Lige siden ClusterControl 1.2.11 blev udgivet i 2015, er MariaDB MaxScale blevet understøttet som en databasebelastningsbalancer. I årenes løb er MaxScale vokset og modnet og tilføjet flere rige funktioner. For nylig blev MariaDB MaxScale 2.2 frigivet, og den introducerer adskillige nye funktioner, herunder styring af replikeringsklynge-failover.
MariaDB MaxScale giver mulighed for master/slave-implementeringer med høj tilgængelighed, automatisk failover, manuel omskiftning og automatisk genforening. Hvis masteren fejler, kan MariaDB MaxScale automatisk fremme den mest opdaterede slave til master. Hvis den mislykkede master gendannes, kan MariaDB MaxScale automatisk omkonfigurere den som en slave til den nye master. Derudover kan administratorer udføre en manuel overgang for at ændre masteren efter behov.
I vores tidligere blogs diskuterede vi, hvordan man implementerer MaxScale ved hjælp af ClusterControl samt implementering af MariaDB MaxScale på Docker. For dem, der endnu ikke er bekendt med MariaDB MaxScale, er det en avanceret, plug-in, databaseproxy til MariaDB-databaseservere. Maxscale sidder mellem klientapplikationer og databaseservere og dirigerer klientforespørgsler og serversvar. Den overvåger også serverne og bemærker hurtigt eventuelle ændringer i serverstatus eller replikeringstopologi.
Selvom Maxscale deler nogle af egenskaberne ved andre belastningsbalanceringsteknologier som ProxySQL, skiller denne nye failover-funktion sig ud (som er en del af dens overvågnings- og autodetektionsmekanisme). I denne blog vil vi diskutere denne spændende nye funktion af Maxscale.
Oversigt over MariaDB MaxScale Failover Mechanism
Master Detection
Skærmen er nu mindre tilbøjelig til pludselig at skifte masterserver, selvom en anden server har flere slaver end den nuværende master. DBA'en kan gennemtvinge et mastergenvalg ved at indstille den aktuelle master skrivebeskyttet eller ved at fjerne alle dens slaver, hvis masteren er nede.
Kun én server kan have Master-statusflaget ad gangen, selv i en multimaster-opsætning. Andre servere i multimaster-gruppen får statusflagerne Relay Master og Slave.
Skift til nyt hovedautovalg
Skiftkommandoen kan nu kaldes med kun monitorinstansens navn som parameter. I dette tilfælde vil monitoren automatisk vælge en server til forfremmelse.
Detektion af replikationsforsinkelse
Replikationsforsinkelsesmålingen læser nu blot Seconds_Behind_Master -felt af slavestatusudgangen for slaver. Slaven beregner denne værdi ved at sammenligne tidsstemplet i binlog-hændelsen, som slaven i øjeblikket behandler med slavens eget ur. Hvis en slave har flere slaveforbindelser, bruges den mindste forsinkelse.
Automatisk skift efter registrering af lav diskplads
Med de seneste MariaDB Server-versioner kan monitoren nu tjekke diskpladsen på backend og registrere, om serveren er ved at løbe tør. Når dette sker, kan skærmen indstilles til automatisk at skifte fra en master med lav diskplads. Slaver kan også indstilles til vedligeholdelsestilstand. Diskpladsen er også en faktor, der tages i betragtning, når du vælger hvilken ny master, der skal fremmes.
Se switchover_on_low_disk_space og maintenance_on_low_disk_space for mere information.
Replikeringsnulstillingsfunktion
nulstil-replikeringen monitor-kommando sletter alle slaveforbindelser og binære logfiler og sætter derefter replikering op. Nyttigt, når data er synkroniseret, men gtid'er ikke er det.
Håndtering af planlagte hændelser i failover/switchover/rejoin
Serverhændelser lanceret af begivenhedsplanlægningstråden håndteres nu under klyngeændringsoperationer. Se handle_server_events for mere information.
Ekstern mastersupport
Monitoren kan registrere, om en server i klyngen replikerer fra en ekstern master (en server, der ikke overvåges af MaxScale-monitoren). Hvis den replikerende server er klyngemasterserveren, anses selve klyngen for at have en ekstern master.
Hvis der sker en failover/switchover, er den nye masterserver sat til at replikere fra klyngens eksterne masterserver. Brugernavnet og adgangskoden til replikeringen er defineret i replikeringsbruger og replikeringsadgangskode. Adressen og porten, der bruges, er dem, der vises af VIS ALLE SLAVESTATUS på den gamle klyngemasterserver. I tilfælde af omskiftning stopper den gamle master også med at replikere fra den eksterne server for at bevare topologien.
