Tidligere postede vi en blog, der diskuterede Achieving MySQL Failover &Failback på Google Cloud Platform (GCP), og i denne blog vil vi se på, hvordan dens rival, Amazon Relational Database Service (RDS), håndterer failover. Vi vil også se på, hvordan du kan udføre en failback af din tidligere masterknude, og bringe den tilbage til sin oprindelige rækkefølge som en master.
Når man sammenligner de teknologiske gigantiske offentlige skyer, der understøtter administrerede relationelle databasetjenester, er Amazon den eneste, der tilbyder en alternativ mulighed (sammen med MySQL/MariaDB, PostgreSQL, Oracle og SQL Server) til at levere sin egen form for databasestyring kaldet Amazon Aurora. For dem, der ikke er bekendt med Aurora, er det en fuldt styret relationel databasemotor, der er kompatibel med MySQL og PostgreSQL. Aurora er en del af den administrerede databasetjeneste Amazon RDS, en webtjeneste, der gør det nemt at opsætte, betjene og skalere en relationel database i skyen.
Hvorfor skulle du have failover eller failback?
At designe et stort system, der er fejltolerant, meget tilgængeligt og uden Single-Point-Of-Failure (SPOF) kræver ordentlig test for at bestemme, hvordan det ville reagere, når tingene går galt.
Hvis du er bekymret for, hvordan dit system ville fungere, når det reagerer på dit systems fejlregistrering, isolering og gendannelse (FDIR), bør failover og failback være af stor betydning.
Database-failover i Amazon RDS
Failover sker automatisk (da manuel failover kaldes switchover). Som nævnt i en tidligere blog opstår behovet for failover, når din nuværende databasemaster oplever en netværksfejl eller unormal afslutning af værtssystemet. Failover skifter den til en stabil redundanstilstand eller til en standby-computerserver, et system, en hardwarekomponent eller et netværk.
I Amazon RDS behøver du ikke at gøre dette, og du er heller ikke forpligtet til at overvåge det selv, da RDS er en administreret databasetjeneste (hvilket betyder, at Amazon håndterer opgaven for dig). Denne service håndterer ting såsom hardwareproblemer, backup og gendannelse, softwareopdateringer, lageropgraderinger og endda softwarepatching. Det taler vi om senere på denne blog.
Databasefailback i Amazon RDS
I den forrige blog dækkede vi også, hvorfor du skulle have failback. I et typisk replikeret miljø skal masteren være kraftig nok til at bære en enorm belastning, især når arbejdsbelastningen er høj. Din masteropsætning kræver tilstrækkelige hardwarespecifikationer for at sikre, at den kan behandle skrivninger, generere replikeringshændelser, behandle kritiske læsninger osv. på en stabil måde. Når failover er påkrævet under katastrofegendannelse (eller til vedligeholdelse), er det ikke ualmindeligt, at når du promoverer en ny master, kan du bruge ringere hardware. Denne situation kan være i orden midlertidigt, men i det lange løb skal den udpegede master bringes tilbage for at lede replikationen, efter at den anses for at være sund (eller vedligeholdelse er fuldført).
I modsætning til failover, sker failback-operationer normalt i et kontrolleret miljø ved at bruge switchover. Det gøres sjældent i paniktilstand. Denne tilgang giver dine ingeniører tid nok til at planlægge omhyggeligt og øve øvelsen for at sikre en glidende overgang. Dens hovedformål er simpelthen at bringe den gode, gamle mester tilbage til den seneste tilstand og gendanne replikeringsopsætningen til dens oprindelige topologi. Da vi har at gøre med Amazon RDS, er der virkelig ingen grund til, at du skal være alt for bekymret over denne type problemer, da det er en administreret tjeneste, hvor de fleste job håndteres af Amazon.
Hvordan håndterer Amazon RDS Database Failover?
Når du implementerer dine Amazon RDS-noder, kan du konfigurere din databaseklynge med Multi-Availability Zone (AZ) eller til en Single-Availability Zone. Lad os tjekke hver af dem om, hvordan failover behandles.
