Introduktion
Spoler tilbage er specifikke for operatorer på indersiden af en indlejret løkke, der forbinder eller anvender. Ideen er at genbruge tidligere beregnede resultater fra en del af en eksekveringsplan, hvor det er sikkert at gøre det.
Det kanoniske eksempel på en planoperatør, der kan spole tilbage, er den dovne bordspole . Dens raison d’être er at cache resultatrækker fra et plan-undertræ og derefter afspille disse rækker ved efterfølgende iterationer, hvis nogen korrelerede loop-parametre er uændrede. Genafspilning af rækker kan være billigere end at genudføre det undertræ, der genererede dem. For mere baggrund om disse ydelsesspoler se min tidligere artikel.
Dokumentationen siger, at kun følgende operatører kan spole tilbage:
- Bordspole
- Rækketællerspole
- Ikke-klyngede indeksspole
- Tabelvurderet funktion
- Sortér
- Fjernforespørgsel
- Bekræftelse og Filter operatorer med et Startudtryk
De første tre elementer er oftest præstationsspoler, selvom de kan introduceres af andre årsager (når de kan være ivrige såvel som dovne).
Tabelvurderede funktioner brug en tabelvariabel, som kan bruges til at cache og afspille resultater under passende omstændigheder. Hvis du er interesseret i tilbagespoling af tabelværdier, kan du se mine spørgsmål og svar på Database Administrators Stack Exchange.
Med dem af vejen handler denne artikel udelukkende om Sorts og hvornår de kan spole tilbage.
Sortér tilbagespoling
Sorter bruger lager (hukommelse og måske disk, hvis de spilder), så de har en facilitet egnet lagring af rækker mellem loop-iterationer. Især det sorterede output kan i princippet afspilles igen (spoles tilbage).
Alligevel er det korte svar på titelspørgsmålet "Spoler sorter tilbage?" er:
Ja, men du vil ikke se det ret ofte.
Sorteringstyper
Sorter findes i mange forskellige typer internt, men til vores nuværende formål er der kun to:
- Sortering i hukommelsen (
CQScanInMemSortNew).- Altid i hukommelsen; kan ikke spilde til disk.
- Bruger standard hurtig sortering.
- Maksimalt 500 rækker og to 8KB sider i alt.
- Alle input skal være køretidskonstanter. Dette betyder typisk, at hele sorteringsundertræet skal bestå af kun Konstant scanning og/eller Compute Scalar operatører.
- Kun eksplicit skelnes i udførelsesplaner, når omfattende showplan er aktiveret (sporingsflag 8666). Dette føjer ekstra egenskaber til Sorteringen operator, hvoraf den ene er "InMemory=[0|1]".
- Alle andre sorteringer.
(Begge typer Sort operatør inkludere deres Top N Sort og Distinct Sort varianter).
Spoleadfærd tilbage
-
In-Memory Sorteringer kan altid spole tilbage når det er sikkert. Hvis der ikke er nogen korrelerede loop-parametre, eller parameterværdierne er uændrede i forhold til den umiddelbart forudgående iteration, kan denne type sortering afspille sine lagrede data i stedet for at genudføre operatører under den i udførelsesplanen.
-
Ikke-i-hukommelse Sorterer kan spole tilbage når det er sikkert, men kun hvis Sortér operatoren indeholder højst én række . Bemærk venligst en Sortering input kan give én række på nogle iterationer, men ikke andre. Kørselsadfærden kan derfor være en kompleks blanding af tilbagespoling og genbinding. Det afhænger fuldstændig af, hvor mange rækker der er givet til Sorteringen på hver iteration under kørsel. Du kan generelt ikke forudsige, hvad en Sort er vil gøre på hver iteration ved at inspicere udførelsesplanen.
Ordet "sikker" i beskrivelserne ovenfor betyder:Enten skete der ikke en ændring i parameter, eller ingen operatorer under Sort har en afhængighed af den ændrede værdi.
Vigtig bemærkning om udførelsesplaner
Udførelsesplaner rapporterer ikke altid tilbagespoling (og genbindinger) korrekt for Sortering operatører. Operatøren vil rapportere en tilbagespoling, hvis nogen korrelerede parametre er uændrede, og en genbinding ellers.
