Der er adskillige cloud-udbydere i disse dage. De kan være små eller store, lokale eller med datacentre spredt over hele verden. Mange af disse cloud-udbydere tilbyder en form for en administreret relationel databaseløsning. De understøttede databaser har en tendens til at være MySQL eller PostgreSQL eller en anden variant af relationel database.
Når du designer enhver form for databaseinfrastruktur, er det vigtigt at forstå dine forretningsbehov og beslutte, hvilken slags tilgængelighed du skal opnå.
I dette blogindlæg vil vi se på muligheder for høj tilgængelighed for MySQL-baserede løsninger fra en af de største cloud-udbydere - Google Cloud Platform.
Implementering af et meget tilgængeligt miljø ved hjælp af GCP SQL-instans
For denne blog, vi ønsker, er et meget simpelt miljø - en database, med måske en eller to replikaer. Vi ønsker let at kunne failover og genoprette driften så hurtigt som muligt, hvis masteren fejler. Vi vil bruge MySQL 5.7 som den valgte version og starter med installationsguiden til instanser:
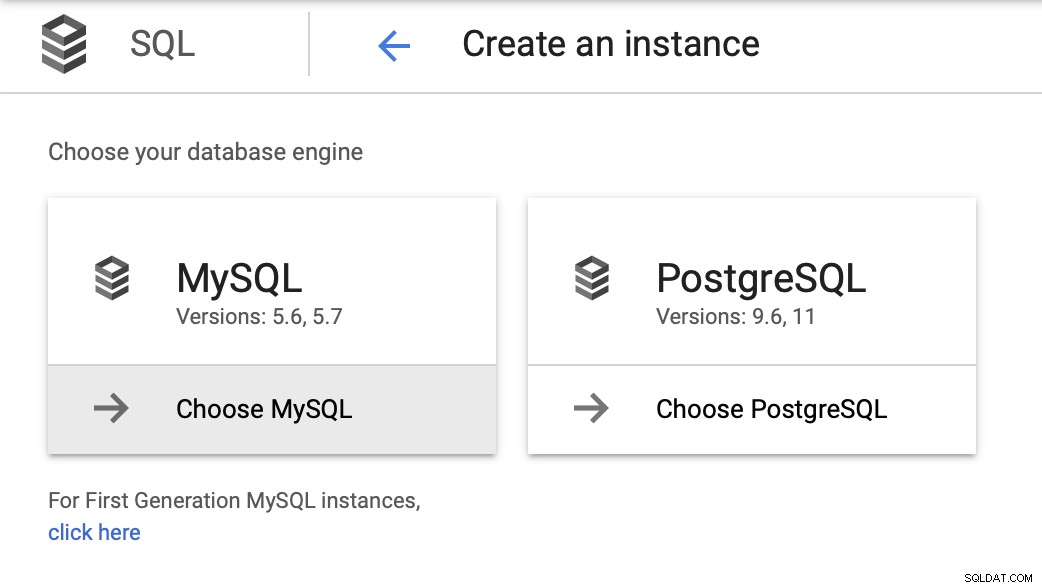
Vi skal derefter oprette root-adgangskoden, angive instansnavnet og bestemme, hvor den skal placeres:
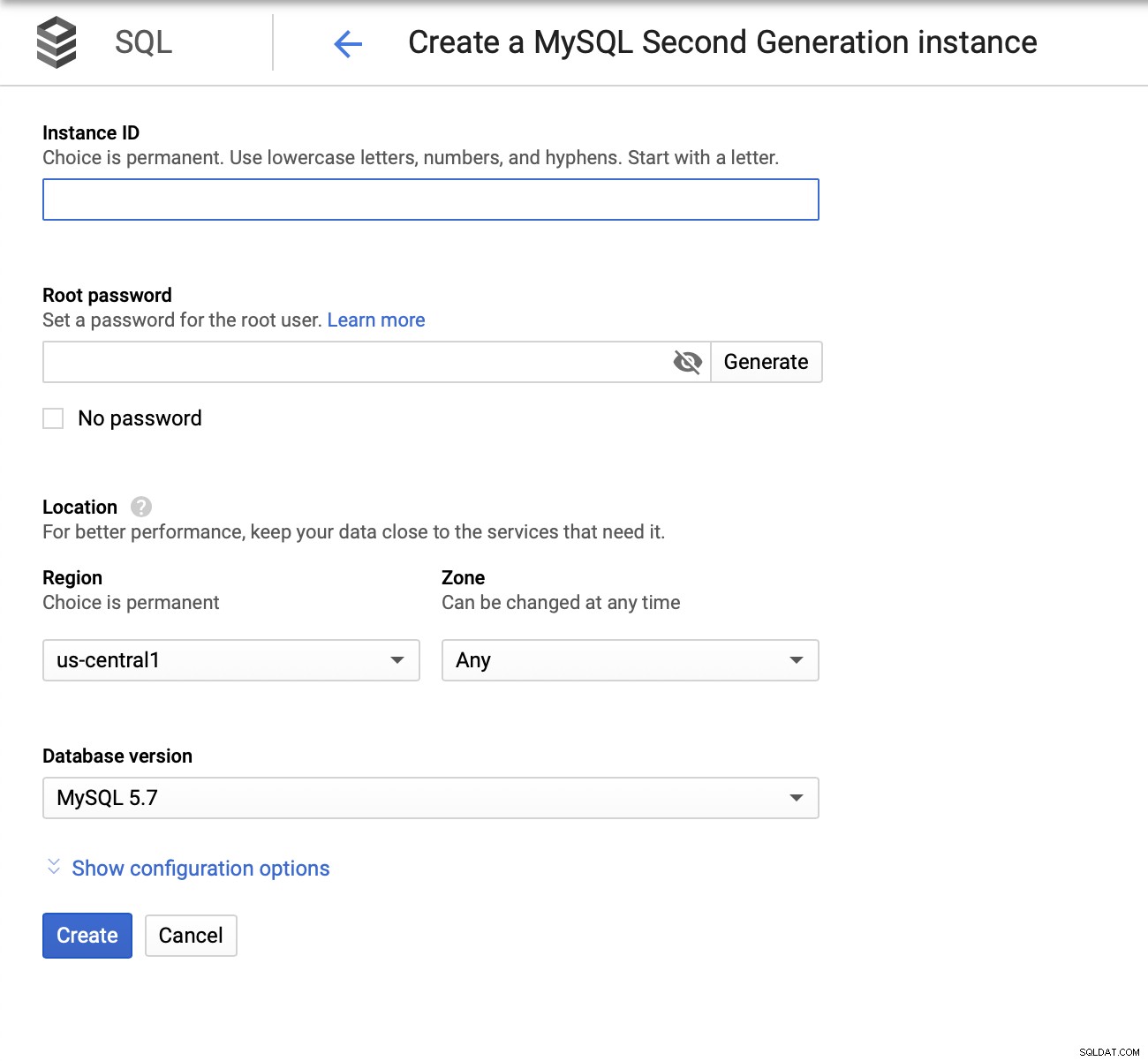
Dernæst vil vi se på konfigurationsmulighederne:
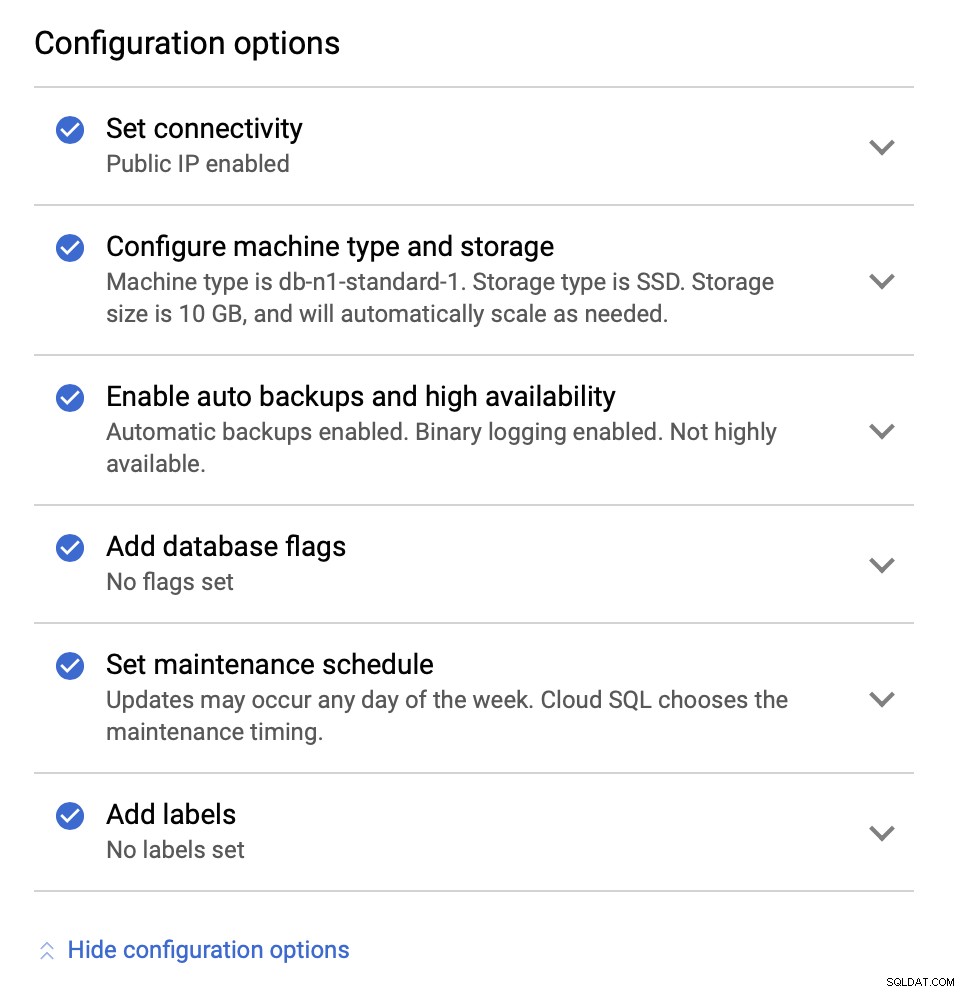
