Amazon Aurora Serverless leverer en on-demand, automatisk skalerbar, meget tilgængelig, relationel database, som kun opkræver dig, når den er i brug. Det giver en relativt enkel, omkostningseffektiv mulighed for sjældne, intermitterende eller uforudsigelige arbejdsbelastninger. Det, der gør dette muligt, er, at det automatisk starter op, skalerer beregningskapaciteten til at matche din applikations brug og derefter lukker ned, når det ikke længere er nødvendigt.
Følgende diagram viser Aurora Serverless højniveauarkitektur.
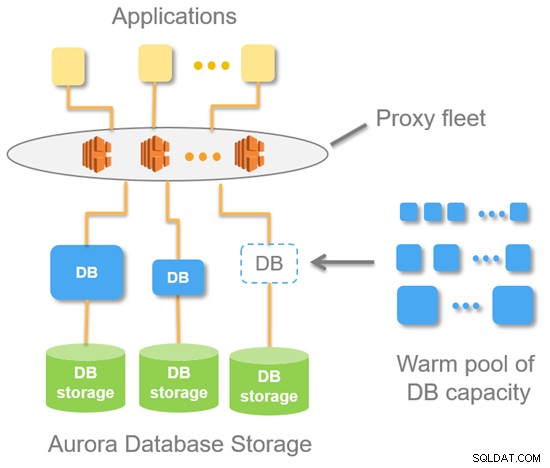
Med Aurora Serverless får du ét endepunkt (i modsætning til to endepunkter for den standard Aurora-provisionerede DB). Dette er dybest set en DNS-record bestående af en flåde af proxyer, som sidder oven på databaseinstansen. Fra et MySQL-serverpunkt betyder det, at forbindelserne altid kommer fra proxy-flåden.
Aurora Serverless Auto-Scaling
Aurora Serverless er i øjeblikket kun tilgængelig til MySQL 5.6. Du skal grundlæggende indstille minimum- og maksimumkapacitetsenheden for DB-klyngen. Hver kapacitetsenhed svarer til en specifik computer- og hukommelseskonfiguration. Aurora Serverless reducerer ressourcerne til DB-klyngen, når dens arbejdsbelastning er under disse tærskler. Aurora Serverless kan reducere kapaciteten til minimum eller øge kapaciteten til maksimal kapacitetsenhed.
Klyngen opskaleres automatisk, hvis en af følgende betingelser er opfyldt:
- CPU-udnyttelsen er over 70 % ELLER
- Mere end 90 % af forbindelserne bliver brugt
Klyngen vil automatisk skalere ned, hvis begge følgende betingelser er opfyldt:
- CPU-udnyttelsen falder til under 30 % OG
- Mindre end 40 % af forbindelserne bliver brugt.
Nogle af de bemærkelsesværdige ting at vide om Auroras automatiske skaleringsflow:
- Den skaleres kun op, når den registrerer ydeevneproblemer, der kan løses ved at opskalere.
- Efter opskalering er nedkølingsperioden for nedskalering 15 minutter.
- Efter nedskalering er nedkølingsperioden for den næste nedskalering igen 310 sekunder.
- Den skaleres til nul kapacitet, når der ikke er nogen forbindelser i en 5-minutters periode.
Som standard udfører Aurora Serverless den automatiske skalering problemfrit uden at afbryde nogen aktive databaseforbindelser til serveren. Den er i stand til at bestemme et skaleringspunkt (et tidspunkt, hvor databasen sikkert kan starte skaleringsoperationen). Under følgende forhold kan Aurora Serverless dog muligvis ikke finde et skaleringspunkt:
- Langevarende forespørgsler eller transaktioner er i gang.
- Midlertidige borde eller bordlåse er i brug.
Hvis et af ovenstående tilfælde sker, fortsætter Aurora Serverless med at forsøge at finde et skaleringspunkt, så det kan starte skaleringsoperationen (medmindre "Force Scaling" er aktiveret). Det gør det, så længe det bestemmer, at DB-klyngen skal skaleres.