For sorteringer, der ikke er i hukommelsen (langt det mest almindelige), vil en rapporteret tilbagespoling kun faktisk afspille de lagrede sorteringsresultater, hvis der højst er én række i sorteringsoutputbufferen. Ellers vil sorteringen rapportere en tilbagespoling, men undertræet vil stadig blive fuldført igen (en genbinding).
For at kontrollere, hvor mange rapporterede tilbagespolinger der var faktiske tilbagespolinger, skal du kontrollere Antal udførelser ejendom på operatører under Sorteringen .
Historie og min forklaring
Sorter Operatørens tilbagespolingsadfærd kan virke mærkelig, men det har været på denne måde fra (i det mindste) SQL Server 2000 til SQL Server 2019 inklusive (såvel som Azure SQL Database). Jeg har ikke været i stand til at finde nogen officiel forklaring eller dokumentation om det.
Min personlige opfattelse er, at Sorter tilbagespoling er ret dyrt på grund af det underliggende sorteringsmaskineri, inklusive spildfaciliteter og brugen af systemtransaktioner i tempdb .
I de fleste tilfælde vil optimeringsværktøjet gøre det bedre at introducere en eksplicit ydelsesspool når den registrerer muligheden for duplikerede korrelerede loop-parametre. Spooler er den billigste måde at cache delvise resultater på.
Det er muligt at genafspille en Sorter resultatet ville kun være mere omkostningseffektivt end en Spool når Sorter indeholder højst én række. Når alt kommer til alt, involverer sortering af én række (eller ingen rækker!) faktisk ingen sortering overhovedet, så meget af overhead kan undgås.
Ren spekulation, men nogen var nødt til at spørge, så der er det.
Demo 1:Unøjagtige tilbagespoling
Dette første eksempel indeholder to tabelvariabler. Den første indeholder tre værdier duplikeret tre gange i kolonne c1 . Den anden tabel indeholder to rækker for hvert match på c2 = c1 . De to matchende rækker er kendetegnet ved en værdi i kolonne c3 .
Opgaven er at returnere rækken fra den anden tabel med den højeste c3 værdi for hvert match på c1 = c2 . Koden er nok klarere end min forklaring:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
NO_PERFORMANCE_SPOOL tip er der for at forhindre, at optimizeren introducerer en præstationsspool. Dette kan ske med tabelvariable, når f.eks. sporingsflag 2453 er aktiveret, eller tabelvariabel udskudt kompilering er tilgængelig, så optimeringsværktøjet kan se den sande kardinalitet af tabelvariablen (men ikke værdifordeling).
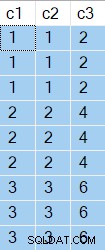
Forespørgselsresultaterne viser c2 og c3 returnerede værdier er de samme for hver enkelt c1 værdi:
Den faktiske udførelsesplan for forespørgslen er:
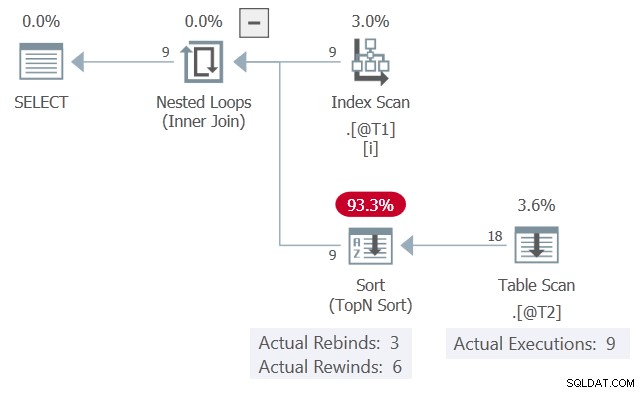
c1 værdier, præsenteret i rækkefølge, matcher den forrige iteration 6 gange og ændres 3 gange. Sorter rapporterer dette som 6 rewinds og 3 rebindings.
Hvis dette var sandt, Tabelscanning ville kun udføre 3 gange. Sorter ville afspille (tilbagespole) sine resultater ved de andre 6 lejligheder.
Som det er, kan vi se Tabelscanningen blev udført 9 gange, én gang for hver række fra tabel @T1 . Der skete ingen tilbagespoling her .
Demo 2:Sorter tilbagespoling
Det forrige eksempel tillod ikke Sortering at spole tilbage, fordi (a) det ikke er en In-Memory Sortering; og (b) på hver iteration af løkken, Sort indeholdt to rækker. Plan Explorer viser i alt 18 rækker fra Tabelscanningen , to rækker på hver af 9 iterationer.
