I et tidligere indlæg diskuterede vi, hvordan du kan tage kontrol over failover-processen i ClusterControl ved at bruge hvidlister og sortlister. I dette indlæg vil vi diskutere et lignende koncept. Men denne gang vil vi fokusere på integrationer med eksterne scripts og applikationer gennem adskillige hooks, der er stillet til rådighed af ClusterControl.
Infrastrukturmiljøer kan bygges på forskellige måder, da der ofte er mange muligheder at vælge imellem for en given brik i puslespillet. Hvordan definerer vi hvilken databasenode der skal skrives til? Bruger du virtuel IP? Bruger du en form for serviceopdagelse? Måske går du med DNS-indtastninger og ændrer A-posterne, når det er nødvendigt? Hvad med proxy-laget? Stoler du på 'read_only'-værdien for at dine fuldmagter kan beslutte sig for forfatteren, eller måske foretager du de nødvendige ændringer direkte i konfigurationen af proxyen? Hvordan håndterer dit miljø overgange? Kan du bare gå videre og udføre det, eller måske skal du tage nogle foreløbige handlinger på forhånd? For eksempel at stoppe nogle andre processer, før du rent faktisk kan foretage skiftet?
Det er ikke muligt for en failover-software at være prækonfigureret til at dække alle de forskellige opsætninger, som folk kan oprette. Dette er hovedårsagen til at tilbyde forskellige måder at tilslutte sig failover-processen. På denne måde kan du tilpasse det og gøre det muligt at håndtere alle finesser i din opsætning. I dette blogindlæg vil vi se på, hvordan ClusterControls failover-proces kan tilpasses ved hjælp af forskellige pre- og post-failover-scripts. Vi vil også diskutere nogle eksempler på, hvad der kan opnås med en sådan tilpasning.
Integration af ClusterControl
ClusterControl giver flere kroge, der kan bruges til at tilslutte eksterne scripts. Nedenfor finder du en liste over dem med en vis forklaring.
- Replication_onfail_failover_script - dette script udføres, så snart det er blevet opdaget, at en failover er nødvendig. Hvis scriptet returnerer ikke-nul, vil det tvinge failover til at afbryde. Hvis scriptet er defineret, men ikke fundet, vil failover blive afbrudt. Fire argumenter leveres til scriptet:arg1='alle servere' arg2='oldmaster' arg3='candidate', arg4='oldmasters slaver' og bestået således:'scripname arg1 arg2 arg3 arg4'. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
- Replication_pre_failover_script - dette script udføres før failoveren sker, men efter at en kandidat er blevet valgt, og det er muligt at fortsætte failover-processen. Hvis scriptet returnerer ikke-nul, vil det tvinge failover til at afbryde. Hvis scriptet er defineret, men ikke fundet, vil failover blive afbrudt. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
- Replication_post_failover_script - dette script udføres efter failoveren skete. Hvis scriptet returnerer ikke-nul, vil der blive skrevet en advarsel i jobloggen. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
- Replication_post_unsuccessful_failover_script - Dette script udføres efter failover-forsøget mislykkedes. Hvis scriptet returnerer ikke-nul, vil der blive skrevet en advarsel i jobloggen. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
- Replication_failed_reslave_failover_script - dette script udføres, efter at en ny master er blevet forfremmet, og hvis reslaveringen af slaverne til den nye master mislykkes. Hvis scriptet returnerer ikke-nul, vil der blive skrevet en advarsel i jobloggen. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
- Replication_pre_switchover_script - dette script udføres før overgangen sker. Hvis scriptet returnerer ikke-nul, vil det tvinge overgangen til at mislykkes. Hvis scriptet er defineret, men ikke fundet, vil skiftet blive afbrudt. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
- Replication_post_switchover_script - dette script udføres efter skiftet skete. Hvis scriptet returnerer ikke-nul, vil der blive skrevet en advarsel i jobloggen. Scriptet skal være tilgængeligt på controlleren og være eksekverbart.
