Galera Cluster, med sin (stort set) synkrone replikering, er almindeligt anvendt i mange forskellige typer miljøer. Det er ikke svært at skalere det ved at tilføje nye noder (eller lige så enkelt et par klik, når du bruger ClusterControl).
Hovedproblemet med synkron replikering er vel den synkrone del, som ofte resulterer i, at hele klyngen kun er så hurtig som dens langsomste knude. Enhver skrivning, der udføres på en klynge, skal replikeres til alle noderne og certificeres på dem. Hvis denne proces af en eller anden grund bliver langsommere, kan det alvorligt påvirke klyngens evne til at imødekomme skrivninger. Flowstyringen vil så starte, dette er for at sikre, at den langsomste node stadig kan følge med belastningen. Dette gør det ret vanskeligt for nogle af de almindelige scenarier, der sker i et virkeligt miljø.
Lad os først diskutere geografisk fordelt katastrofeoprettelse. Selvfølgelig kan du køre klynger på tværs af et Wide Area Network, men den øgede latenstid vil have en betydelig indflydelse på klyngens ydeevne. Dette begrænser i høj grad muligheden for at bruge sådan en opsætning, især over længere afstande, når forsinkelsen er højere.
En anden ganske almindelig use case - et testmiljø til større versionsopgradering. Det er ikke en god idé at blande forskellige versioner af MariaDB Galera Cluster noder i samme klynge, selvom det er muligt. På den anden side kræver migrering til den nyere version detaljerede tests. Ideelt set ville både læsning og skrivning være blevet testet. En måde at opnå det på er at oprette en separat Galera-klynge og køre testene, men du vil gerne køre test i et miljø så tæt på produktionen som muligt. Når først den er klargjort, kan en klynge bruges til tests med forespørgsler fra den virkelige verden, men det ville være svært at generere en arbejdsbyrde, der ville være tæt på produktionen. Du kan ikke flytte noget af produktionstrafikken til et sådant testsystem, det er fordi dataene ikke er aktuelle.
Endelig selve migrationen. Igen, hvad vi sagde tidligere, selvom det er muligt at blande gamle og nye versioner af Galera-noder i samme klynge, er det ikke den sikreste måde at gøre det på.
Heldigvis ville den enkleste løsning for alle disse tre problemer være at forbinde separate Galera-klynger med en asynkron replikering. Hvad gør det til en så god løsning? Nå, det er asynkront, hvilket gør, at det ikke påvirker Galera-replikationen. Der er ingen flowkontrol, så "master"-klyngens ydeevne vil ikke blive påvirket af "slave"-klyngens ydeevne. Som med enhver asynkron replikering kan en forsinkelse dukke op, men så længe den holder sig inden for acceptable grænser, kan den fungere helt fint. Du skal også huske på, at asynkron replikering i dag kan paralleliseres (flere tråde kan arbejde sammen for at øge båndbredden) og reducere replikeringsforsinkelsen yderligere.
I dette blogindlæg vil vi diskutere, hvad der er trinene til at implementere asynkron replikering mellem MariaDB Galera-klynger.
Hvordan konfigureres asynkron replikering mellem MariaDB Galera-klynger?
Først og fremmest er vi nødt til at implementere en klynge. Til vores formål opsætter vi en klynge med tre knudepunkter. Vi vil holde opsætningen på et minimum, så vi vil ikke diskutere kompleksiteten af applikationen og proxylaget. Proxy-lag kan være meget nyttigt til håndtering af opgaver, som du ønsker at implementere asynkron replikering til - omdirigering af en delmængde af den skrivebeskyttede trafik til testklyngen, hvilket hjælper i katastrofegendannelsessituationen, når "hoved"-klyngen ikke er tilgængelig ved at omdirigere trafik til DR-klyngen. Der er adskillige proxyer, du kan prøve, afhængigt af dine præferencer - HAProxy, MaxScale eller ProxySQL - alle kan bruges i sådanne opsætninger, og afhængigt af tilfældet kan nogle af dem muligvis hjælpe dig med at administrere din trafik.
Konfiguration af kildeklyngen
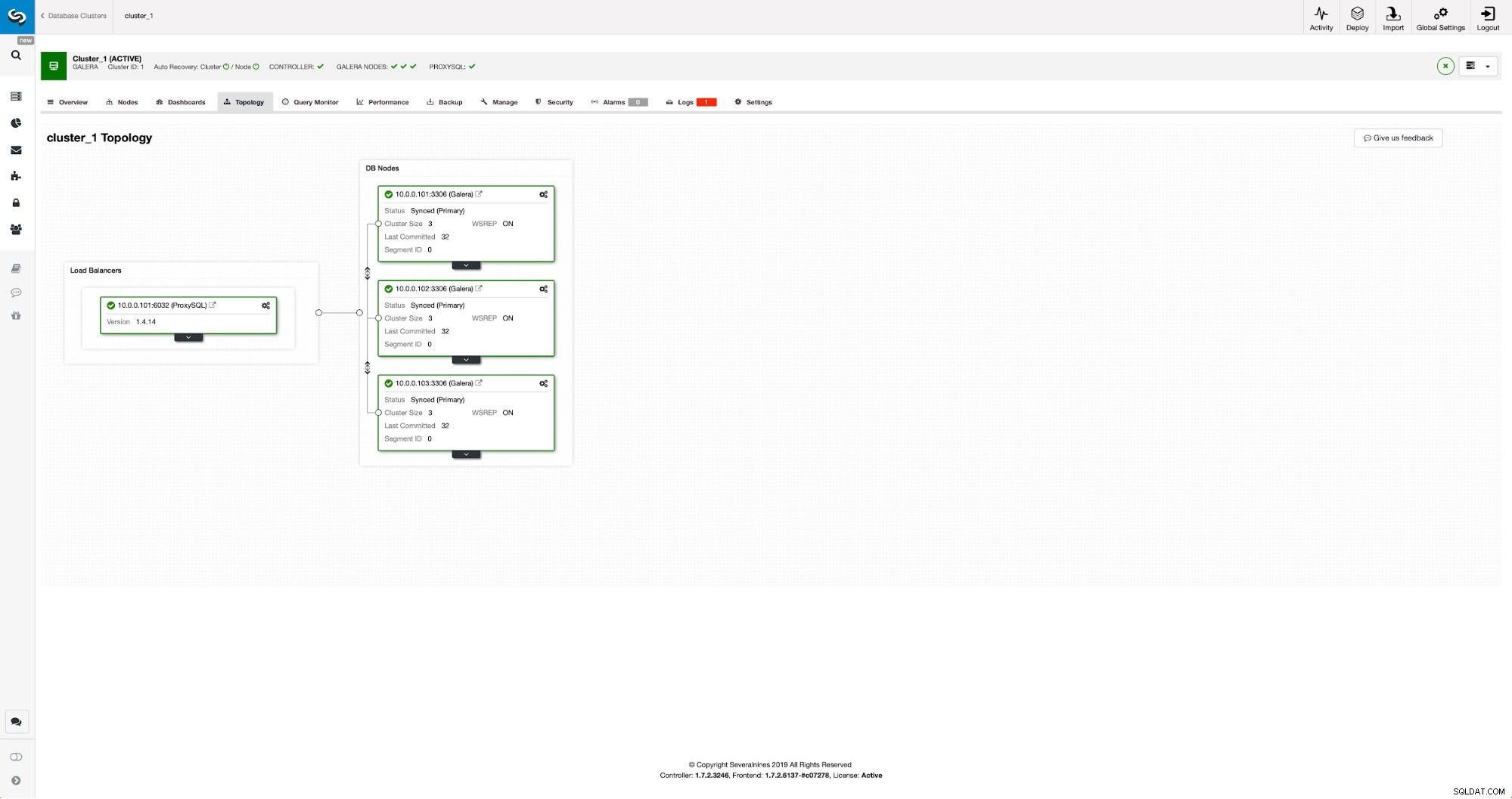
Vores klynge består af tre MariaDB 10.3 noder, vi implementerede også ProxySQL til at lave læse-skrive-opdelingen og distribuere trafikken på tværs af alle noder i klyngen. Dette er ikke en installation i produktionsklasse, for det ville vi være nødt til at implementere flere ProxySQL-noder og en Keepalived ovenpå dem. Det er stadig nok til vores formål. For at opsætte asynkron replikering skal vi have en binær log aktiveret på vores klynge. Mindst én node, men det er bedre at holde den aktiveret på dem alle, hvis den eneste node med binlog aktiveret går ned - så vil du have en anden node i klyngen op at køre, som du kan slave af.
