Før du forsøger at udføre skemaændringer på dine produktionsdatabaser, bør du sikre dig, at du har en bundsolid tilbagerulningsplan; og at din ændringsprocedure er blevet testet og valideret med succes i et separat miljø. Samtidig er det dit ansvar at sørge for, at ændringen ikke forårsager nogen eller mindst mulig påvirkning, der er acceptabel for virksomheden. Det er bestemt ikke en nem opgave.
I denne artikel vil vi tage et kig på, hvordan du udfører databaseændringer på MySQL og MariaDB på en kontrolleret måde. Vi vil snakke om nogle gode vaner i dit daglige DBA-arbejde. Vi vil fokusere på forudgående krav og opgaver under de faktiske operationer og problemer, som du kan komme ud for, når du håndterer databaseskemaændringer. Vi vil også tale om open source-værktøjer, der kan hjælpe dig i processen.
Test og rollback scenarier
Sikkerhedskopi
Der er mange måder at miste dine data på. Skema opgraderingsfejl er en af dem. I modsætning til applikationskode kan du ikke slippe et bundt filer og erklære, at en ny version er blevet implementeret. Du kan heller ikke bare lægge et ældre sæt filer tilbage for at rulle dine ændringer tilbage. Selvfølgelig kan du køre et andet SQL-script for at ændre databasen igen, men der er tilfælde, hvor den eneste nøjagtige måde at rulle ændringer tilbage på er ved at gendanne hele databasen fra backup.
Men hvad nu hvis du ikke har råd til at rulle din database tilbage til den seneste backup, eller dit vedligeholdelsesvindue ikke er stort nok (systemets ydeevne taget i betragtning), så du ikke kan udføre en komplet database backup før ændringen?
Man kan have et sofistikeret, redundant miljø, men så længe data bliver ændret både på primære og standby-steder, er der ikke meget at gøre ved det. Mange scripts kan kun køres én gang, eller ændringerne er umulige at fortryde. Det meste af SQL-ændringskoden falder i to grupper:
- Kør én gang – du kan ikke tilføje den samme kolonne til tabellen to gange.
- Umulig at fortryde – når du først har droppet den kolonne, er den væk. Du kunne uden tvivl gendanne din database, men det er ikke ligefrem en fortrydelse.
Du kan løse dette problem på mindst to mulige måder. En ville være at aktivere den binære log og tage en backup, som er kompatibel med PITR. Sådan sikkerhedskopiering skal være fuld, fuldstændig og konsekvent. For xtrabackup, så længe det indeholder et komplet datasæt, vil det være PITR-kompatibelt. For mysqldump er der også en mulighed for at gøre den PITR-kompatibel. For mindre ændringer ville en variation af mysqldump backup være kun at tage et undersæt af data for at ændre. Dette kan gøres med --where mulighed. Sikkerhedskopieringen bør være en del af den planlagte vedligeholdelse.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlEn anden mulighed er at bruge CREATE TABLE AS SELECT.
Du kan gemme data eller simple strukturændringer i form af en fast midlertidig tabel. Med denne tilgang får du en kilde, hvis du har brug for at rulle dine ændringer tilbage. Det kan være ret praktisk, hvis du ikke ændrer meget data. Tilbageføringen kan ske ved at tage data ud fra den. Hvis der opstår fejl under kopiering af data til tabellen, slettes de automatisk og oprettes ikke, så sørg for, at din erklæring opretter en kopi, du har brug for.
Der er naturligvis også nogle begrænsninger.
Fordi rækkefølgen af rækkerne i de underliggende SELECT-sætninger ikke altid kan bestemmes, markeres CREATE TABLE ... IGNORE SELECT og CREATE TABLE ... REPLACE SELECT som usikre til sætningsbaseret replikering. Sådanne sætninger producerer en advarsel i fejlloggen, når du bruger sætningsbaseret tilstand og skrives til den binære log ved hjælp af det rækkebaserede format, når du bruger MIXED-tilstand.
Et meget simpelt eksempel på en sådan metode kunne være:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;En anden interessant mulighed kan være MariaDB flashback-database. Når der sker en forkert opdatering eller sletning, og du gerne vil vende tilbage til en tilstand af databasen (eller bare en tabel) på et bestemt tidspunkt, kan du bruge flashback-funktionen.