Som du kan se, dækker krogene over de fleste tilfælde, hvor du måske ønsker at tage nogle handlinger - før og efter en omstilling, før og efter en failover, når reslaven har fejlet, eller når failoveren har fejlet. Alle scripts påkaldes med fire argumenter (som muligvis håndteres i scriptet eller ikke, det er ikke nødvendigt for scriptet at bruge dem alle):alle servere, værtsnavn (eller IP - som det er defineret i ClusterControl) af den gamle master, værtsnavnet (eller IP - som det er defineret i ClusterControl) for masterkandidaten og den fjerde, alle replikaer af den gamle master. Disse muligheder skulle gøre det muligt at håndtere størstedelen af sagerne.
Alle disse hooks skal defineres i en konfigurationsfil for en given klynge (/etc/cmon.d/cmon_X.cnf hvor X er klyngens id). Et eksempel kan se sådan ud:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shNaturligvis skal påkaldte scripts være eksekverbare, ellers vil cmon ikke være i stand til at udføre dem. Lad os nu tage et øjeblik og gennemgå failover-processen i ClusterControl og se, hvornår de eksterne scripts udføres.
Failover-proces i ClusterControl
Vi definerede alle de kroge, der er tilgængelige:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shHerefter skal du genstarte cmon-processen. Når det er gjort, er vi klar til at teste failoveren. Den originale topologi ser således ud:
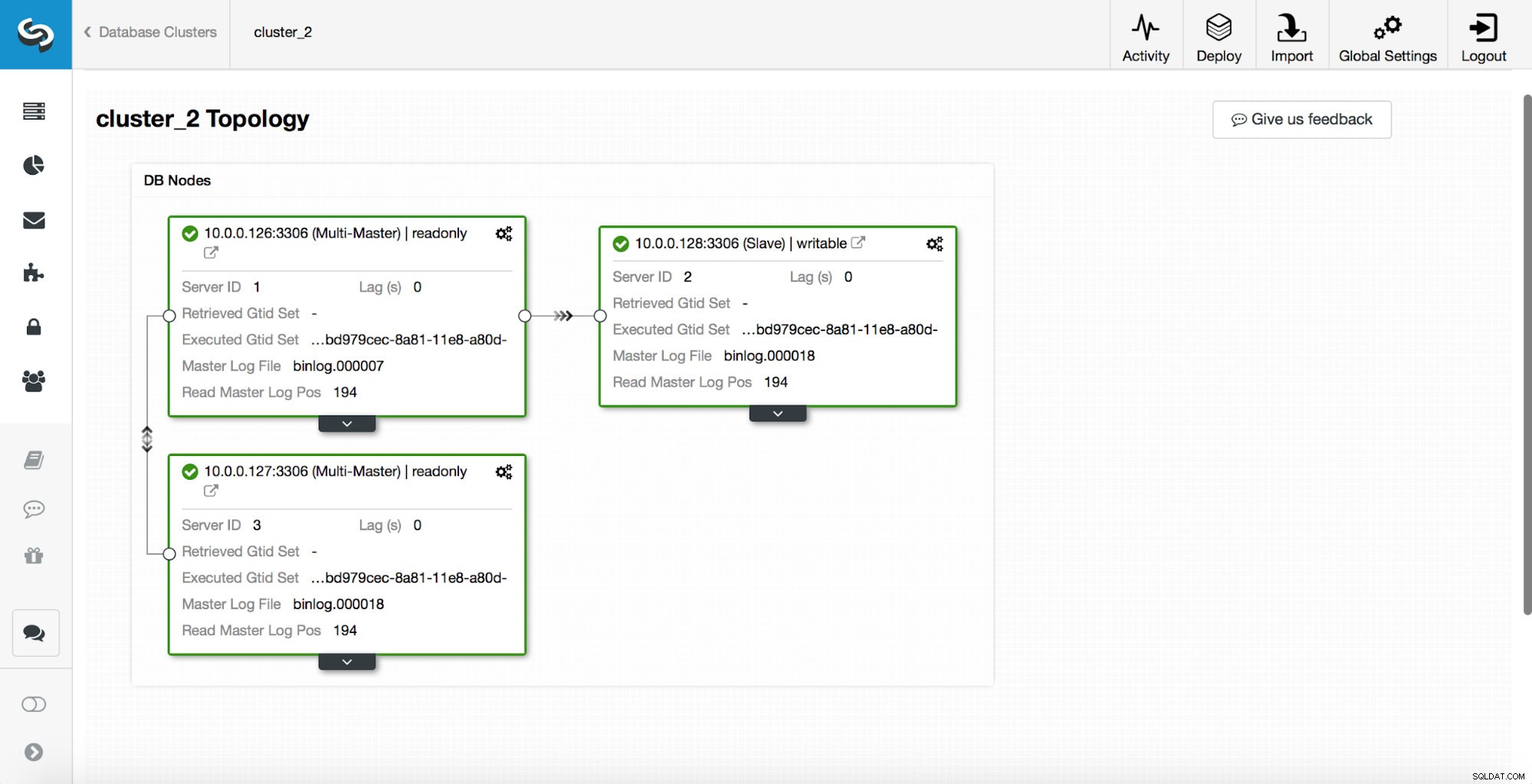
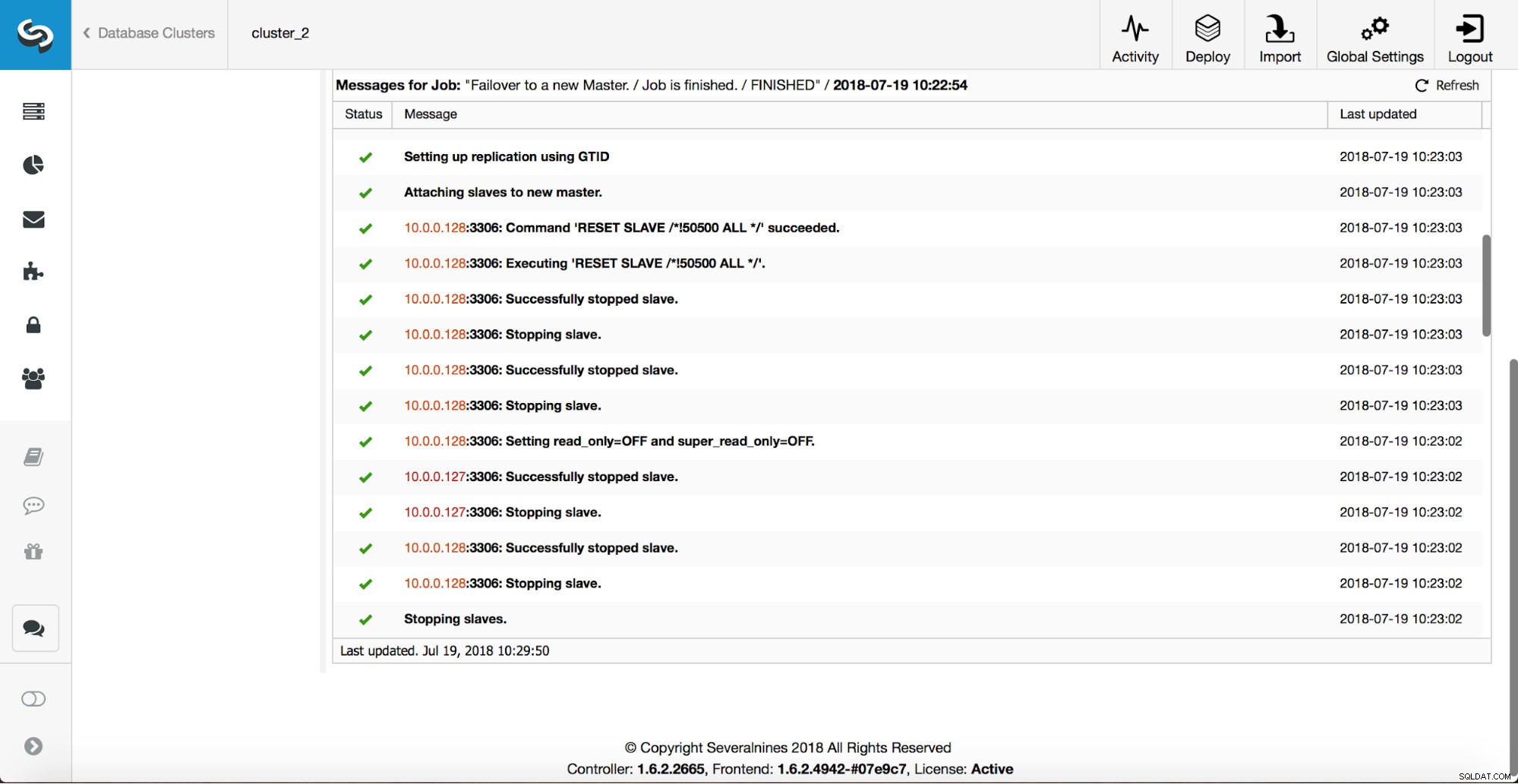
En master er blevet dræbt, og failover-processen startede. Bemærk venligst, at de nyere logposter er øverst, så du vil følge failoveren fra bunden til toppen.