Vi kan foretage ændringer med hensyn til instansstørrelsen (vi vil gå med db-n1-standard-4), lager- og vedligeholdelsesplan. Det, der er vigtigst for os i denne opsætning, er mulighederne for høj tilgængelighed:
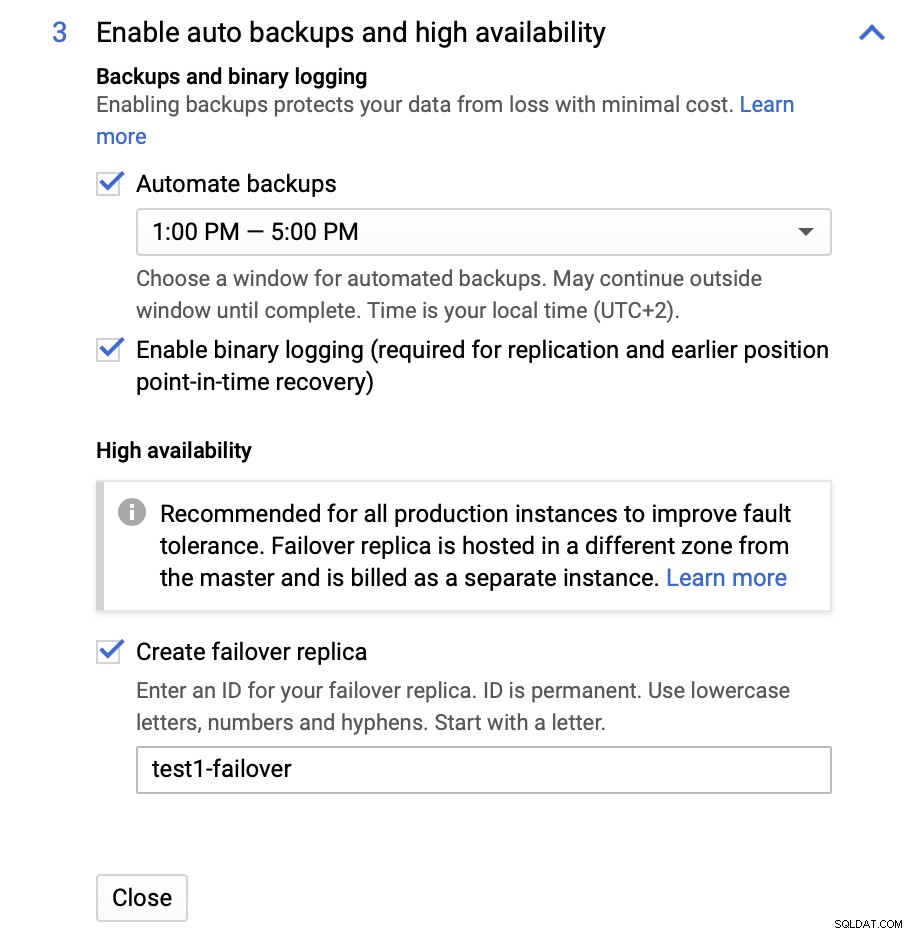
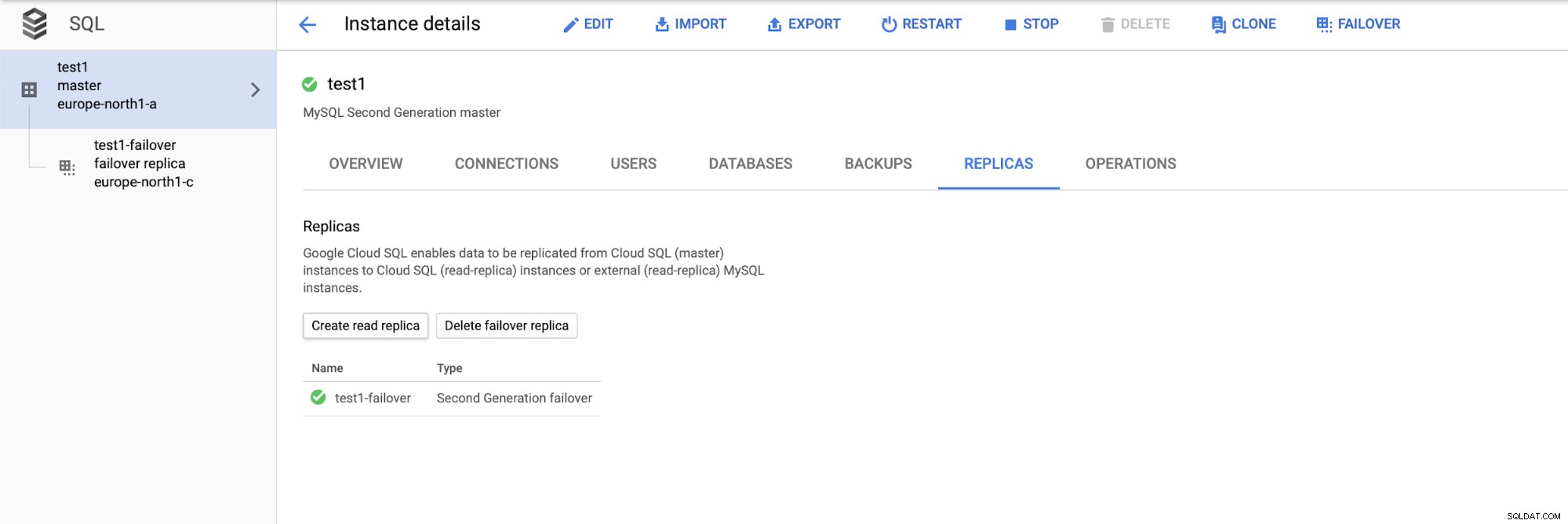
Her kan vi vælge at få lavet en failover-replika. Denne replika vil blive forfremmet til en master, hvis den originale master mislykkes.

