
SQL Server-indekser bruges til at hjælpe med at hente data hurtigere og reducere flaskehalse, der påvirker kritiske ressourcer. Indekser på en databasetabel fungerer som en ydelsesoptimeringsteknik. Du undrer dig måske – hvordan øger indekser forespørgselsydeevne? Findes der sådanne ting som gode og dårlige indekser? Antag at du har en tabel med 50 kolonner, er det en god idé at lave indekser på hver af kolonnerne? Hvis vi opretter flere indekser, hjælper det så SQL-forespørgsler med at køre hurtigere?
Alle gode spørgsmål, men før vi dykker ind, er det vigtigt at vide, hvorfor indekser kan være påkrævet i første omgang.
Forestil dig, at du besøger et bybibliotek, der har en samling på tusindvis af bøger. Du leder efter en bestemt bog, men hvordan finder du den? Hvis du gennemgik hver bog i hvert stativ, kunne det tage dage at finde den. Det samme gælder for en database, når du leder efter en post fra de millioner af rækker, der er gemt i en tabel.
Et SQL Server-indeks er formet i et B-Tree-format der består af en rodknude øverst og en bladknude nederst. For eksempel på vores biblioteksbøger udsender en bruger en forespørgsel for at søge efter en bog med ID 391. I dette tilfælde begynder forespørgselsmotoren at krydse fra rodnoden og flytter til bladknuden.
Root Node –> Mellemliggende node –> Bladknude.
Forespørgselsmotoren leder efter referencesiden på mellemniveauet. I dette eksempel består den første mellemnode af bog-id'er fra 1-500, og den anden mellemknude består af 501-1000.
Baseret på den mellemliggende knude, krydser forespørgselsmotoren gennem B-træet for at lede efter den tilsvarende mellemknude og bladknudepunktet. Denne bladknude kan bestå af faktiske data eller pege på den faktiske dataside baseret på indekstypen. På billedet nedenfor ser vi, hvordan man krydser indekset for at søge efter data ved hjælp af SQL Server-indekser. I dette tilfælde behøver SQL Server ikke at gennemgå hver side, læse den og lede efter et specifikt bog-id-indhold.
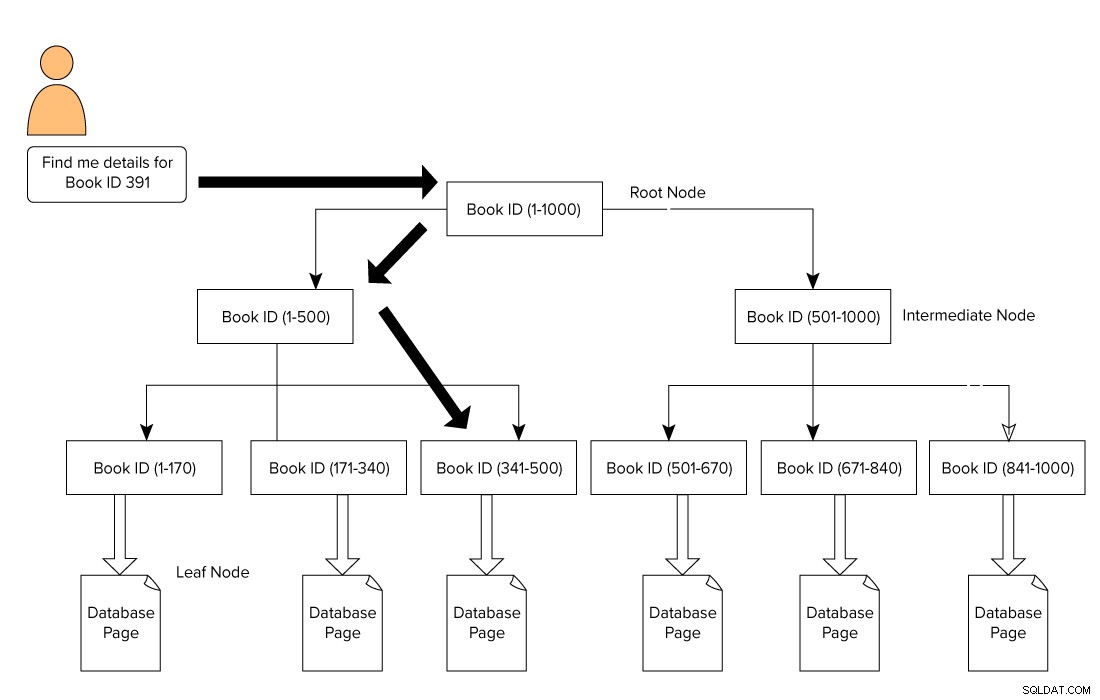
Indeksers indvirkning på SQL Server-ydeevne
I det tidligere bibliotekseksempel undersøgte vi de potentielle indeksydelsespåvirkninger. Lad os se på forespørgselsydeevnen med og uden et indeks.
