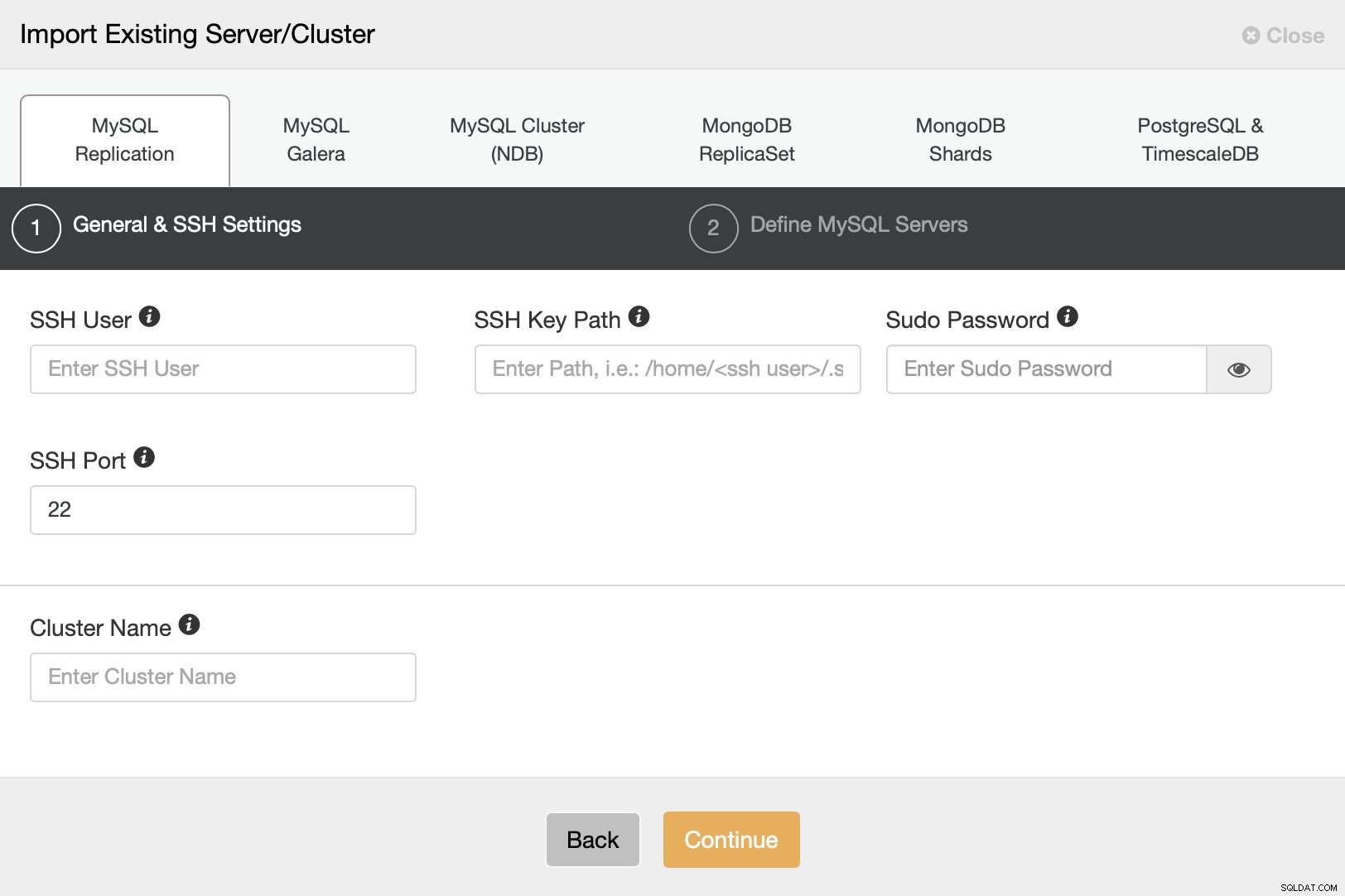
Vi er nødt til at konfigurere SSH-forbindelsen, da dette er et krav for ClusterControl at være i stand til at styre noderne.