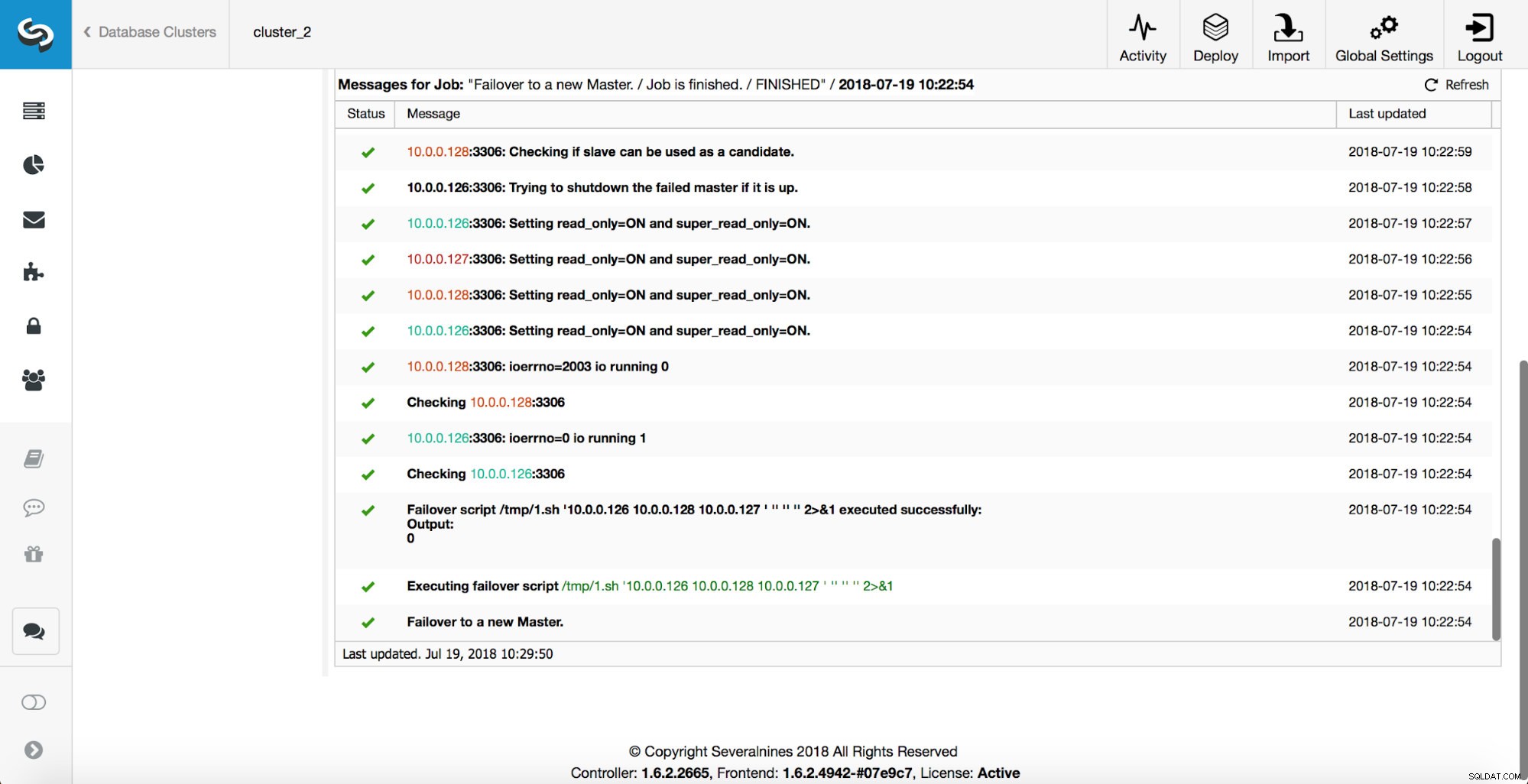
Som du kan se, udløser den umiddelbart efter failover-jobbet 'replikering_på-failover_script'-krogen. Derefter markeres alle tilgængelige værter som read_only, og ClusterControl forsøger at forhindre den gamle master i at køre.
