I årevis plejede MySQL-replikation at være baseret på binære loghændelser - alt hvad en slave vidste var den nøjagtige hændelse og den nøjagtige position, den lige læste fra masteren. Enhver enkelt transaktion fra en master kan være endt i forskellige binære logfiler og i forskellige positioner i disse logfiler. Det var en simpel løsning, der kom med begrænsninger - mere komplekse topologiændringer kunne kræve, at en administrator stopper replikering på de involverede værter. Eller disse ændringer kan forårsage nogle andre problemer, f.eks. kunne en slave ikke flyttes ned i replikeringskæden uden tidskrævende genopbygningsproces (vi kunne ikke nemt ændre replikering fra A -> B -> C til A -> C -> B uden at stoppe replikation på både B og C). Vi har alle været nødt til at omgå disse begrænsninger, mens vi drømmer om en global transaktions-id.
GTID blev introduceret sammen med MySQL 5.6 og medførte nogle store ændringer i den måde, MySQL fungerer på. Først og fremmest har hver transaktion en unik identifikator, som identificerer den på samme måde på hver server. Det er ikke længere vigtigt, i hvilken binær logposition en transaktion blev registreret, alt hvad du behøver at vide er GTID'et:'966073f3-b6a4-11e4-af2c-080027880ca6:4'. GTID er bygget af to dele - den unikke identifikator for en server, hvor en transaktion først blev udført, og et sekvensnummer. I ovenstående eksempel kan vi se, at transaktionen blev udført af serveren med server_uuid af '966073f3-b6a4-11e4-af2c-080027880ca6', og det er den 4. transaktion udført der. Denne information er nok til at udføre komplekse topologiændringer - MySQL ved hvilke transaktioner der er blevet udført, og derfor ved den hvilke transaktioner der skal udføres næste gang. Glem alt om binære logfiler, det er alt sammen i GTID.
Så hvor kan du finde GTID'er? Du finder dem to steder. På en slave, i 'vis slavestatus;', finder du to kolonner:Retrieved_Gtid_Set og Executed_Gtid_Set. Den første dækker GTID'er, som blev hentet fra masteren via replikering, den anden informerer om alle transaktioner, der blev udført på en given vært - både via replikering eller udført lokalt.
Opsætning af en replikeringsklynge på den nemme måde
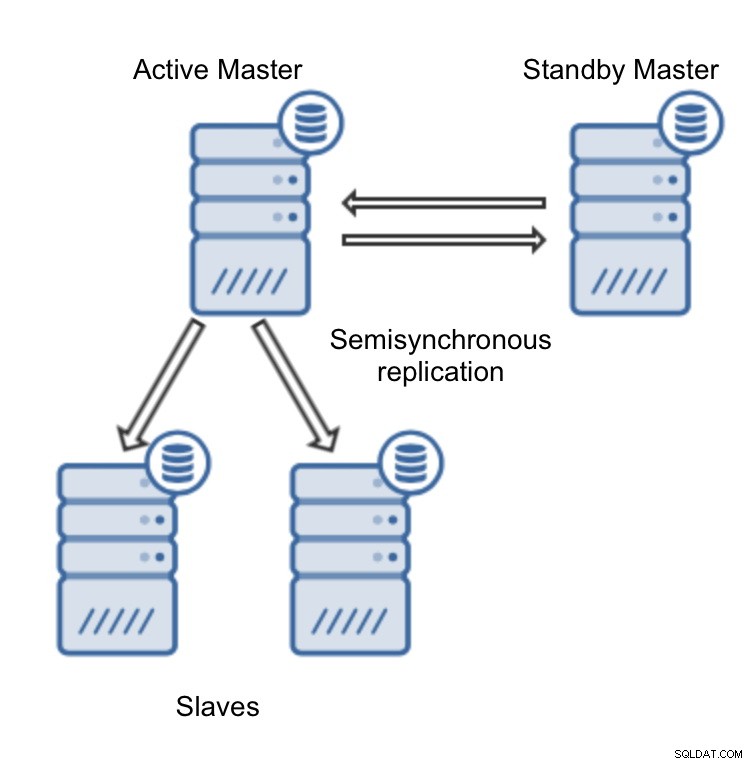
Implementering af MySQL replikeringsklynge er meget let i ClusterControl (du kan prøve det gratis). Den eneste forudsætning er, at alle værter, som du vil bruge til at implementere MySQL-noder til, kan tilgås fra ClusterControl-instansen ved hjælp af adgangskodefri SSH-forbindelse.