Efter failover replikeres den nye master fra den eksterne master. Hvis den mislykkede gamle master kommer online igen, replikeres den også fra den eksterne server. For at normalisere situationen skal du enten have auto_rejoin slået til eller manuelt udføre en rejoin. Dette vil omdirigere den gamle master til den aktuelle klyngemaster.
Hvordan failover er nyttigt og anvendeligt?
Failover hjælper dig med at minimere nedetid, udføre daglig vedligeholdelse eller håndtere katastrofal og uønsket vedligeholdelse, der nogle gange kan opstå på uheldige tidspunkter. Med MaxScales evne til at isolere klientapplikationer fra backend-databaseservere tilføjer den værdifuld funktionalitet, der hjælper med at minimere nedetid.
MaxScale-overvågningsplugin'et overvåger løbende tilstanden af backend-databaseservere. MaxScales routing-plugin bruger derefter denne statusinformation til altid at dirigere forespørgsler til backend-databaseservere, der er i drift. Det er derefter i stand til at sende forespørgsler til backend-databaseklyngerne, selvom nogle af serverne i en klynge gennemgår vedligeholdelse eller oplever fejl.
MaxScales høje konfigurerbarhed gør det muligt for ændringer i klyngekonfigurationen at forblive gennemsigtige for klientapplikationer. For eksempel, hvis en ny server skal tilføjes administrativt til eller fjernes fra en master-slave-klynge, kan du blot tilføje MaxScale-konfigurationen til serverlisten over skærm- og router-plugins via maxadmin CLI-konsollen. Klientapplikationen vil være fuldstændig uvidende om denne ændring og vil fortsætte med at sende databaseforespørgsler til MaxScales lytteport.
Det er enkelt og nemt at sætte en databaseserver i vedligeholdelse. Gør blot følgende kommando ved hjælp af maxctrl, og MaxScale stopper med at sende forespørgsler til denne server. For eksempel,
maxctrl: set server DB_785 maintenance
OKKontroller derefter serverens tilstand som følger,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Når først den er i vedligeholdelsestilstand, stopper MaxScale med at dirigere nye anmodninger til serveren. For aktuelle anmodninger vil MaxScale ikke dræbe disse sessioner, men vil snarere tillade den at fuldføre sin eksekvering og vil ikke afbryde nogen kørende forespørgsler, mens den er i vedligeholdelsestilstand. Vær også opmærksom på, at vedligeholdelsestilstanden ikke er vedvarende. Hvis MaxScale genstarter, når en node er i vedligeholdelsestilstand, vil en ny forekomst af MariaDB MaxScale ikke overholde denne tilstand. Hvis flere MariaDB MaxScale-instanser er konfigureret til at bruge noden, skal vedligeholdelsestilstanden indstilles i hver MariaDB MaxScale-instans. Men hvis flere tjenester inden for en MariaDB MaxScale-instans bruger serveren, behøver du kun at indstille vedligeholdelsestilstanden én gang på serveren, for at alle tjenester kan notere tilstandsændringen.
Når du er færdig med din vedligeholdelse, skal du blot rydde serveren med følgende kommando. For eksempel,
maxctrl: clear server DB_785 maintenance
OKKontroller, om den er sat tilbage til normal, bare kør kommandoen liste servere .