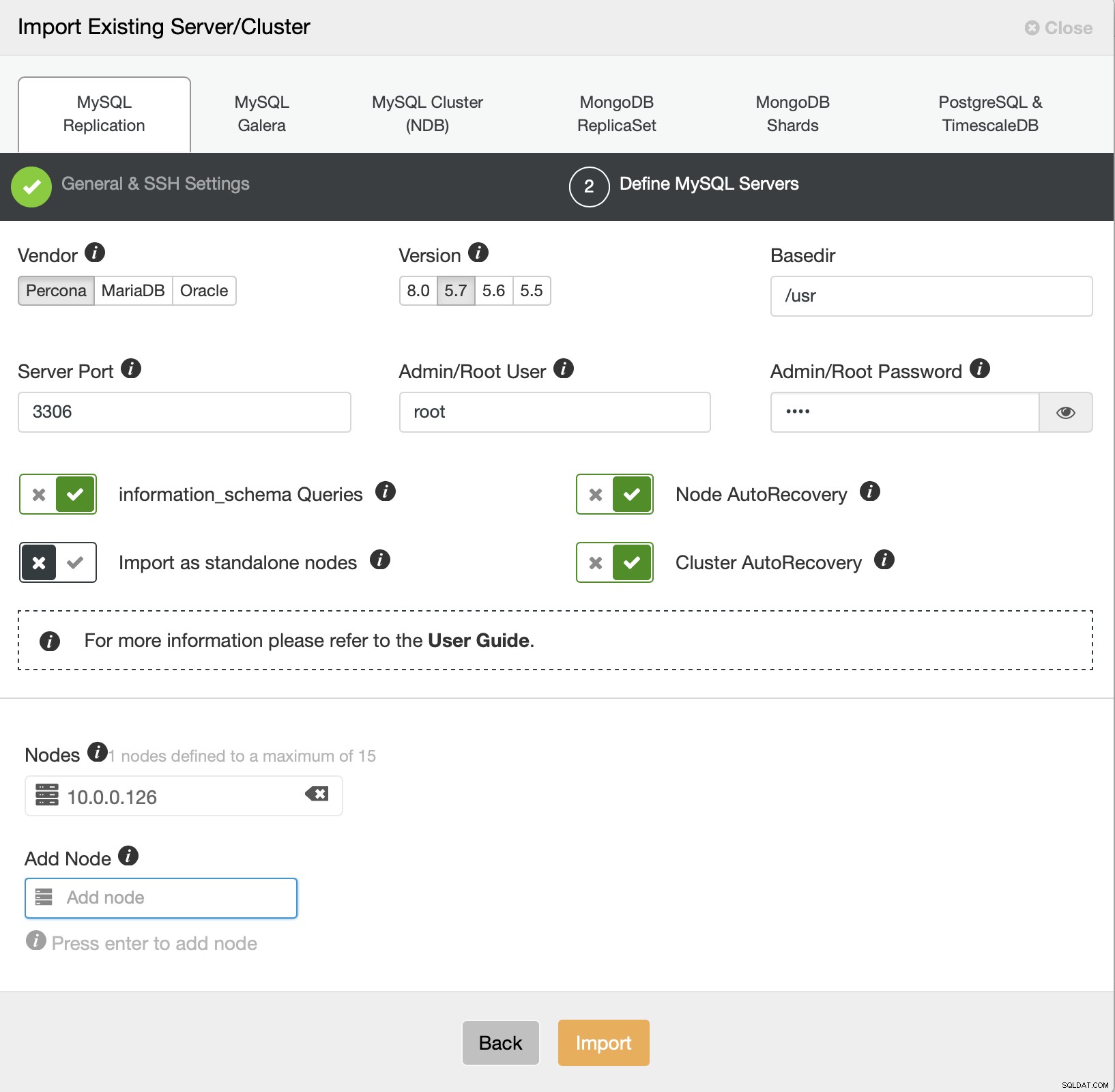
Vi skal nu definere nogle detaljer om leverandøren, versionen, root-brugeren adgang, selve noden, og om vi vil have ClusterControl til at administrere autogendannelse for os eller ej. Det er alt, når jobbet lykkes, vil du blive præsenteret for en klynge på listen.
For at konfigurere det meget tilgængelige miljø skal vi udføre et par af handlinger. Vores miljø vil bestå af...
- Master - Slave-par
- To ProxySQL-instanser til læse/skriveopdeling og topologidetektion
- To Keepalive-forekomster til virtuel IP-administration
Idéen er enkel - vi vil implementere slaven til vores mester, så vi vil have en anden instans at failover til, hvis masteren mislykkes. ClusterControl vil være ansvarlig for fejldetektion, og det vil fremme slaven, hvis masteren bliver utilgængelig. ProxySQL vil holde styr på replikeringstopologien, og den vil omdirigere trafikken til den korrekte node - skrivninger vil blive sendt til masteren, uanset hvilken node den er i, læsninger kan enten sendes til master-only eller distribueres på tværs af master og slaver . Endelig vil Keepalved blive samlokaliseret med ProxySQL, og det vil give VIP, som applikationen kan oprette forbindelse til. Denne VIP vil altid blive tildelt en af ProxySQL-instanserne, og Keepalived vil flytte den til den anden, hvis den "hoved" ProxySQL-knude svigter.
Når det er sagt, lad os konfigurere dette ved hjælp af ClusterControl. Det hele kan gøres med blot et par klik. Vi starter med at tilføje slaven.