Lad os justere eksemplet nu, så der kun er én række i tabel @T2 for hver matchende række fra @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Resultaterne er de samme som tidligere vist, fordi vi beholdt den matchende række, der sorterede højest i kolonne c3 . Udførelsesplanen ligner også overfladisk, men med en vigtig forskel:
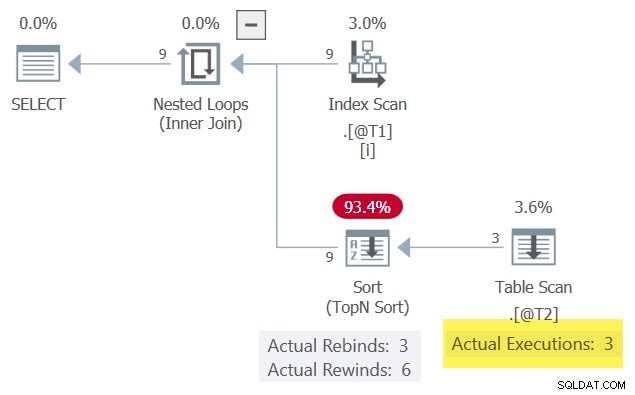
Med én række i Sorter til enhver tid kan den spole tilbage, når den korrelerede parameter c1 ændres ikke. Tabelscanning er kun udført 3 gange som et resultat.
Læg mærke til Sorteringen producerer flere rækker (9) end den modtager (3). Dette er en god indikation på, at en Sortér har formået at cache et resultatsæt en eller flere gange – en vellykket tilbagespoling.
Demo 3:Rewinding Nothing
Jeg nævnte før, at en Sort, der ikke er i hukommelsen kan spole tilbage, når den indeholder højst en række.
For at se det i aktion med nul rækker , ændrer vi til en OUTER APPLY og sæt ingen rækker i tabellen @T2 . Af årsager, der snart vil vise sig, stopper vi også med at projicere kolonne c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Resultaterne har nu NULL i kolonne c3 som forventet:
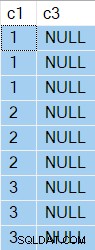
Udførelsesplanen er:
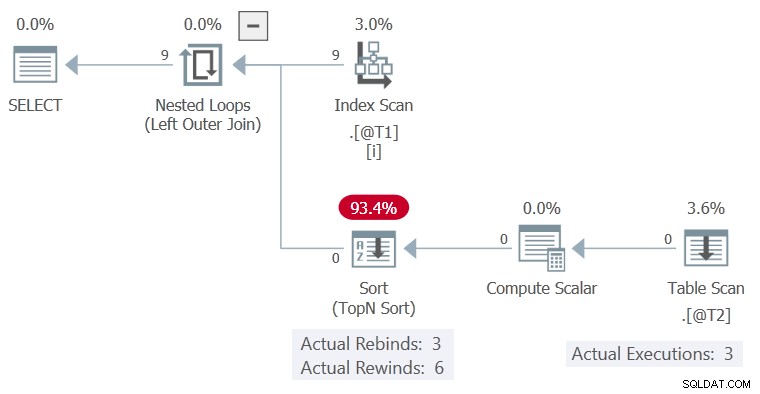
Sorter var i stand til at spole tilbage uden rækker i bufferen, så Tabelscanningen blev kun udført 3 gange, hver tidskolonne c1 ændret værdi.
Demo 4:Maksimal tilbagespoling!
Ligesom de andre operatører, der understøtter tilbagespoling, en Sort vil kun genbinde dens undertræ, hvis en korreleret parameter er ændret og undertræet afhænger på en eller anden måde af den værdi.