Antag, at vi kræver data for [SalesOrderID] 56958 fra tabellen [SalesOrderDetail_Demo].
VÆLG *
FRA [AdventureWorks].[Salg].[SalesOrderDetail_Demo]
hvor SalesOrderID=56958
Denne tabel har ingen indekser. En tabel uden nogen indekser kaldes en heap-tabel i SQL Server.
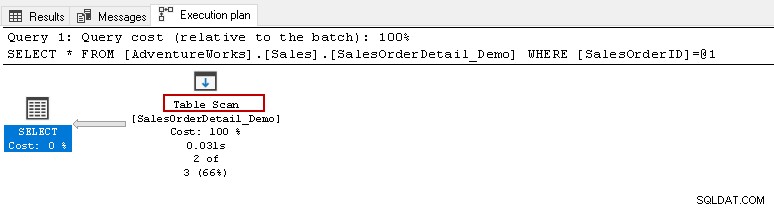
Herfra vil du gerne køre ovenstående udvalgserklæring og se den faktiske udførelsesplan. Denne tabel har 121317 poster i sig. Den udfører en tabelscanning, hvilket betyder, at den læser alle rækker i en tabel for at finde det specifikke [SalesOrderID].
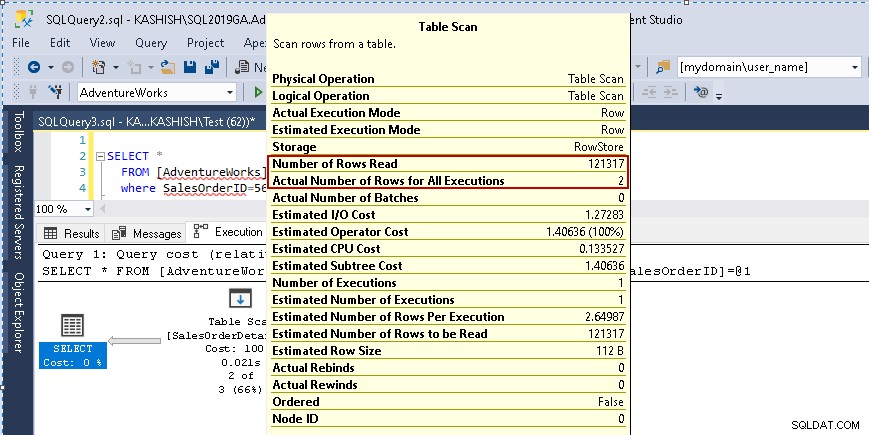
Når du holder markøren over ikonet for tabelscanning, viser det, at det faktiske resultatsæt indeholder 2 rækker, men til dette formål læser det alle rækker i den tabel.
- Antal læste rækker:121317
- Det faktiske antal rækker for udførelsen:2
Tænk nu på en tabel med millioner eller milliarder af rækker. Det er ikke en god praksis at gennemgå alle poster i tabellen for at filtrere nogle få rækker. I et omfattende databasesystem til online transaktionsbehandling (OLTP) bruger det ikke serverressourcer (CPU, IO, hukommelse) effektivt, og derfor kan brugeren stå over for ydeevneproblemer.
Lad os nu køre ovenstående udvalgserklæring med tabellen med indekser. Denne tabel har et primært nøgleklyngeindeks og to ikke-klyngede indekser på kolonnerne [ProductID] og [rowguid]. Vi vil senere tale om de forskellige typer af indekser i SQL Server.
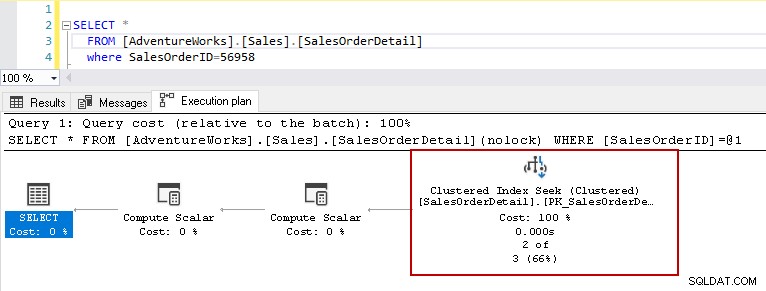
Hvis du nu kører select-sætningen igen med det samme prædikat, viser udførelsesplanen præstationsproblemet. Forespørgselsoptimering beslutter at bruge klynget indekssøgning i stedet for en klynget indeksscanning.