Når vi har implementeret opsætningen, lad os tilføje en replikeringsslave:
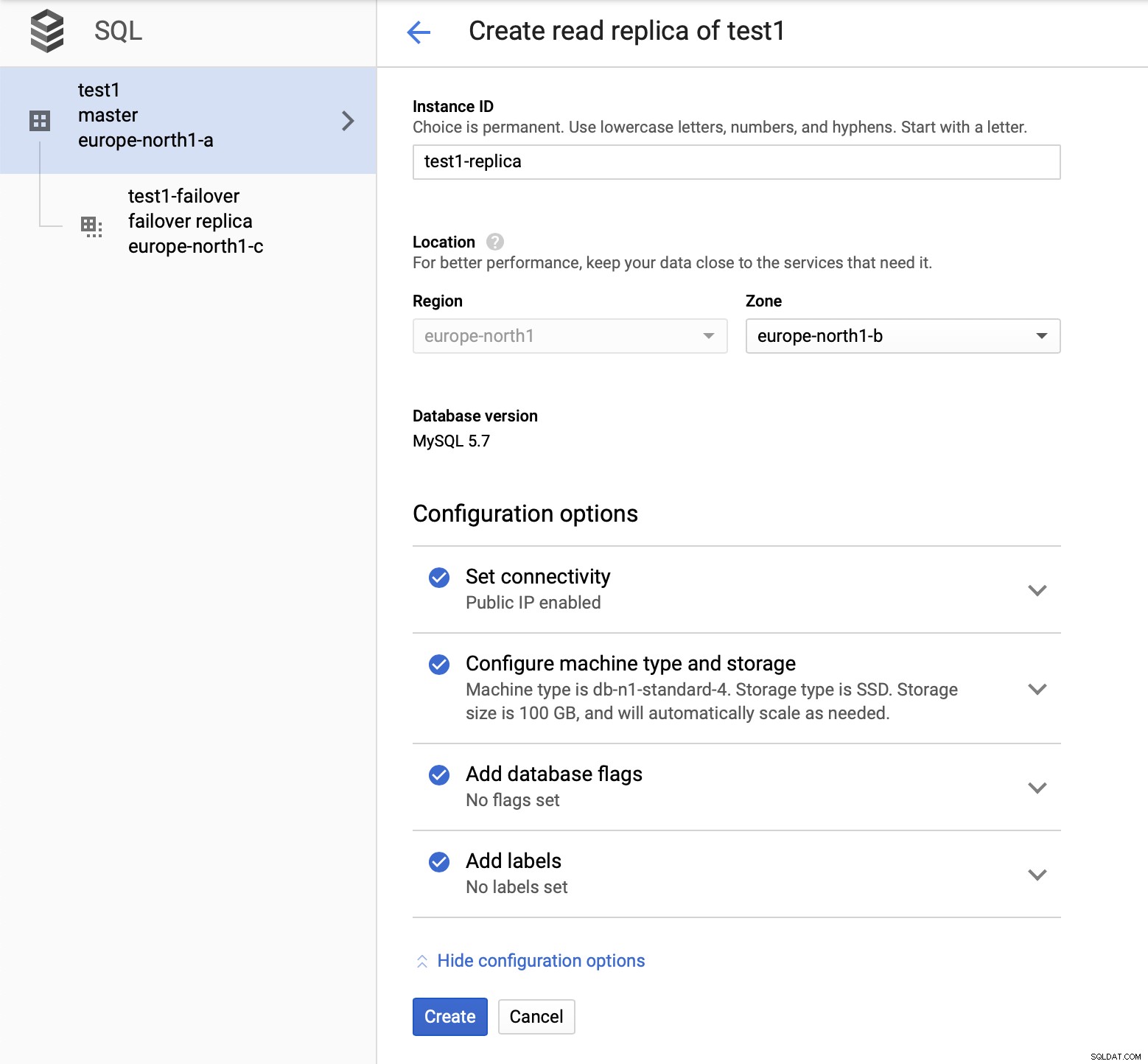
Når processen med at tilføje replikaen er færdig, er vi klar til noget tests. Vi skal køre testarbejdsbelastning ved hjælp af Sysbench på vores master, failover-replika og læse replika for at se, hvordan dette vil fungere. Vi vil køre tre forekomster af Sysbench ved at bruge slutpunkterne for alle tre typer knudepunkter.
