En af de fede funktioner i Galera er automatisk nodeprovisionering og medlemskontrol. Hvis en node svigter eller mister kommunikationen, bliver den automatisk smidt ud af klyngen og forbliver uoperativ. Så længe størstedelen af noder stadig kommunikerer (Galera kalder denne pc - primær komponent), er der en meget stor chance for, at den mislykkede node automatisk vil være i stand til automatisk at forbinde, gensynkronisere og genoptage replikeringen, når forbindelsen er tilbage.
Generelt er alle Galera-noder ens. De har det samme datasæt og samme rolle som mastere, der er i stand til at håndtere læsning og skrivning samtidigt, takket være Galera gruppekommunikation og certificeringsbaseret replikeringsplugin. Derfor er der faktisk ingen failover fra databasens synspunkt på grund af denne ligevægt. Kun fra applikationssiden, der ville kræve failover, for at springe de uoperative noder over, mens klyngen er partitioneret.
I dette blogindlæg skal vi se på at forstå, hvordan Galera Cluster udfører node- og klyngendannelse i tilfælde af netværkspartitionering. Bare som en sidebemærkning har vi dækket et lignende emne i dette blogindlæg for noget tid tilbage. Codership har forklaret Galeras gendannelseskoncept i detaljer på dokumentationssiden, Node Failure and Recovery.
Knudefejl og udsættelse
For at forstå gendannelsen skal vi først forstå, hvordan Galera opdager knudefejl og udsættelsesprocessen. Lad os sætte dette ind i et kontrolleret testscenarie, så vi bedre kan forstå udsættelsesprocessen. Antag, at vi har en Galera-klynge med tre knudepunkter som illustreret nedenfor:
Følgende kommando kan bruges til at hente vores Galera-udbyderindstillinger:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GDet er en lang liste, men vi skal blot fokusere på nogle af parametrene for at forklare processen:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Først og fremmest følger Galera ISO 8601-formatering for at repræsentere varighed. P1D betyder, at varigheden er en dag, mens PT15S betyder, at varigheden er 15 sekunder (bemærk tidsbetegnelsen, T, der går forud for tidsværdien). For eksempel hvis man ønskede at øge evs.view_forget_timeout til 1 og en halv dag, ville man indstille P1DT12H eller PT36H.
I betragtning af at alle værter ikke er blevet konfigureret med nogen firewall-regler, bruger vi følgende script kaldet block_galera.sh på galera2 for at simulere en netværksfejl til/fra denne node:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateVed at udføre scriptet får vi følgende output:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Det rapporterede tidsstempel kan betragtes som starten på klyngeopdelingen, hvor vi mister galera2, mens galera1 og galera3 stadig er online og tilgængelige. På dette tidspunkt ser vores Galera Cluster-arkitektur noget sådan ud:
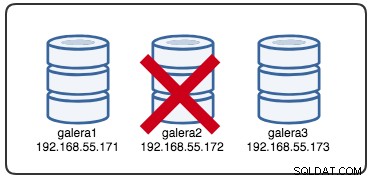
Fra partitioneret nodeperspektiv
På galera2 vil du se nogle udskrifter inde i MySQL-fejlloggen. Lad os dele dem op i flere dele. Nedetiden startede omkring kl. 16:46:02 UTC-tid og efter gmcast.peer_timeout=PT3S , vises følgende:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Da det passerede evs.suspect_timeout =PT5S , begge noder galera1 og galera3 mistænkes for at være døde af galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveDerefter vil Galera revidere den aktuelle klyngevisning og positionen af denne node:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Med den nye klyngevisning vil Galera udføre kvorumberegning for at afgøre, om denne node er en del af den primære komponent. Hvis den nye komponent ser "primær =nej", vil Galera degradere den lokale nodetilstand fra SYNCED til OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Med den seneste ændring af klyngevisningen og nodetilstanden returnerer Galera klyngevisningen efter fraflytning og den globale tilstand som nedenfor:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Du kan se følgende globale status for galera2 har ændret sig i denne periode:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+På dette tidspunkt er MySQL/MariaDB-serveren på galera2 stadig tilgængelig (databasen lytter på 3306 og Galera på 4567), og du kan forespørge i mysql-systemtabellerne og liste databaserne og tabellerne. Men når du hopper ind i ikke-systemtabellerne og laver en simpel forespørgsel som denne:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useDu vil straks få en fejl, der angiver, at WSREP er indlæst, men ikke klar til brug af denne node, som rapporteret af wsrep_ready status. Dette skyldes, at noden mister sin forbindelse til den primære komponent, og den går ind i den ikke-operative tilstand (den lokale nodestatus blev ændret fra SYNCED til OPEN). Datalæsninger fra noder i en ikke-operativ tilstand betragtes som forældede, medmindre du indstiller wsrep_dirty_reads=ON for at tillade læsninger, selvom Galera stadig afviser enhver kommando, der ændrer eller opdaterer databasen.