Gendannelse af kolonnen c2 projektion til demo 3 vil vise dette i aktion:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Resultaterne viser nu to NULL kolonner selvfølgelig:
Udførelsesplanen er helt anderledes:
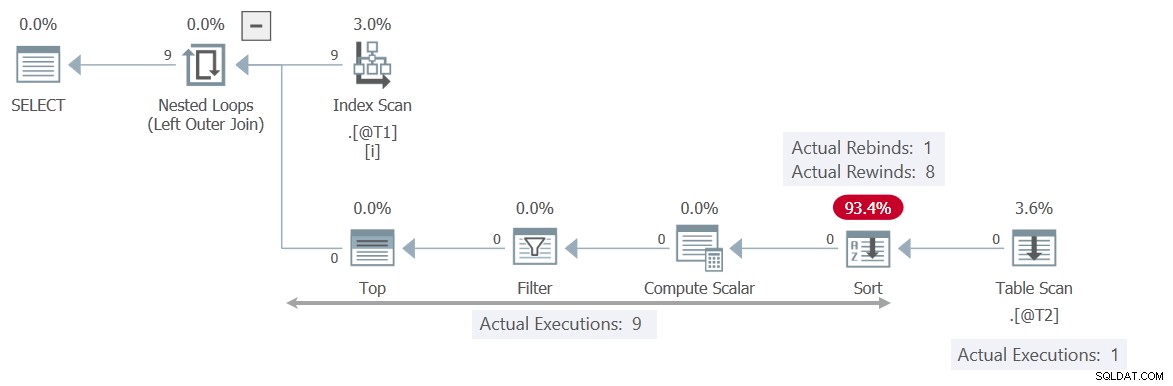
Denne gang er Filtret indeholder markeringen T2.c2 = T1.c1 , hvilket gør Tabelscanning uafhængig af den aktuelle værdi af den korrelerede parameter c1 . Sorter kan sikkert spole 8 gange tilbage, hvilket betyder, at scanningen kun udføres én gang .
Demo 5:In-Memory Sortering
Det næste eksempel viser en Sortering i hukommelsen operatør:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); De resultater, du får, vil variere fra udførelse til udførelse, men her er et eksempel:
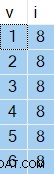
Det interessante er værdierne i kolonne i vil altid være den samme - på trods af ORDER BY NEWID() klausul.
Du har sikkert allerede gættet årsagen til dette er Sorteringen cache-resultater (tilbagespoling). Udførelsesplanen viser Konstant scanning udføres kun én gang, producerer 11 rækker i alt:
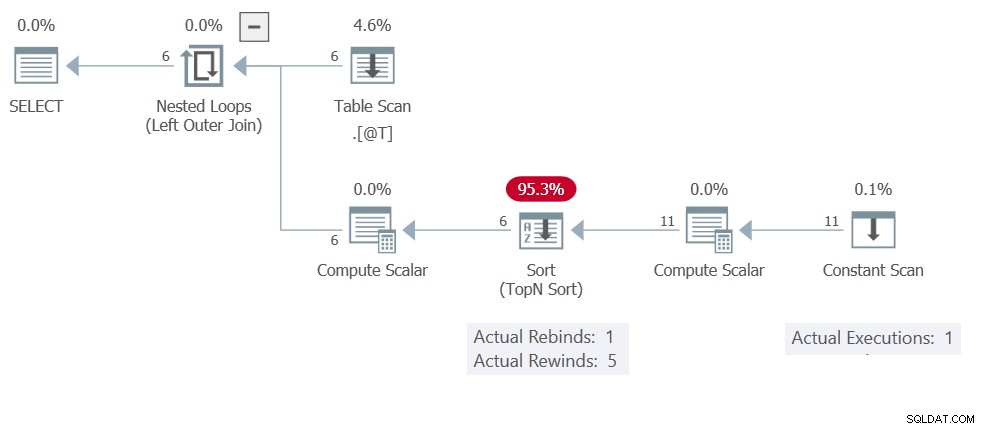
Denne Sortér har kun Compute Scalar og Konstant scanning operatører på dets input, så det er en In Memory Sort . Husk, at disse ikke er begrænset til højst en enkelt række – de kan rumme 500 rækker og 16 KB.
Som tidligere nævnt er det ikke muligt eksplicit at se, om en Sortér er In-Memory eller ej ved at efterse en almindelig udførelsesplan. Vi har brug for omfattende showplan-output , aktiveret med udokumenteret sporingsflag 8666. Med det aktiveret vises ekstra operatøregenskaber:
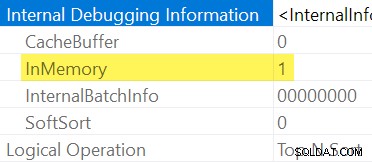
Når det ikke er praktisk at bruge udokumenterede sporingsflag, kan du udlede, at en Sorter er "InMemory" ved sin Input Memory Fraction er nul, og Hukommelsesbrug elementer, der ikke er tilgængelige i post-execution showplan (på SQL Server-versioner, der understøtter disse oplysninger).