Når du aktiverer binær log, skal du sørge for at konfigurere den binære log-rotation, så de gamle logfiler bliver fjernet på et tidspunkt. Du vil bruge ROW binært log-format. Du bør også sikre dig, at du har GTID konfigureret og i brug - det vil være meget praktisk, når du skal genslave din "slave"-klynge, eller hvis du skal aktivere flertrådsreplikering. Da dette er en Galera-klynge, vil du have 'wsrep_gtid_domain_id' konfigureret og 'wsrep_gtid_mode' aktiveret. Disse indstillinger vil sikre, at GTID'er vil blive genereret for den trafik, der kommer fra Galera-klyngen. Yderligere information kan findes i dokumentationen. Når alt dette er gjort, kan du fortsætte med at opsætte den anden klynge.
Opsætning af målklyngen
Da der i øjeblikket ikke er nogen målklynge, er vi nødt til at starte med at implementere den. Vi vil ikke dække disse trin i detaljer, du kan finde instruktioner i dokumentationen. Generelt består processen af flere trin:
- Konfigurer MariaDB-lagre
- Installer MariaDB 10.3-pakker
- Konfigurer noder til at danne en klynge
I begyndelsen starter vi med kun én node. Du kan konfigurere dem alle til at danne en klynge, men så skal du stoppe dem og kun bruge én til næste trin. Den ene node bliver en slave af den oprindelige klynge. Vi vil bruge mariabackup til at klargøre det. Derefter konfigurerer vi replikeringen.
Først skal vi oprette en mappe, hvor vi gemmer sikkerhedskopien:
mkdir /mnt/mariabackupDerefter udfører vi sikkerhedskopien og opretter den i mappen, der er udarbejdet i trin ovenfor. Sørg for at bruge den korrekte bruger og adgangskode til at oprette forbindelse til databasen:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Dernæst skal vi kopiere backupfilerne til den første node i den anden klynge. Vi brugte scp til det, du kan bruge hvad du vil - rsync, netcat, alt hvad der virker.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Efter at sikkerhedskopien er blevet kopieret, skal vi forberede den ved at anvende logfilerne:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!I tilfælde af fejl bliver du muligvis nødt til at udføre sikkerhedskopien igen. Hvis alt gik ok, kan vi fjerne de gamle data og erstatte dem med sikkerhedskopieringsoplysningerne
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Vi ønsker også at indstille den korrekte ejer af filerne:
chown -R mysql.mysql /var/lib/mysql/Vi vil stole på GTID for at holde replikeringen konsistent, så vi er nødt til at se, hvad der var det sidst anvendte GTID i denne backup. Disse oplysninger kan findes i filen xtrabackup_info, der er en del af sikkerhedskopien:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Vi bliver også nødt til at sikre, at slaveknuden har binære logfiler aktiveret sammen med 'log_slave_updates'. Ideelt set vil dette være aktiveret på alle noderne i den anden klynge - bare i tilfælde af at "slaveknuden" mislykkedes, og du bliver nødt til at konfigurere replikationen ved hjælp af en anden node i slaveklyngen.
Det sidste, vi skal gøre, før vi kan konfigurere replikeringen, er at oprette en bruger, som vi skal bruge til at køre replikeringen:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Det er alt, hvad vi har brug for. Nu kan vi starte den første node i den anden klynge, vores to-be-slave:
galera_new_clusterNår den er startet, kan vi gå ind i MySQL CLI og konfigurere den til at blive en slave ved at bruge den GITD-position, vi fandt et par trin tidligere:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Når det er gjort, kan vi endelig konfigurere replikeringen og starte den:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)På dette tidspunkt har vi en Galera-klynge bestående af én node. Denne node er også en slave af den originale klynge (især dens master er node 10.0.0.101). For at tilslutte os andre noder vil vi bruge SST, men for at få det til at fungere først skal vi sikre, at SST-konfigurationen er korrekt - husk venligst, at vi lige har erstattet alle brugerne i vores anden klynge med indholdet af kildeklyngen. Hvad du skal gøre nu er at sikre, at 'wsrep_sst_auth'-konfigurationen af den anden klynge matcher den i den første klynge. Når det er gjort, kan du starte de resterende noder én efter én, og de skal slutte sig til den eksisterende node (10.0.0.104), hente dataene over SST og danne Galera-klyngen. Til sidst skulle du ende med to klynger, tre noder hver, med asynkron replikationslink på tværs af dem (fra 10.0.0.101 til 10.0.0.104 i vores eksempel). Du kan bekræfte, at replikeringen virker ved at kontrollere værdien af:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Hvordan konfigureres asynkron replikering mellem MariaDB Galera-klynger ved hjælp af ClusterControl?
På tidspunktet for denne blog har ClusterControl ikke funktionaliteten til at konfigurere asynkron replikering på tværs af flere klynger, vi arbejder på det, mens jeg skriver dette. Ikke desto mindre kan ClusterControl være til stor hjælp i denne proces - vi viser dig, hvordan du kan fremskynde de besværlige manuelle trin ved hjælp af automatisering leveret af ClusterControl.
Ud fra det, vi viste før, kan vi konkludere, at det er de generelle trin, du skal tage, når du opsætter replikering mellem to Galera-klynger:
- Implementer en ny Galera-klynge
- Tilbered ny klynge ved hjælp af data fra den gamle
- Konfigurer ny klynge (SST-konfiguration, binære logfiler)
- Opsæt replikeringen mellem den gamle og den nye klynge
De første tre punkter er noget, du nemt kan gøre ved at bruge ClusterControl selv nu. Vi skal vise dig, hvordan du gør det.