Hvad er en Multi-AZ-opsætning?
Når en katastrofe eller katastrofe opstår, såsom uplanlagte udfald eller naturkatastrofer, hvor dine databaseforekomster er berørt, skifter Amazon RDS automatisk til en standby-replika i en anden tilgængelighedszone. Denne AZ er typisk i en anden gren af datacentret, ofte langt fra den aktuelle tilgængelighedszone, hvor forekomster er placeret. Disse AZ'er er yderst tilgængelige, avancerede faciliteter, der beskytter dine databaseforekomster. Failover-tider afhænger af færdiggørelsen af opsætningen, som ofte er baseret på databasens størrelse og aktivitet samt andre forhold til stede på det tidspunkt, hvor den primære DB-instans blev utilgængelig.
Failover-tider er typisk 60-120 sekunder. De kan dog være længere, da store transaktioner eller en langvarig gendannelsesproces kan øge failover-tiden. Når failoveren er fuldført, kan det også tage yderligere tid, før RDS-konsollen (UI) afspejler den nye tilgængelighedszone.
Hvad er en Single-AZ-opsætning?
Single-AZ opsætninger bør kun bruges til dine databaseforekomster, hvis din RTO (Recovery Time Objective) og RPO (Recovery Point Objective) er høje nok til at tillade det. Der er risici forbundet med at bruge en Single-AZ, såsom store nedetider, der kan forstyrre forretningsdriften.
Almindelige RDS-fejlscenarier
Mængden af nedetid afhænger af typen af fejl. Lad os gennemgå, hvad disse er, og hvordan gendannelse af instansen håndteres.
Genoprettelig instansfejl
En Amazon RDS-instansfejl opstår, når den underliggende EC2-instans lider af en fejl. Ved hændelse vil AWS udløse en hændelsesmeddelelse og sende en advarsel til dig ved hjælp af Amazon RDS Event Notifications. Dette system bruger AWS Simple Notification Service (SNS) som alarmbehandler.
RDS vil automatisk forsøge at starte en ny instans i den samme tilgængelighedszone, vedhæfte EBS-volumen og forsøge at gendanne. I dette scenarie er RTO typisk under 30 minutter. RPO er nul, fordi EBS-volumenet var i stand til at genvindes. EBS-volumen er i en enkelt tilgængelighedszone, og denne type gendannelse finder sted i den samme tilgængelighedszone som den oprindelige instans.
Ikke-genoprettelige instansfejl eller EBS-volumenfejl
For mislykket RDS-instansgendannelse (eller hvis den underliggende EBS-volumen lider af en datatabsfejl) er punkt-i-tidsgendannelse (PITR) påkrævet. PITR håndteres ikke automatisk af Amazon, så du skal enten oprette et script for at automatisere det (ved hjælp af AWS Lambda) eller gøre det manuelt.
RTO-timingen kræver opstart af en ny Amazon RDS-instans, som vil have et nyt DNS-navn, når den er oprettet, og derefter anvende alle ændringer siden sidste sikkerhedskopiering.
RPO'en er typisk 5 minutter, men du kan finde den ved at ringe til RDS:describe-db-instances:LatestRestorableTime. Tiden kan variere fra 10 minutter til timer afhængigt af antallet af logfiler, der skal påføres. Det kan kun bestemmes ved test, da det afhænger af størrelsen af databasen, antallet af ændringer, der er foretaget siden sidste sikkerhedskopiering, og arbejdsbelastningsniveauerne på databasen. Da sikkerhedskopier og transaktionslogfiler er gemt i Amazon S3, kan denne gendannelse ske i enhver understøttet tilgængelighedszone i regionen.
Når den nye instans er oprettet, skal du opdatere din klients slutpunktsnavn. Du har også mulighed for at omdøbe den til den gamle DB-instans' slutpunktsnavn (men det kræver, at du sletter den gamle mislykkede instans), men det gør det umuligt at bestemme årsagen til problemet.
