Jeg fortsætter en række artikler om det grundlæggende i EXPLAIN i PostgreSQL, som er en kort gennemgang af Understanding EXPLAIN af Guillaume Lelarge.
For bedre at forstå problemet, anbefaler jeg stærkt at gennemgå den originale "Understanding EXPLAIN" af Guillaume Lelarge og læs min første og anden artikel.
BEstil efter
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Først udfører du en sekventiel scanning (Seq Scan) af foo-tabellen og udfører derefter sorteringen (Sort). Tegnet -> for EXPLAIN-kommandoen angiver hierarkiet af trin (knudepunkt). Jo tidligere trinnet udføres, jo større indrykning har det.
Sorteringsnøgle er en betingelse for sortering.
Sorteringsmetode:ekstern fletning Disk en midlertidig fil på disken med en kapacitet på 4592 kB bruges ved sortering.
Tjek med BUFFERE-indstillingen:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
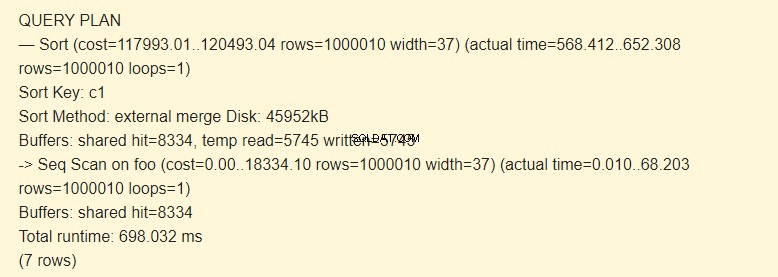
Faktisk betyder linjen temp read=5745 written=5745, at 45960Kb (5745 blokke på 8 Kb hver) blev gemt og læst i den midlertidige fil. Operationerne med 8334 blokke blev udført i cachen.
Operationerne med filsystemet er langsommere end operationer i RAM.
Lad os prøve at øge hukommelseskapaciteten for work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Sorteringsmetode:quicksort Hukommelse:102702kB – hele sorteringen blev udført i RAM.
Indekset er som følger:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Vi har kun Index Scan tilbage, hvilket markant påvirkede hastigheden af forespørgslen.
LIMIT
Slet det tidligere oprettede indeks:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Som forventet bruges Seq Scan og Filter.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan læser rækker i tabellen og sammenligner dem (Filter) med betingelsen. Så snart der er 10 poster, der opfylder betingelsen, afsluttes scanningen. I vores tilfælde, for at få 10 resultatrækker, skulle vi kun læse 3063 poster i stedet for hele tabellen. 3053 rækker af dette nummer blev afvist (rækker fjernet af filter).
Det samme sker med Index Scan.
DELTAG
Opret en ny tabel og generer statistik for den:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Forespørgslen for to tabeller er som følger:
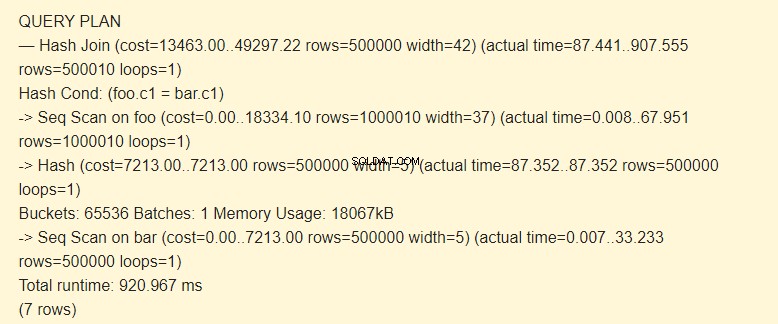
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Først læser sekventiel scanning (Seq Scan) bjælketabellen. En hash (hash) beregnes for hver række.
Derefter scanner den foo-tabellen, og for hver række beregnes en hash, der sammenlignes (Hash Join) med hash-værdien af bar-tabellen ved Hash Cond-betingelsen. Hvis de matcher, udsendes en resulterende streng.
18067 kB hukommelse bruges til at gemme hashes til linjen.
Tilføj indekset:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash bruges ikke længere. Merge Join og Index Scan på indeksene i begge tabeller forbedrer ydeevnen betydeligt.
VENSTRE JOIN:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
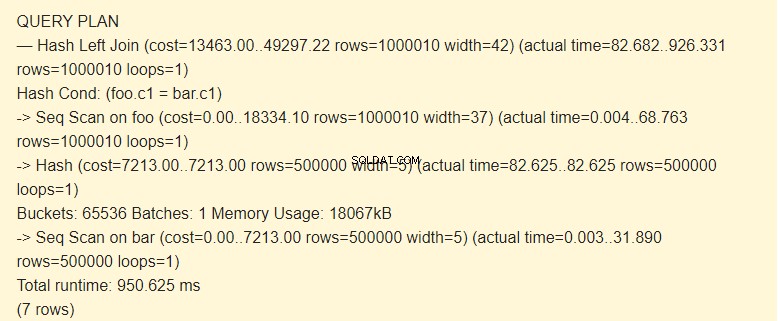
Seq Scan?
Lad os se, hvilket resultat vi får, hvis vi deaktiverer Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Ifølge planlæggeren er det dyrere at bruge indekser end at bruge hashes. Dette er muligt med en tilstrækkelig stor mængde tildelt hukommelse. Kan du huske, at vi øger work_mem?
Men hvis du ikke har nok hukommelse, vil planlæggeren opføre sig anderledes:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Hvis vi deaktiverer Index Scan, hvilket resultat vil EXPLAIN vise?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
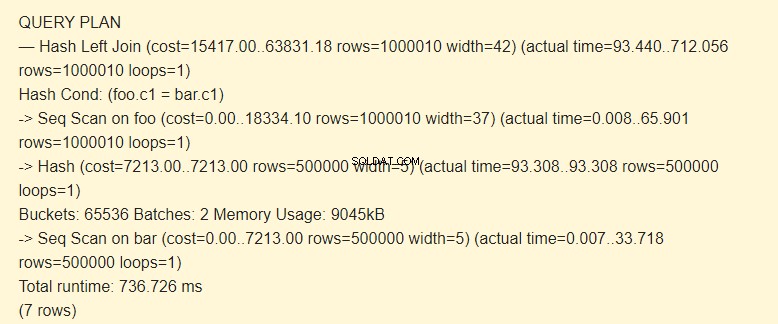
Batches:2 har øget omkostninger. Hele hashen passede ikke i hukommelsen; vi var nødt til at opdele det i to pakker på 9045 kB.
Tak fordi du læste mine artikler! Jeg håber, de var nyttige. Hvis du har kommentarer eller feedback, er du velkommen til at fortælle mig det.