Point-in-time rollback gør det muligt for DBA'er at gendanne data hurtigere ved at rulle transaktioner tilbage til et tidligere tidspunkt i stedet for at udføre en gendannelse fra en backup. Baseret på ROW-baserede DML-hændelser kan flashback transformere den binære log og vende formål. Det betyder, at det kan hjælpe med at fortryde givne rækkeændringer hurtigt. For eksempel kan den ændre DELETE hændelser til INSERTs og omvendt, og den vil bytte WHERE og SET dele af UPDATE hændelserne. Denne enkle idé kan dramatisk fremskynde genopretning fra visse typer fejl eller katastrofer. For dem, der er bekendt med Oracle-databasen, er det en velkendt funktion. Begrænsningen af MariaDB flashback er manglen på DDL-understøttelse.
Opret en forsinket replikeringsslave
Siden version 5.6 understøtter MySQL forsinket replikering. En slaveserver kan halte bagud masteren med mindst en specificeret tid. Standardforsinkelsen er 0 sekunder. Brug indstillingen MASTER_DELAY for SKIFT MASTER TIL for at indstille forsinkelsen til N sekunder:
CHANGE MASTER TO MASTER_DELAY = N;Det ville være en god mulighed, hvis du ikke havde tid til at forberede et ordentligt gendannelsesscenarie. Du skal have nok forsinkelse for at bemærke den problematiske ændring. Fordelen ved denne tilgang er, at du ikke behøver at gendanne din database for at fjerne de nødvendige data for at rette din ændring. Standby DB er oppe og køre, klar til at hente data, hvilket minimerer den nødvendige tid.
Opret en asynkron slave, som ikke er en del af klyngen
Når det kommer til Galera-klyngen, er det ikke let at teste ændringer. Alle noder kører de samme data, og tung belastning kan skade flowkontrol. Så du skal ikke kun kontrollere, om ændringerne blev gennemført med succes, men også, hvad indvirkningen på klyngetilstanden var. For at gøre din testprocedure så tæt som muligt på