Replikering er en af de mest almindelige måder at opnå høj tilgængelighed for MySQL og MariaDB. Den er blevet meget mere robust med tilføjelsen af GTID'er og er grundigt testet af tusinder og atter tusinder af brugere. MySQL-replikering er dog ikke en 'sæt og glem'-egenskab, den skal overvåges for potentielle problemer og vedligeholdes, så den forbliver i god form. I dette blogindlæg vil vi gerne dele nogle tips og tricks til, hvordan man vedligeholder, fejlfinder og løser problemer med MySQL-replikering.
Hvordan afgør man, om MySQL-replikering er i god form?
Dette er uden tvivl den vigtigste færdighed, som enhver, der tager sig af en MySQL-replikeringsopsætning, skal besidde. Lad os tage et kig på, hvor vi skal lede efter oplysninger om replikationstilstanden. Der er en lille forskel mellem MySQL og MariaDB, og vi vil også diskutere dette.
VIS SLAVESTATUS
Dette er uden tvivl den mest almindelige metode til at kontrollere replikeringstilstanden på en slavevært - den har været med os siden altid, og det er normalt det første sted, vi går hen, hvis vi forventer, at der er et eller andet problem med replikering.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Nogle detaljer kan variere mellem MySQL og MariaDB, men størstedelen af indholdet vil se ens ud. Ændringer vil være synlige i GTID-sektionen, da MySQL og MariaDB gør det på en anden måde. Fra VIS SLAVE STATUS kan du udlede nogle informationer - hvilken master der bruges, hvilken bruger og hvilken port der bruges til at forbinde til masteren. Vi har nogle data om den aktuelle binære logposition (ikke så vigtig længere, da vi kan bruge GTID og glemme alt om binlogs) og tilstanden af SQL- og I/O-replikeringstråde. Så kan du se, om og hvordan filtrering er konfigureret. Du kan også finde nogle oplysninger om fejl, replikeringsforsinkelse, SSL-indstillinger og GTID. Eksemplet ovenfor kommer fra MySQL 5.7 slave, som er i en sund tilstand. Lad os tage et kig på et eksempel, hvor replikering er brudt.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Denne prøve er taget fra MariaDB 10.1, du kan se ændringer i bunden af outputtet for at få det til at fungere med MariaDB GTID'er. Det, der er vigtigt for os, er fejlen - du kan se, at noget ikke er rigtigt i SQL-tråden:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Vi vil diskutere dette særlige problem senere, for nu er det nok, at du vil se, hvordan du kan kontrollere, om der er nogen fejl i replikeringen ved hjælp af VIS SLAVESTATUS.
En anden vigtig information, der kommer fra VIS SLAVE STATUS er - hvor dårligt vores slave halter. Du kan tjekke det i kolonnen "Seconds_Behind_Master". Denne metric er især vigtig at spore, hvis du ved, at din applikation er følsom, når det kommer til uaktuelle læsninger.