Tilføjelse af en databaseslave med ClusterControl

Vi starter med at vælge "Tilføj replikeringsslave". Så bliver vi bedt om at udfylde en formular:
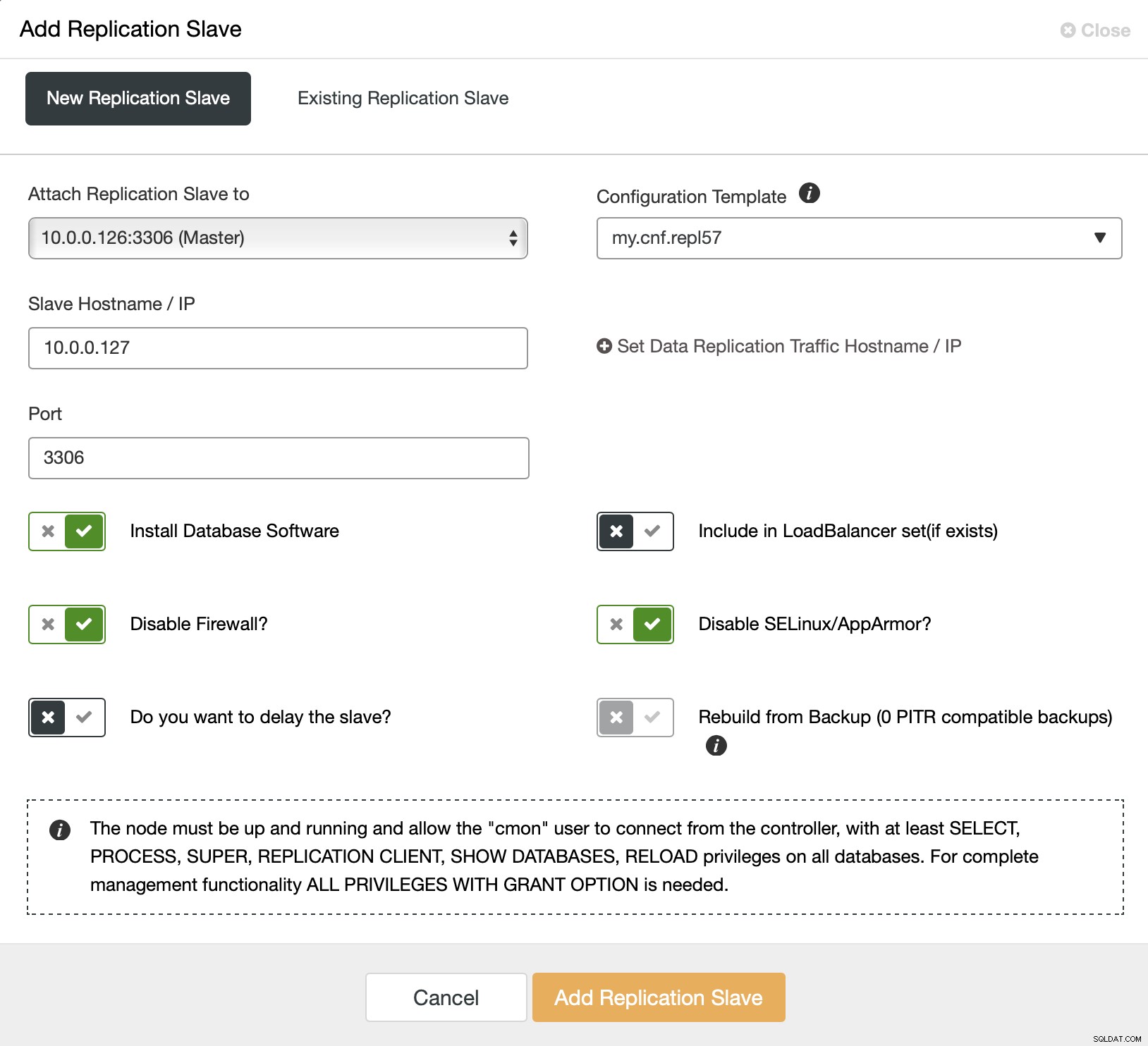
Vi skal vælge masteren (i vores tilfælde gør vi ikke rigtigt har mange muligheder), skal vi videregive IP eller værtsnavn for den nye slave. Hvis vi tidligere havde oprettet sikkerhedskopier, kunne vi bruge en af dem til at klargøre slaven. I vores tilfælde er dette ikke tilgængeligt, og ClusterControl vil levere slaven direkte fra masteren. Det er alt, jobbet starter, og ClusterControl udfører nødvendige handlinger. Du kan overvåge fremskridtene på fanen Aktivitet.

Endelig, når jobbet er fuldført, bør slaven være synlig på klyngeliste.

Nu fortsætter vi med at konfigurere ProxySQL-instanserne. I vores tilfælde er miljøet minimalt, så for at gøre tingene enklere, vil vi lokalisere ProxySQL på en af databasenoderne. Dette er dog ikke den bedste mulighed i et rigtigt produktionsmiljø. Ideelt set ville ProxySQL enten være placeret på en separat node eller samlokaliseret med de andre applikationsværter.
Stedet at starte jobbet er Administrer -> Loadbalancers.
