
I en tidligere artikel undersøgte vi SQL Server-indekskrav og ydeevneovervejelser. Når det kommer til databaseydeevne, er ydeevnejustering uden tvivl en af de vigtigste og mest komplekse funktioner. Den består af mange forskellige områder såsom SQL-forespørgselsoptimering, indeksjustering og systemressourcejustering, som alle skal udføres korrekt for at kunne hente data hurtigt.
Der er flere vigtige områder at overveje, når det kommer til SQL Server-indekser, da de kan have en betydelig indflydelse på både din indsats for justering af ydeevne og den samlede databaseydeevne. Nedenfor er nogle detaljer om hver enkelt og de kritiske roller, de spiller.
SQL Server-indeksets bedste praksis
1. Forstå, hvordan databasedesign påvirker SQL Server-indekser
Indekseringskravene varierer mellem online transaktionsbehandling (OLTP) og online analytisk behandling (OLAP) databaser.
I en OLTP-database udfører brugere hyppige læse-skrivehandlinger, indsætter nye data og ændrer eksisterende data. De bruger datamanipulationssprogsforespørgsler (Insert, Update, Delete) sammen med Select-sætninger til datahentning og ændringer. For OLTP-databaser er det bedst at oprette indekser i kolonnen Valgt i en tabel. Flere indekser kan have en negativ indvirkning på ydeevnen og lægge pres på systemressourcer. I stedet anbefales det at oprette det mindste antal indekser, der kan opfylde dine indekseringskrav. I OLAP-databaser på den anden side bruger du for det meste Select-udsagn til at hente data til yderligere analytiske formål. I dette tilfælde kan du tilføje flere indekser med flere nøglekolonner pr. indeks. Du kan også udnytte kolonnelagerindekser til hurtigere datahentning i datavarehusforespørgsler
2. Opret indekser til dine krav til arbejdsbelastning
Når du opretter en ny tabel i din database, skal du ikke bare tilføje indekser blindt. Nogle gange sætter udviklere et klynget indeks og et par ikke-klyngede indeks på det uden at lede efter de forespørgsler, der bruger disse indekser. Der kan være et indeks, der ikke opfylder forespørgselsoptimeringskravet; Derfor bør du korrekt analysere din arbejdsbyrde og SQL-forespørgsler (lagrede procedurer, funktioner, visninger og ad-hoc-forespørgsler). Du kan fange arbejdsbyrden ved hjælp af SQL-profiler, udvidede hændelser og dynamiske administrationsvisninger og derefter oprette indekser for at optimere ressourcekrævende forespørgsler.
3. Opret indekser for de mest brugte og mest brugte forespørgsler
Det er vigtigt at gruppere arbejdsbelastninger for de mest brugte forespørgsler i dit system. Ved at oprette de bedste indekser til disse forespørgsler vil det belaste dit system mindst muligt.
4. Anvend bedste praksis for SQL Server-indeksnøglekolonnen
Da du kan have flere kolonner i en tabel, er her et par overvejelser for indeksnøglekolonner.
- Kolonner med tekst, billede, ntext, varchar(max), nvarchar(max) og varbinary(max) kan ikke bruges i indeksnøglekolonnerne.
- Det anbefales at bruge en heltalsdatatype i indeksnøglekolonnen. Den har et lavt pladsbehov og fungerer effektivt. På grund af dette vil du gerne oprette den primære nøglekolonne, normalt på en heltalsdatatype.
- Du kan kun bruge XML-datatypen i et XML-indeks.
- Du bør overveje at oprette en primær nøgle til kolonnen med unikke værdier. Hvis en tabel ikke har nogen unikke værdikolonner, kan du definere en identitetskolonne for en heltalsdatatype. En primær nøgle opretter også et klynget indeks for rækkefordelingen.
- Du kan overveje en kolonne med værdierne Unique og Not NULL som en nyttig indeksnøglekandidat.
