For lang tid siden besvarede jeg et spørgsmål om NULL på Stack Exchange med titlen "Hvorfor skulle vi ikke tillade NULLs?" Jeg har min andel af kæledyr og lidenskaber, og frygten for NULLs er ret højt oppe på min liste. En kollega sagde for nylig til mig, efter at have udtrykt en præference for at tvinge en tom streng i stedet for at tillade NULL:
"Jeg kan ikke lide at håndtere nuller i kode."
Jeg er ked af det, men det er ikke en god grund. Hvordan præsentationslaget håndterer tomme strenge eller NULL'er burde ikke være driveren til dit tabeldesign og din datamodel. Og hvis du tillader en "manglende værdi" i en kolonne, betyder det noget for dig fra et logisk synspunkt, om "manglen på værdi" er repræsenteret af en nul-længde streng eller en NULL? Eller værre, en symbolsk værdi som 0 eller -1 for heltal eller 1900-01-01 for datoer?
Itzik Ben-Gan skrev for nylig en hel serie om NULLs, og jeg anbefaler stærkt at gennemgå det hele:
- NULL-kompleksiteter – del 1
- NULL-kompleksiteter – Del 2
- NULL-kompleksiteter – Del 3, Manglende standardfunktioner og T-SQL-alternativer
- NULL-kompleksiteter – Del 4, Manglende unikke standardbegrænsninger
Men mit mål her er lidt mindre kompliceret end som så, efter at emnet kom op i et andet Stack Exchange-spørgsmål:"Tilføj et automatisk nu-felt til en eksisterende tabel." Der tilføjede brugeren en ny kolonne til en eksisterende tabel med den hensigt at automatisk udfylde den med den aktuelle dato/tid. De spekulerede på, om de skulle lade NULL-værdier stå i den kolonne for alle de eksisterende rækker eller angive en standardværdi (som 1900-01-01, formentlig, selvom de ikke var eksplicitte).
Det kan være nemt for en, der kender til, at bortfiltrere gamle rækker baseret på en symbolsk værdi – når alt kommer til alt, hvordan kunne nogen tro, at en form for Bluetooth-doodad blev fremstillet eller købt den 1900-01-01? Nå, jeg har set dette i nuværende systemer, hvor de bruger en eller anden vilkårlig klingende dato i visninger til at fungere som et magisk filter, der kun præsenterer rækker, hvor værdien kan stole på. Faktisk er datoen i WHERE-sætningen i alle tilfælde, jeg har set indtil videre, datoen/tidspunktet, hvor kolonnen (eller dens standardbegrænsning) blev tilføjet. Hvilket er fint; det er måske ikke den bedste måde at løse problemet på, men det er en måde.
Hvis du dog ikke får adgang til tabellen gennem visningen, er denne implikation af en kendt værdi kan stadig forårsage både logiske og resultatrelaterede problemer. Det logiske problem er simpelthen, at nogen, der interagerer med bordet, skal vide, at 1900-01-01 er en falsk, symbolsk værdi, der repræsenterer "ukendt" eller "ikke relevant." For et eksempel fra den virkelige verden, hvad var den gennemsnitlige udgivelseshastighed, i sekunder, for en quarterback, der spillede i 1970'erne, før vi målte eller sporede sådan noget? Er 0 en god tokenværdi for "ukendt"? Hvad med -1? eller 100? For at komme tilbage til dato, hvis en patient uden ID bliver indlagt på hospitalet og er bevidstløs, hvad skal de så angive som fødselsdato? Jeg synes ikke, 1900-01-01 er en god idé, og det var bestemt ikke en god idé dengang, det var mere sandsynligt, at det var en rigtig fødselsdato.