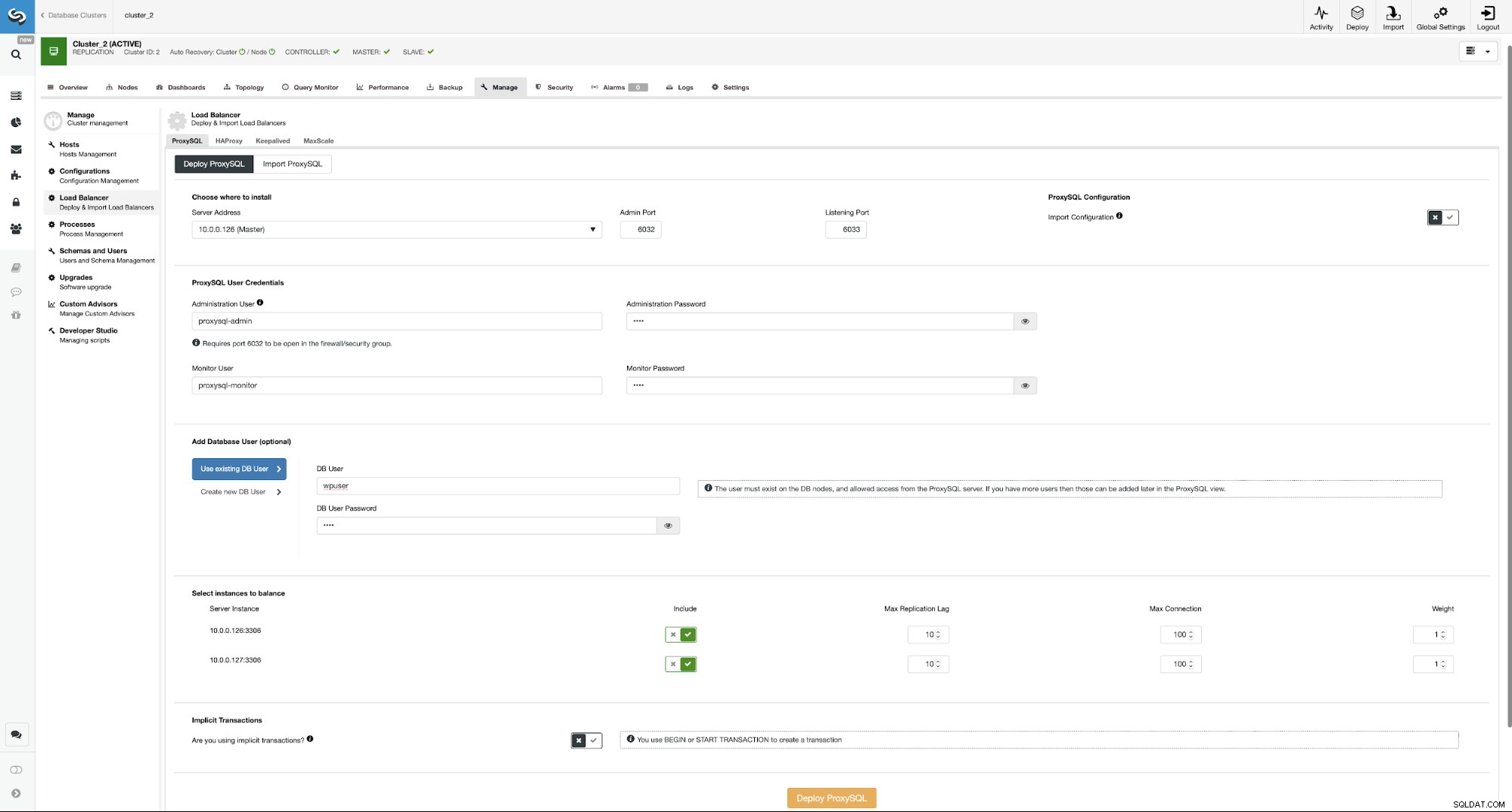
Her skal du vælge, hvor ProxySQL'en skal installeres, sende administrative legitimationsoplysninger , og tilføje en databasebruger. I vores tilfælde vil vi bruge vores eksisterende bruger, da vores WordPress-applikation allerede bruger den til at oprette forbindelse til databasen. Vi skal så vælge, hvilke noder der skal bruges i ProxySQL (vi ønsker både master og slave her) og lade ClusterControl vide, om vi bruger eksplicitte transaktioner eller ej. Dette er ikke rigtig relevant i vores tilfælde, da vi vil rekonfigurere ProxySQL, når det bliver implementeret. Når du har denne mulighed aktiveret, vil læse/skriveopdeling ikke være aktiveret. Ellers vil ClusterControl konfigurere ProxySQL til læse/skriveopdeling. I vores minimale opsætning bør vi seriøst tænke, om vi ønsker, at læse/skriveopdelingen skal ske. Lad os analysere det.
Fordelene og ulemperne ved læse-/skrivespyt i ProxySQL
Den største fordel ved at bruge læse/skrive-opdelingen er, at al SELECT-trafik vil blive fordelt mellem masteren og slaven. Det betyder, at belastningen på noderne bliver lavere, og responstiden bør også være lavere. Dette lyder godt, men husk, at hvis en node fejler, skal den anden node være i stand til at rumme al trafikken. Der er ingen mening i at have automatiseret failover på plads, hvis tabet af en knude betyder, at den anden knude vil blive overbelastet og de facto også utilgængelig.