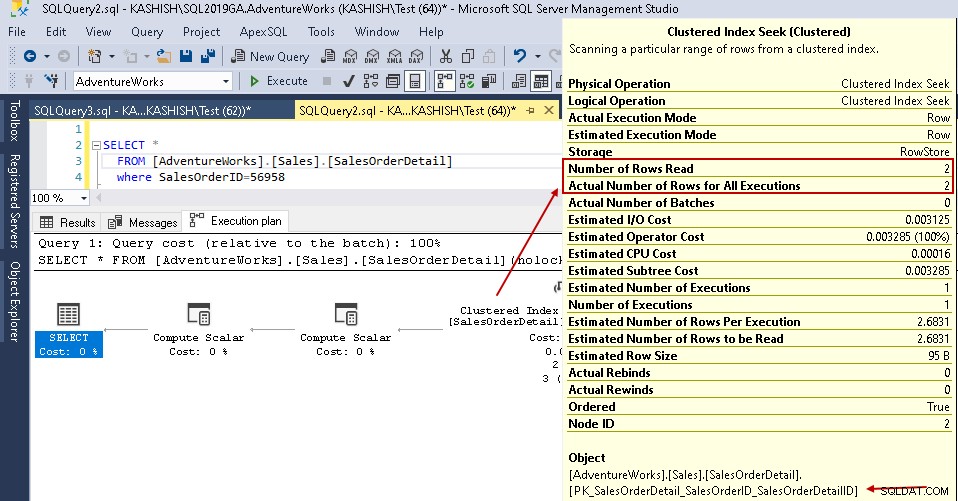
I de klyngede indekssøgningsdetaljer viser den forespørgselsoptimering nøjagtigt, som læser rækkerne, den gav i outputtet.
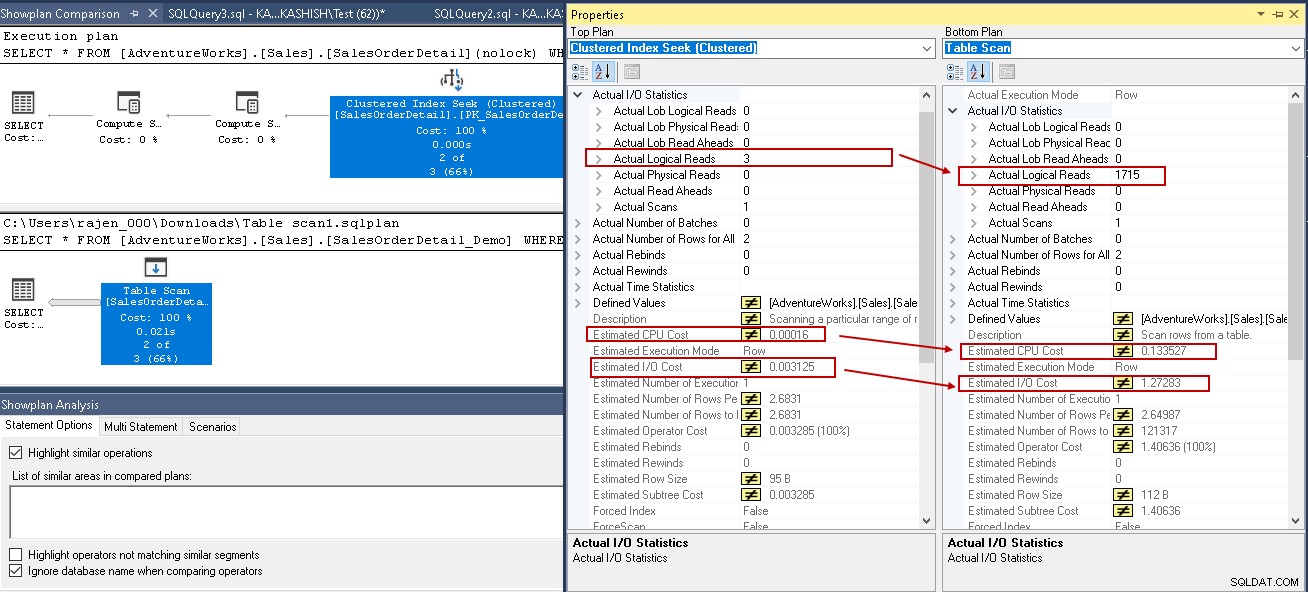
For at give dig en sammenlignende analyse, lad os sammenligne udførelsesplanen med og uden et SQL Server-indeks. Du kan henvise til SQL Shacks Sådan sammenlignes planer for udførelse af forespørgsler i SQL Server 2016 -artikel for yderligere indsigt.