Implementer og klargør en ny MariaDB Galera Cluster ved hjælp af ClusterControl
Udgangssituationen er den samme - vi har én klynge oppe at køre. Vi skal sætte den anden op. En af de nyere funktioner i ClusterControl er en mulighed for at implementere en ny klynge og klargøre den ved hjælp af dataene fra backup. Dette er meget nyttigt til at skabe testmiljøer, det er også en mulighed, vi vil bruge til at klargøre vores nye klynge til replikeringsopsætningen. Derfor er det første skridt, vi tager, at oprette en sikkerhedskopi ved hjælp af mariabackup:
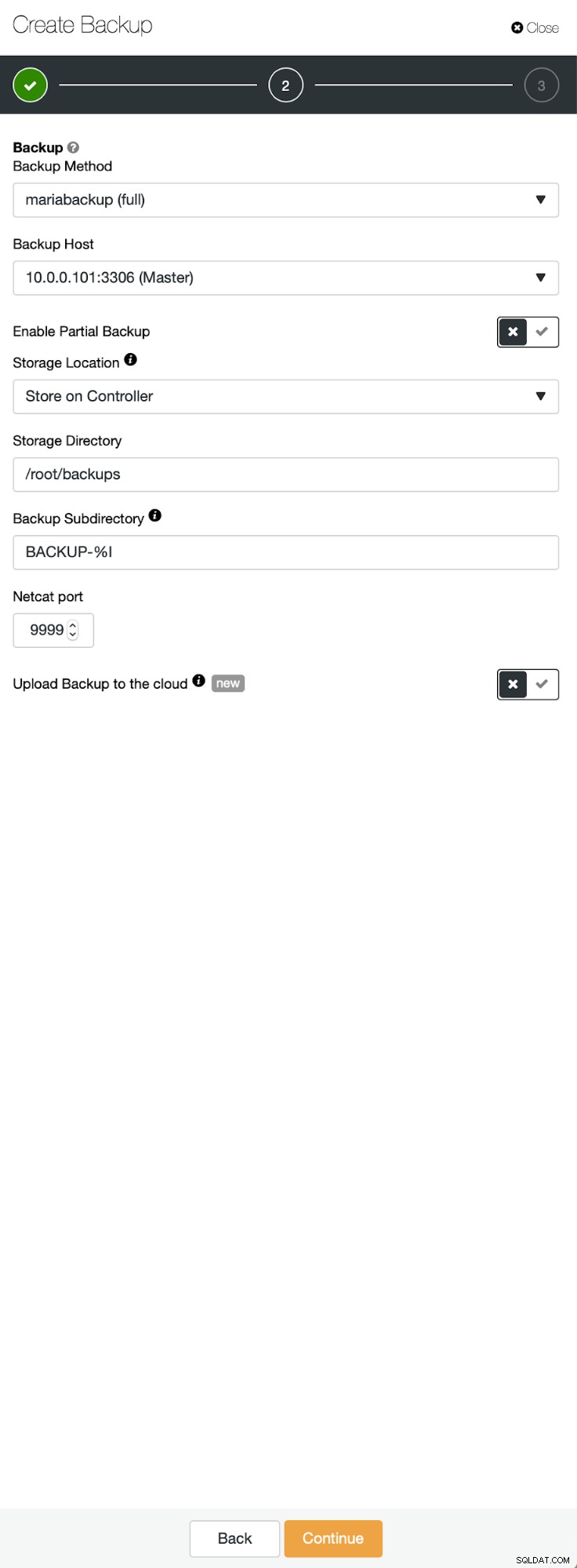
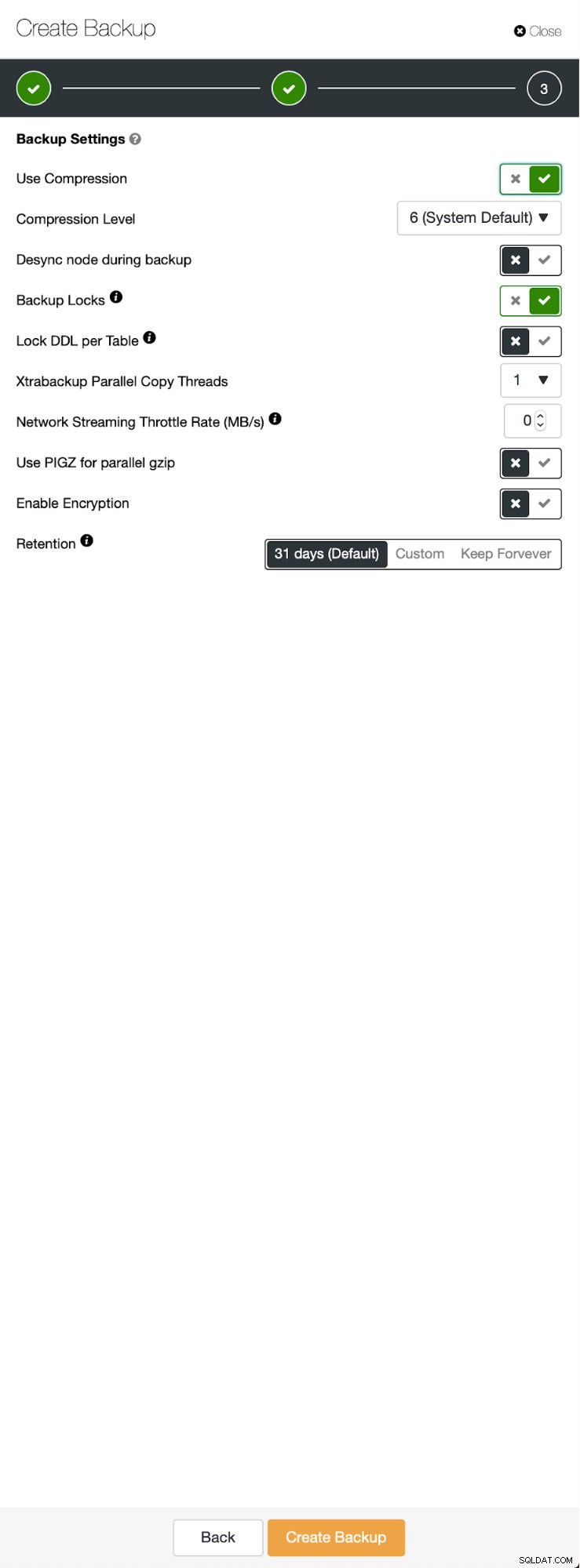
Tre trin, hvor vi valgte noden for at tage backup fra den. Denne node (10.0.0.101) bliver en master. Det skal have binære logfiler aktiveret. I vores tilfælde har alle noderne binlog aktiveret, men hvis de ikke havde det, er det meget nemt at aktivere det fra ClusterControl - vi viser trinene senere, når vi gør det for den anden klynge.
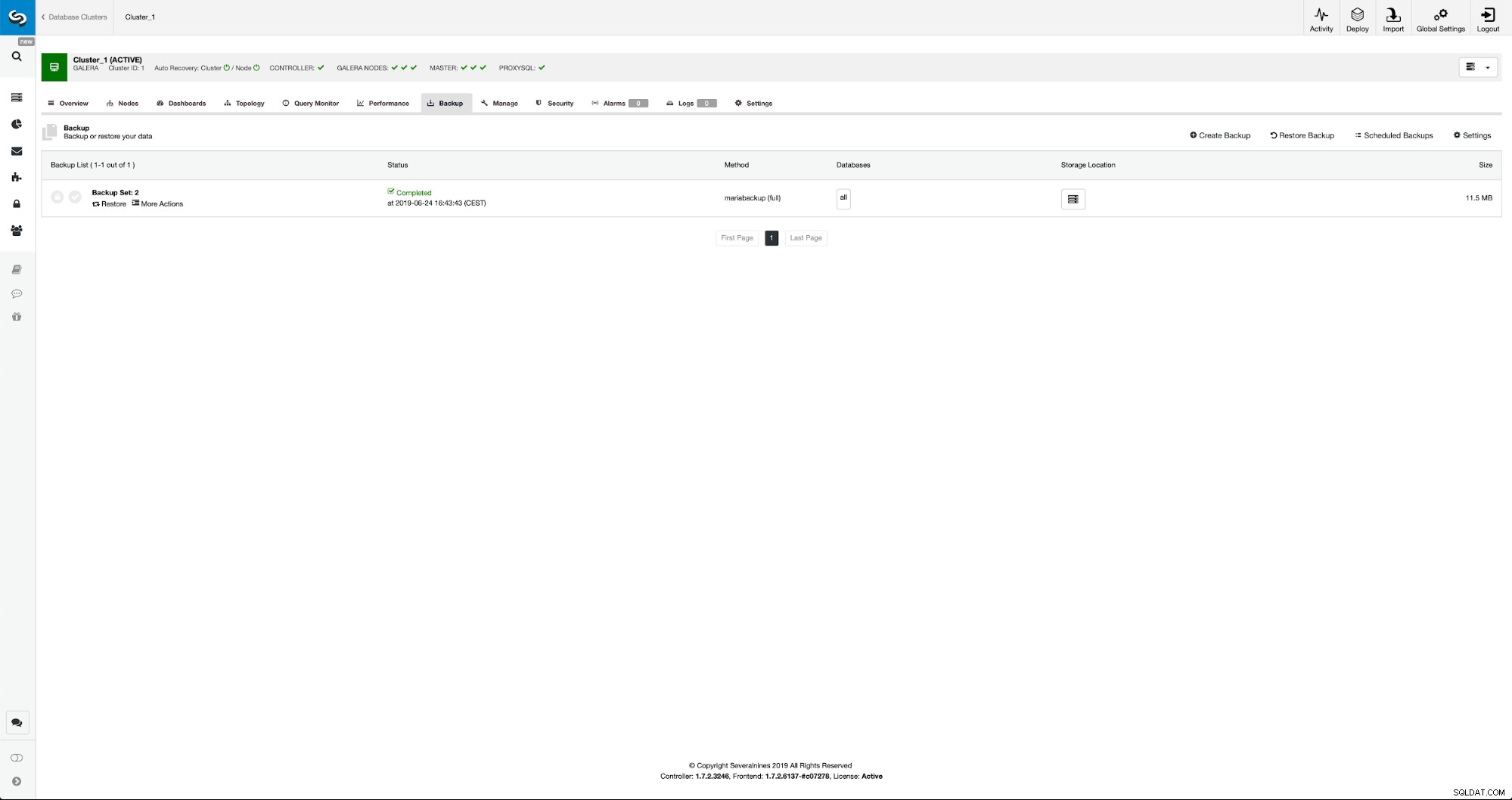
Når sikkerhedskopieringen er fuldført, vil den blive synlig på listen. Vi kan derefter fortsætte og gendanne den:

Skulle vi ønske det, kunne vi endda udføre Point-In-Time Recovery, men i vores tilfælde betyder det ikke rigtig noget:Når replikeringen er konfigureret, vil alle nødvendige transaktioner fra binlogs blive anvendt på den nye klynge.