Du kan også anvende visse administrative handlinger gennem ClusterControl UI. Se eksempelskærmbilledet nedenfor:
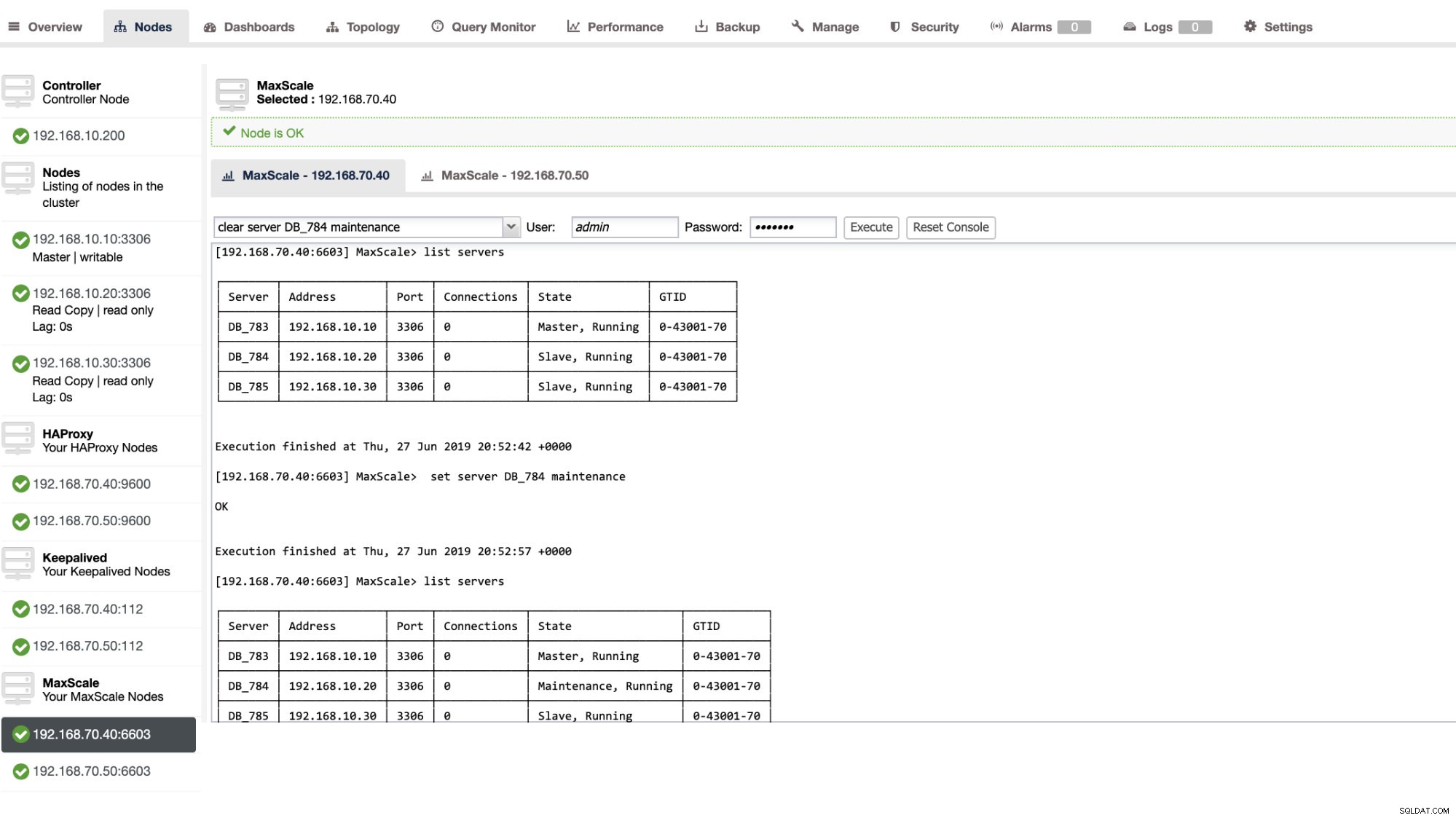
MaxScale Failover i aktion
Den automatiske failover
MariaDB's MaxScale failover fungerer meget effektivt og omkonfigurerer slaven i overensstemmelse hermed som forventet. I denne test har vi følgende konfigurationsfilsæt, som blev oprettet og administreret af ClusterControl. Se nedenfor:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonBemærk, at kun auto_failover og auto_rejoin er de variabler, som jeg har tilføjet, da ClusterControl ikke tilføjer dette som standard, når du først har opsat en MaxScale load balancer (tjek denne blog om, hvordan du opsætter MaxScale ved hjælp af ClusterControl). Glem ikke, at du skal genstarte MariaDB MaxScale, når du har anvendt ændringerne i din konfigurationsfil. Bare løb,
systemctl restart maxscaleog du er klar.
Før vi fortsætter failover-testen, lad os først tjekke klyngens helbred:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ser godt ud!
Jeg dræbte masteren med bare den rene killer-kommando KILL -9 $(pidof mysqld) i min masterknude og ser, til ingen overraskelse, monitoren har været hurtig til at bemærke dette og udløser failover. Se logfilerne som følger:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Lad os nu se på dens klynges helbred,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Noden 192.168.10.10 som tidligere var master har været nede. Jeg prøvede at genstarte og se, om automatisk genforbindelse ville udløse, og som du bemærkede i loggen på tidspunktet 2019-06-28 06:39:20.165, det har været så hurtigt at fange nodens tilstand og derefter konfigurere konfigurationen automatisk uden besvær for DBA'en at tænde den.