Når forbindelsen er på plads, kan du implementere en klynge ved at bruge indstillingen "Deploy". Når guidevinduet er åbent, skal du tage et par beslutninger - hvad vil du gøre? Vil du implementere en ny klynge? Implementer en Postgresql-node eller importer eksisterende klynge.
Vi ønsker at implementere en ny klynge. Vi vil derefter blive præsenteret for følgende skærmbillede, hvor vi skal beslutte, hvilken type klynge vi vil implementere. Lad os vælge replikering og derefter videregive de nødvendige detaljer om ssh-forbindelse.
Klik på Fortsæt, når du er klar. Denne gang skal vi beslutte, hvilken MySQL-leverandør vi vil bruge, hvilken version og et par konfigurationsindstillinger, herunder blandt andet adgangskode til root-kontoen i MySQL.
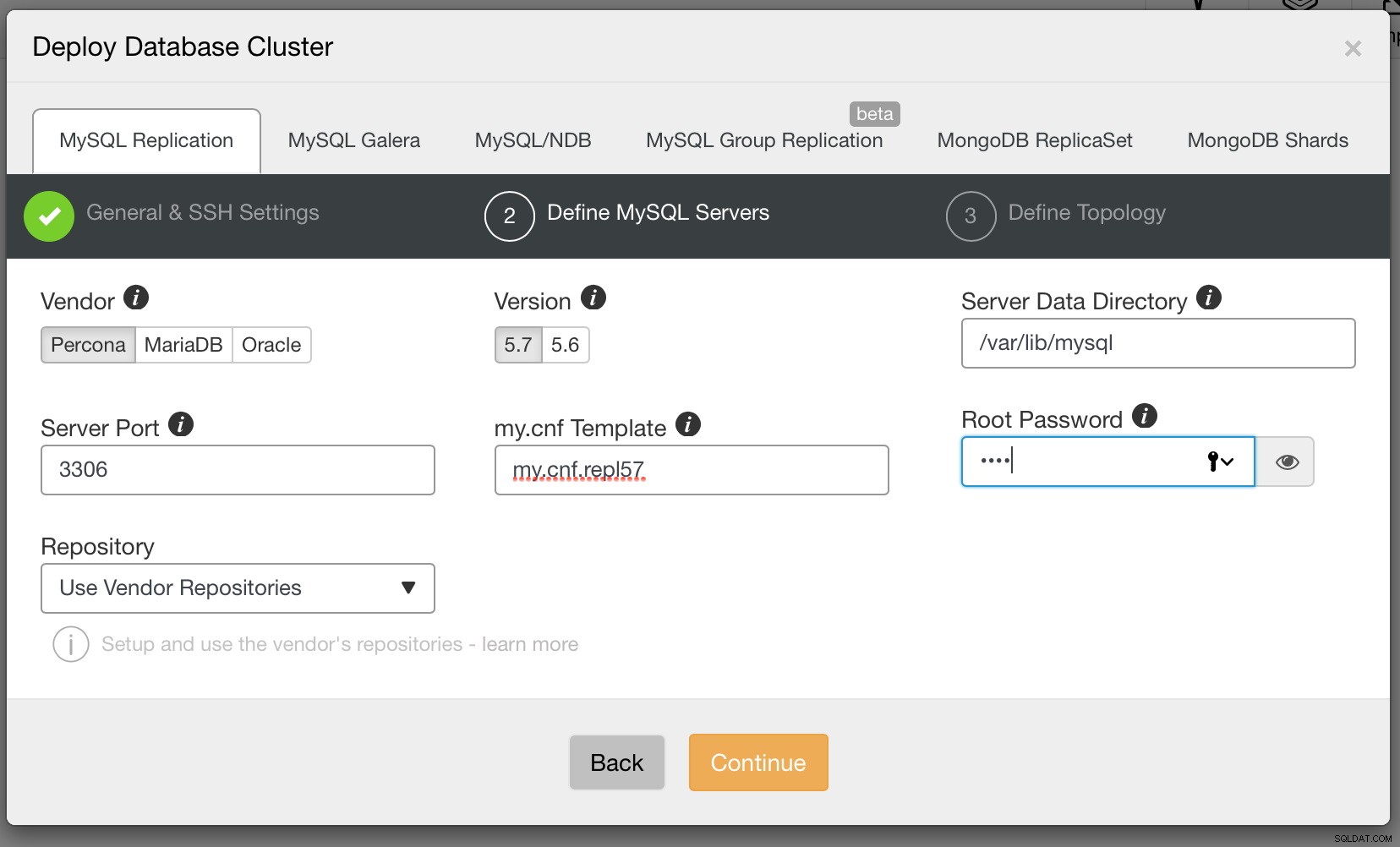
Til sidst skal vi tage stilling til replikeringstopologien - du kan enten bruge en typisk master - slave opsætning eller oprette mere kompleks, aktiv - standby master - master par (+ slaver, hvis du vil tilføje dem). Når du er klar, skal du blot klikke på "Deploy", og om et par minutter skulle du have din klynge installeret.
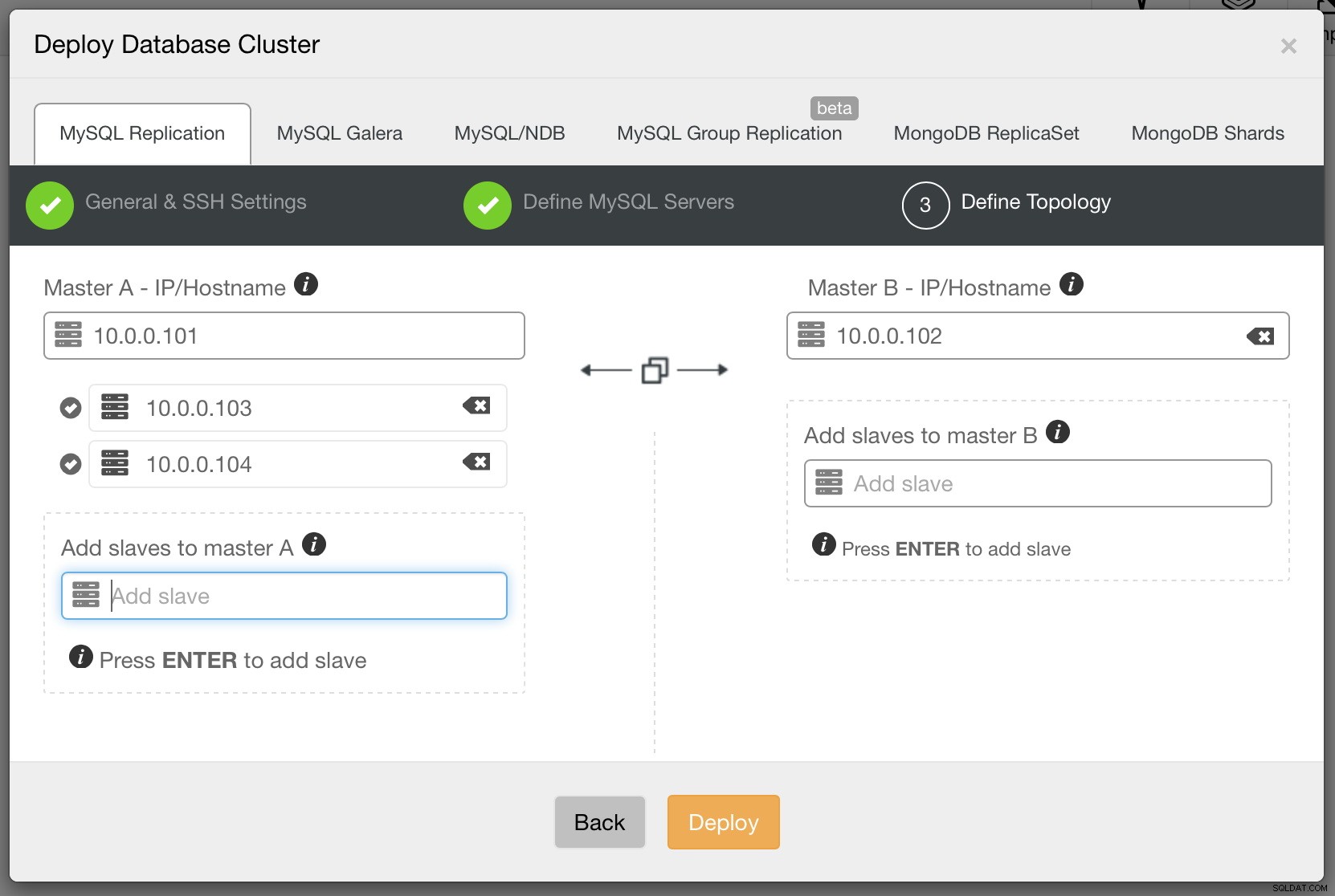
Når dette er gjort, vil du se din klynge i klyngelisten i ClusterControls brugergrænseflade.
Når replikeringen kører, kan vi se nærmere på, hvordan GTID fungerer.
Fejlgående transaktioner - hvad er problemet?