Derefter vælger vi muligheden for at oprette en klynge fra sikkerhedskopien. Dette åbner en anden dialogboks:
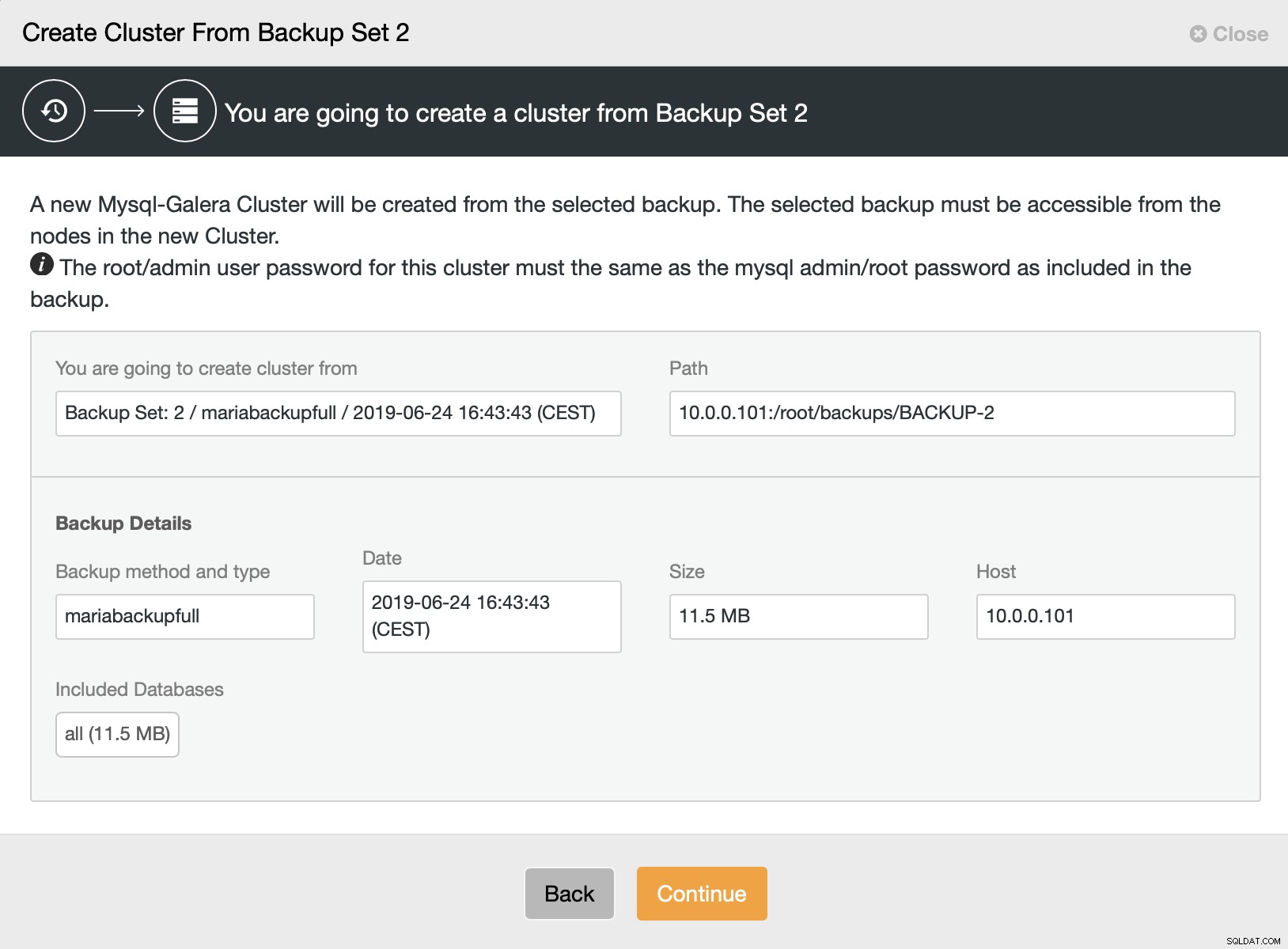
Det er en bekræftelse af, hvilken sikkerhedskopi der vil blive brugt, hvilken vært sikkerhedskopien blev taget fra, hvilken metode der blev brugt til at oprette den og nogle metadata for at hjælpe med at kontrollere, om sikkerhedskopien ser sund ud.