I ClusterControl kan du spore disse data i afsnittet "Oversigt":
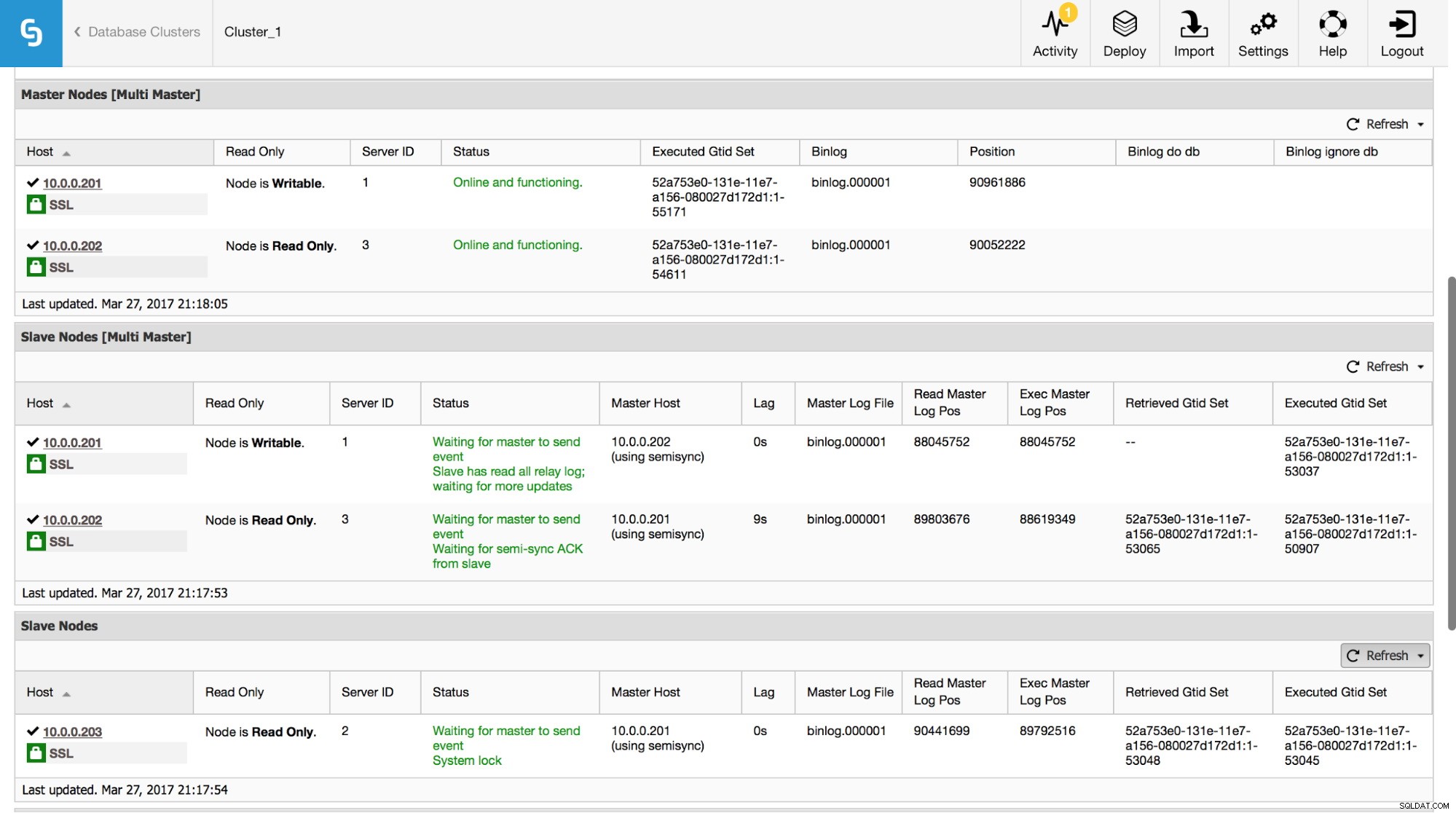
Vi har synliggjort alle de vigtigste informationer fra VIS SLAVE STATUS-kommandoen. Du kan kontrollere status for replikeringen, hvem der er master, om der er en replikeringsforsinkelse eller ej, binære logpositioner. Du kan også finde hentede og udførte GTID'er.
Performanceskema
Et andet sted, du kan lede efter oplysningerne om replikering, er performance_schema. Dette gælder kun for Oracles MySQL 5.7 - tidligere versioner og MariaDB indsamler ikke disse data.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Nedenfor kan du finde nogle eksempler på tilgængelige data i nogle af disse tabeller.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Som du kan se, kan vi verificere tilstanden af replikationen, sidste fejl, modtaget transaktionssæt og nogle flere data. Hvad der er vigtigt - hvis du aktiverede flertrådsreplikering i tabellen replication_applier_status_by_worker, vil du se tilstanden for hver enkelt arbejder - dette hjælper dig med at forstå replikeringstilstanden for hver af arbejdertrådene.