Det kan måske give mening at fordele belastningen, hvis du har flere slaver - at miste en node ud af fem er mindre virkningsfuld end at miste en ud af to. Uanset hvad du beslutter dig for, kan du nemt ændre adfærden ved at gå til ProxySQL-knudepunktet og klikke på fanen Regler.
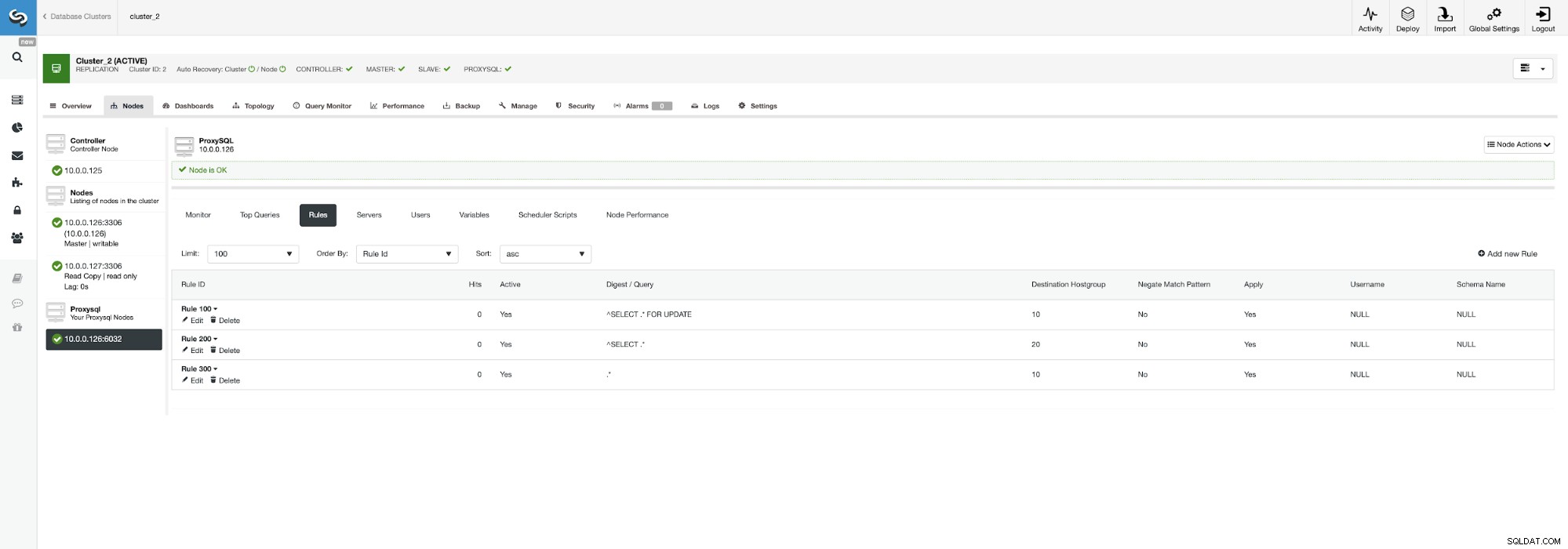
Sørg for at se på regel 200 (den der fanger alle SELECT-sætninger) ). På skærmbilledet nedenfor kan du se, at destinationsværtsgruppen er 20, hvilket betyder, at alle noder i klyngen - læse/skriveopdeling og skalering er aktiveret. Vi kan nemt deaktivere dette ved at redigere denne regel og ændre destinationsværtsgruppen til 10 (den, der indeholder master).