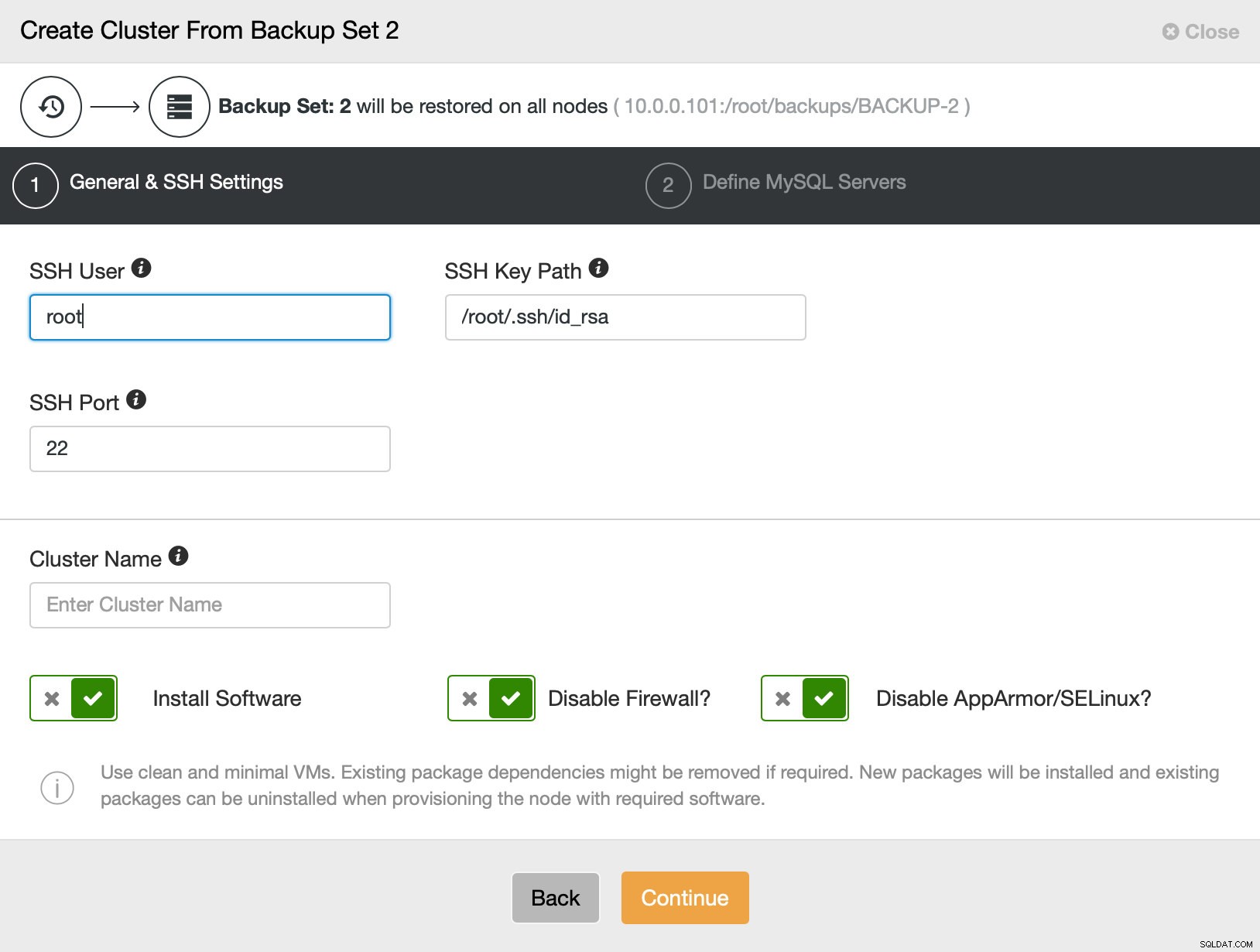
Derefter går vi dybest set til den almindelige implementeringsguide, hvor vi skal definere SSH-forbindelse mellem ClusterControl-værten og de noder, som klyngen skal implementeres på (kravet til ClusterControl) og, i andet trin, leverandør, version, adgangskode og noder, der skal implementeres på:
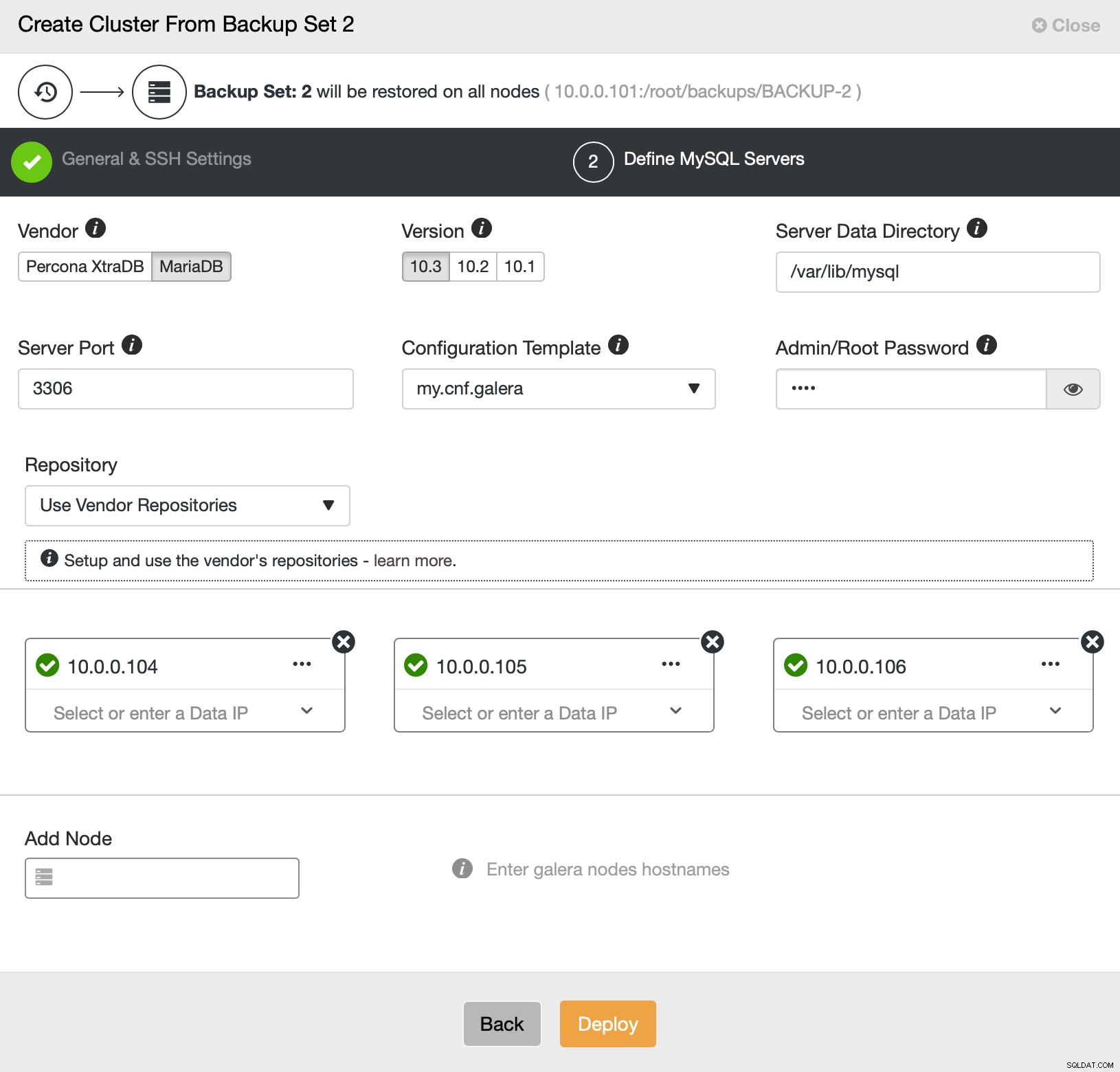
Det handler alt sammen om implementering og klargøring. ClusterControl vil konfigurere den nye klynge, og den vil klargøre den ved hjælp af data fra den gamle.