Ydeevneimplikationer af tokenværdier
Fra et præstationsperspektiv kan falske eller "token"-værdier som 1900-01-01 eller 9999-21-31 give problemer. Lad os se på et par af disse med et eksempel baseret løst på det seneste spørgsmål nævnt ovenfor. Vi har en Widget-tabel, og efter nogle garantireturneringer har vi besluttet at tilføje en EnteredService-kolonne, hvor vi indtaster den aktuelle dato/tid for nye rækker. I det ene tilfælde vil vi lade alle de eksisterende rækker være NULL, og i det andet vil vi opdatere værdien til vores magiske 1900-01-01 dato. (Vi udelader enhver form for komprimering fra samtalen indtil videre.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Nu indsætter vi de samme 100.000 rækker i hver tabel:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Så kan vi tilføje den nye kolonne og opdatere 10 % af de eksisterende værdier med en fordeling af aktuelle datoer, og de andre 90 % til vores token-dato kun i en af tabellerne:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Endelig kan vi tilføje indekser:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Brugt plads
Jeg hører altid "diskplads er billig", når vi taler om datatypevalg, fragmentering og tokenværdier vs. NULL. Min bekymring er ikke så meget med den diskplads, som disse ekstra meningsløse værdier optager. Det er mere, at når bordet bliver forespurgt, spilder det hukommelse. Her kan vi få en hurtig idé om, hvor meget plads vores tokenværdier bruger før og efter at kolonnen og indekset er tilføjet:
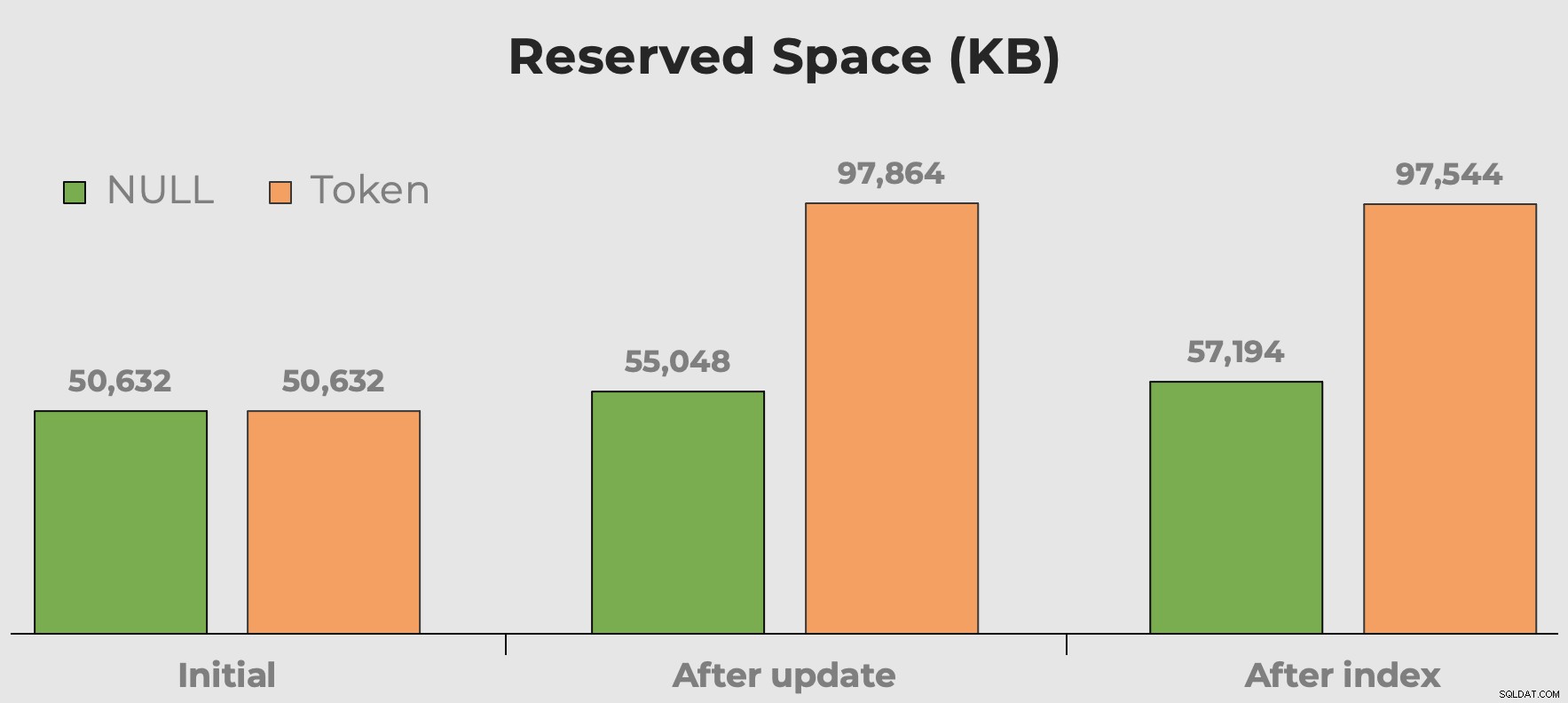 Reserveret plads i tabellen efter tilføjelse af en kolonne og tilføjelse af et indeks. Mellemrummet fordobles næsten med tokenværdier.