Så vil vi udløse den manuelle failover via brugergrænsefladen:
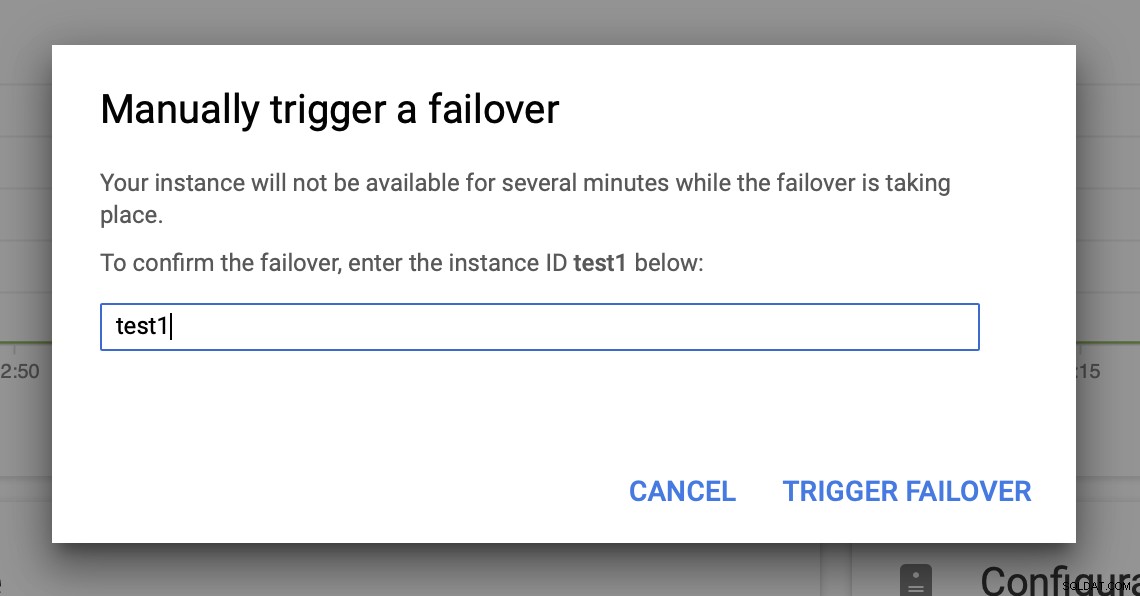
Test MySQL Failover på Google Cloud Platform?
Jeg er nået til dette punkt uden nogen detaljeret viden om, hvordan SQL-knuderne i GCP fungerer. Jeg havde dog nogle forventninger baseret på tidligere MySQL-erfaring og hvad jeg har set hos de andre cloud-udbydere. Til at begynde med bør failover til failover-noden være meget hurtig. Det, vi gerne vil have, er at holde replikeringsslaverne tilgængelige uden behov for en genopbygning. Vi vil også gerne se, hvor hurtigt vi kan udføre failoveren en anden gang (da det ikke er ualmindeligt, at problemet spreder sig fra en database til en anden).
Hvad vi bestemte under vores tests...
- Mens det mislykkedes, blev masteren tilgængelig igen efter 75 - 80 sekunder.
- Failover-replika var ikke tilgængelig i 5-6 minutter.
- Læs replika var tilgængelig under failover-processen, men den blev utilgængelig i 55 - 60 sekunder efter failover-replikaen blev tilgængelig
Hvad vi ikke er sikre på...
Hvad sker der, når failover-replikaen ikke er tilgængelig? Baseret på tidspunktet ser det ud til, at failover-replikaen er ved at blive genopbygget. Dette giver mening, men så ville gendannelsestiden være stærkt relateret til størrelsen af forekomsten (især I/O-ydeevne) og størrelsen af datafilen.
Hvad sker der med læst replika, efter at failover-replikaen ville være blevet genopbygget? Oprindeligt var den læste replika forbundet med masteren. Når masteren fejlede, ville vi forvente, at den læste replika ville give en forældet visning af datasættet. Når den nye master dukker op, skal den genoprette forbindelse via replikering til instansen (som plejede at være failover-replika, og som er blevet forfremmet til master). Der er ikke behov for et minuts nedetid, når CHANGE MASTER udføres.