produktions-arbejdsbelastningen, vil du måske tilføje en asynkron slave til din klynge og køre din test der. Testen vil ikke påvirke synkroniseringen mellem klynge noder, fordi den teknisk set ikke er en del af klyngen, men du vil have mulighed for at tjekke den med rigtige data. En sådan slave kan nemt tilføjes fra ClusterControl.
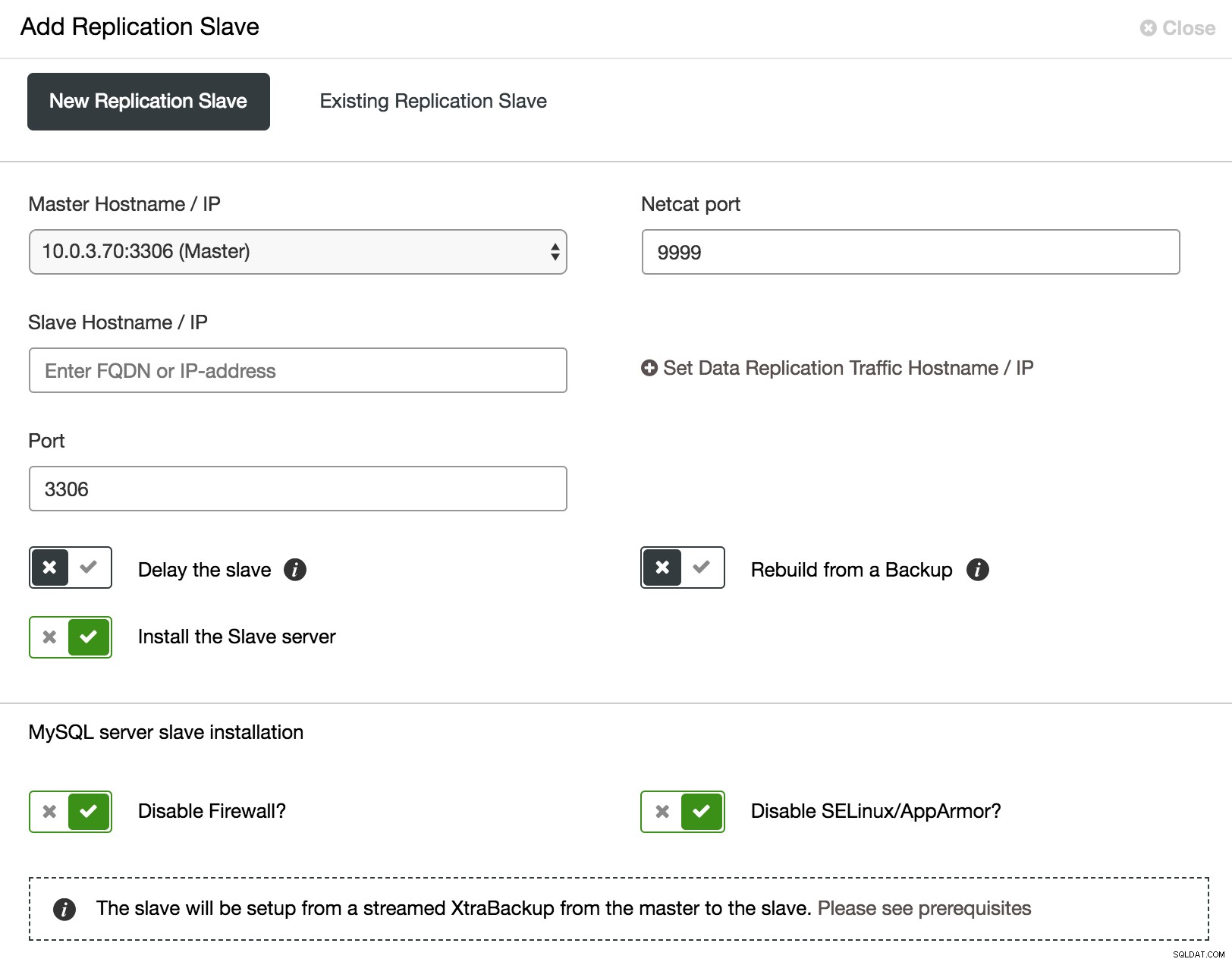 ClusterControl tilføj asynkron slave
ClusterControl tilføj asynkron slave Som vist i ovenstående skærmbillede, kan ClusterControl automatisere processen med at tilføje en asynkron slave på nogle få måder. Du kan tilføje noden til klyngen, forsinke slaven. For at reducere indvirkningen på masteren kan du bruge en eksisterende backup i stedet for masteren som datakilde, når du bygger slaven.
Klon database og mål tid
En god test skal være så tæt som muligt på produktionsændringen. Den bedste måde at gøre dette på er at klone dit eksisterende miljø.
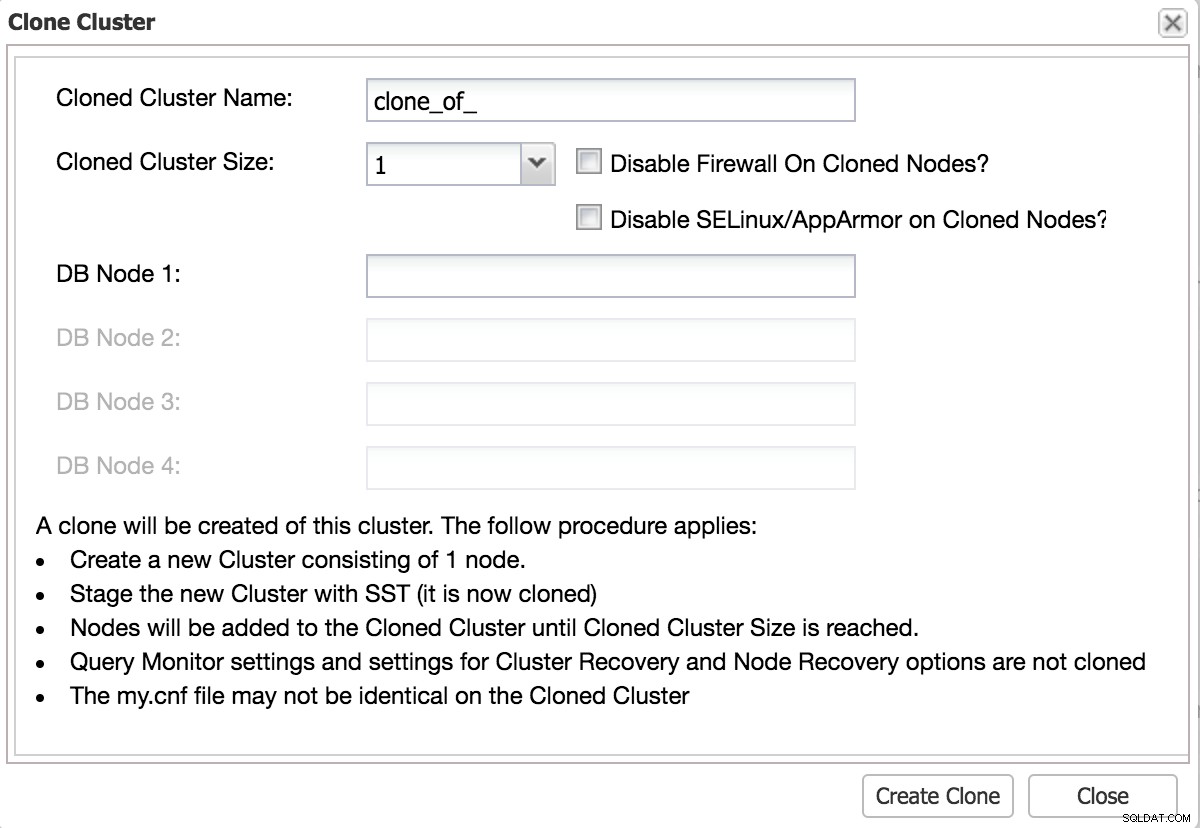 ClusterControl Clone Cluster til test
ClusterControl Clone Cluster til test Udfør ændringer via replikering
For at have bedre kontrol over dine ændringer kan du anvende dem på en slaveserver i forvejen og derefter foretage omstillingen. For sætningsbaseret replikering fungerer dette fint, men for rækkebaseret replikering kan dette fungere op til en vis grad. Rækkebaseret replikering gør det muligt for ekstra kolonner at eksistere i slutningen af tabellen, så så længe den kan skrive de første kolonner, vil det være fint. Anvend først disse indstillinger på alle slaver, derefter failover på en af slaverne og implementer derefter ændringen på masteren og tilknyt den som en slave. Hvis din ændring involverer indsættelse eller fjernelse af en kolonne i midten af tabellen, fungerer den med rækkebaseret replikering.
Betjening