Som vi nævnte i begyndelsen af dette indlæg, bragte GTID en væsentlig ændring i den måde, folk bør tænke på MySQL-replikering. Det hele handler om vaner. Lad os sige, af en eller anden grund, at en applikation udførte en skrivning på en af slaverne. Det burde ikke være sket, men overraskende nok sker det hele tiden. Som et resultat stopper replikering med dubletnøglefejl. Der er et par måder at håndtere et sådant problem på. En af dem ville være at slette den stødende række og genstarte replikering. En anden ville være at springe den binære loghændelse over og derefter genstarte replikering.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter =1; START SLAVE SQL_THREAD; Begge måder skulle bringe replikering tilbage til arbejdet, men de kan introducere datadrift, så det er nødvendigt at huske, at slavekonsistensen skal kontrolleres efter en sådan hændelse (pt-table-checksum og pt-table-sync fungerer godt her).
Hvis der opstår et lignende problem, mens du bruger GTID, vil du bemærke nogle forskelle. Sletning af den stødende række kan se ud til at løse problemet, replikering burde kunne begynde. Den anden metode, ved at bruge sql_slave_skip_counter, virker slet ikke - den returnerer en fejl. Husk, det handler nu ikke om binlog-begivenheder, det handler om, at GTID bliver eksekveret eller ej.
Hvorfor lader det til at "slette" kun problemet? En af de vigtigste ting at huske på med hensyn til GTID er, at en slave, når den opretter forbindelse til masteren, tjekker, om den mangler nogen transaktioner, som blev udført på masteren. Disse kaldes fejlagtige transaktioner. Hvis en slave finder sådanne transaktioner, vil den udføre dem. Lad os antage, at vi kørte efter SQL for at rydde en stødende række:
DELETE FROM mytable WHERE id=100; Lad os tjekke vis slavestatus:
Master_uuid:966073f3-b6a4-11e4-af2c-080027880CA6 hentet_gtid_set:96607-, og 844-af1510-44-15-44-,-10-44-,-10-44-,-10-44-,-10-4-,-15-,-15-,-15-,-15-,-15-,-15-,-15-,-15-,-15-,-2011115011111501115011150111501115011150111501115011150111501115011150111501115, og 84-, ved at få 11e4-af2c-080027880ca6:1-29,Og se, hvor 84d15910-b6a4-11e4-af2c-080027880ca6:1 kommer fra:
mysql> VIS VARIABLER SOM 'server_uuid'\G**************************** 1. række **** ***********************Variabelnavn:server_uuid Værdi:84d15910-b6a4-11e4-af2c-080027880ca61 række i sæt (0,00 sek.) Som du kan se, har vi 29 transaktioner, der kom fra masteren, UUID på 966073f3-b6a4-11e4-af2c-080027880ca6 og en, der blev udført lokalt. Lad os sige, at vi på et tidspunkt failover, og masteren (966073f3-b6a4-11e4-af2c-080027880ca6) bliver en slave. Den vil tjekke sin liste over udførte GTID'er og vil ikke finde denne:84d15910-b6a4-11e4-af2c-080027880ca6:1. Som et resultat vil den relaterede SQL blive udført:
DELETE FROM mytable WHERE id=100; Dette er ikke noget, vi forventede... Hvis binlogen, der indeholder denne transaktion i mellemtiden, ville blive renset på den gamle slave, så vil den nye slave klage efter failover:
Last_IO_Error:Fik fatal fejl 1236 fra master ved læsning af data fra binær log:'Slaven opretter forbindelse ved hjælp af CHANGE MASTER TO MASTER_AUTO_POSITION =1, men masteren har slettet binære logfiler, der indeholder GTID'er, som slaven kræver.' Hvordan opdager man fejlagtige transaktioner?
