Hvis din it-infrastruktur kører på AWS, har du sikkert hørt om Amazon Relational Database Service (RDS), en nem måde at opsætte, betjene og skalere en relationel database i skyen. Det giver omkostningseffektiv kapacitet og kan tilpasses størrelsen, mens den automatiserer tidskrævende administrationsopgaver såsom hardwareprovisionering, databaseopsætning, patching og sikkerhedskopier. Der er en række databasemotortilbud til RDS som MySQL, MariaDB, PostgreSQL, Microsoft SQL Server og Oracle Server.
ClusterControl 1.7.3 fungerer på samme måde som RDS, da den understøtter databaseklyngeimplementering, -styring, overvågning og skalering på AWS-platformen. Det understøtter også en række andre cloud-platforme som Google Cloud Platform og Microsoft Azure. ClusterControl forstår databasetopologien og er i stand til at udføre automatisk gendannelse, topologistyring og mange flere avancerede funktioner til at tage kontrol over din database.
I dette blogindlæg vil vi sammenligne automatiske failover-tider for Amazon Aurora, Amazon RDS til MySQL og en MySQL-replikeringsopsætning, der er implementeret og administreret af ClusterControl. Den type failover, vi skal lave, er slavefremme i tilfælde af, at masteren går ned. Det er her, den mest opdaterede slave overtager masterrollen i klyngen for at genoptage databasetjenesten.
Vores failover-test
For at måle failover-tiden skal vi køre en simpel MySQL-forbindelsesopdateringstest med en loop til at tælle SQL-sætningsstatussen, der forbinder til et enkelt databaseslutpunkt. Scriptet ser sådan ud:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Ovenstående Bash-script forbinder simpelthen til en MySQL-vært og udfører en opdatering på en enkelt række med en timeout på 1 sekund på både Bash- og mysql-klientkommandoer. De timeout-relaterede parametre er påkrævet, så vi kan måle nedetiden i sekunder korrekt, da mysql-klienten som standard altid genopretter forbindelsen, indtil den når MySQL wait_timeout. Vi udfyldte et testdatasæt med følgende kommando på forhånd:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepare Scriptet rapporterer, om ovenstående forespørgsel lykkedes (OK) eller mislykkedes (Fejl). Eksempeludgange vises længere nede.
Failover med Amazon RDS til MySQL
I vores test bruger vi det laveste RDS-tilbud med følgende specifikationer:
- MySQL-version:5.7.22
- vCPU:4
- RAM:16 GB
- Lagringstype:Provisioned IOPS (SSD)
- IOPS:1000
- Lagerplads:100 Gib
- Multi-AZ-replikering:Ja
Efter at Amazon RDS har klargjort din DB-instans, kan du bruge enhver standard MySQL-klientapplikation eller -værktøj til at oprette forbindelse til instansen. I forbindelsesstrengen angiver du DNS-adressen fra DB-instansens slutpunkt som værtsparameteren og angiver portnummeret fra DB-instansens slutpunkt som portparameteren.
Ifølge Amazon RDS-dokumentationssiden, i tilfælde af et planlagt eller uplanlagt udfald af din DB-instans, skifter Amazon RDS automatisk til en standby-replika i en anden tilgængelighedszone, hvis du har aktiveret Multi-AZ. Den tid, det tager for failover at fuldføre, afhænger af databaseaktiviteten og andre forhold på det tidspunkt, hvor den primære DB-instans blev utilgængelig. Fejltider er typisk 60-120 sekunder.