Under vedligeholdelsesvinduet ønsker vi ikke at have programtrafik på databasen. Nogle gange er det svært at lukke ned for alle applikationer spredt over hele virksomheden. Alternativt ønsker vi kun at tillade nogle specifikke værter at få adgang til MySQL fra fjernbetjeningen (for eksempel overvågningssystemet eller backup-serveren). Til dette formål kan vi bruge Linux-pakkefiltrering. For at se hvilke pakkefiltreringsregler der er tilgængelige, kan vi køre følgende kommando:
iptables -L INPUT -vFor at lukke MySQL-porten på alle grænseflader bruger vi:
iptables -A INPUT -p tcp --dport mysql -j DROPog for at åbne MySQL-porten igen efter vedligeholdelsesvinduet:
iptables -D INPUT -p tcp --dport mysql -j DROPFor dem uden root-adgang kan du ændre max_connection til 1 eller 'springe netværk over'.
Logføring
For at starte logningsprocessen skal du bruge tee-kommandoen ved MySQL-klientprompten, sådan her:
mysql> tee /tmp/my.out;Denne kommando fortæller MySQL at logge både input og output fra din nuværende MySQL login session til en fil ved navn /tmp/my.out. Udfør derefter din scriptfil med kildekommando.
For at få et bedre indtryk af dine eksekveringstider, kan du kombinere det med profileringsfunktionen. Start profiler med
SET profiling = 1;Udfør derefter din forespørgsel med
SHOW PROFILES;du ser en liste over forespørgsler, som profileren har statistik for. Så til sidst vælger du, hvilken forespørgsel du vil undersøge med
SHOW PROFILE FOR QUERY 1;Skema-migreringsværktøjer
Mange gange er en direkte ALTER på masteren ikke mulig - i de fleste tilfælde forårsager det forsinkelse på slaven, og dette er muligvis ikke acceptabelt for applikationerne. Hvad der dog kan gøres, er at udføre ændringen i en rullende tilstand. Du kan starte med slaver og, når ændringen er anvendt på slaven, migrere en af slaverne som en ny master, degradere den gamle master til en slave og udføre ændringen på den.