- Du bør bygge et indeks baseret på prædikaterne i Where-sætningen. For eksempel kan du overveje kolonner, der bruges i Where-sætningen, SQL joins, ligesom, rækkefølge efter, gruppere efter prædikater og så videre.
- Du bør forbinde tabeller på en måde, der reducerer antallet af rækker for resten af forespørgslen. Dette vil hjælpe forespørgselsoptimering med at forberede udførelsesplanen med et minimum af systemressourcer.
- Hvis du bruger flere kolonner til en indeksnøgle, er det også vigtigt at overveje deres placering i indeksnøglen.
- Du bør også overveje at bruge inkluderede kolonner i dine indekser.
5. Analyser datafordelingen af dine SQL Server-indekskolonner
Du bør undersøge datafordelingen i SQL Server-indeksnøglekolonnerne. En kolonne med ikke-unikke værdier kan forårsage en forsinkelse i at hente dataene og resultere i en langvarig transaktion. Du kan analysere datafordelingen ved hjælp af histogrammet i statistik.
6. Brug datasorteringsrækkefølge
Du bør også overveje datasorteringskravene i dine forespørgsler og indekser. Som standard sorterer SQL Server data i stigende rækkefølge i et indeks. Antag, at du opretter et indeks i stigende rækkefølge, men dine forespørgsler bruger Order By-sætningen til at sortere data i faldende rækkefølge.
Se f.eks. den faktiske udførelsesplan for følgende forespørgsel.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
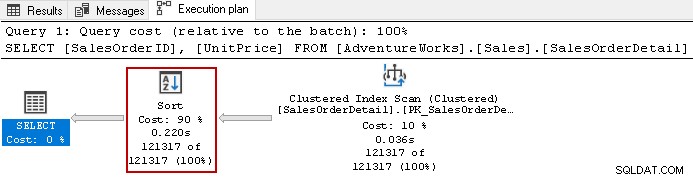
Den bruger den dyre sorteringsoperator med en samlet 90 % omkostning i denne forespørgsel. Vi besluttede at bygge et ikke-klynget indeks på [UnitPrice] og [SalesOrderID]. Den bruger en standard sorteringsrækkefølge for begge kolonner i indekset.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Vi kørte Select-sætningen igen, og forespørgselsoptimeringsværktøjet bruger stadig sorteringsoperatoren. Den kan bruge det ikke-klyngede indeks, men sorterer dataene for at forberede resultatet.
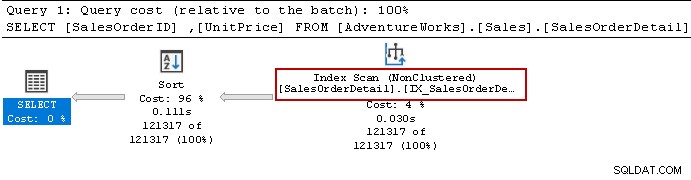
Lad os genskabe indekset ved hjælp af følgende forespørgsel. Denne gang sorterer den data i faldende rækkefølge for [Enhedspris] i indeksdefinitionen.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
Det kræver ikke nogen sorteringsoperator nu, fordi indekset opfylder forespørgselskravene.
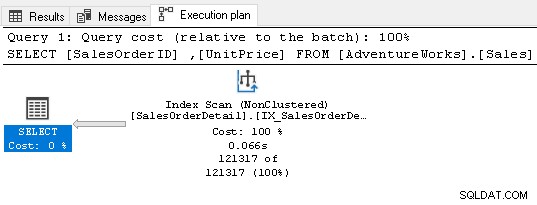
7. Brug fremmednøgler til dit SQL Server-indeks
Du bør oprette et indeks på kolonnerne med fremmednøgler. Det er tilrådeligt at oprette et klynget indeks på den fremmede nøgle for at forbedre forespørgselsydeevnen.
8. Vær opmærksom på overvejelser om SQL Server-indekslagring
Indekslagring er også et nyttigt aspekt at overveje. SQL Server opretter alle indekser på den samme filgruppe i tabellen. Du kan overveje en separat filgruppe for indekser og adskille den fysiske fil på en separat disk. Dette vil øge IO-ydeevne og gennemløb.