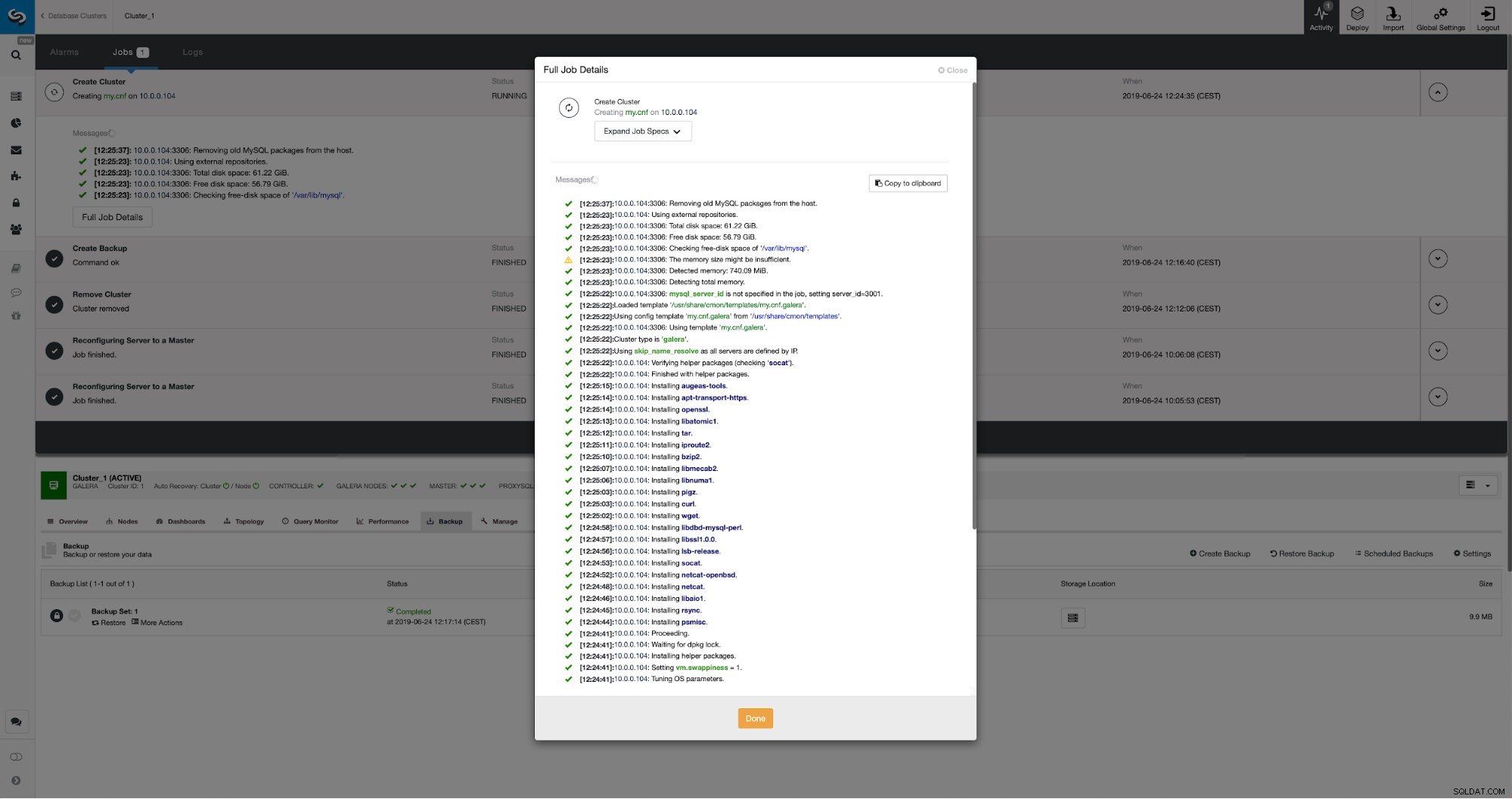
Vi kan følge udviklingen i aktivitetsfanen. Når den er fuldført, vises den anden klynge på klyngelisten i ClusterControl.
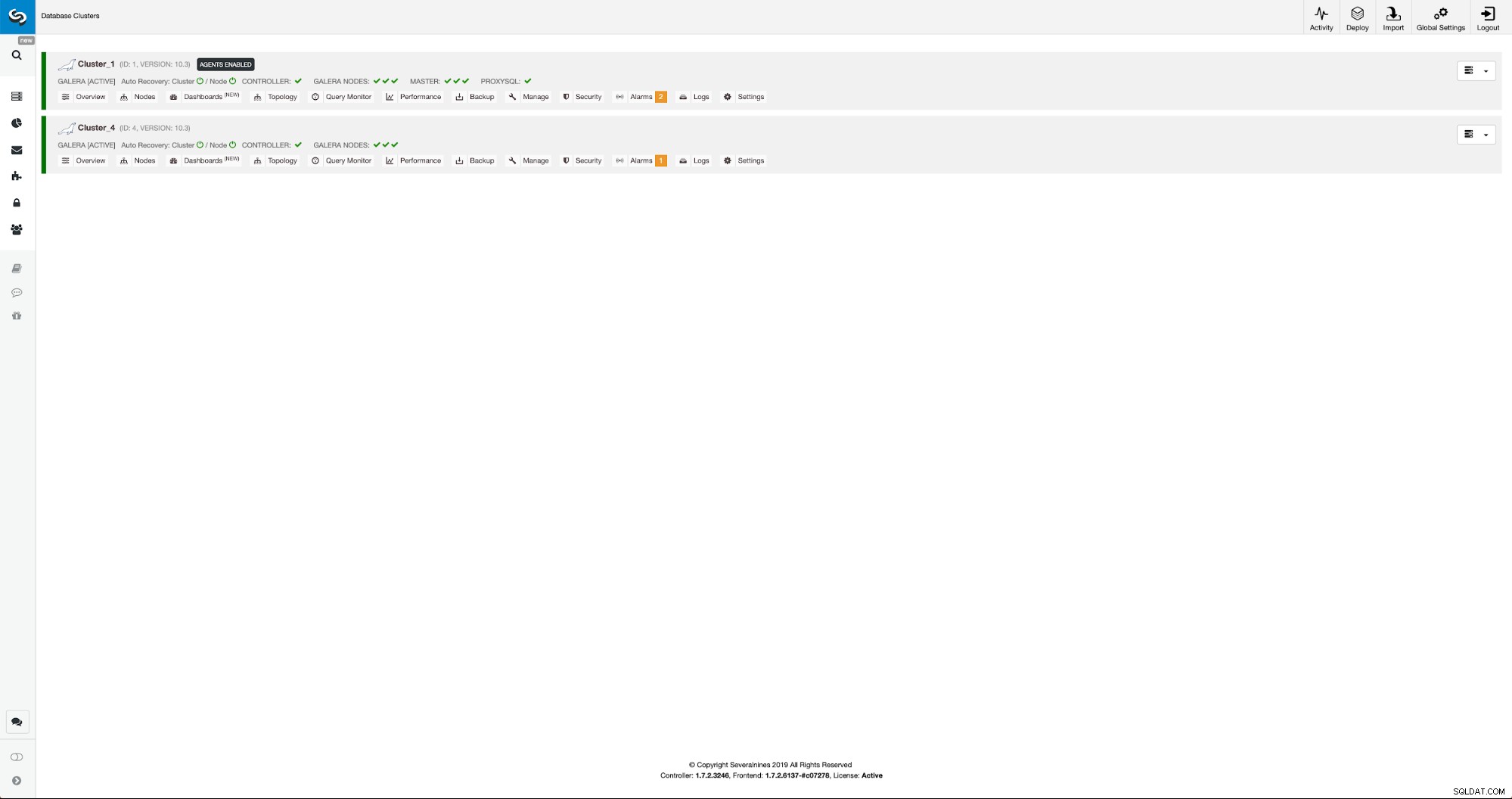
Omkonfiguration af den nye klynge ved hjælp af ClusterControl
Nu skal vi omkonfigurere klyngen - vi vil aktivere binære logfiler. I den manuelle proces var vi nødt til at foretage ændringer i wsrep_sst_auth-konfigurationen og også konfigurationsindtastninger i [mysqldump] og [xtrabackup] sektioner af konfigurationen. Disse indstillinger kan findes i filen secrets-backup.cnf. Denne gang er det ikke nødvendigt, da ClusterControl genererede nye adgangskoder til klyngen og konfigurerede filerne korrekt. Hvad der dog er vigtigt at huske på, hvis du ændrer adgangskoden til 'backupuser'@'127.0.0.1'-brugeren i den originale klynge, bliver du også nødt til at foretage konfigurationsændringer i den anden klynge for at afspejle det, da ændringer i den første klynge vil replikere til den anden klynge.