Reserveret plads i tabellen efter tilføjelse af en kolonne og tilføjelse af et indeks. Mellemrummet fordobles næsten med tokenværdier.
Forespørgselsudførelse
Uundgåeligt vil nogen gøre antagelser om dataene i tabellen og forespørge mod EnteredService-kolonnen, som om alle værdierne der er legitime. For eksempel:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Tokenværdierne kan rode med estimater i nogle tilfælde, men endnu vigtigere, de vil producere forkerte (eller i det mindste uventede) resultater. Her er eksekveringsplanen for forespørgslen mod tabellen med tokenværdier:
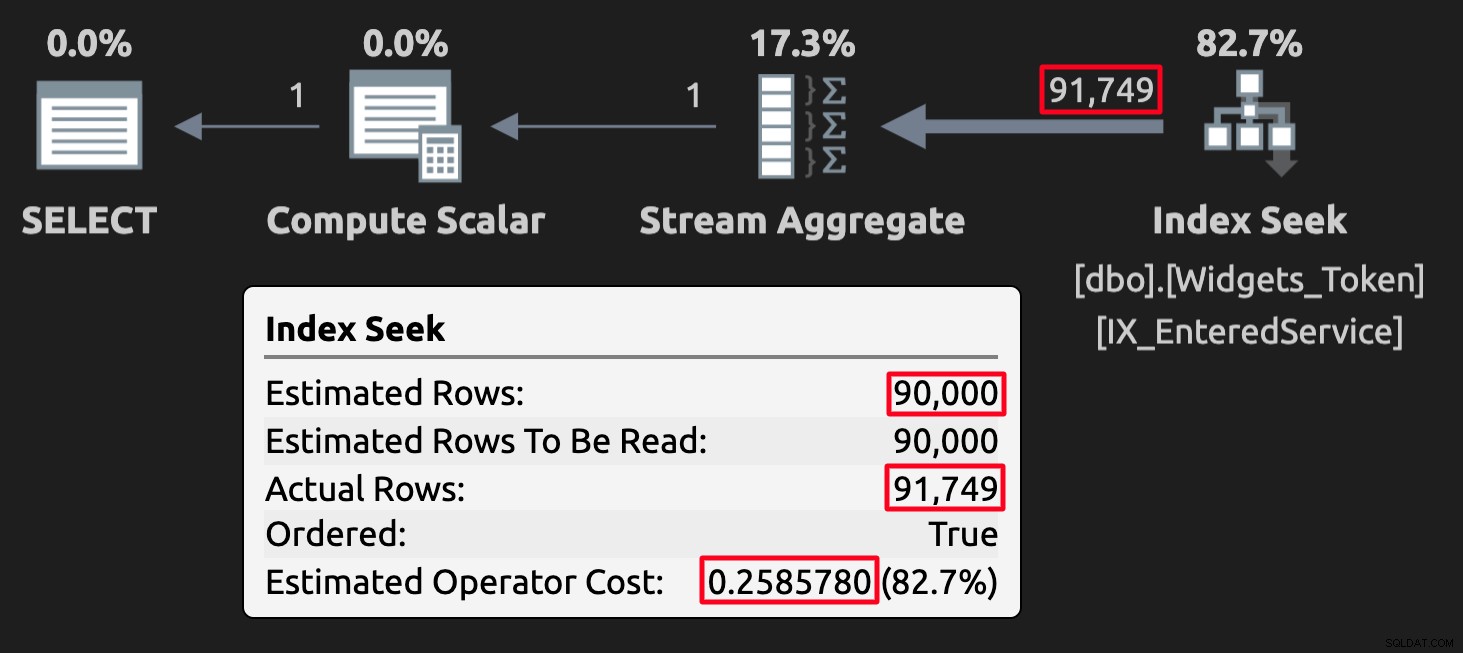 Udførelsesplan for token-tabellen; bemærk de høje omkostninger.
Udførelsesplan for token-tabellen; bemærk de høje omkostninger.