Et værktøj, der kan hjælpe med sådan en opgave, er Perconas pt-online-schema-change. Pt-online-schema-change er ligetil - det opretter en midlertidig tabel med det ønskede nye skema (for eksempel hvis vi tilføjede et indeks eller fjernede en kolonne fra en tabel). Derefter skaber det triggere på det gamle bord. Disse triggere er der for at spejle ændringer, der sker på det originale bord, til det nye bord. Ændringer spejles under skemaændringsprocessen. Hvis en række tilføjes til den oprindelige tabel, tilføjes den også til den nye. Det emulerer den måde, MySQL ændrer tabeller internt på, men det fungerer på en kopi af den tabel, du ønsker at ændre. Det betyder, at den originale tabel ikke er låst, og klienter kan fortsætte med at læse og ændre data i den.
Ligeledes, hvis en række ændres eller slettes på den gamle tabel, anvendes den også i den nye tabel. Derefter begynder en baggrundsproces med kopiering af data (ved hjælp af LOW_PRIORITY INSERT) mellem gammel og ny tabel. Når data er blevet kopieret, udføres RENAME TABLE.
Et andet interessant værktøj er gh-ost. Gh-ost opretter en midlertidig tabel med det ændrede skema, ligesom pt-online-schema-change gør. Den udfører INSERT-forespørgsler, som bruger følgende mønster til at kopiere data fra gammel til ny tabel. Ikke desto mindre bruger den ikke triggere. Desværre kan triggere være kilden til mange begrænsninger. gh-ost bruger den binære logstrøm til at fange tabelændringer og anvender dem asynkront på spøgelsestabellen. Når vi har bekræftet, at gh-ost kan udføre vores skemaændring korrekt, er det tid til rent faktisk at udføre det. Husk, at du muligvis manuelt skal droppe gamle tabeller, der blev oprettet af gh-ost under processen med at teste migreringen. Du kan også bruge --initially-drop-ghost-table og --initially-drop-old-table flag til at bede gh-ost om at gøre det for dig. Den sidste kommando til at udføre er nøjagtig den samme, som vi brugte til at teste vores ændring, vi tilføjede bare --execute til den.
pt-online-schema-change og gh-ost er meget populære blandt Galera-brugere. Ikke desto mindre har Galera nogle ekstra muligheder. De to metoder Total Order Isolation (TOI) og Rolling Schema Upgrade (RSU) har både deres fordele og ulemper.
TOI - Dette er standard DDL-replikeringsmetoden. Noden, der stammer fra skrivesættet, registrerer DDL på parsingtidspunktet og udsender en replikeringshændelse for SQL-sætningen, før DDL-behandlingen overhovedet startes. Skema-opgraderinger kører på alle klynge noder i samme samlede ordresekvens, hvilket forhindrer andre transaktioner i at forpligte sig under operationens varighed. Denne metode er god, når du vil have dine online skemaopgraderinger til at replikere gennem klyngen og ikke har noget imod at låse hele tabellen (svarende til hvordan standardskemaændringer skete i MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU - udfør skemaopgraderingerne lokalt. I denne metode påvirker dine skrivninger kun den node, hvorpå de køres. Ændringerne kopieres ikke til resten af klyngen. Denne metode er god til ikke-modstridende operationer, og den vil ikke bremse klyngen.
SET GLOBAL wsrep_OSU_method='RSU';Mens noden behandler skemaopgraderingen, desynkroniseres den med klyngen. Når den er færdig med at behandle skemaopgraderingen, anvender den forsinkede replikeringshændelser og synkroniserer sig selv med klyngen. Dette kunne være en god mulighed for at køre tunge indeksoprettelser.
Konklusion
Vi præsenterede her flere forskellige metoder, der kan hjælpe dig med at planlægge dine skemaændringer. Det afhænger selvfølgelig af din ansøgning og forretningskrav. Du kan designe din forandringsplan, udføre nødvendige tests, men der er stadig en lille chance for, at noget går galt. Ifølge Murphys lov - "vil ting gå galt i enhver given situation, hvis du giver dem en chance". Så sørg for at prøve forskellige måder at udføre disse ændringer på, og vælg den, du er mest komfortabel med.