Replikeringsforsinkelse
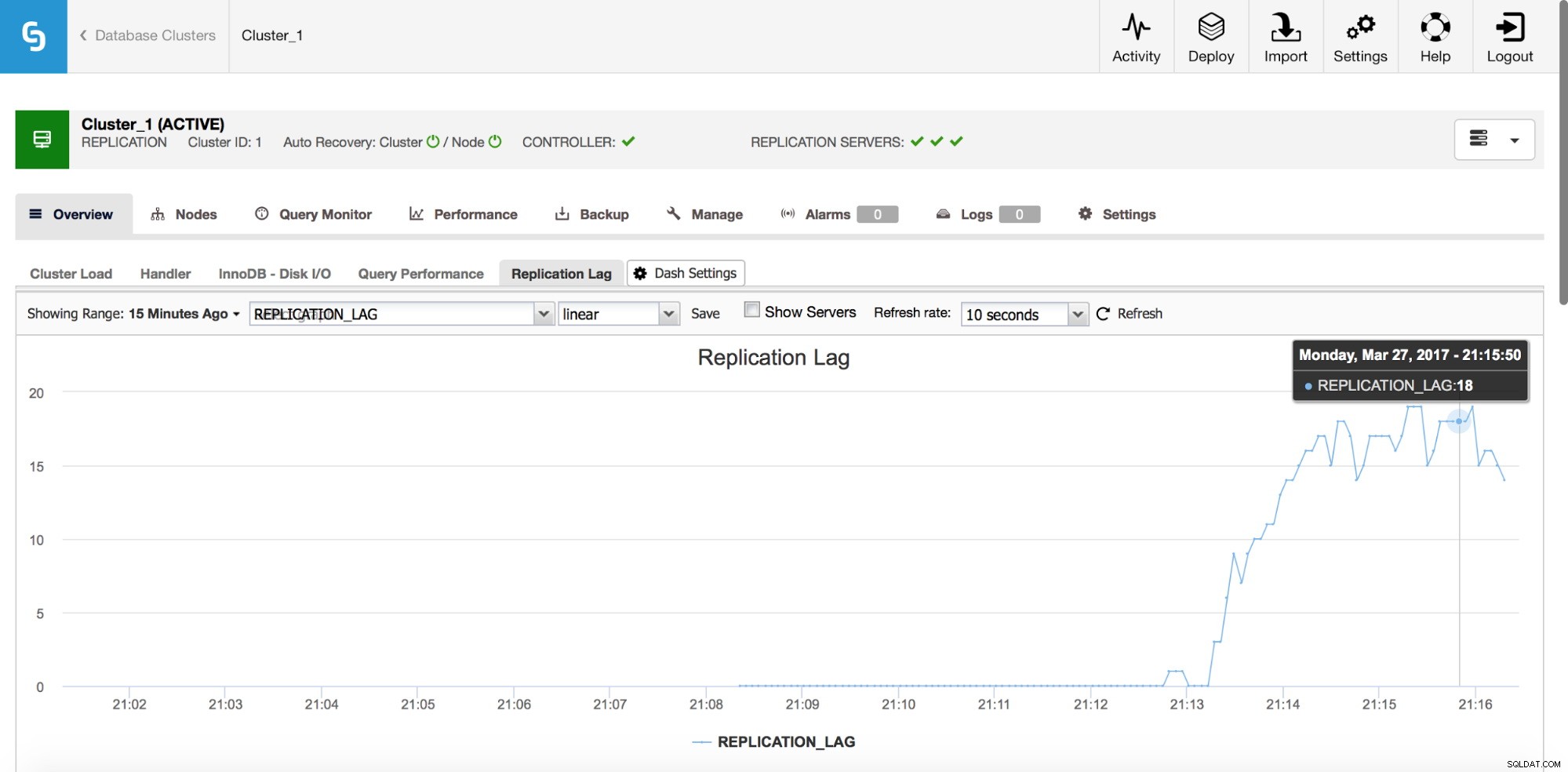
Lag er absolut et af de mest almindelige problemer, du vil stå over for, når du arbejder med MySQL-replikering. Replikeringsforsinkelsen dukker op, når en af slaverne ikke er i stand til at følge med mængden af skriveoperationer udført af masteren. Årsagerne kan være forskellige - forskellig hardwarekonfiguration, tungere belastning af slaven, høj grad af skriveparallelisering på master, som skal serialiseres (når du bruger en enkelt tråd til replikeringen), eller skrivningerne kan ikke paralleliseres i samme omfang, som det har gjort. været på masteren (når du bruger flertrådsreplikering).