Forstyrrelser i tilgængelighedszone
Afbrydelser i tilgængelighedszone kan være midlertidige og er sjældne, men hvis AZ-fejl er mere permanent, vil forekomsten blive sat til en mislykket tilstand. Gendannelsen ville fungere som beskrevet tidligere, og en ny instans kunne oprettes i en anden AZ ved hjælp af punkt-i-tidsgendannelse. Dette trin skal udføres manuelt eller ved scripting. Strategien for denne type gendannelsesscenarie bør være en del af dine større planer for katastrofegendannelse (DR).
Hvis Availability Zone-fejlen er midlertidig, vil databasen være nede, men forbliver i tilgængelig tilstand. Du er ansvarlig for overvågning på applikationsniveau (ved hjælp af enten Amazons eller tredjepartsværktøjer) for at opdage denne type scenarier. Hvis dette sker, kan du vente på, at tilgængelighedszonen gendannes, eller du kan vælge at gendanne forekomsten til en anden tilgængelighedszone med en gendannelse på tidspunktet.
RTO'en ville være den tid, det tager at starte en ny RDS-instans op og derefter anvende alle ændringerne siden sidste sikkerhedskopiering. RPO'en kan være længere, op til det tidspunkt, hvor tilgængelighedszonens fejl opstod.
Test af failover og failback på Amazon RDS
Vi oprettede og konfigurerede en Amazon RDS Aurora ved hjælp af db.r4.large med en Multi-AZ-implementering (som vil skabe en Aurora-replika/læser i en anden AZ), som kun er tilgængelig via EC2. Du skal sørge for at vælge denne mulighed ved oprettelsen, hvis du har til hensigt at have Amazon RDS som failover-mekanisme.
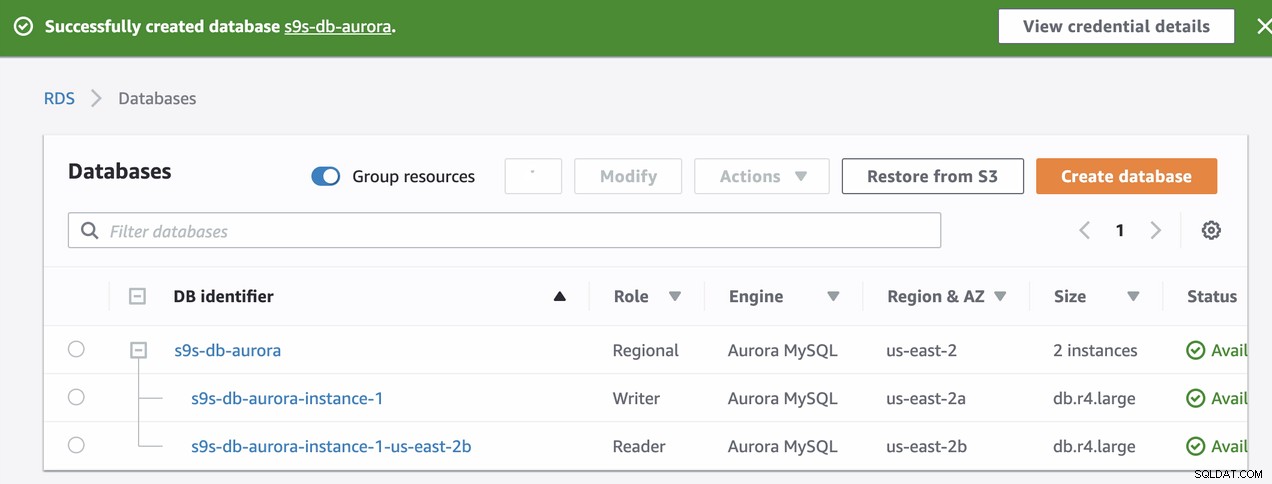
Under klargøringen af vores RDS-instans tog det ca. ~11 minutter før instanserne blev tilgængelige og tilgængelige. Nedenfor er et skærmbillede af de tilgængelige noder i RDS efter oprettelsen:
Disse to noder vil have deres egne udpegede slutpunktsnavne, som vi vil bruge til at forbinde fra klientens perspektiv. Bekræft det først, og kontroller det underliggende værtsnavn for hver af disse noder. For at kontrollere, kan du køre denne bash-kommando nedenfor og bare erstatte værtsnavnene/slutpunktsnavnene i overensstemmelse hermed:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Resultatet tydeliggør som følger,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulering af Amazon RDS-failover
Lad os nu simulere et nedbrud for at simulere en failover for Amazon RDS Aurora writer-instansen, som er s9s-db-aurora-instance-1 med slutpunktet s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
For at gøre dette skal du oprette forbindelse til din writer-instans ved hjælp af mysql-klientens kommandoprompt og derefter udsende syntaksen nedenfor:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Udstedelse af denne kommando har sin Amazon RDS-gendannelsesdetektion og virker ret hurtigt. Selvom forespørgslen er til testformål, kan den være anderledes, når denne forekomst sker i en faktuel begivenhed. Du kan være interesseret i at vide mere om test af et forekomstnedbrud i deres dokumentation. Se hvordan vi ender nedenfor:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Kørsel af SQL-kommandoen ovenfor betyder, at den skal simulere diskfejl i mindst 3 minutter. Jeg overvågede tidspunktet for at begynde simuleringen, og det tog omkring 18 sekunder, før failoveren begynder.
Se nedenfor om, hvordan RDS håndterer simuleringsfejlen og failoveren,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Resultaterne af denne simulering er ret interessante. Lad os tage dette en ad gangen.
- Omkring kl. 10:06:29 begyndte jeg at køre simuleringsforespørgslen som angivet ovenfor.
- Omkring kl. 10:06:44 viser det, at slutpunktet s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com med tildelt værtsnavnet ip-10-20-1- 139, hvor det i virkeligheden er den skrivebeskyttede instans, blev utilgængelig alligevel, at simuleringskommandoen blev kørt under læse-skrive-instansen.