Observation af Aurora Auto Scaling Behaviour
Bemærk at i Aurora Serverless kan kun et lille antal parametre ændres, og max_connections er ikke en af dem. For alle andre konfigurationsparametre bruger Aurora MySQL Serverless-klynger standardværdierne. For max_connections styres den dynamisk af Aurora Serverless ved hjælp af følgende formel:
max_connections =GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})
Hvor, log er log2 (log base-2) og "DBInstanceClassMemory" er antallet af hukommelsesbytes, der er allokeret til DB-instansklassen, der er knyttet til den aktuelle DB-instans, minus den hukommelse, der bruges af Amazon RDS-processerne, der administrerer instansen. Det er ret svært at forudbestemme den værdi, som Aurora vil bruge, så det er godt at sætte nogle tests for at forstå, hvordan denne værdi skaleres i overensstemmelse hermed.
Her er vores Aurora Serverless-implementeringsoversigt for denne test:
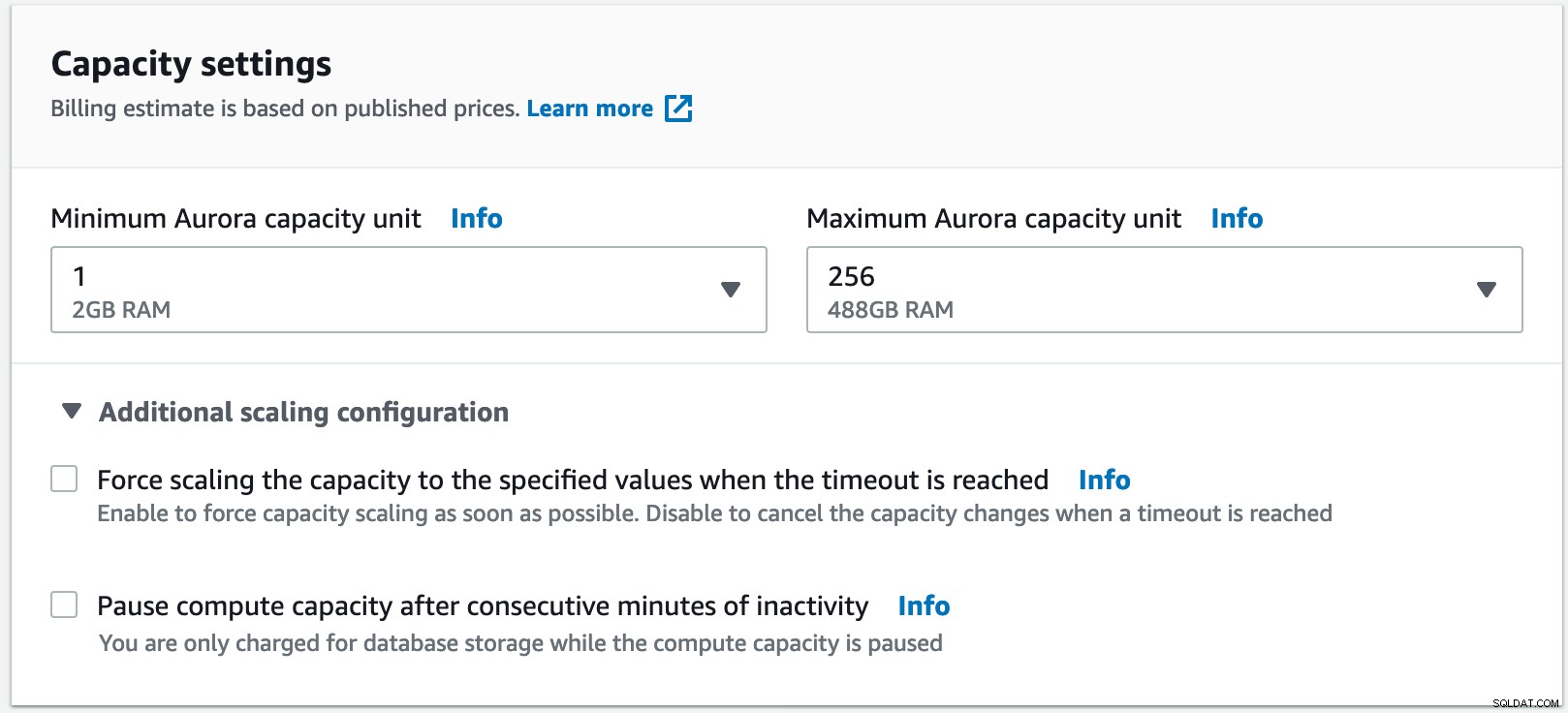
Til dette eksempel har jeg valgt minimum 1 Aurora-kapacitetsenhed, hvilket er lig med 2 GB RAM indtil den maksimale kapacitet på 256 enhed med 488 GB RAM.