MySQL har to funktioner, som er meget nyttige, når du vil sammenligne GTID-sæt på forskellige værter.
GTID_SUBSET() tager to GTID-sæt og kontrollerer, om det første sæt er en delmængde af det andet.
Lad os sige, at vi har følgende tilstand.
Mester:
mysql> vis masterstatus\G**************************** 1. række ********* ******************** Fil:binlog.000002 Position:160205927 Binlog_Do_DB:Binlog_Ignore_DB:Executed_Gtid_Set:8a6962d2-b907-11e4-bebc-080027880ca6:9b-094,41-094, b907-11e4-bebd-080027880ca6:1,ab8f5793-b907-11e4-bebd-080027880ca6:1-21 række i sæt (0,00 sek.) Slave:
mysql> vis slavestatus\G[...] Retrieved_Gtid_Set:8a6962d2-b907-11e4-bebc-080027880ca6:1-153,9b09b44a-b907-11e4-bebd-8e20d:8e4-bebd-8e27-06027-0602-0602-0809-0602-0602-0802-0602-0602-0607-0802-0609 -11e4-bebc-080027880ca6:1-153,9b09b44a-b907-11e4-bebd-080027880ca6:1,ab8f5793-b907-11e4-bebd-080027840code
Vi kan kontrollere, om slaven har fejlagtige transaktioner ved at udføre følgende SQL:
mysql> VÆLG GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027840ca6, '80027840ca6:72b-e-6:72-e-e 080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1_***set ************** 1. række ****************************er_undersæt:01 række i sæt (0,00 sek.) Det ser ud til, at der er fejlagtige transaktioner. Hvordan identificerer vi dem? Vi kan bruge en anden funktion, GTID_SUBTRACT()
mysql> VÆLG GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-0800217880ca'6:4c-e-1bd-1bd-0800217849'0800217880ca'6:4c-1bd-11-69'6:4c 080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') som mangler\***G*****) ************** 1. række ****************************** mangler:ab8f5793-b907- 11e4-bebd-080027880ca6:3-41 række i sæt (0,01 sek.) Vores manglende GTID'er er ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - disse transaktioner blev udført på slaven, men ikke på masteren.
Hvordan løser man problemer forårsaget af fejlagtige transaktioner?
Der er to måder - injicer tomme transaktioner eller udelad transaktioner fra GTID-historikken.