- Omkring kl. 10:06:51 viser det, at endepunktet s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com med tildelt værtsnavnet ip-10-20-1- 139 er oppe, men den har markeret som læse-skrive-tilstand. Bemærk, at variabelen innodb_read_only, for Aurora MySQL-administrerede forekomster, er dette dens identifikator til at bestemme, om værten er læse-skrive- eller skrivebeskyttet node, og Aurora kører også kun på InnoDB-lagringsmotoren til MySQL-kompatible forekomster.
- Omkring kl. 10:07:13 er rækkefølgen ændret. Det betyder, at failoveren blev udført, og at forekomsterne er blevet tildelt til dets udpegede slutpunkter.
Tjek resultatet nedenfor, som vises i RDS-konsollen:
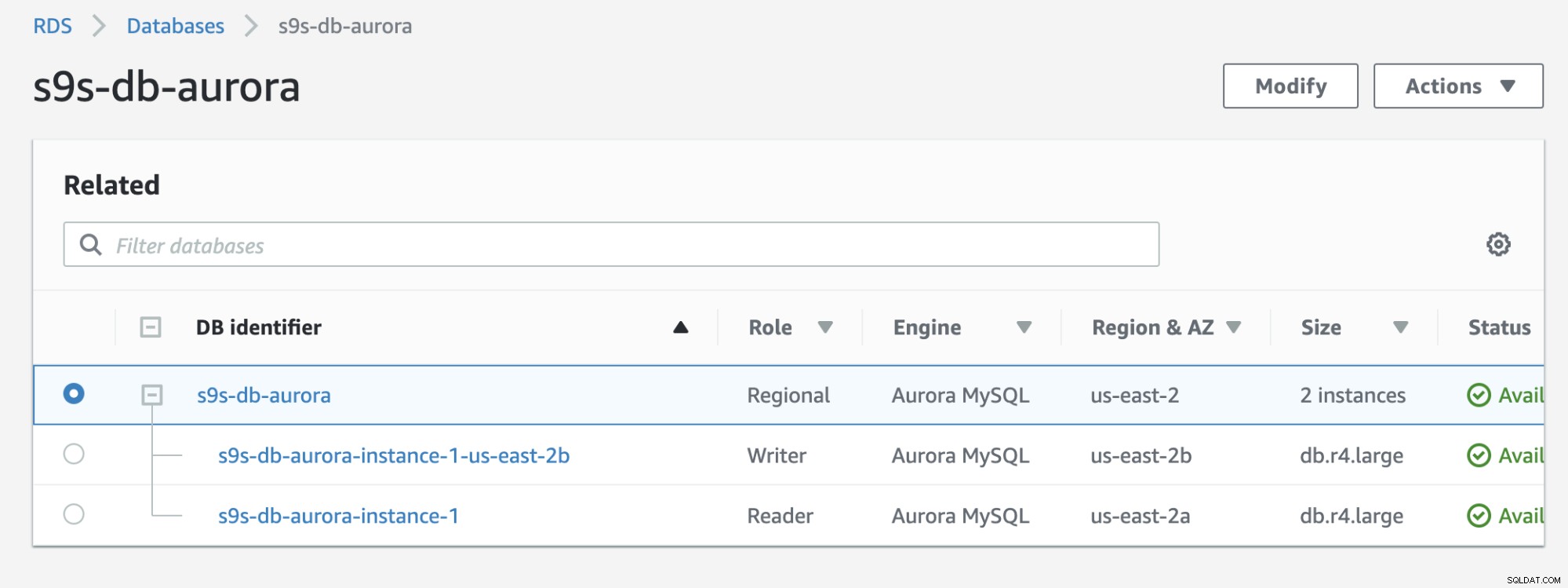
Hvis du sammenligner med den tidligere, s9s-db-aurora- instance-1 var en læser, men blev derefter forfremmet som forfatter efter failover. Processen inklusiv testen tog omkring 44 sekunder at fuldføre opgaven, men failover viser afsluttet på næsten 30 sekunder. Det er imponerende og hurtigt for en failover, især i betragtning af at dette er en administreret servicedatabase; hvilket betyder, at du ikke behøver at bekymre dig om hardware- eller vedligeholdelsesproblemer.
Udførelse af et tilbageslag i Amazon RDS
Failback i Amazon RDS er ret simpelt. Inden vi går igennem det, lad os tilføje en ny læserreplika. Vi har brug for en mulighed for at teste og identificere, hvilken node AWS RDS ville vælge fra, når den forsøger at fejle tilbage til den ønskede master (eller failback til den tidligere master), og for at se, om den vælger den rigtige node baseret på prioritet. Den aktuelle liste over forekomster lige nu og dens endepunkter er vist nedenfor.
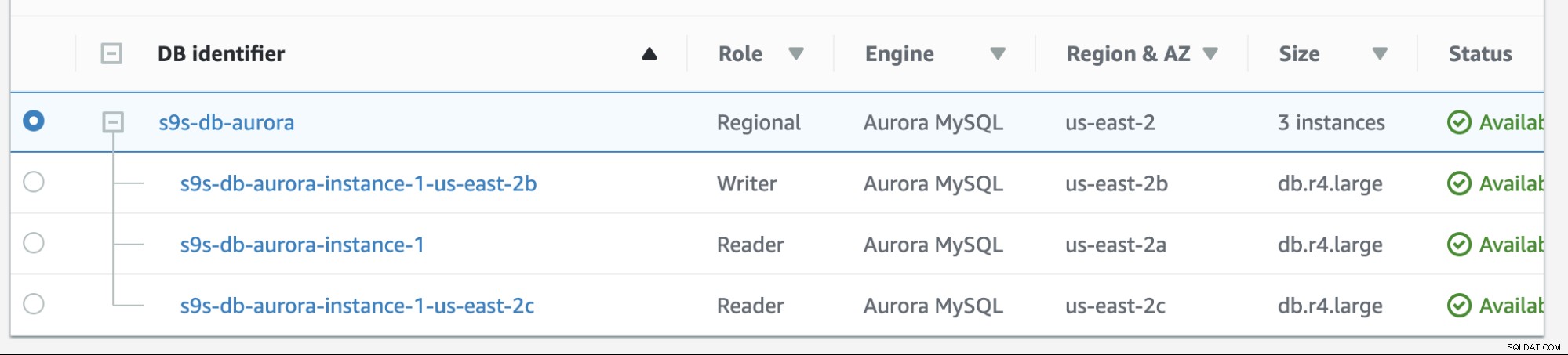

Den nye replika er placeret på us-east-2c AZ med db værtsnavn af ip-10-20-2-239.