Og her er eksekveringsplanen for forespørgslen mod tabellen med NULL'er:
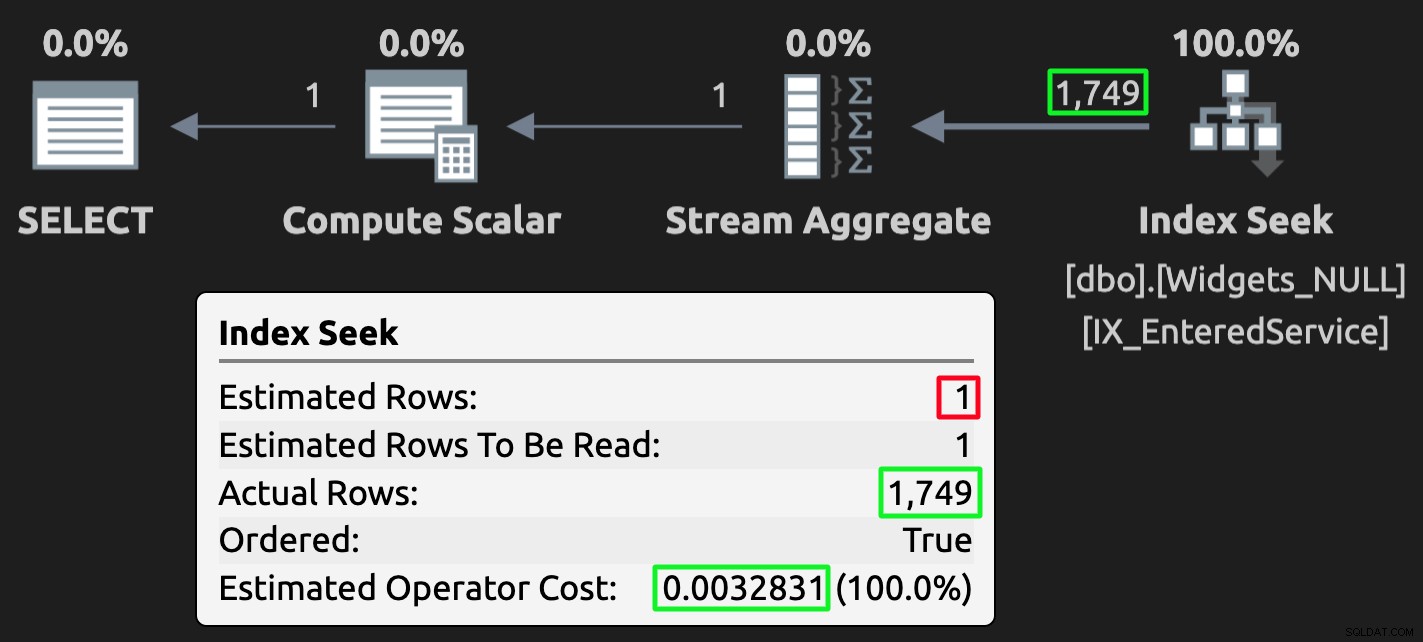 Udførelsesplan for NULL-tabellen; forkert skøn, men meget lavere omkostninger.
Udførelsesplan for NULL-tabellen; forkert skøn, men meget lavere omkostninger.
Det samme ville ske den anden vej, hvis forespørgslen bad om>={en dato} og 9999-12-31 blev brugt som den magiske værdi, der repræsenterer ukendt.
Igen, for de mennesker, der tilfældigvis ved, at resultaterne er forkerte, specifikt fordi du har brugt tokenværdier, er dette ikke et problem. Men alle andre, der ikke ved det – inklusive fremtidige kolleger, andre arvere og vedligeholdere af koden, og endda fremtidige dig med hukommelsesudfordringer – kommer sandsynligvis til at snuble.
Konklusion
Valget om at tillade NULLs i en kolonne (eller at undgå NULLs helt) bør ikke reduceres til en ideologisk eller frygtbaseret beslutning. Der er reelle, håndgribelige ulemper ved at opbygge din datamodel for at sikre, at ingen værdi kan være NULL, eller ved at bruge meningsløse værdier til at repræsentere noget, der nemt kunne have været ikke gemt overhovedet. Jeg foreslår ikke, at hver kolonne i din model skal tillade NULL; bare at du ikke er imod ideen af NULL.