Tests blev udført ved hjælp af sysbench, ved blot at sende flere tråde ud, indtil den når grænsen for MySQL-databaseforbindelser. Vores første forsøg på at udsende 128 simultane databaseforbindelser på én gang fik en direkte fiasko:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=128 \
--delete_inserts=5 \
--time=360 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runOvenstående kommando returnerede straks fejlen 'For mange forbindelser':
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsNår vi kiggede på indstillingerne for max_connection, fik vi følgende:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
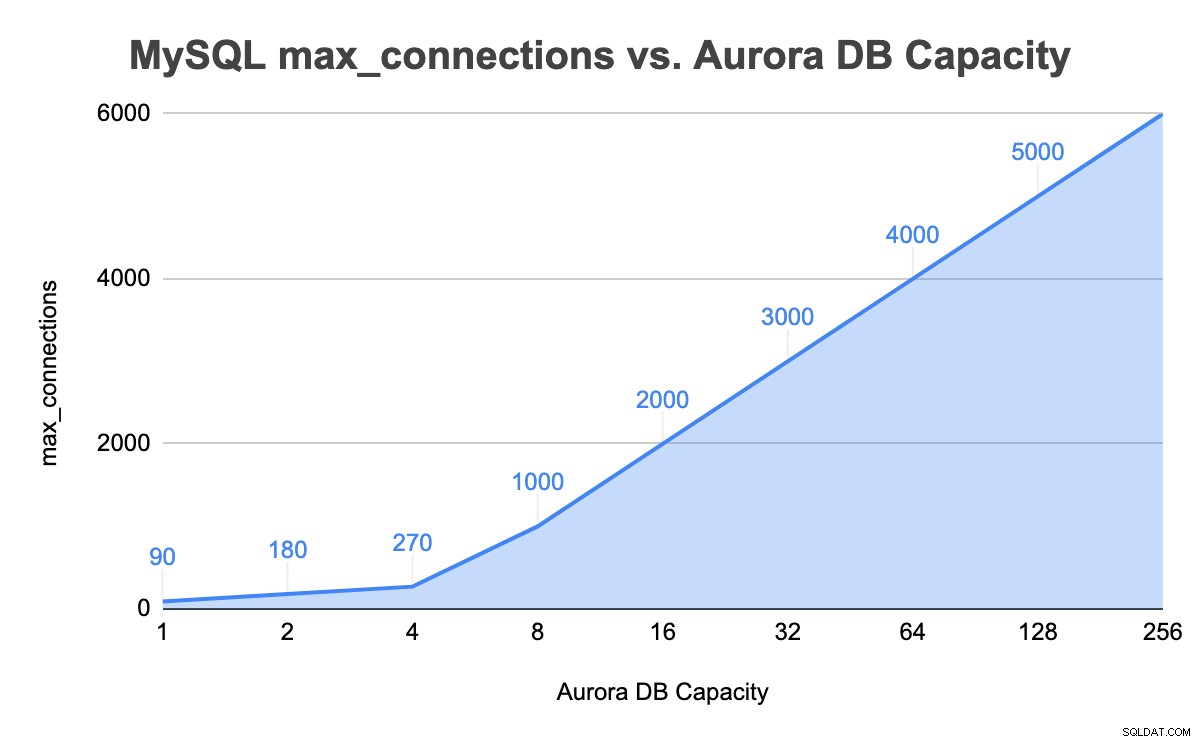
| ip-10-2-56-105 | 90 |
+----------------+-------------------+Det viser sig, at startværdien af max_connections for vores Aurora-instans med én DB-kapacitet (2GB RAM) er 90. Dette er faktisk meget lavere end vores forventede værdi, hvis det beregnes ved hjælp af den medfølgende formel til at estimere max_connections værdi:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+Dette betyder simpelthen, at DBInstanceClassMemory ikke er lig med den faktiske hukommelse for Aurora-forekomsten. Det skal være langt lavere. Ifølge denne diskussionstråd justeres variablens værdi for at tage højde for hukommelse, der allerede er i brug til OS-tjenester og RDS-administrationsdæmon.
Alligevel hjælper det os heller ikke at ændre standardværdien for max_connections til noget højere, da denne værdi er dynamisk styret af Aurora Serverless cluster. Derfor var vi nødt til at reducere værdien af sysbench-starttrådene til 84, fordi interne Aurora-tråde allerede reserverede omkring 4 til 5 forbindelser via 'rdsadmin'@'localhost'. Derudover har vi også brug for en ekstra forbindelse til vores administrations- og overvågningsformål.