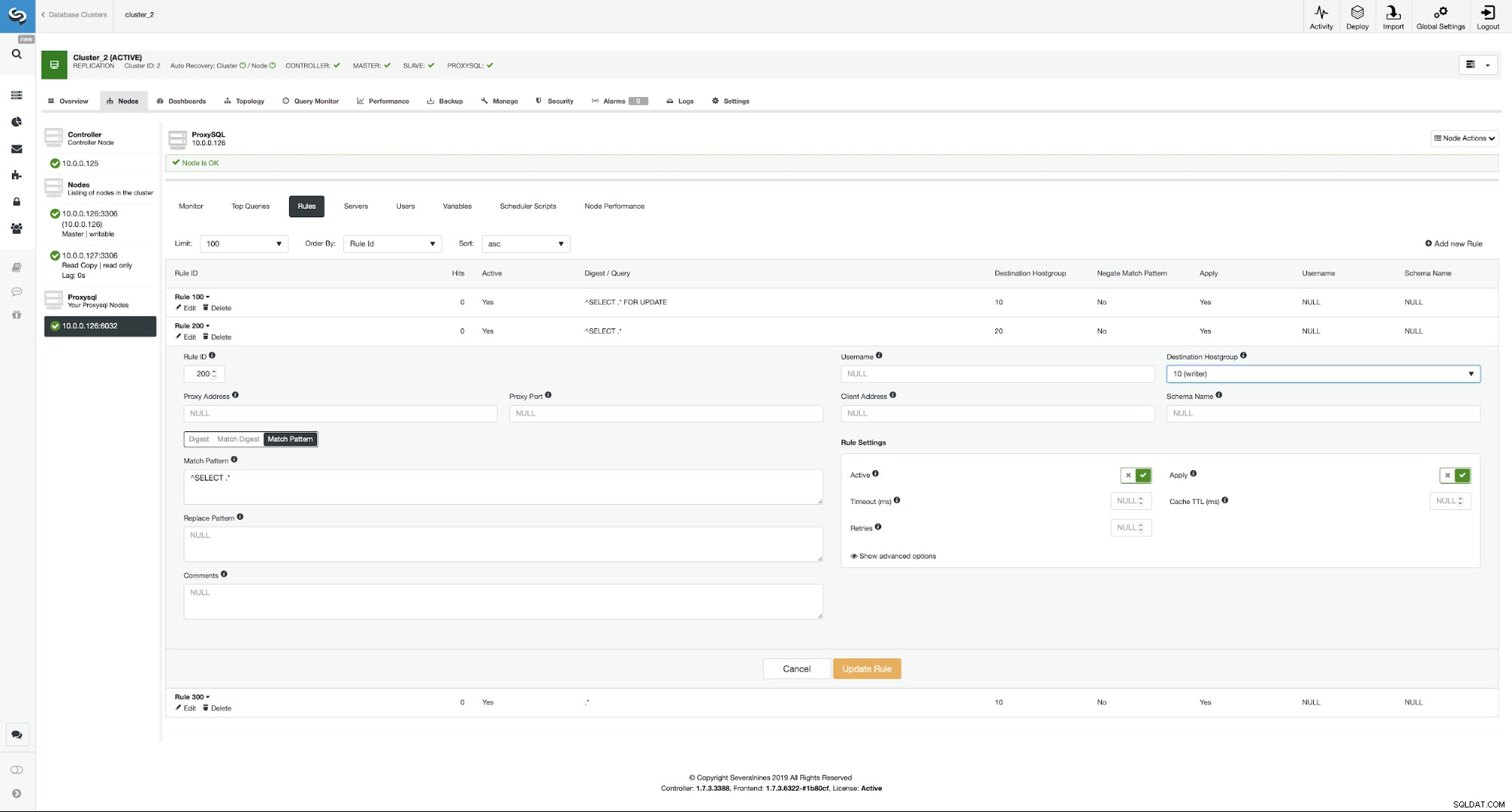
Hvis du gerne vil aktivere læse/skrive-opdelingen, kan du nemt gør det ved at redigere denne forespørgselsregel igen og sætte destinationsværtsgruppen tilbage til 20.
Lad os nu implementere anden ProxySQL.
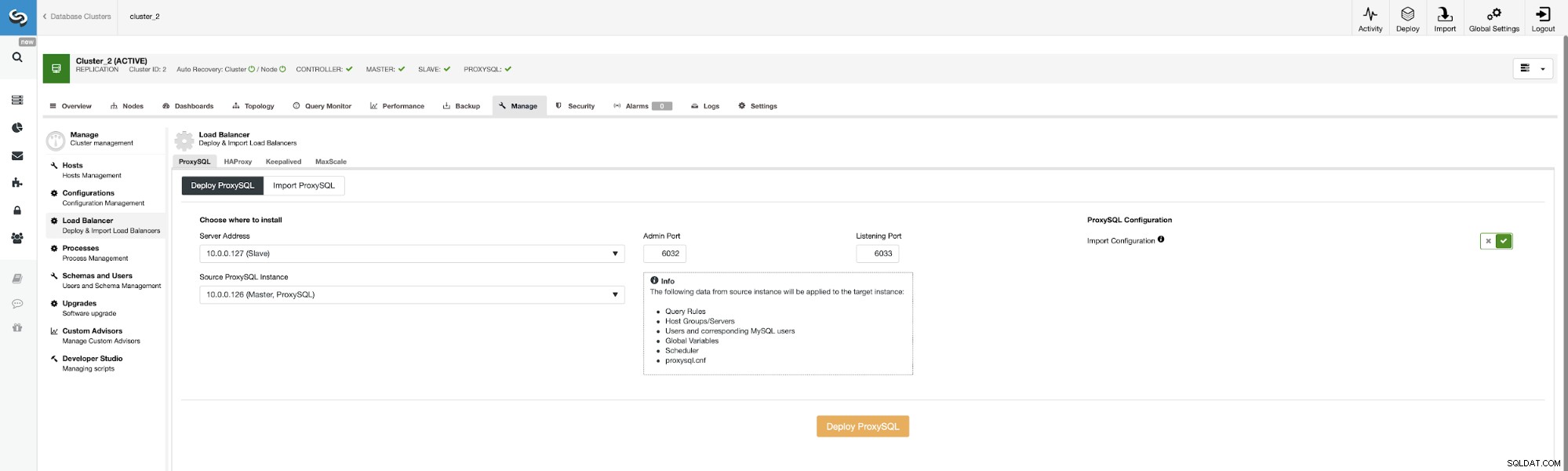
For at undgå at passere alle konfigurationsmulighederne igen kan vi bruge "Import Configuration" ” og vælg vores eksisterende ProxySQL som kilde.
