Svaret vil selvfølgelig være "det afhænger af", men baseret på at teste dette mål...
Forudsat
- 1 million produkter
producthar et klynget indeks påproduct_id- De fleste (hvis ikke alle) produkter har tilsvarende oplysninger i
product_codetabel - Ideelle indekser til stede på
product_codefor begge forespørgsler.
PIVOT version skal ideelt set have et indeks product_code(product_id, type) INCLUDE (code) mens JOIN version har ideelt set brug for et indeks product_code(type,product_id) INCLUDE (code)
Hvis disse er på plads, angiv nedenstående planer
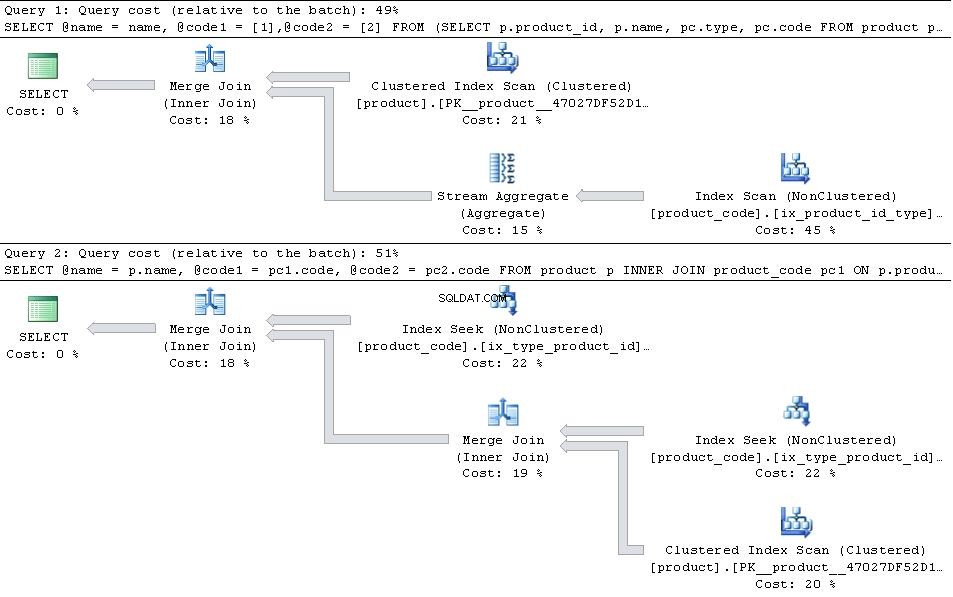
derefter JOIN version er mere effektiv.
I det tilfælde, at type 1 og type 2 er de eneste types i tabellen derefter PIVOT versionen har en smule kant med hensyn til antal læsninger, da den ikke behøver at søge ind i product_code to gange, men det er mere end opvejet af den ekstra overhead for strømaggregatoperatøren
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
DELTAG
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Hvis der er yderligere type andre poster end 1 og 2 JOIN version vil øge dens fordel, da den blot fusionerer sammenføjninger på de relevante sektioner af type,product_id indeks, mens PIVOT planen bruger product_id, type og vil derfor skulle scanne over den ekstra type rækker, der er blandet med 1 og 2 rækker.