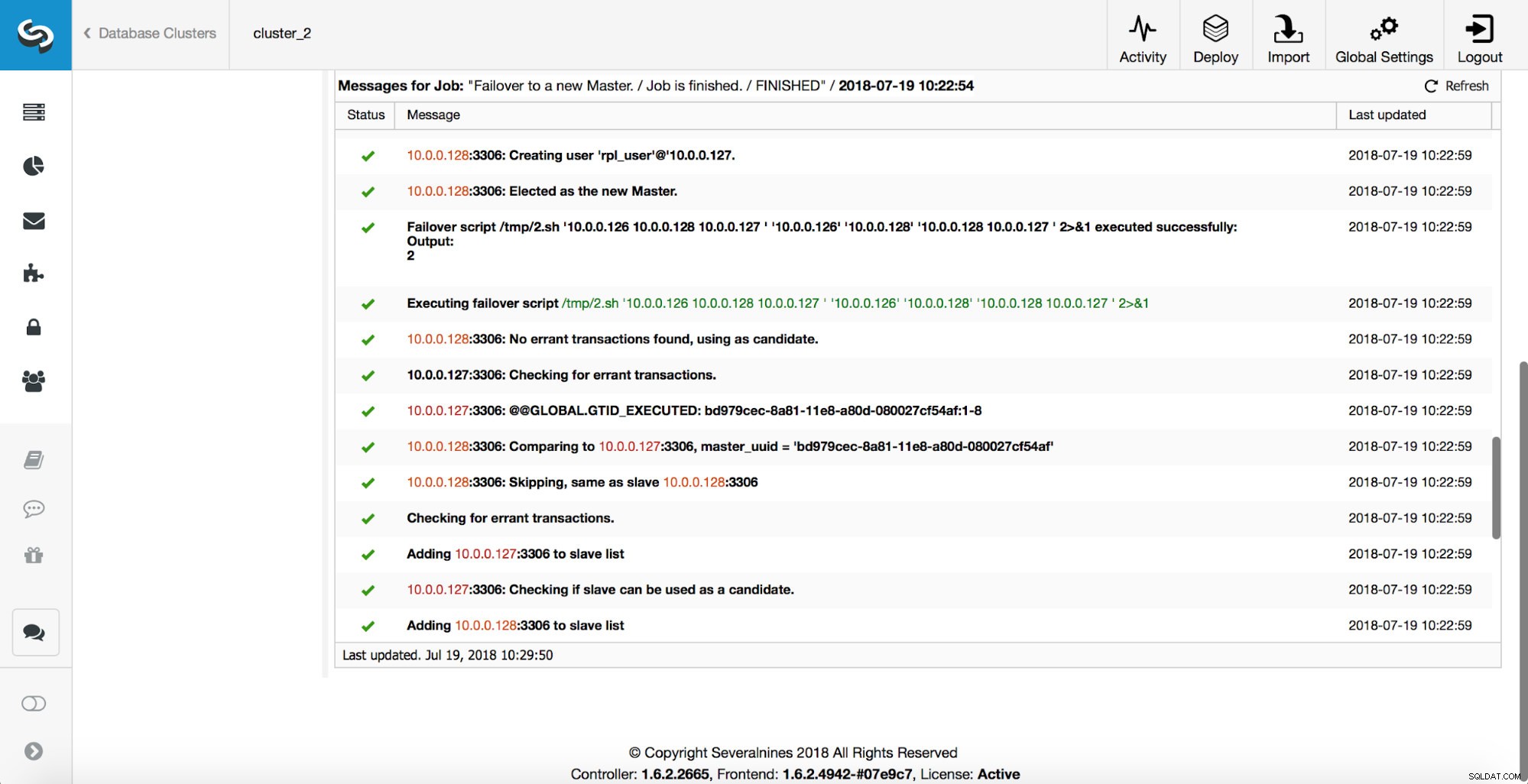
Dernæst udvælges masterkandidaten, og der udføres sundhedstjek. Når det er bekræftet, at masterkandidaten kan bruges som en ny master, udføres 'replikerings_pre_failover_scriptet'.