Så vi udførte følgende kommando i stedet (med --threads=84):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=84 \
--delete_inserts=5 \
--time=600 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runEfter at ovenstående test var gennemført på 10 minutter (--tid=600), kørte vi den samme kommando igen, og på dette tidspunkt var nogle af de bemærkelsesværdige variabler og status ændret som vist nedenfor:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Bemærk, at max_connections nu er fordoblet op til 180, med et andet værtsnavn og lille oppetid, som om serveren lige var startet. Fra applikationssynspunktet ser det ud til, at en anden "større databaseinstans" har overtaget slutpunktet og konfigureret med en anden max_connections-variabel. Når man ser på Aurora-begivenheden, er følgende sket:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Derefter udløste vi den samme sysbench-kommando og skabte yderligere 84 forbindelser til databaseslutpunktet. Efter at den genererede stresstest er fuldført, skalerer serveren automatisk op til 4 DB kapacitet, som vist nedenfor:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+Du kan se det ved at se på det forskellige værtsnavn, max_connection og oppetidsværdi, hvis det sammenlignes med den forrige. En anden større instans har "overtaget" rollen fra den forrige instans, hvor DB-kapaciteten var lig med 2. Det faktiske skaleringspunkt er når serverbelastningen faldt og næsten ramte gulvet. I vores test, hvis vi holdt forbindelsen fuld og databasebelastningen konsekvent høj, ville automatisk skalering ikke finde sted.
Ved at se på begge skærmbilleder nedenfor kan vi se, at skaleringen kun sker, når vores Sysbench har gennemført sin stresstest i 600 sekunder, fordi det er det sikreste punkt at udføre automatisk skalering.
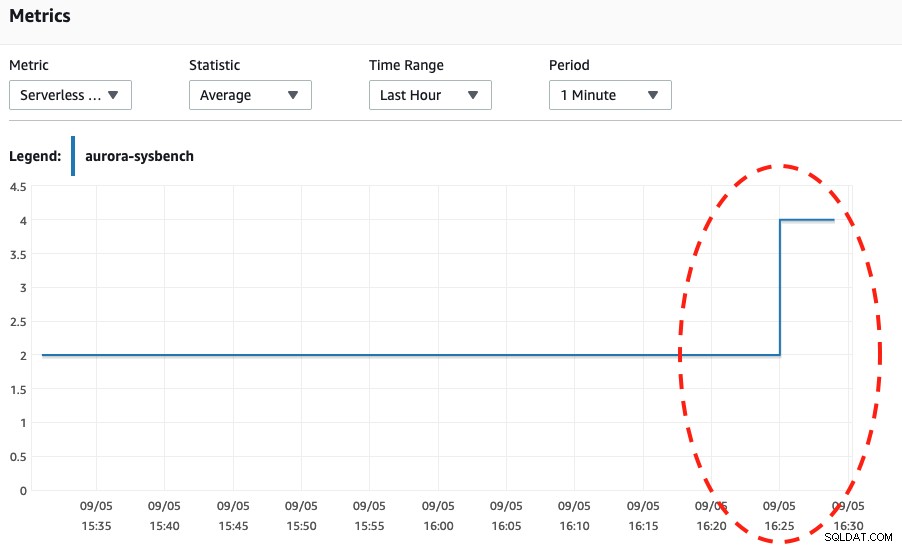 Serverløs DB-kapacitet CPU-udnyttelse
Serverløs DB-kapacitet CPU-udnyttelse 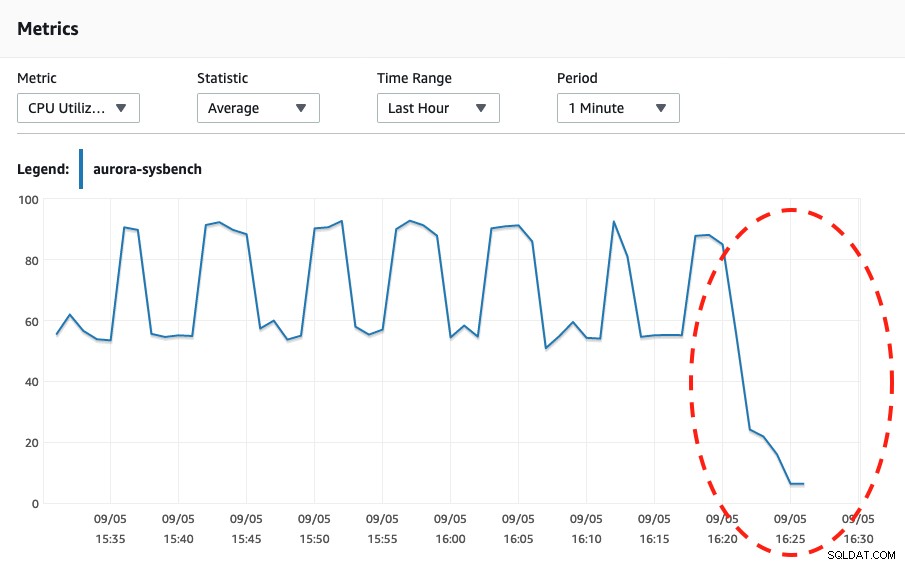 CPU-udnyttelse
CPU-udnyttelse Når man ser på Aurora-begivenheder, skete følgende hændelser:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Endelig genererede vi meget flere forbindelser indtil næsten 270 og venter, indtil det er færdigt, for at komme ind i kapaciteten på 8 DB:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