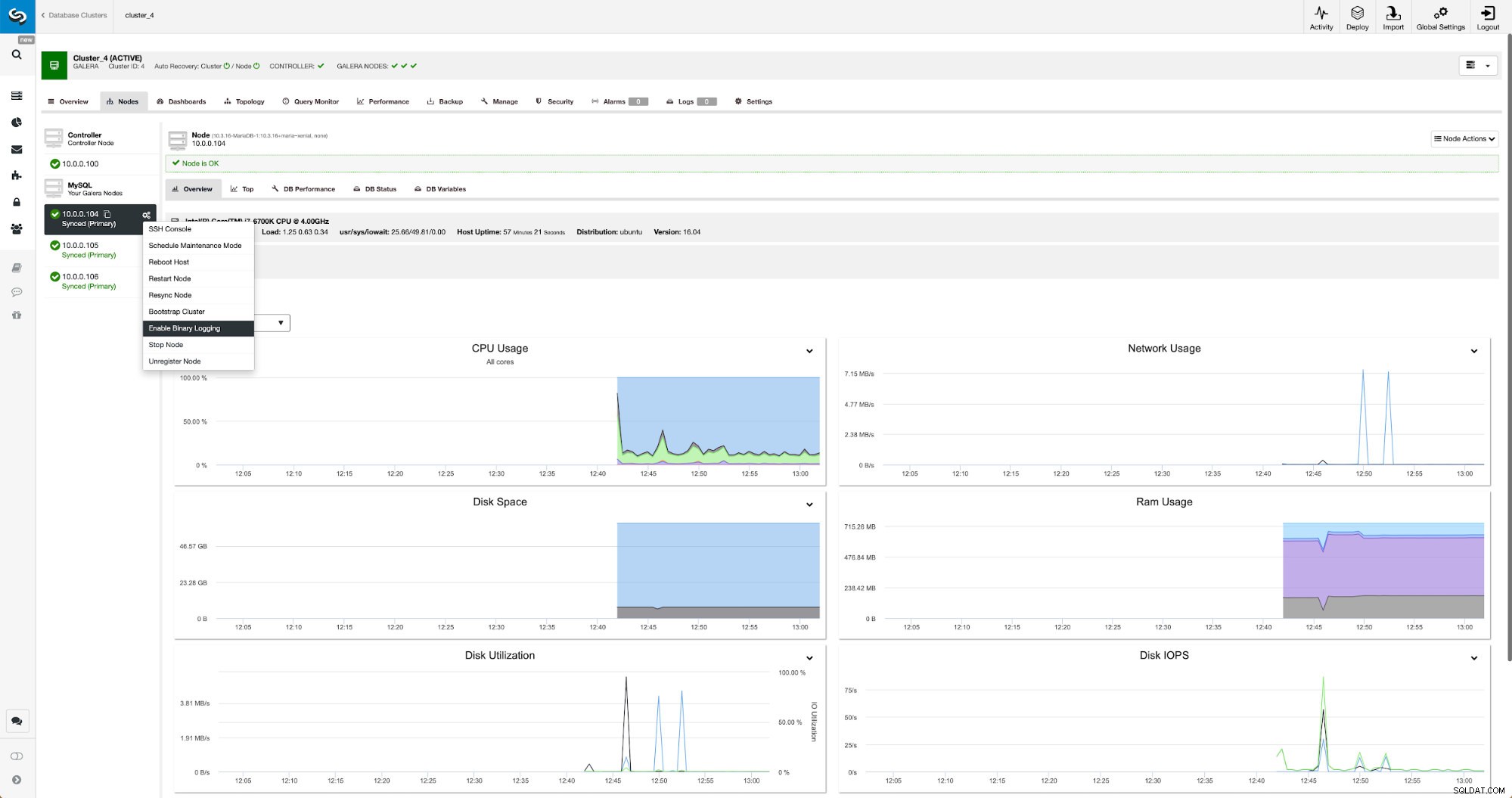
Binære logfiler kan aktiveres fra sektionen Nodes. Du skal vælge node for node og køre "Enable Binary Logging" job. Du vil blive præsenteret for en dialogboks:
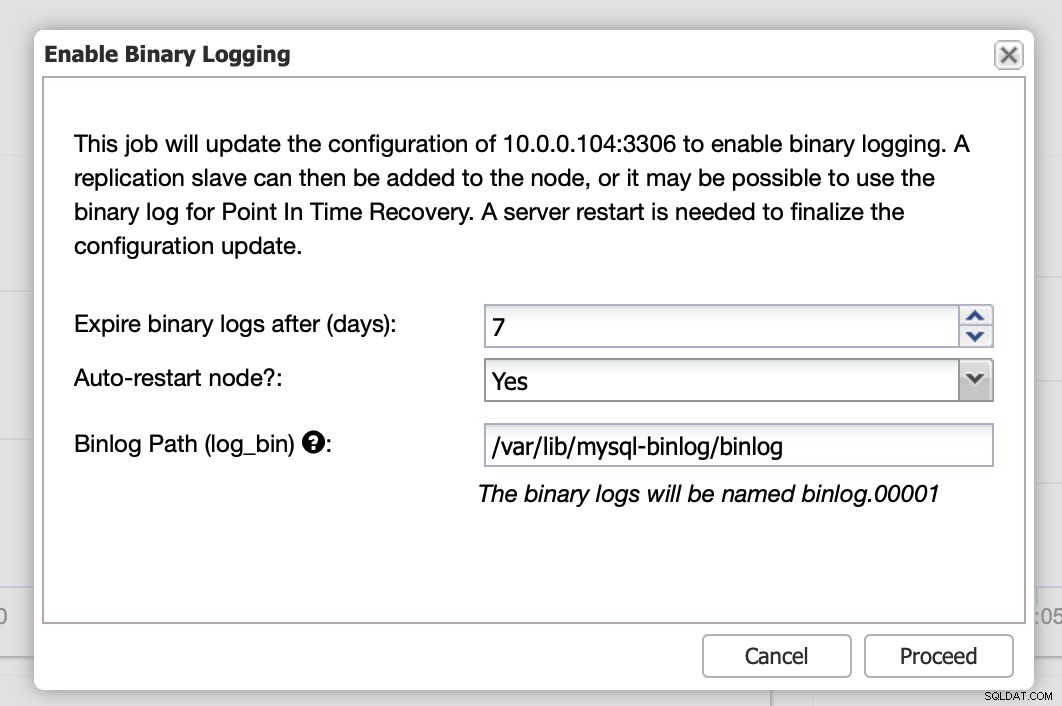
Her kan du definere, hvor længe du vil beholde logfilerne, hvor de skal gemmes, og hvis ClusterControl skal genstarte noden, så du kan anvende ændringer - binær logkonfiguration er ikke dynamisk, og MariaDB skal genstartes for at anvende disse ændringer.
Når ændringerne er fuldført, vil du se alle noder markeret som "master", hvilket betyder, at disse noder har binær log aktiveret og kan fungere som master.