Når dette job er fuldført, skal vi stadig udføre det sidste trin i indstillingen af vores miljø. Vi er nødt til at implementere Keepalived oven på ProxySQL-forekomsterne.
Implementering af Keepalived oven på ProxySQL-forekomster
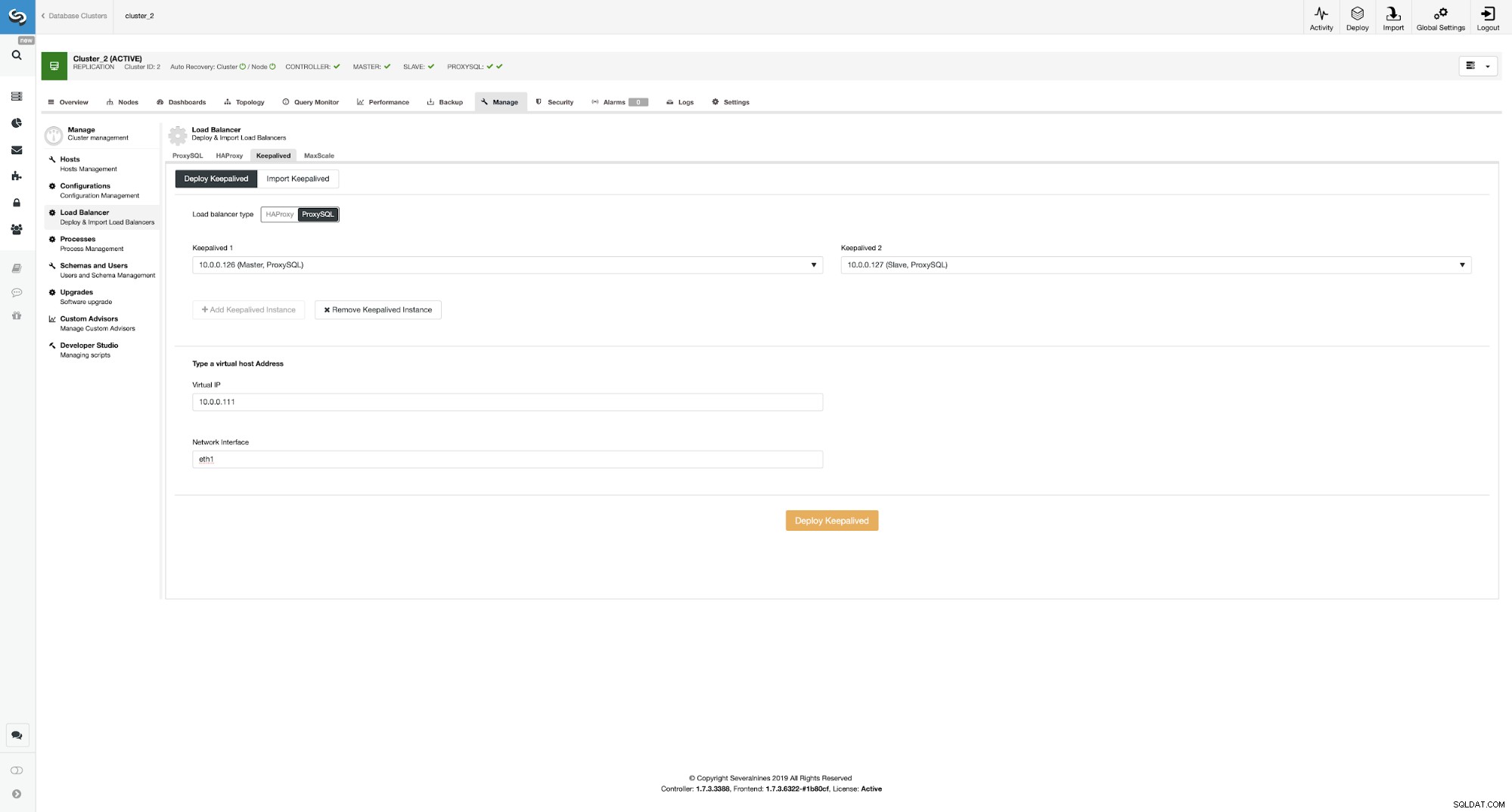
Her valgte vi ProxySQL som load balancer-typen, bestod begge ProxySQL-instanser for Keepalved skal installeres på, og vi skrev vores VIP- og netværksgrænseflade.