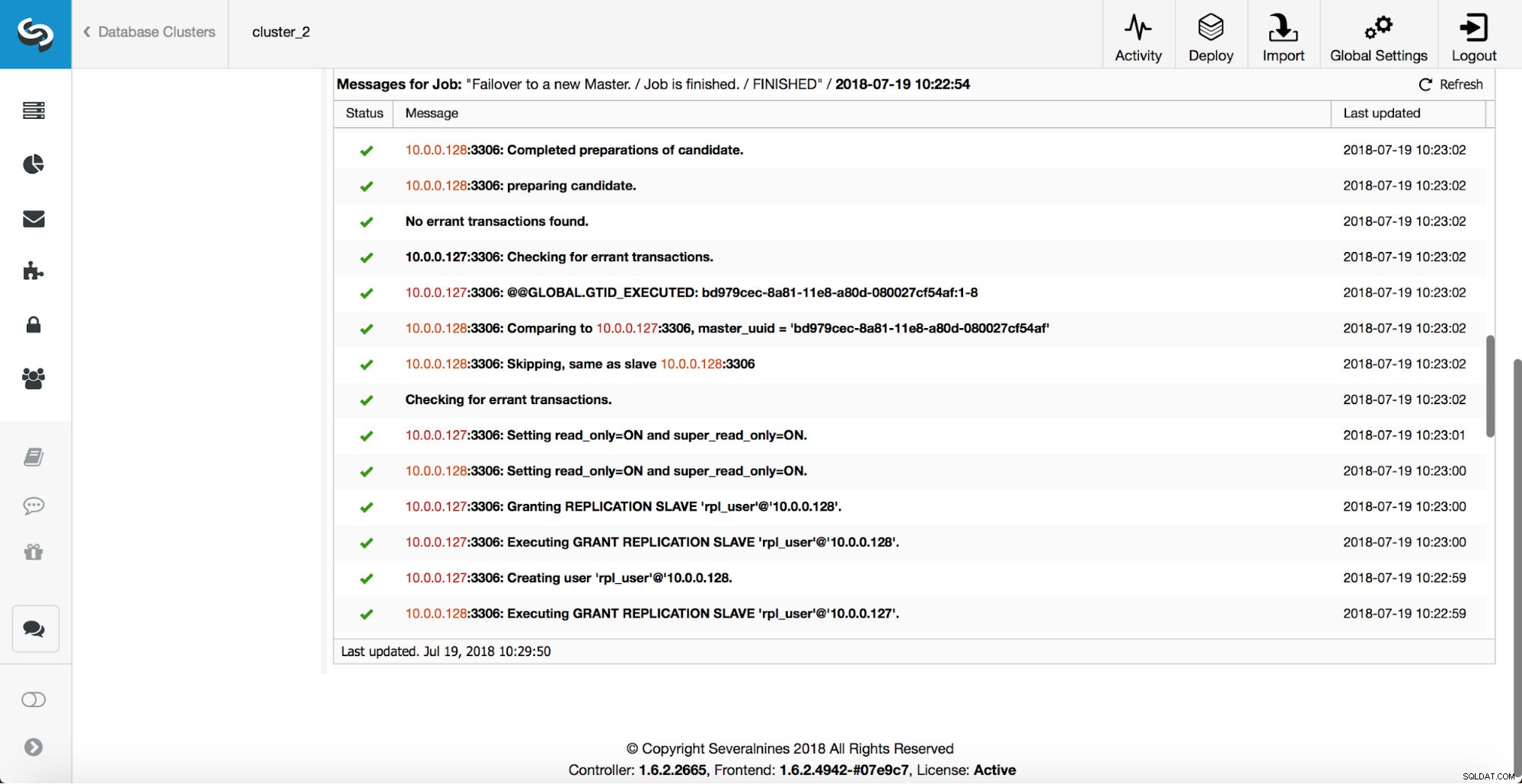
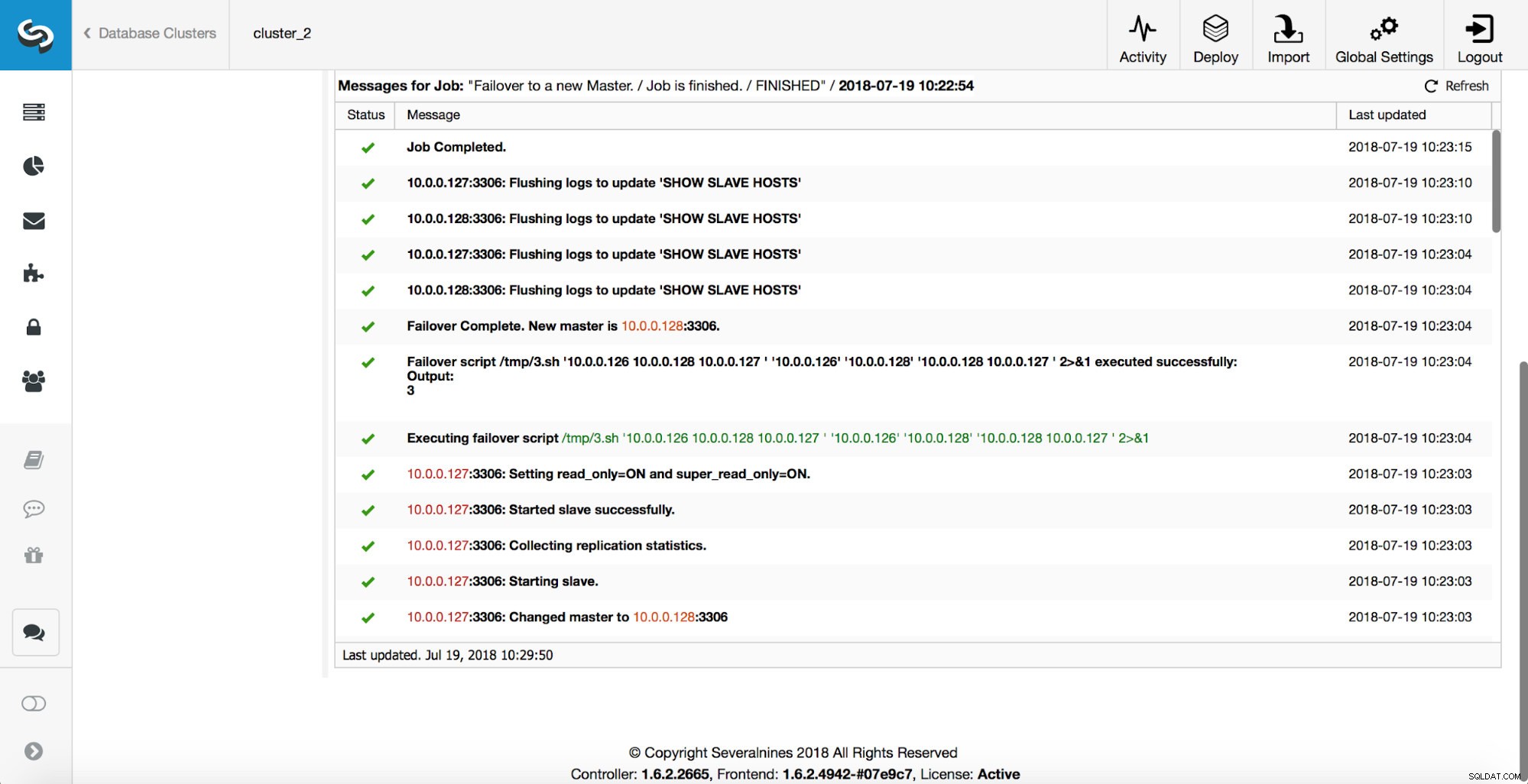
Flere kontroller udføres, replikaer stoppes og slaver af den nye master. Til sidst, efter failoveren er fuldført, udløses en sidste hook, 'replikation_post_failover_script'.