For at starte en multi-AZ-failover i RDS, udførte vi en genstartoperation med "Genstart med Failover" markeret, som vist på følgende skærmbillede:
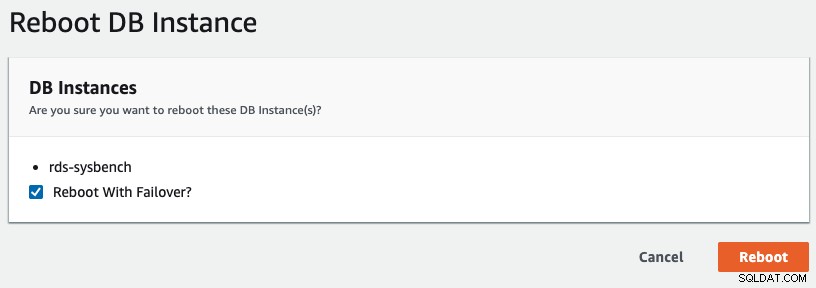
Følgende er, hvad der observeres af vores applikation:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
... MySQL-nedetiden som set af applikationssiden blev startet fra 03:41:09 til 03:41:36, hvilket er omkring 27 sekunder i alt. Fra RDS-begivenhederne kan vi se, at multi-AZ failover kun skete 15 sekunder efter faktisk nedetid:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed. Når den nye databaseinstans genstartede omkring kl. 03:41:33, var MySQL-tjenesten tilgængelig omkring 3 sekunder senere.
Failover med Amazon Aurora til MySQL
Amazon Aurora kan betragtes som en overlegen version af RDS, med en masse bemærkelsesværdige funktioner som hurtigere replikering med delt lagring, intet datatab under failover og op til 64 TB af en lagergrænse. Amazon Aurora til MySQL er baseret på open source MySQL Edition, men er ikke open source i sig selv; det er en proprietær, lukket kildedatabase. Det fungerer på samme måde med MySQL-replikering (en og kun én master, med flere slaver), og failover håndteres automatisk af Amazon Aurora.
Ifølge Amazon Aurora FAQS, hvis du har en Amazon Aurora Replica, i den samme eller en anden tilgængelighedszone, når Aurora fejler, vender Aurora den kanoniske navnepost (CNAME) for din DB-instans for at pege på den sunde replika, som er i tur forfremmes til at blive den nye primære. Start-til-slut, failover afsluttes typisk inden for 30 sekunder.
Hvis du ikke har en Amazon Aurora-replika (dvs. en enkelt instans), vil Aurora først forsøge at oprette en ny DB-instans i den samme tilgængelighedszone som den oprindelige instans. Hvis det ikke er muligt, vil Aurora forsøge at oprette en ny DB-instans i en anden tilgængelighedszone. Fra start til slut afsluttes failover typisk på under 15 minutter.
Dit program bør prøve databaseforbindelser igen i tilfælde af forbindelsestab.
Når Amazon Aurora har klargjort din DB-instans, får du to endepunkter, et til forfatteren og et til læseren. Læserendepunktet giver belastningsbalancerende understøttelse af skrivebeskyttede forbindelser til DB-klyngen. Følgende endepunkter er taget fra vores testopsætning:
- forfatter - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- læser - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
I vores test brugte vi følgende Aurora-specifikationer:
- Forekomsttype:db.r5.large
- MySQL-version:5.7.12
- vCPU:2
- RAM:16 GB
- Multi-AZ-replikering:Ja
For at udløse en failover skal du blot vælge writer-forekomsten -> Handlinger -> Failover, som vist på følgende skærmbillede:
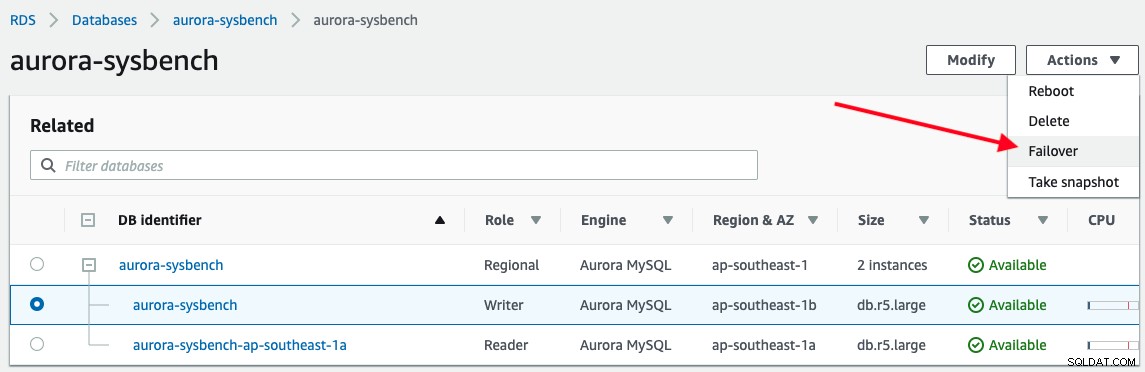
Følgende output rapporteres af vores applikation, mens der oprettes forbindelse til Aurora writer-slutpunktet :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
... Databasens nedetid blev startet kl. 12:35:49 indtil 12:35:56 med et samlet beløb på 7 sekunder. Det er ret imponerende.