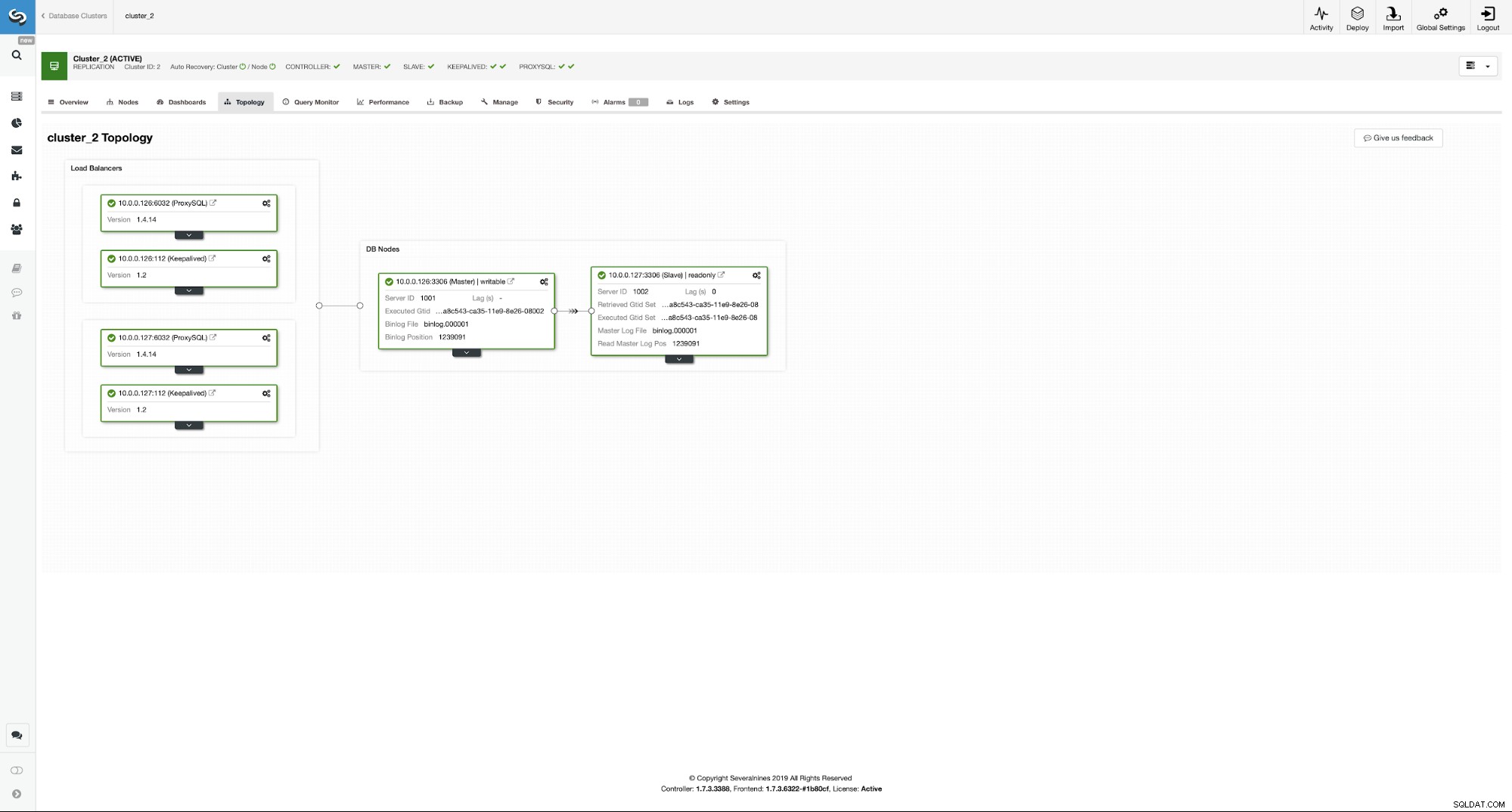
Som du kan se, har vi nu hele opsætningen klar. Vi har en VIP på 10.0.0.111, som er tildelt en af ProxySQL-instanserne. ProxySQL-instanser vil omdirigere vores trafik til de korrekte backend MySQL-noder, og ClusterControl vil holde øje med, at miljøet udfører failover, hvis det er nødvendigt. Den sidste handling, vi skal tage, er at omkonfigurere Wordpress til at bruge den virtuelle IP til at oprette forbindelse til databasen.
For at gøre det skal vi redigere wp-config.php og ændre DB_HOST-variablen til vores virtuelle IP:
/** MySQL hostname */
define( 'DB_HOST', '10.0.0.111' );Konklusion
Fra nu af vil Wordpress oprette forbindelse til databasen ved hjælp af VIP og ProxySQL. I tilfælde af at masternoden fejler, vil ClusterControl udføre failover.
Som du kan se, er ny master valgt og ProxySQL peger også mod ny master i værtsgruppen 10.
Vi håber, at dette blogindlæg giver dig en idé om, hvordan du designer et meget tilgængeligt databasemiljø til et Wordpress-websted, og hvordan ClusterControl kan bruges til at implementere alle dets elementer.