Hvornår kan kroge være nyttige?
I dette afsnit gennemgår vi et par eksempler, hvor det kan være en god idé at implementere eksterne scripts. Vi vil ikke komme ind på nogen detaljer, da de er for tæt knyttet til et bestemt miljø. Det vil mere være en liste over forslag, der kan være nyttige at implementere.
STONITH script
Shoot The Other Node In The Head (STONITH) er en proces for at sikre, at den gamle mester, som er død, forbliver død (og ja.. vi kan ikke lide zombier, der strejfer omkring i vores infrastruktur). Den sidste ting, du sandsynligvis ønsker, er at have en gammel mester, der ikke reagerer, som derefter kommer online igen, og som et resultat ender du med to skrivbare mestre. Der er forholdsregler, du kan tage for at sikre, at den gamle master ikke bliver brugt, selvom du dukker op igen, og det er sikrere for den at forblive offline. Måder på, hvordan man sikrer, at det vil være forskelligt fra miljø til miljø. Derfor vil der højst sandsynligt ikke være nogen indbygget understøttelse af STONITH i failover-værktøjet. Afhængigt af miljøet vil du måske udføre CLI-kommando, som vil stoppe (og endda fjerne) en VM, som den gamle master kører på. Hvis du har en lokal opsætning, har du muligvis mere kontrol over hardwaren. Det kan være muligt at bruge en form for fjernstyring (integreret Lights-out eller anden fjernadgang til serveren). Du har muligvis også adgang til håndterbare strømstik og sluk for strømmen i et af dem for at sikre, at serveren aldrig starter igen uden menneskelig indgriben.
Serviceopdagelse
Vi har allerede nævnt lidt om serviceopdagelse. Der er adskillige måder, man kan gemme information om en replikeringstopologi og detektere, hvilken vært der er en master. En af de mere populære muligheder er bestemt at bruge etc.d eller Consul til at gemme data om den aktuelle topologi. Med det kan en applikation eller proxy stole på disse data for at sende trafikken til den korrekte node. ClusterControl (ligesom de fleste af de værktøjer, der understøtter failover-håndtering) har ikke en direkte integration med hverken etc.d eller Consul. Opgaven med at opdatere topologidataene ligger hos brugeren. Hun kan bruge hooks som replication_post_failover_script eller replication_post_switchover_script til at fremkalde nogle af scripts og foretage de nødvendige ændringer. En anden ret almindelig løsning er at bruge DNS til at dirigere trafik til korrekte forekomster. Hvis du vil holde Time-To-Live for en DNS-post lav, bør du være i stand til at definere et domæne, som vil pege på din master (dvs. writes.cluster1.example.com). Dette kræver en ændring af DNS-posterne, og igen kan hooks som replication_post_failover_script eller replication_post_switchover_script være virkelig nyttige til at foretage nødvendige ændringer efter en failover sket.
Proxy-omkonfiguration
Hver proxyserver, der bruges, skal sende trafik til korrekte forekomster. Afhængigt af selve proxyen, kan hvordan en masterdetektion udføres enten (delvis) hardkodes eller kan være op til brugeren at definere, hvad hun kan lide. ClusterControl failover-mekanisme er designet på en måde, den integrerer godt med proxyer, som den har implementeret og konfigureret. Det kan stadig ske, at der er proxyer på plads, som ikke blev installeret af ClusterControl, og de kræver, at nogle manuelle handlinger finder sted, mens failover udføres. Sådanne proxyer kan også integreres med ClusterControl failover-processen gennem eksterne scripts og hooks som replication_post_failover_script eller replication_post_switchover_script.
Yderligere logning
Det kan ske, at du gerne vil indsamle data fra failover-processen til fejlretningsformål. ClusterControl har omfattende udskrifter for at sikre, at det er muligt at følge processen og finde ud af, hvad der skete og hvorfor. Det kan stadig ske, at du gerne vil indsamle nogle yderligere, tilpassede oplysninger. Grundlæggende kan alle krogene bruges her - du kan indsamle den oprindelige tilstand, før failoveren kan du spore miljøets tilstand på alle stadier af failoveren.