For dette eksempel skal du se på de fremhævede værdier i den grupperede indekssøgning og tabelscanning:
- Logiske læsninger:SQL Server-databasemotor læser en side fra buffercachen, og den forårsager en logisk læsning. Nedenfor ser vi, at logiske læsninger reduceres fra 1715 til 3, når du har oprettet indekset.
- De anslåede CPU-omkostninger falder også fra 0,133527 til 0,00016
- Estimerede IO-omkostninger falder fra 1,27283 til 0,003125
Billedet nedenfor viser forskellen mellem en tabelscanning og en indekssøgning.
Gode (nyttige) indekser og dårlige indekser i SQL Server
Som navnet antyder, forbedrer et godt indeks forespørgselsydeevne og minimerer ressourceudnyttelsen. Kan et indeks reducere ydelsen af forespørgsler i SQL Server? Nogle gange opretter vi indekset på en bestemt kolonne, men det bliver aldrig brugt. Antag, at du har et indeks på en kolonne, og du udfører en masse indsættelser og opdateringer for den kolonne. For hver opdatering er den tilsvarende indeksopdatering også påkrævet. Hvis din arbejdsbyrde har mere skriveaktivitet, og du har mange indekser på en kolonne, ville det bremse den overordnede ydeevne af dine forespørgsler. Et ubrugt indeks kan også forårsage langsom ydeevne for udvalgte udsagn. Forespørgselsoptimeringsværktøjet bruger statistik til at opbygge en eksekveringsplan. Den læser alle indekserne og deres datasampling, og baseret på det opbygger den en optimeret plan for udførelse af forespørgsler. Du kan spore dit indeksbrug ved hjælp af den dynamiske administrationsvisning sys.dm_db_index_usage_stats og overvåge ressourcerne, såsom brugerscanning, brugersøgninger og brugeropslag.
SQL Server-indekstyper og overvejelser
SQL Server har to hovedindekser - klyngede og ikke-klyngede indekser. Et klynget indeks gemmer de faktiske data i indeksets bladknude. Det sorterer fysisk dataene på datasiderne baseret på den klyngede indeksnøgle. SQL Server tillader et klynget indeks pr. tabel. Du kan forbinde flere kolonner for at bygge en klynget indeksnøgle. Et ikke-klynget indeks er et logisk indeks, og det har indeksnøglekolonnen, der peger på den klyngede indeksnøgle.
Vi kan også have andre indekser i SQL Server, såsom XML-indeks, kolonnelagerindeks, rumligt indeks, fuldtekstindeks, hash-indeks osv.
Du bør overveje følgende punkter, før du opbygger et indeks i SQL Server:
- Arbejdsbelastning
- Kolonnen, hvor indekset er påkrævet
- Tabelstørrelse
- Stigende eller faldende rækkefølge af kolonnedata
- Kolonnerækkefølge
- Indekstype
- Fyldfaktor, padindeks og TempDB-sorteringsrækkefølge
SQL Server-indeksfordele, implikationer og anbefalinger
Indekser i en database kan være et tveægget sværd. Et nyttigt SQL Server-indeks forbedrer forespørgslen og systemets ydeevne uden at påvirke de andre forespørgsler. På den anden side, hvis du opretter et indeks uden nogen forberedelse eller overvejelse, kan det forårsage ydeevneforringelser, langsom datahentning og kunne forbruge mere kritiske ressourcer såsom CPU, IO og hukommelse. Indekser øger også dine databasevedligeholdelsesopgaver. Med disse faktorer i tankerne er det altid bedst at teste et passende indeks i et præproduktionsmiljø med den produktionsækvivalente arbejdsbyrde, derefter analysere ydeevne og beslutte, om det er bedst at implementere det på en produktionsdatabase. Der er mange flere anbefalinger at tage hensyn til. Se mine 11 bedste indeksbestemte fremgangsmåder for yderligere indsigt.