Hej,
Brugen af Index i SQL Server-databasen forekommer i miljøer, der kræver størst ydeevne, hastighed og hukommelsesbesparelser.
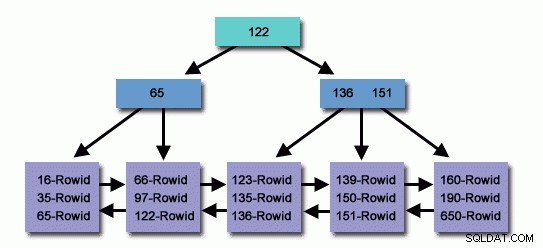
I en tabel med millioner eller milliarder af poster kan vi bruge et indeks til at læse færre poster og søge mindre for at finde relateret post.
Nøjagtigt oprettet Index, millioner af poster i databasen, vi har søgt inden for meget kort tid for at bringe posten af den, der ringer bekvemmelighed, mens på samme tid mindre læse posten ved at nå målet posten, vi bruger operativsystemets ressourcer effektivt.
Du bør oprette indeks for for det meste skrivebeskyttede forespørgsler på en tabel. Hvis Slet, opdateringshandlinger er mere end skrivebeskyttede forespørgsler, bør du ikke oprette indeks for den tabel.
Du kan se på den manglende indeksanbefaling af SQL Server med følgende script. Du kan oprette manglende indeks, men du bør overvåge disse indeks. Hvis de ikke er nyttige, bør du droppe dem.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;