For at injicere tomme transaktioner kan vi bruge følgende SQL:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';Forespørgsel OK, 0 rækker påvirket (0,01 sek.) mysql> begynde; commit;Forespørgsel OK, 0 rækker påvirket (0,00 sek) Forespørgsel OK, 0 rækker påvirket (0,01 sek) mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';Forespørgsel OK, 0 rækker påvirket (0,00 sek.) mysql> begynde; commit;Forespørgsel OK, 0 rækker påvirket (0,00 sek)Forespørgsel OK, 0 rækker påvirket (0,01 sek) mysql> SET gtid_next=automatic;Forespørgsel OK, 0 rækker påvirket (0,00 sek.) Dette skal udføres på hver vært i replikeringstopologien, som ikke har disse GTID'er udført. Hvis masteren er tilgængelig, kan du injicere disse transaktioner der og lade dem replikere ned i kæden. Hvis masteren ikke er tilgængelig (for eksempel styrtede den ned), skal disse tomme transaktioner udføres på hver slave. Oracle udviklede et værktøj kaldet mysqlslavetrx, som er designet til at automatisere denne proces.
En anden tilgang er at fjerne GTID'erne fra historien:
Stop slave:
mysql> STOP SLAVE; Udskriv Executed_Gtid_Set på slaven:
mysql> VIS MASTER STATUS\G Nulstil GTID-oplysninger:
NULSTIL MASTER; Indstil GTID_PURGED til et korrekt GTID-sæt. baseret på data fra SHOW MASTER STATUS. Du bør udelukke fejlagtige transaktioner fra sættet.
Indstil global gtid_purged ='8a6962d2-b907-11e4-beBC-080027880CA6:1-153, 9B09B44A-B907-11e4-BeBD-080027880CA6:1, AB8F5793-B907-11E4-BDBD-0800278027:1, AB8F5793-B907-11E4BDBD-080000278022:1, AB8F5793 '; Start slave.
mysql> START SLAVE\G I alle tilfælde bør du verificere konsistensen af dine slaver ved hjælp af pt-table-checksum og pt-table-sync (hvis nødvendigt) - fejlagtig transaktion kan resultere i en datadrift.
Failover i ClusterControl
Fra version 1.4 forbedrede ClusterControl sine failover-håndteringsprocesser til MySQL-replikering. Du kan stadig udføre en manuel master switch ved at forfremme en af slaverne til master. Resten af slaverne vil derefter fail-over til den nye master. Fra version 1.4 har ClusterControl også mulighed for at udføre en fuldautomatisk failover, hvis masteren fejler. Vi dækkede det i dybden i et blogindlæg, der beskriver ClusterControl og automatiseret failover. Vi vil stadig gerne nævne en funktion, der er direkte relateret til emnet for dette indlæg.
Som standard udfører ClusterControl failover på en "sikker måde" - på tidspunktet for failover (eller switchover, hvis det er brugeren, der har udført en master switch), vælger ClusterControl en masterkandidat og verificerer derefter, at denne node ikke har nogen fejlagtige transaktioner hvilket vil påvirke replikering, når det først er forfremmet til master. Hvis en fejltransaktion opdages, stopper ClusterControl failover-processen, og masterkandidaten vil ikke blive forfremmet til at blive en ny master.
Hvis du vil være 100 % sikker på, at ClusterControl vil promovere en ny master, selvom nogle problemer (såsom fejlagtige transaktioner) opdages, kan du gøre det ved at bruge indstillingen replication_stop_on_error=0 i cmon-konfigurationen. Selvfølgelig, som vi diskuterede, kan det føre til problemer med replikering - slaver kan begynde at bede om en binær loghændelse, som ikke er tilgængelig længere.
For at håndtere sådanne sager tilføjede vi eksperimentel støtte til slavegenopbygning. Hvis du indstiller replication_auto_rebuild_slave=1 i cmon-konfigurationen, og din slave er markeret som nede med følgende fejl i MySQL, vil ClusterControl forsøge at genopbygge slaven ved hjælp af data fra masteren:
Fik fatal fejl 1236 fra master ved læsning af data fra binær log:'Slaven opretter forbindelse ved hjælp af CHANGE MASTER TO MASTER_AUTO_POSITION =1, men masteren har slettet binære logfiler, der indeholder GTID'er, som slaven kræver.'
En sådan indstilling er muligvis ikke altid passende, da genopbygningsprocessen vil inducere en øget belastning af masteren. Det kan også være, at dit datasæt er meget stort, og en regelmæssig genopbygning er ikke en mulighed - det er derfor, denne adfærd er deaktiveret som standard.