Endelig vil Galera fortsætte med at lytte og genoprette forbindelsen til andre medlemmer i baggrunden i det uendelige:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Udsættelsesprocessens flow af Galera-gruppekommunikation for den partitionerede node under netværksproblemet kan opsummeres som nedenfor:
- Afbryder forbindelsen fra klyngen efter gmcast.peer_timeout .
- Mistanker om andre noder efter evs.suspect_timeout .
- Henter den nye klyngevisning.
- Udfører kvorumberegning for at bestemme nodens tilstand.
- Degraderer noden fra SYNCED til OPEN.
- Forsøg på at genoprette forbindelse til den primære komponent (andre Galera-noder) i baggrunden.
Fra primærkomponentperspektiv
På henholdsvis galera1 og galera3 efter gmcast.peer_timeout=PT3S , vises følgende i MySQL-fejlloggen:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Efter det passerede evs.suspect_timeout =PT5S , galera2 er mistænkt for død af galera3 (og galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera tjekker ud, om de andre noder reagerer på gruppekommunikationen på galera3, den finder ud af, at galera1 er i primær og stabil tilstand:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera reviderer klyngevisningen af denne node (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera fjerner derefter den partitionerede node fra den primære komponent:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Den nye primære komponent består nu af to noder, galera1 og galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Den primære komponent vil udveksle staten mellem hinanden for at blive enige om den nye klyngevisning og globale tilstand:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera beregner og verificerer quorumet af statens udveksling mellem onlinemedlemmer:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera opdaterer den nye klyngevisning og den globale tilstand efter galera2-udsættelse:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)På dette tidspunkt vil både galera1 og galera3 rapportere lignende global status:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+De viser det problematiske medlem i wsrep_evs_delayed status. Da den lokale tilstand er "Synced", er disse noder operationelle, og du kan omdirigere klientforbindelserne fra galera2 til enhver af dem. Hvis dette trin er ubelejligt, kan du overveje at bruge en belastningsbalancer foran databasen for at forenkle forbindelsesendepunktet fra klienterne.
Gendannelse og sammenføjning af noder
En opdelt Galera-node vil fortsætte med at forsøge at etablere forbindelse med den primære komponent i det uendelige. Lad os tømme iptables-reglerne på galera2 for at lade den forbinde med de resterende noder:
# on galera2
$ iptables -FNår noden er i stand til at oprette forbindelse til en af noderne, begynder Galera automatisk at genetablere gruppekommunikationen:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableNode galera2 vil derefter oprette forbindelse til en af de primære komponenter (i dette tilfælde er galera1, node ID 737422d6) for at få den aktuelle klyngevisning og nodes tilstand:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera vil derefter udføre statsudveksling med resten af medlemmerne, der kan danne den primære komponent:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Statsudvekslingen tillader galera2 at beregne kvorumet og producere følgende resultat:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera vil derefter fremme den lokale nodetilstand fra ÅBEN til PRIMÆR for at starte og etablere nodeforbindelsen til den primære komponent:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Som rapporteret af ovenstående linje, beregner Galera afstanden på, hvor langt noden er bagud fra klyngen. Denne node kræver tilstandsoverførsel for at nå skrivesætnummer 2836958 fra 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera forbereder IST-lytteren på port 4568 på denne node og beder enhver synkroniseret node i klyngen om at blive donor. I dette tilfælde vælger Galera automatisk galera3 (192.168.55.173), eller det kan også vælge en donor fra listen under wsrep_sst_donor (hvis defineret) for synkroniseringsoperationen:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Det vil derefter ændre den lokale nodetilstand fra PRIMÆR til JOINER. På dette stadium tildeles galera2 en anmodning om statsoverførsel og begynder at cache skrivesæt:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetNode galera2 begynder at modtage de manglende skrivesæt fra den valgte donors gcache (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Når alle de manglende skrivesæt er modtaget og anvendt, vil Galera promovere galera2 som JOINED indtil seqnr. 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Noden anvender alle cachelagrede skrivesæt i sin slavekø og afslutter med at indhente klyngen. Dens slavekø er nu tom. Galera vil promovere galera2 til SYNCED, hvilket indikerer, at noden nu er operationel og klar til at betjene kunder:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsPå dette tidspunkt er alle noder tilbage operationelle. Du kan bekræfte ved at bruge følgende udsagn på galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size rapporteret som 3, og klyngestatus er Primær, hvilket indikerer, at galera2 er en del af den primære komponent. wsrep_evs_delayed er også blevet ryddet, og den lokale stat er nu synkroniseret.