På samme måde kan du bruge tabelpartitionering til at adskille data på tværs af flere diske og filgrupper. Du kan designe partitionerede indekser til disse tabelpartitioner for at forbedre samtidig dataadgang.
En anden mulighed er at definere FILLFACTOR, mens du opretter eller genopbygger et indeks. En FILLFACTOR definerer den ledige plads på bladknudedatasiderne. Det er nyttigt til yderligere dataindsættelser. Hvis dine data er statiske og ikke ofte ændres, kan du overveje en høj værdi af FILLFACTOR. På den anden side, for hyppigt skiftende data, kan du efterlade plads nok til nye dataindsættelser.
9. Find manglende indekser
Nogle gange får du information om et manglende SQL Server-indeks i forespørgselsudførelsesplanen. Du kan også køre de dynamiske administrationsvisninger for at finde disse manglende indekser. Du bør ikke blindt oprette disse indekser. Det er blot et forslag til forespørgselsoptimering, men det tager ikke hensyn til det eksisterende indeks eller dine krav til arbejdsbelastning. Det kan også inkludere flere kolonner i indeksdefinitionen, så gennemgå disse forslag, før du implementerer det.
10. Opret altid et klynget indeks før et ikke-klynget indeks
Som en generel retningslinje bør du oprette et klynget indeks, før du bygger ikke-klyngede indekser. Hvis en tabel ikke har et indeks, består et ikke-klynget indeks af rækkeidentifikatorer. Når du har oprettet et klynget indeks, skal SQL Server genopbygge disse ikke-klyngede indekser, så de kan pege på den klyngede indeksnøgle i stedet for række-id'erne.
11. Overvåg indeksvedligeholdelse og opdater statistik
Nedenfor er flere vedligeholdelsesområder, der skal overvåges, når det kommer til SQL Server-indekser.
- Fjern indeksfragmentering :Du bør regelmæssigt gennemgå interne og eksterne fragmenteringer, især for de høje transaktionstabeller. Dine forespørgsler reagerer muligvis langsomt, selvom du har korrekte indekser til dine arbejdsbelastninger. Et stærkt fragmenteret indeks kan forringe ydeevnen, fordi det kræver yderligere IO. Du kan udføre en omorganisering eller genopbygge et indeks baseret på dets fragmenteringsværdier. Normalt bør du genopbygge indekset, hvis det har en fragmentering på mere end 30 %, og omorganisere det, hvis det har mindre end 30 % fragmentering.
- Fjern ubrugte indekser: Du bør altid gennemgå de ubrugte (tomgangs) indekser i din database, fordi forespørgselsoptimeringsværktøjet skal overveje dem for hver forespørgsel. Et ubrugt indeks bruger også lagerplads og øger vedligeholdelsesomkostningerne.
- Opdater statistik: Du bør jævnligt opdatere statistikken, selvom du har indstillet statistikken for automatisk opdatering i din databasekonfiguration. Forespørgselsoptimeringsværktøjet kan forberede en dårlig eksekveringsplan, hvis indeksstatistikken ikke opdateres. Du kan planlægge et agentjob for at opdatere SQL Server-statistikker med en fuld scanning efter arbejdstid.
Du kan henvise til SQL-indeksvedligeholdelse for yderligere indsigt om dette emne.
Anvendelse af bedste praksis for SQL Server-indeks
Selvom der ikke altid er en ligetil måde at designe et optimalt SQL Server-indeks på, vil anvendelsen af de anbefalinger, der er specificeret i dette indlæg, hjælpe dig med at navigere i de forskellige indekseringskrav, du vil støde på med hver databasetype og dens arbejdsbelastninger. Disse bedste fremgangsmåder hjælper med at optimere dine indekser for at forbedre databaseydeevnen og sikre en jævnere ydelsesjusteringsproces undervejs.