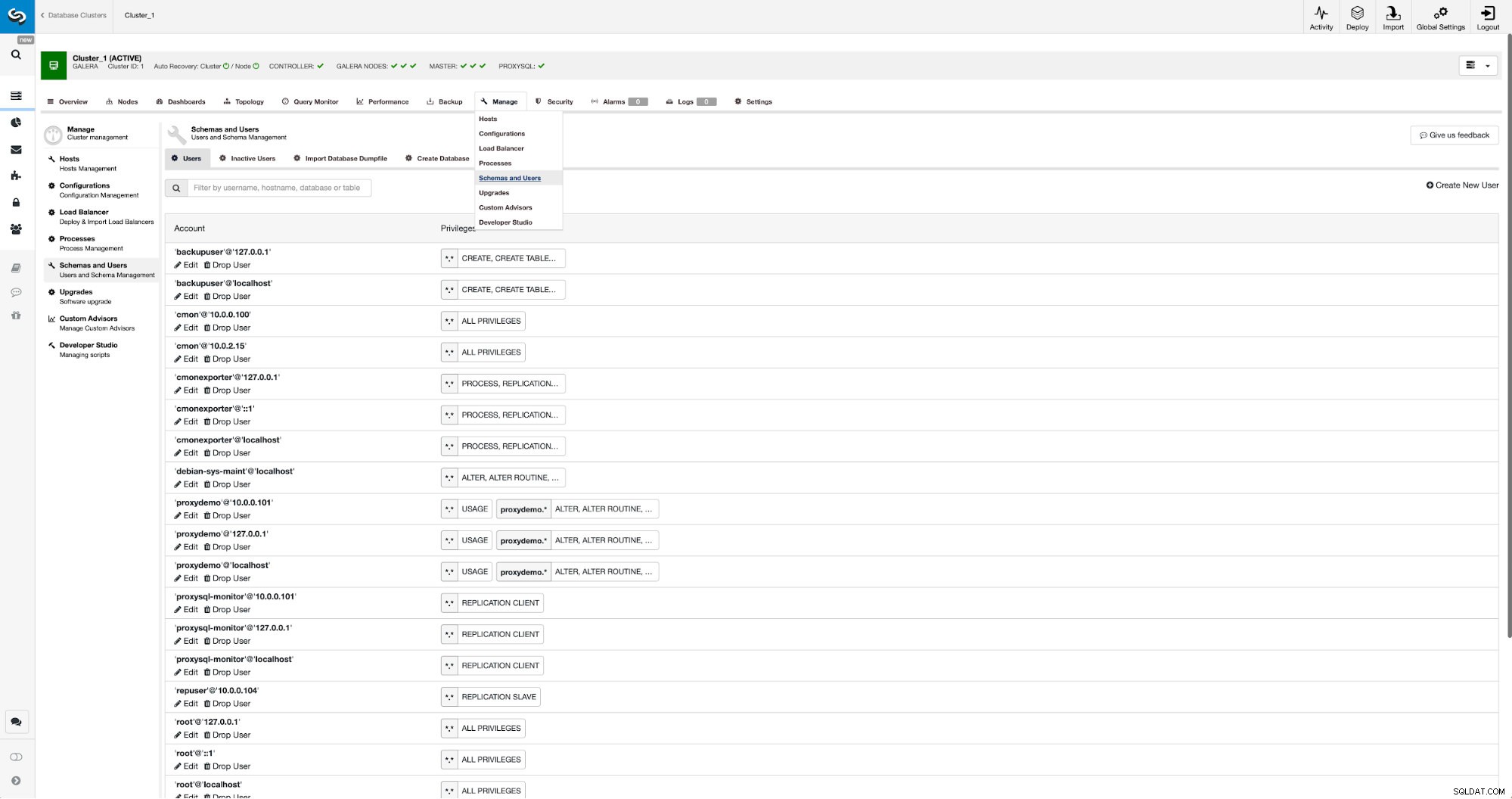
Hvis vi ikke allerede har oprettet en replikeringsbruger, skal vi gøre det. I den første klynge skal vi gå til Administrer -> Skemaer og brugere:
På højre side har vi en mulighed for at oprette en ny bruger:
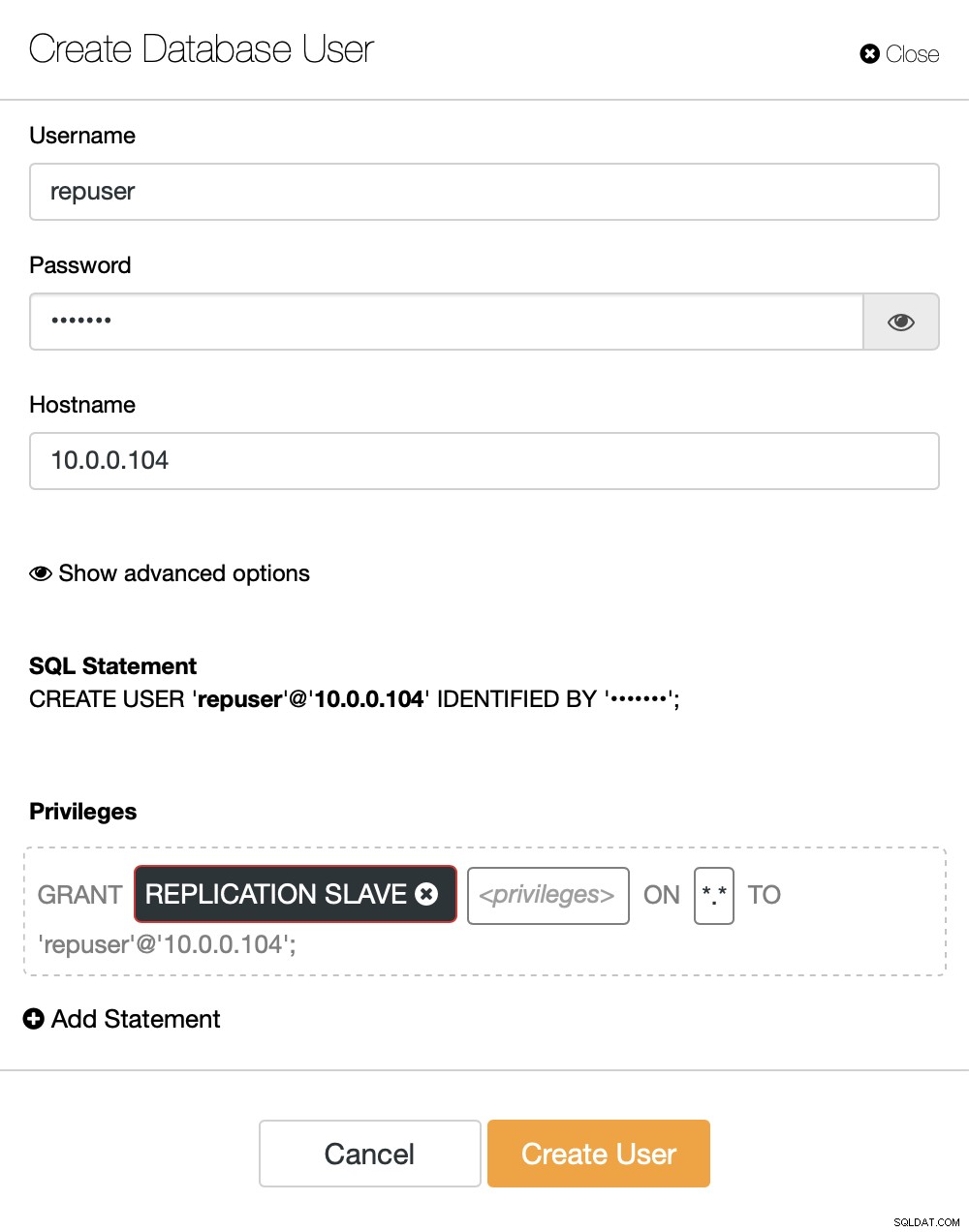
Dette afslutter den nødvendige konfiguration for at opsætte replikeringen.
Opsætning af replikering mellem klynger ved hjælp af ClusterControl
Som vi sagde, arbejder vi på at automatisere denne del. I øjeblikket skal det gøres manuelt. Som du måske husker, har vi brug for GITD-position af vores backup og derefter køre par kommandoer ved hjælp af MySQL CLI. GTID-data er tilgængelige i sikkerhedskopien. ClusterControl laver backup ved hjælp af xbstream/mbstream og komprimerer den efterfølgende. Vores backup er gemt på ClusterControl-værten, hvor vi ikke har adgang til mbstream binær. Du kan prøve at installere den, eller du kan kopiere sikkerhedskopifilen til det sted, hvor sådan binær er tilgængelig:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Når det er gjort, vil vi den 10.0.0.104 kontrollere indholdet af xtrabackup_info-filen:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Til sidst konfigurerer vi replikeringen og starter den:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Dette er det - vi har lige konfigureret asynkron replikering mellem to MariaDB Galera-klynger ved hjælp af ClusterControl. Som du kunne have set, var ClusterControl i stand til at automatisere størstedelen af de trin, vi skulle tage for at konfigurere dette miljø.