Hvordan registreres det?
Der er et par metoder til at opdage replikationsforsinkelsen. Først og fremmest kan du tjekke "Seconds_Behind_Master" i VIS SLAVE STATUS output - det vil fortælle dig, om slaven halter eller ej. Det fungerer godt i de fleste tilfælde, men i mere komplekse topologier, når du bruger mellemliggende mastere, på værter et sted lavt i replikationskæden, er det muligvis ikke præcist. En anden, bedre, løsning er at stole på eksterne værktøjer som pt-heartbeat. Idéen er enkel - en tabel oprettes med blandt andet en tidsstempelkolonne. Denne kolonne opdateres på masteren med jævne mellemrum. På en slave kan du så sammenligne tidsstemplet fra den kolonne med det aktuelle tidspunkt - det vil fortælle dig, hvor langt bagefter slaven er.
Uanset hvordan du beregner forsinkelsen, skal du sørge for, at dine værter er tidsmæssigt synkroniserede. Brug ntpd eller andre måder til tidssynkronisering - hvis der er en tidsdrift, vil du se "falsk" lag på dine slaver.
Hvordan reduceres forsinkelsen?
Dette er ikke et let spørgsmål at besvare. Kort sagt afhænger det af, hvad der forårsager forsinkelsen, og hvad der blev en flaskehals. Der er to typiske mønstre - slave er I/O-bundet, hvilket betyder, at dets I/O-undersystem ikke kan klare mængden af skrive- og læseoperationer. For det andet - slave er CPU-bundet, hvilket betyder, at replikeringstråden bruger al den CPU, den kan (én tråd kan kun bruge én CPU-kerne), og den er stadig ikke nok til at håndtere alle skriveoperationer.
Når CPU er en flaskehals, kan løsningen være så enkel som at bruge multi-threaded replikering. Øg antallet af arbejdstråde for at tillade højere parallelisering. Det er dog ikke altid muligt - i sådanne tilfælde vil du måske gerne lege lidt med gruppe commit-variabler (for både MySQL og MariaDB) for at forsinke commits i en lille periode (vi taler om millisekunder her) og på denne måde , øge parallelisering af commits.
Hvis problemet er i I/O, er problemet lidt sværere at løse. Du skal selvfølgelig gennemgå dine InnoDB I/O-indstillinger – måske er der plads til forbedringer. Hvis my.cnf-tuning ikke hjælper, har du ikke for mange muligheder - forbedre dine forespørgsler (hvor det er muligt) eller opgrader dit I/O-undersystem til noget mere dygtigt.
De fleste af proxyerne (f.eks. alle proxyer, der kan implementeres fra ClusterControl:ProxySQL, HAProxy og MaxScale) giver dig mulighed for at fjerne en slave ud af rotation, hvis replikationsforsinkelsen krydser en foruddefineret tærskel. Dette er på ingen måde en metode til at reducere forsinkelsen, men det kan være nyttigt at undgå forældede læsninger og, som en bivirkning, at reducere belastningen på en slave, hvilket burde hjælpe den med at indhente det.
Selvfølgelig kan forespørgselsjustering være en løsning i begge tilfælde - det er altid godt at forbedre forespørgsler, der er CPU- eller I/O-tunge.
Fejlagtige transaktioner
Errant-transaktioner er transaktioner, der kun er blevet udført på en slave, ikke på masteren. Kort sagt, de laver en slave i uoverensstemmelse med mesteren. Når du bruger GTID-baseret replikering, kan dette forårsage alvorlige problemer, hvis slaven forfremmes til en master. Vi har et dybdegående indlæg om dette emne, og vi opfordrer dig til at se nærmere på det og blive fortrolig med, hvordan du opdager og løser problemer med fejlagtige transaktioner. Vi inkluderede også oplysninger om, hvordan ClusterControl registrerer og håndterer fejlagtige transaktioner.