+---------------+-----------------+-------------------+--------+I forekomsten af 8 kapacitetsenheder er MySQL max_connections værdien nu 1000. Vi gentog lignende trin ved at maksimere databaseforbindelserne og op til grænsen på 256 kapacitetsenheder. Følgende tabel opsummerer den samlede DB-kapacitetsenhed versus max_connections-værdien i vores test op til den maksimale DB-kapacitet:
Tvungen skalering
Som nævnt ovenfor vil Aurora Serverless kun udføre automatisk skalering, når det er sikkert at gøre det. Brugeren har dog mulighed for at tvinge DB-kapacitetsskalering til at ske med det samme ved at markere afkrydsningsfeltet Force scaling under 'Yderligere skaleringskonfiguration':
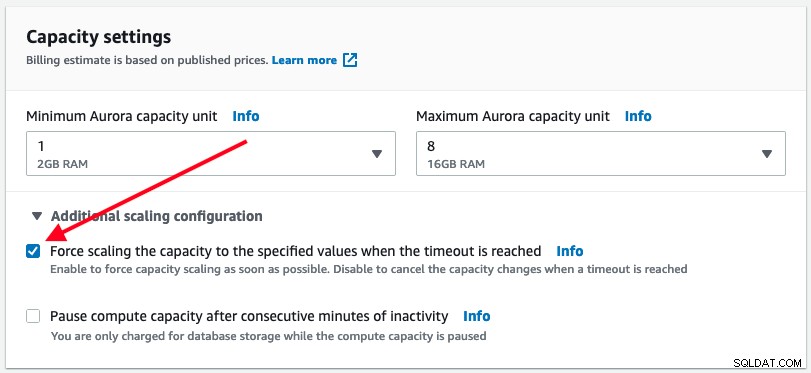
Når tvungen skalering er aktiveret, sker skaleringen, så snart timeoutet er udløbet nået, hvilket er 300 sekunder. Denne adfærd kan forårsage databaseafbrydelse fra dit program, hvor aktive forbindelser til databasen kan blive afbrudt. Vi observerede følgende fejl, da tvungen automatisk skalering skete, efter at den nåede timeout:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.Ovenstående betyder ganske enkelt, at i stedet for at finde det rigtige tidspunkt at skalere op, tvinger Aurora Serverless instanserstatningen til at finde sted umiddelbart efter, at den når sin timeout, hvilket forårsager, at transaktioner bliver afbrudt og rullet tilbage. At prøve den afbrudte forespørgsel igen for anden gang vil sandsynligvis løse problemet. Denne konfiguration kan bruges, hvis din applikation er modstandsdygtig over for forbindelsesfald.
Oversigt
Amazon Aurora Serverless auto scaling er en vertikal skaleringsløsning, hvor en mere kraftfuld instans overtager en ringere instans, og udnytter den underliggende Aurora shared storage-teknologi effektivt. Som standard udføres den automatiske skaleringsoperation problemfrit, hvorved Aurora finder et sikkert skaleringspunkt til at udføre instansskiftet. Man har mulighed for at tvinge til automatisk skalering med risiko for, at aktive databaseforbindelser bliver droppet.