Vi vil forsøge at lave en failback ved at bruge forekomsten s9s-db-aurora-instance-1 som det ønskede failback-mål. I denne opsætning har vi to læserforekomster. For at sikre, at den korrekte node opfanges under failover, skal du fastslå, om prioritet eller tilgængelighed er øverst (tier-0> tier-1> tier-2 og så videre indtil tier-15). Dette kan gøres ved at ændre forekomsten eller under oprettelsen af replikaen.
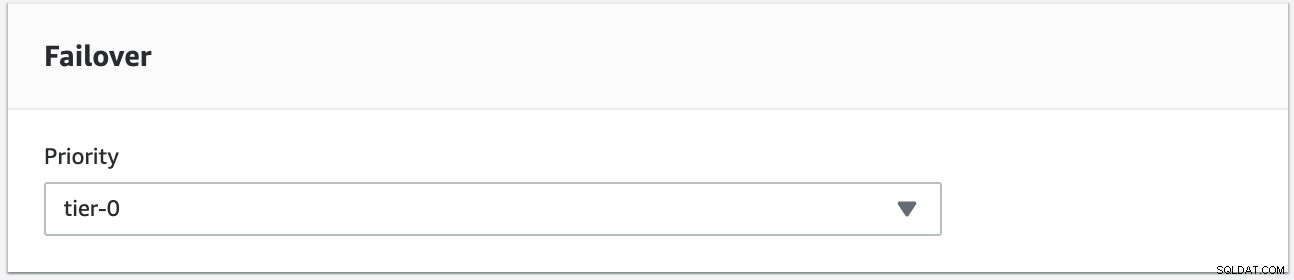
Du kan bekræfte dette i din RDS-konsol.
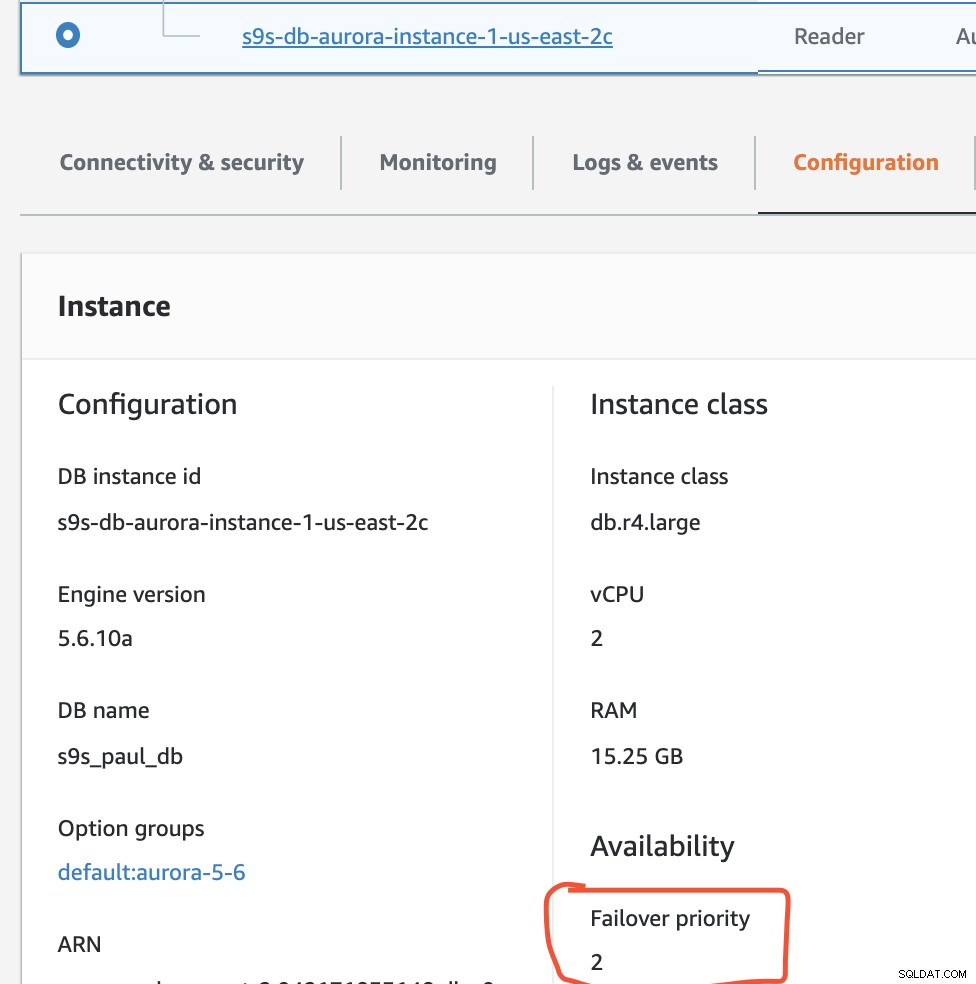
I denne opsætning har s9s-db-aurora-instance-1 prioritet =0 (og er en læse-replika), s9s-db-aurora-instance-1-us-east-2b har prioritet =1 (og er den nuværende skribent), og s9s-db-aurora-instance-1-us- øst-2c har prioritet =2 (og er også en læse-replika). Lad os se, hvad der sker, når vi forsøger at failback.
Du kan overvåge tilstanden ved at bruge denne kommando.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Efter failover er blevet udløst, vil den failback til vores ønskede mål, som er noden s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Failback-forsøget startede kl. 13:30:59 og afsluttedes omkring kl. 13:31:38 (nærmeste 30 sekunders mærke). Det ender med ~32 sekunder på denne test, som stadig er hurtig.