Når man ser på databasehændelsen fra Aurora-administrationskonsollen, skete kun disse to hændelser:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restarted Det tager ikke meget tid for Aurora at forfremme en slave til at blive en herre, og degradere mesteren til at blive en slave. Bemærk, at alle Aurora-replikaer deler den samme underliggende volumen med den primære instans, og det betyder, at replikering kan udføres på millisekunder, da opdateringer foretaget af den primære instans øjeblikkeligt er tilgængelige for alle Aurora-replikaer. Derfor har den minimal replikationsforsinkelse (Amazon hævdede at være 100 millisekunder og mindre). Dette vil i høj grad reducere helbredstjektiden og forbedre restitutionstiden betydeligt.
Failover med ClusterControl
I dette eksempel efterligner vi en lignende opsætning med Amazon RDS ved hjælp af m5.xlarge-instanser, med en ProxySQL imellem for at automatisere failover fra applikation ved hjælp af en enkelt slutpunktsadgang ligesom RDS. Følgende diagram illustrerer vores arkitektur:
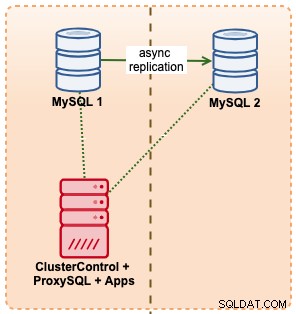
Da vi har direkte adgang til databaseforekomsterne, vil vi udløse en automatisk failover ved blot at dræbe MySQL-processen på den aktive master:
$ kill -9 $(pidof mysqld) Ovenstående kommando udløste en automatisk gendannelse inde i ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master. Mens fra vores testapplikationssynspunkt, skete nedetiden på det følgende tidspunkt under forbindelse til ProxySQL-værtsport 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
... Ved at se på både gendannelsesjobhændelser og output fra vores applikation, var MySQL-databasenoden nede 4 sekunder før klyngengendannelsesjobbet starter, fra 11:08:28 til 11:08:39, med en samlet MySQL-nedetid på 11 sekunder . En af de mest imponerende ting ved ClusterControl er, at du kan spore genoprettelsesfremskridtene på, hvilken handling, der foretages og udføres af ClusterControl under failover. Det giver et niveau af gennemsigtighed, som du ikke vil være i stand til at få med nogen databasetilbud fra cloududbydere.
For MySQL/MariaDB/PostgreSQL-replikering giver ClusterControl dig mulighed for at have en mere finmasket mod dine databaser med understøttelse af følgende avancerede konfiguration og parametre:
- Master-master replikeringstopologistyring
- Kædereplikeringstopologistyring
- Topologifremviser
- Hvidliste/sortliste slaver, der skal forfremmes som master
- Fejltransaktionskontrol
- Pre/post, succes/fail failover/switchover hændelser hook med eksternt script
- Automatisk genopbygningsslave ved fejl
- Skal ud slave fra eksisterende backup
Oversigt over fejltid
Med hensyn til failover-tid er Amazon RDS Aurora til MySQL den klare vinder med 7 sekunder , efterfulgt af ClusterControl 11 sekunder og Amazon RDS til MySQL med 27 sekunder .
Bemærk, at dette kun er en simpel test, med én klient og én transaktion i sekundet for at måle den hurtigste restitutionstid. Store transaktioner eller en langvarig gendannelsesproces kan øge failover-tiden, f.eks. kan langvarige transaktioner tage lang tid at rulle tilbage, når MySQL lukkes ned.