Gendannelsesprocesforløbet for den partitionerede node under netværksproblemet kan opsummeres som nedenfor:
- Genetablerer gruppekommunikation til andre noder.
- Henter klyngevisningen fra en af de primære komponenter.
- Udfører statsudveksling med den primære komponent og beregner kvorum.
- Ændrer den lokale nodetilstand fra ÅBEN til PRIMÆR.
- Beregner afstanden mellem lokal node og klyngen.
- Ændrer den lokale nodetilstand fra PRIMÆR til JOINER.
- Forbereder IST-lytter/modtager på port 4568.
- Anmoder om statsoverførsel via IST og vælger en donor.
- Begynder at modtage og anvende det manglende skrivesæt fra den valgte donors gcache.
- Ændrer den lokale nodetilstand fra JOINER til JOINED.
- Indhenter klyngen ved at anvende de cachelagrede skrivesæt i slavekøen.
- Ændrer den lokale nodetilstand fra JOINED til SYNCED.
Klyngefejl
En Galera Cluster anses for at være mislykket, hvis der ikke er nogen tilgængelig primær komponent (pc). Overvej en lignende Galera-klynge med tre knudepunkter som afbildet i diagrammet nedenfor:
En klynge anses for operationel, hvis alle noder eller størstedelen af noderne er online. Online betyder, at de er i stand til at se hinanden gennem Galeras replikeringstrafik eller gruppekommunikation. Hvis der ikke kommer trafik ind og ud fra noden, sender klyngen et hjerteslagssignal, så noden reagerer rettidigt. Ellers vil det blive sat på listen over forsinkelser eller mistanke i henhold til, hvordan noden reagerer.
Hvis en node går ned, lad os sige node C, vil klyngen forblive operationel, fordi node A og B stadig er beslutningsdygtige med 2 stemmer ud af 3 for at danne en primær komponent. Du bør få følgende klyngetilstand på A og B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Hvis lad os sige, at en primær switch gik kaput, som illustreret i følgende diagram:
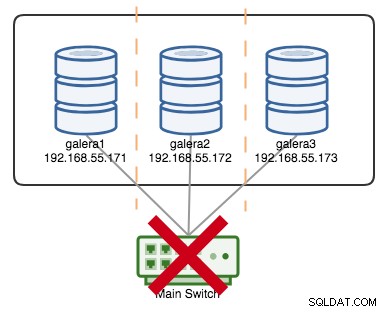
På dette tidspunkt mister hver enkelt node kommunikationen til hinanden, og klyngetilstanden vil blive rapporteret som ikke-Primær på alle noder (som hvad der skete med galera2 i det foregående tilfælde). Hver node ville beregne quorumet og finde ud af, at det er mindretallet (1 stemme ud af 3), og dermed miste quorumet, hvilket betyder, at der ikke dannes en Primær Komponent, og derfor nægter alle noder at levere nogen data. Dette anses for at være klyngefejl.
Når netværksproblemet er løst, vil Galera automatisk genetablere kommunikationen mellem medlemmer, udveksle nodes tilstande og bestemme muligheden for at reformere den primære komponent ved at sammenligne nodetilstand, UUID'er og seqnos. Hvis sandsynligheden er der, vil Galera flette de primære komponenter som vist i følgende linjer:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
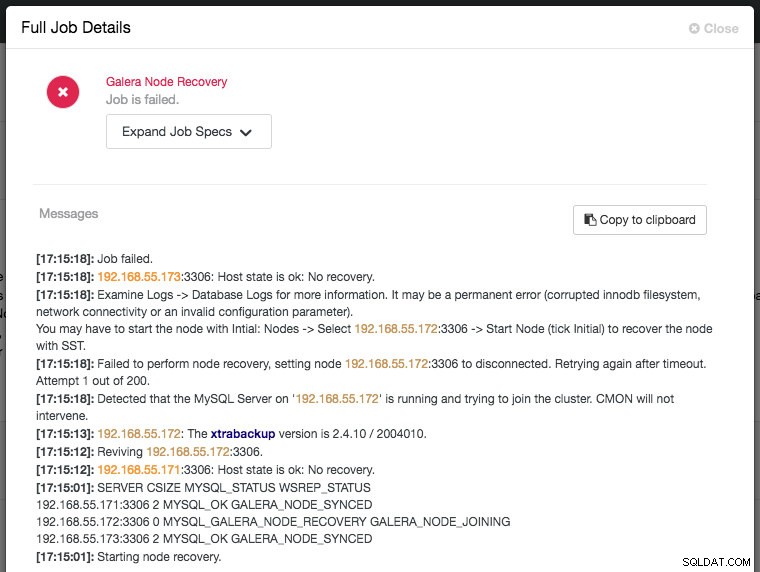
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Konklusion
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.