Vigtigere er det, under failover-processen er der ingen måde at udføre en anden failover på (hvilket på en måde giver mening):
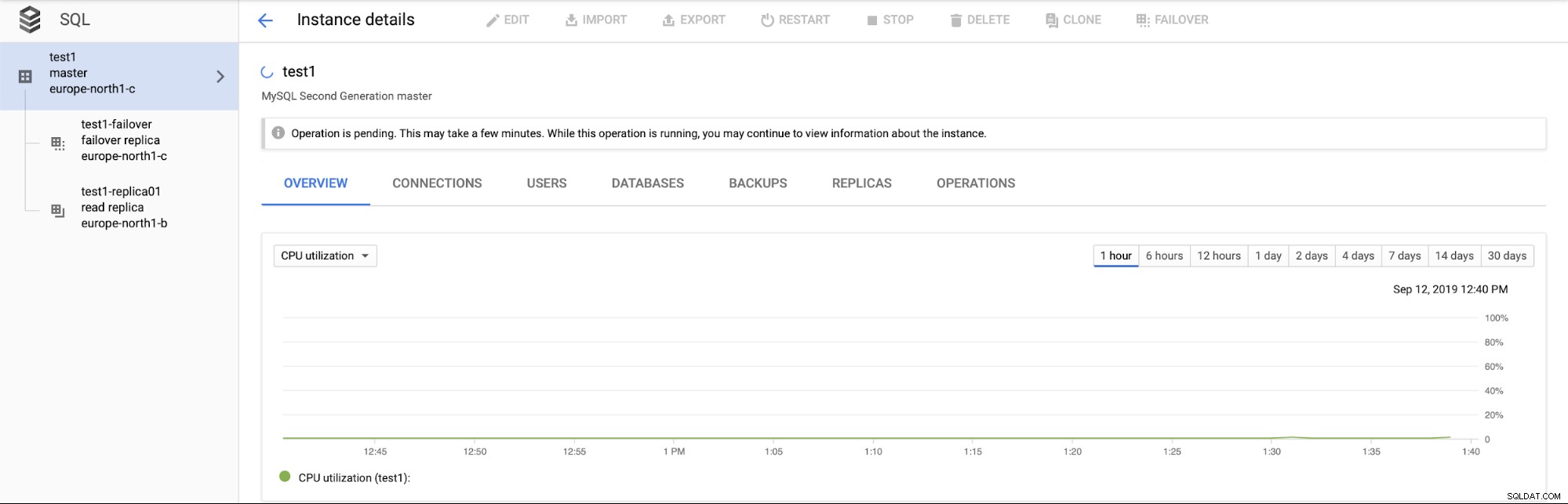
Det er heller ikke muligt at fremme læst replika (hvilket ikke nødvendigvis giver mening - vi ville forvente at kunne promovere læste replikaer til enhver tid).

Det er vigtigt at bemærke, at stole på de læste replikaer for at give høj tilgængelighed (uden at oprette en failover-replika) er ikke en holdbar løsning. Du kan promovere en læst replika til at blive en master, men en ny klynge ville blive oprettet; løsrevet fra resten af noderne.
Der er ingen måde at slave dine andre replikaer fra den nye klynge. Den eneste måde at gøre dette på ville være at skabe nye replikaer, men dette er en tidskrævende proces. Den er også praktisk talt ubrugelig, hvilket gør failover-replikaen til den eneste rigtige mulighed for høj tilgængelighed for SQL-noder i Google Cloud Platform.
Konklusion
Selvom det er muligt at skabe et meget tilgængeligt miljø for SQL-noder i GCP, vil masteren ikke være tilgængelig i ca. halvandet minut. Hele processen (inklusive genopbygning af failover-replikaen og nogle handlinger på de læste replikaer) tog flere minutter. I løbet af den tid var vi ikke i stand til at udløse en ekstra failover, og vi var heller ikke i stand til at promovere en læst replika.
Har vi nogen GCP-brugere derude? Hvordan opnår du høj tilgængelighed?