Når nu til sidst tjekker dens tilstand, ser det ud til at fungere perfekt som forventet. Se nedenfor:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Min tidligere mester er blevet rettet og genoprettet, og jeg vil gerne skifte
Det er heller ikke noget besvær at skifte til din tidligere master. Du kan betjene dette med maxctrl (eller maxadmin i tidligere versioner af MaxScale) eller gennem ClusterControl UI (som tidligere vist).
Lad os blot henvise til den tidligere tilstand af replikationsklyngesundheden tidligere og ønskede at skifte 192.168.10.10 (nuværende slave) tilbage til dens mastertilstand. Før vi fortsætter, skal du muligvis først identificere den skærm, du skal bruge. Du kan bekræfte dette med følgende kommando nedenfor:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Når du har det, kan du udføre følgende kommando nedenfor for at skifte:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKKontroller derefter igen klyngens tilstand,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ser perfekt ud!
Logs vil udførligt vise dig, hvordan det gik og dens række af handlinger under skiftet. Se detaljerne nedenfor:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]I tilfælde af en forkert omskiftning vil den ikke fortsætte, og den vil derfor generere en fejl som vist i loggen ovenfor. Så du vil være sikker og ingen skræmmende overraskelser overhovedet.
Gør din MaxScale yderst tilgængelig
Selvom det er lidt off-topic med hensyn til failover, ville jeg tilføje nogle værdifulde punkter her med hensyn til høj tilgængelighed, og hvordan det var relateret til MariaDB MaxScale failover.
At gøre din MaxScale yderst tilgængelig er en vigtig del i tilfælde af, at dit system går ned, oplever diskkorruption eller virtuel maskine korruption. Disse situationer er uundgåelige og kan påvirke tilstanden af din automatiske failover-opsætning, når disse uventede vedligeholdelsescyklusser opstår.
For et replikeringsklyngemiljø er dette meget fordelagtigt og anbefales stærkt til en specifik MaxScale-opsætning. Formålet med dette er, at kun én MaxScale-instans skal have lov til at ændre klyngen på et givet tidspunkt. Hvis du har setup med Keepalived, er det her forekomsterne med status som MASTER. MaxScale kender ikke selv sin tilstand, men med maxctrl (eller maxadmin i tidligere versioner) kan indstille en MaxScale-instans til passiv tilstand. Fra version 2.2.2 opfører en passiv MaxScale sig på samme måde som en aktiv med den forskel, at den ikke vil udføre failover, omskiftning eller rejoin. Selv manuelle versioner af disse kommandoer vil ende med en fejl. Forskellene i passiv/aktiv tilstand kan blive udvidet i fremtiden, så hold øje med sådanne ændringer i MaxScale. For at gøre dette skal du blot gøre følgende:
maxctrl: alter maxscale passive true
OKDu kan bekræfte dette bagefter ved at køre kommandoen nedenfor:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Hvis du vil tjekke ud, hvordan du opsætter meget tilgængelig med Keepalived, så tjek venligst dette indlæg fra MariaDB.
VIP-håndtering
Derudover, da MaxScale ikke selv har indbygget VIP-håndtering, kan du bruge Keepalved til at håndtere det for dig. Du kan bare bruge den virtuelle_ipadresse, der er tildelt MASTER-tilstandsknuden. Dette vil sandsynligvis komme op med virtuel IP-styring ligesom MHA gør med master_failover_script-variablen. Som nævnt tidligere, tjek dette Keepalived with MaxScale-opsætningsblogindlæg af MariaDB.
Konklusion
MariaDB MaxScale er funktionsrig og har masser af muligheder, ikke kun begrænset til at være en proxy og load balancer, men den tilbyder også failover-mekanismen, som store organisationer leder efter. Det er næsten en software, der passer til alle, men den kommer selvfølgelig med begrænsninger, som en bestemt applikation kan have brug for i modsætning til andre belastningsbalancere såsom ProxySQL.
ClusterControl tilbyder også en auto-failover og master auto-detektionsmekanisme, plus cluster- og nodegendannelse med mulighed for at implementere Maxscale og andre belastningsbalanceringsteknologier.
Hvert af disse værktøjer har sine forskellige funktioner og funktionalitet, men MariaDB MaxScale er godt understøttet i ClusterControl og kan implementeres nemt sammen med Keepalved, HAProxy for at hjælpe dig med at fremskynde din daglige rutineopgave.