Jeg har bekræftet failover/failback flere gange, og det har konsekvent udvekslet sin læse-skrive-tilstand mellem instanserne s9s-db-aurora-instance-1 og s9s-db-aurora-instance-1- us-øst-2b. Dette efterlader s9s-db-aurora-instance-1-us-east-2c uplukket, medmindre begge noder oplever problemer (hvilket er meget sjældent, da de alle er placeret i forskellige AZ'er).
Under failover/failback-forsøgene går RDS i et hurtigt overgangstempo under failover på omkring 15 - 25 sekunder (hvilket er meget hurtigt). Husk på, at vi ikke har store datafiler gemt på denne instans, men det er stadig ret imponerende i betragtning af, at der ikke er mere at administrere.
Konklusion
At køre en Single-AZ introducerer fare, når der udføres en failover. Amazon RDS giver dig mulighed for at ændre og konvertere din Single-AZ til en multi-AZ-kompatibel opsætning, selvom dette vil tilføje nogle omkostninger for dig. Single-AZ kan være fint, hvis du er ok med en højere RTO- og RPO-tid, men anbefales bestemt ikke til højtrafikerede, missionskritiske forretningsapplikationer.
Med Multi-AZ kan du automatisere failover og failback på Amazon RDS, hvor du bruger din tid på at fokusere på forespørgselsjustering eller optimering. Dette letter mange problemer, som DevOps eller DBA'er står over for.
Selv om Amazon RDS kan forårsage et dilemma i nogle organisationer (da det ikke er platformagnostisk), er det stadig værd at overveje; især hvis din applikation kræver en langsigtet DR-plan, og du ikke ønsker at skulle bruge tid på at bekymre dig om hardware og kapacitetsplanlægning.