Tilbage til udførelsesplanen:Der er ingen korrelerede parametre, så Sorter er gratis at spole 5 gange tilbage, hvilket betyder Konstant scanning udføres kun én gang. Du er velkommen til at ændre TOP (1) til TOP (3) eller hvad du nu kan lide. Tilbagespoling betyder, at resultaterne vil være de samme (cache/tilbagespolede) for hver inputrække.
Du kan blive generet af ORDER BY NEWID() klausul, der ikke forhindrer tilbagespoling. Dette er faktisk et kontroversielt punkt, men slet ikke begrænset til sorter. For en mere fyldig diskussion (advarsel:muligt kaninhul) se venligst dette spørgsmål og svar. Den korte version er, at dette er en bevidst produktdesignbeslutning, der optimerer for ydeevne, men der er planer om at gøre adfærden mere intuitiv over tid.
Demo 6:Ingen sortering i hukommelsen
Dette er det samme som demo 5, bortset fra at den replikerede streng er et tegn længere:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Igen vil resultaterne variere pr. udførelse, men her er et eksempel. Læg mærke til i værdierne er nu ikke alle ens:

Det ekstra tegn er lige nok til at skubbe den anslåede størrelse af de sorterede data over 16KB. Dette betyder en In-Memory Sortering kan ikke bruges, og tilbagespolingen forsvinder.
Udførelsesplanen er:
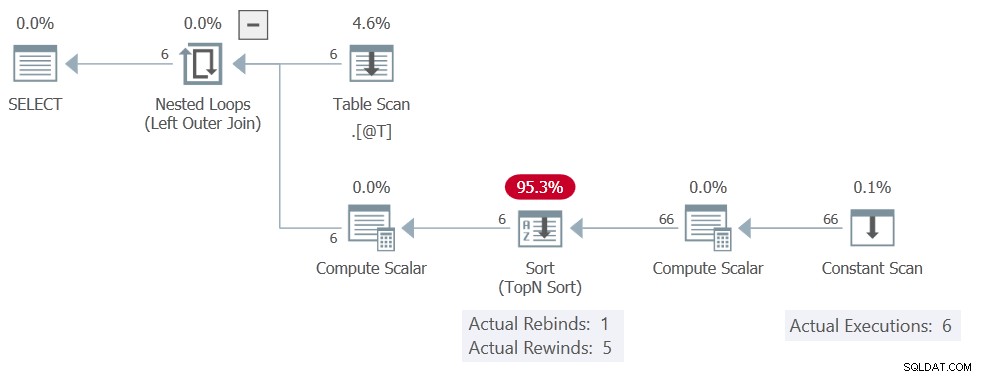
Sorter stadig rapporter 5 tilbagespoling, men Konstant scanning udføres 6 gange, hvilket betyder, at der ikke rigtigt forekom nogen tilbagespoling. Den producerer alle 11 rækker på hver af 6 henrettelser, hvilket giver i alt 66 rækker.
Opsummering og endelige tanker
Du vil ikke se en Sortering operatør virkelig tilbagespoling meget ofte, selvom du vil se det siger det gjorde ret meget.
Husk en almindelig Sortering kan kun spole tilbage, hvis det er sikkert og der er højst én række i sorteringen ad gangen. At være "sikker" betyder enten ingen ændring i løkkekorrelationsparametre eller intet under Sort påvirkes af parameterændringerne.
En In-Memory Sortering kan fungere på op til 500 rækker og 16 KB data hentet fra Konstant scanning og Compute Scalar kun operatører. Det vil også kun spole tilbage, når det er sikkert (produktfejl til side!), men er ikke begrænset til maksimalt én række.
Disse kan virke som esoteriske detaljer, og det formoder jeg, at de er. Så siger de, de har hjulpet mig med at forstå en eksekveringsplan og finde gode præstationsforbedringer mere end én gang. Måske vil du også finde informationen nyttig en dag.
Hold øje med Sorts der producerer flere rækker, end de har på deres input!
Hvis du gerne vil se et mere realistisk eksempel på Sort spoler tilbage baseret på en demo, som Itzik Ben-Gan leverede i en del af hans Closest Match serier, se venligst Nærmest match med sortering tilbage.