Ingen binlogfil på masteren
Hvordan identificerer man problemet?
Under nogle omstændigheder kan det ske, at en slave opretter forbindelse til en master og beder om en ikke-eksisterende binær logfil. En årsag til dette kunne være den fejlagtige transaktion - på et tidspunkt er en transaktion blevet udført på en slave, og senere bliver denne slave en master. Andre værter, som er konfigureret til at slave fra den master, vil bede om den manglende transaktion. Hvis det blev udført for lang tid siden, er der en chance for, at binære logfiler allerede er blevet slettet.
Et andet, mere typisk eksempel - du vil klargøre en slave ved hjælp af xtrabackup. Du kopierer sikkerhedskopien på en vært, anvender loggen, ændrer ejeren af MySQL-databiblioteket - typiske handlinger, du udfører for at gendanne en sikkerhedskopi. Du udfører
SET GLOBAL gtid_purged=baseret på dataene fra xtrabackup_binlog_info og du kører CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (dette er i MySQL, MariaDB har en lidt anden proces), start slaven og så ender du med en fejl som:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'i MySQL eller:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'i MariaDB.
Dette betyder grundlæggende, at masteren ikke har alle binære logfiler, der er nødvendige for at udføre alle manglende transaktioner. Sandsynligvis er sikkerhedskopien for gammel, og masteren har allerede renset nogle af binære logfiler, der er oprettet mellem det tidspunkt, hvor sikkerhedskopien blev oprettet, og da slaven blev klargjort.
Hvordan løses dette problem?
Desværre er der ikke meget du kan gøre i dette særlige tilfælde. Hvis du har nogle MySQL-værter, som gemmer binære logfiler i længere tid end masteren, kan du prøve at bruge disse logfiler til at afspille manglende transaktioner på slaven igen. Lad os tage et kig på, hvordan det kan gøres.
Først og fremmest, lad os tage et kig på det ældste GTID i masterens binære logfiler:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Så 'binlog.000021' er den seneste (og eneste) fil. Lad os tjekke, hvad der er den første GTID-post i denne fil:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Som vi kan se, er den ældste binære logindgang, der er tilgængelig:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Vi skal også kontrollere, hvad der er det sidste GTID, der er dækket af sikkerhedskopien:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Det er:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666, så vi mangler to begivenheder:
5d1e2227-07c6-11e7-8123-0800274195a:-1066:-1666:-1666:-1666
Lad os se, om vi kan finde disse transaktioner på en anden slave.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Det ser ud til, at 'binlog.000003' er den seneste binære log. Vi skal tjekke, om vores manglende GTID'er kan findes i den:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Husk, at du måske ønsker at kopiere binlog-filer uden for produktionsserveren, da behandling af dem kan tilføje en vis belastning. Da vi bekræftede, at disse GTID'er eksisterer, kan vi udtrække dem:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlEfter en hurtig scp kan vi anvende disse hændelser på slaven
slave1:~# mysql -ppass < to_apply_on_slave1.sqlNår det er gjort, kan vi kontrollere, om disse GTID'er er blevet anvendt ved at se på outputtet af VIS SLAVESTATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set ser godt ud, derfor kan vi starte slavetråde:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Lad os tjekke om det fungerede fint. Vi vil igen bruge SHOW SLAVE STATUS output:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Det ser godt ud, det er oppe at køre!
En anden metode til at løse dette problem vil være at tage en sikkerhedskopi endnu en gang og klargøre slaven igen ved at bruge friske data. Dette vil sandsynligvis være hurtigere og helt sikkert mere pålideligt. Det er ikke ofte, at du har forskellige binlog-rensningspolitikker på master og på slaver)
Vi vil fortsætte med at diskutere andre typer replikeringsproblemer i det næste blogindlæg.